UNIVERSITA' DEGLI STUDI DI MILANO Facoltà di Scienze Matematiche, Fisiche e Naturali Corso di Laurea in Informatica triennale ANALISI ED OTTIMIZZAZIONE BASE DATI DI UN SERVER WEB PER LA DISTRIBUZIONE SOFTWARE IN AMBITO SCIENTIFICO Relatore: Prof.ssa S. CASTANO Correlatore: Dott. G. BATTISTIONI Tesi di laurea di Christian QUADRI matricola 689544 Anno Accademico 2007/2008
Transcript
UNIVERSITA' DEGLI STUDI DI MILANOFacoltà di Scienze Matematiche, Fisiche e Naturali
Corso di Laurea in Informatica triennale
ANALISI ED OTTIMIZZAZIONE BASE DATI DI UN SERVER WEB PER LA DISTRIBUZIONE
SOFTWARE IN AMBITO SCIENTIFICO
Relatore: Prof.ssa S. CASTANOCorrelatore: Dott. G. BATTISTIONI
Tesi di laurea diChristian QUADRI
matricola 689544
Anno Accademico 2007/2008
Indice
1 Il sistema preesistente.................................................................................................................7
1.1 Funzionalità del sistema esistente......................................................................................7
interrogazioni, anche complesse, del linguaggio SQL.
La progettazione della base di dati è iniziata con l'analisi dei requisiti e la creazione dello
schema EntitàRelazione che è stato poi presentato al gruppo di ricerca, modificandolo dove
necessario. Lo schema è stato tradotto nel suo modello relazionale e implementato utilizzando
MySQL come DBMS.
Una volta definita e testata la struttura della base di dati è iniziata la fase di analisi e
progettazione delle nuove funzionalità realizzabili all'interno dell'applicazione web, in
funzione dei nuovi requisiti e della nuova tipologia di base di dati identificandone le parti da
modificare e i nuovi moduli da realizzare.
Il risultato della progettazione è il seguente:
– Apportare modifiche alle procedure di interazione con la base di dati, creando un modulo
di interfaccia tra sito web e base di dati sostituendo quelle precedenti.
– Riprogettazione della procedura di autenticazione per gli utenti registrati rendendola
obbligatoria per accedere alla procedura di scaricamento pacchetti, diversamente da
quanto avveniva in precedenza in cui l'accesso al download era regolato tramite
autorizzazione diretta del web server.
– Progettazione di una nuova procedura di download dei pacchetti in grado di monitorare il
completamento con successo dello scaricamento.
– Progettazione di un modulo di ricerca avanzata utilizzabile dall'amministratore del sito
per effettuare ricerche specifiche e personalizzabili all'interno della lista degli utenti
registrati.
L'implementazione delle nuove parti dell'applicazione web è stata fatta utilizzando le
tecnologie a disposizione sul web server. Sviluppando tali moduli si è cercando di riutilizzare
Introduzione 6
il più' possibile il codice già presente e si sono integrati i nuovi blocchi mantenendo
un'architettura coerente con quella preesistente.
Nel Capitolo 1 è presentato lo stato del sistema durante la fase di analisi, descrivendo
dettagliatamente la struttura dell'archivio dei dati e le sue interazioni con l'applicazione web.
Nel Capitolo 2 è descritta la fase di progettazione della nuova base di dati e dei moduli
applicativi, presentando un'analisi delle criticità del sistema preesistente
Il Capitolo 3 è interamente dedicato alla fase implementativa descrivendo il funzionamento
delle procedure realizzate, presentando i problemi riscontrati e la loro soluzione.
Nel Capitolo 4 sono presentate alcune schermate del sito web relative alle funzionalità
implementate.
Nell'ultimo capitolo sono riportate le conclusioni del lavoro di tesi e alcuni sviluppi futuri
realizzabili sulle basi di ciò che è stato realizzato.
Capitolo 1 7
Capitolo 1
Il sistema preesistente
In questo capitolo verranno descritte:
– le funzionalità del sistema nel Sottocapitolo 1.1.
– il sistema di gestione dei dati e di distribuzione del software nel Sottocapitolo 1.2;
– nel Sottocapitolo 1.3 i requisiti che sono alla base della ristrutturazione del sistema
oggetto dell'elaborato finale.
1.1 Funzionalità del sistema esistente
La struttura generale del sistema esistente è rappresentata nella figura 1.1
Figura 1.1: struttura generale del sistema esistente
Il sistema preesistente 8
Il principale obiettivo del sistema si occupa del distribuzione controllata del software di
simulazione delle particelle elementari FLUKA[1][2] per applicazioni nella fisica delle alte
energie, schermature, dosimetria in fisica medica e radiobiologia. Il gruppo di ricercatori ha
la necessità di controllare la distribuzione di questo software, in quanto la sua licenza ne vieta
l'utilizzo per scopi commerciali e militari. Un'ulteriore scopo del sistema è quello di fornire
supporto tecnico, informazione e documentazione del software agli utilizzatori distribuiti in
tutto il mondo prevalentemente presso enti di ricerca in abito fisico.
Ogni utente che intende scaricare il simulatore deve effettuare una registrazione via web
immettendo i seguenti dati: nome, cognome, indirizzo di posta elettronica, l'organizzazione o
l'ente presso cui lavora o effettua ricerche, gli interessi nell'ambito dei settori della fisica delle
particelle, l'esperienza nell'uso del software, l'ambito di utilizzo (ricerca/didattica o
occasionale) e l'iscrizione alla mailing list generica di discussione (FLUKAdiscuss).
L'iscrizione alla lista degli utenti utilizzatori (FLUKAuser) è attivata in modo automatico al
momento della registrazione.
Oltre a questi dati viene richiesta una password che verrà utilizzata nella procedura di
autenticazione.
Non viene richiesto l'inserimento di uno username in quanto viene automaticamente generato
dal sistema e fornito all'utente tramite l'invio di una email, all'indirizzo di posta elettronica
specificato durante la registrazione.
Il sistema controlla che l'indirizzo di posta elettronica sia unico all'interno dell'archivio dei
dati, in quando è l'unico dato, tra quelli descritti sopra, in grado di verificare se un utente è
già registrato.
Il software viene distribuito in due modalità: pacchetto sorgente e pacchetto compilato. Per
Il sistema preesistente 9
entrambi i tipi sono associati permessi, che vengono concessi sulla base del dominio
dell'indirizzo di posta elettronica, in funzione dell'appartenenza alle liste dei domini consentiti
o proibiti1.
Possono verificarsi tre casi:
– Accesso consentito, se il dominio appartiene alla lista dei domini consentiti.
– Accesso negato, se il dominio appartiene alla lista dei domini proibiti.
– Accesso in stato decisionale, se il dominio non appartiene a nessuna delle due liste. In
questo caso la concessione dei permessi è demandata dell'amministratore del sito. In
questo stato l'utente non ha accesso al sistema.
Nel caso di accesso negato l'utente non verrà inserito nell'archivio dei dati e verrà informato
tramite un messaggio.
L'amministratore del sito può, in qualsiasi momento, cambiare i permessi, bloccando o
abilitando gli utenti registrati.
Il sistema deve memorizzare automaticamente data e ora della registrazione e l'indirizzo IP da
cui è stata effettuata, per un migliore controllo della distribuzione geografica2 degli utenti a
scopo statistico.
Ogni utente che intende modificare o cancellare il proprio profilo deve richiederlo
espressamente all'amministratore del sito il quale eseguirà manualmente la cancellazione o la
modifica richiesta.
1 Per ottenere i permessi di scaricare i pacchetti sorgenti sono necessari requisiti aggiuntivi che possono essere ottenuti contattando direttamente l'amministratore, il quale approverà o respingerà la richiesta.
2 Per distribuzione geografica degli indirizzi si intende solo la nazione, ricavata attraverso l'utilizzo del sistema DNS e dei database RIPE[3]
Il sistema preesistente 10
1.2 Gestione dati
In questo sottocapitolo verrà presentato in maniera dettagliata il sistema di acquisizione,
gestione e mantenimento dei dati preesistente sul server web. Nella Sezione 1.2.1 verrà
presentata l'archivio dei dati in formato testo, mentre nella Sezione 1.2.2 verra descritto il
funzionamento delle funzionalità offerte dal sistema.
1.2.1 L'archivio dei dati
L'archivio dei dati è in formato testo semplice e suddivisa in diversi file, uno per ogni utente
nominato in base allo username. Al suo interno sono contenuti i dati relativi ad uno specifico
account nel seguente formato: nome_campo separatore3 valore, i nomi dei
campi e il loro significato sono descritti nella Tabella 1.1.
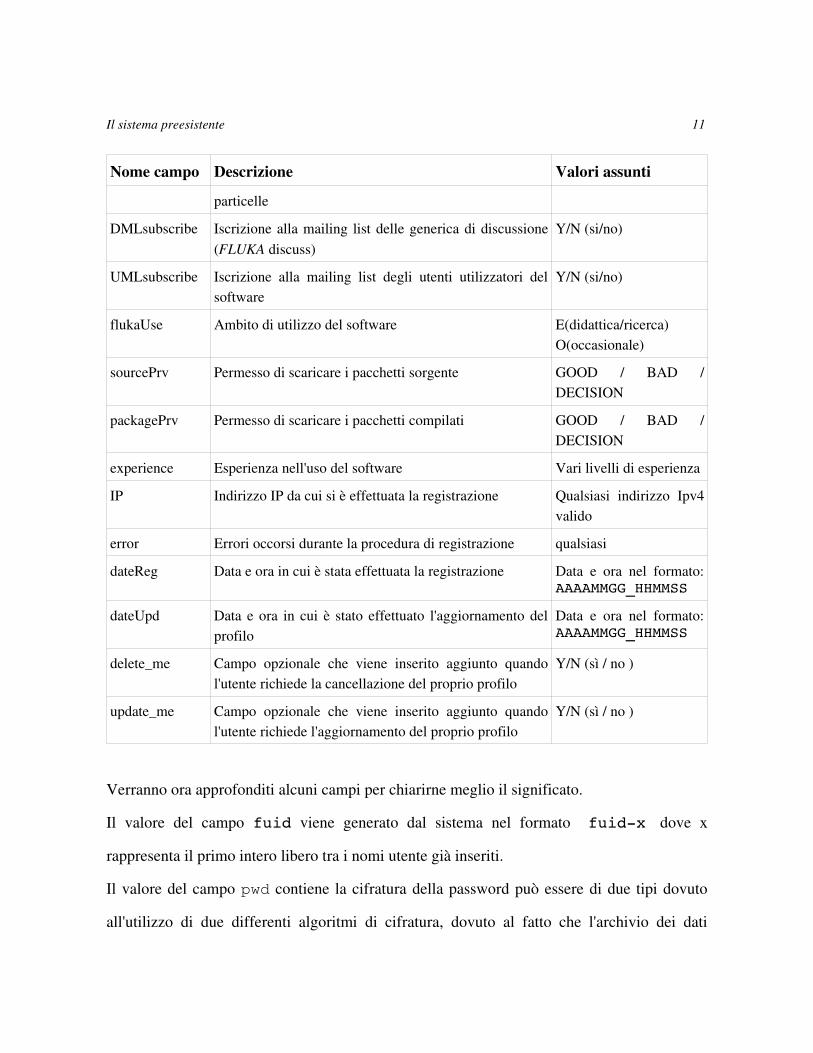
Tabella 1.1: descrizione dei campi dell'archivio dei dati
Nome campo Descrizione Valori assuntifuid Username dell'utente Qualsiasi
pwd Password cifrata Qualsiasi
fname Nome Qualsiasi
lname Cognome Qualsiasi
email Indirizzo di posta elettronica Qualsiasi indirizzo di posta elettronica valido
affiliation Ente, laboratorio o azienda presso cui lavora l'utente Qualsiasi
interests Interessi nell'ambito dei settori della fisica della Qualsiasi
3 Nel caso specifico il separatore è rappresentato dal carattere '='.
Il sistema preesistente 11
Nome campo Descrizione Valori assuntiparticelle
DMLsubscribe Iscrizione alla mailing list delle generica di discussione (FLUKA discuss)
Y/N (si/no)
UMLsubscribe Iscrizione alla mailing list degli utenti utilizzatori del software
Y/N (si/no)
flukaUse Ambito di utilizzo del software E(didattica/ricerca) O(occasionale)
sourcePrv Permesso di scaricare i pacchetti sorgente GOOD / BAD / DECISION
packagePrv Permesso di scaricare i pacchetti compilati GOOD / BAD / DECISION
experience Esperienza nell'uso del software Vari livelli di esperienza
IP Indirizzo IP da cui si è effettuata la registrazione Qualsiasi indirizzo Ipv4 valido
error Errori occorsi durante la procedura di registrazione qualsiasi
dateReg Data e ora in cui è stata effettuata la registrazione Data e ora nel formato: AAAAMMGG_HHMMSS
dateUpd Data e ora in cui è stato effettuato l'aggiornamento del profilo
Data e ora nel formato: AAAAMMGG_HHMMSS
delete_me Campo opzionale che viene inserito aggiunto quando l'utente richiede la cancellazione del proprio profilo
Y/N (sì / no )
update_me Campo opzionale che viene inserito aggiunto quando l'utente richiede l'aggiornamento del proprio profilo
Y/N (sì / no )
Verranno ora approfonditi alcuni campi per chiarirne meglio il significato.
Il valore del campo fuid viene generato dal sistema nel formato fuidx dove x
rappresenta il primo intero libero tra i nomi utente già inseriti.
Il valore del campo pwd contiene la cifratura della password può essere di due tipi dovuto
all'utilizzo di due differenti algoritmi di cifratura, dovuto al fatto che l'archivio dei dati
Il sistema preesistente 12
contiene anche utenti registrati attraverso l'interfaccia di una versione precedente del sito
web.
Entrambi gli algoritmi sono usati dal web server Apache per criptare le password utilizzate
per il processo di autenticazione ad aree protette del file system del server, attraverso
l'utilizzo di htaccess4
I valori contenuti nei campi sourcePrv e packagePrv rispecchiano i tre tipi di permessi
descritti nei requisiti. GOOD significa che l'utente ha il permesso di scaricare il tipo di
pacchetto, BAD l'utente non possiede il permesso5, DECISION, l'indirizzo mail dell'utente
non appartiene né ai domini consentiti né a quelli proibiti.
Il campo interests può avere due formati a causa una diversa procedura di registrazione
nelle precedenti versioni del sito internet che lasciava totale libertà all'utente di inserire i
propri interessi nell'abito della fisica. Al fine di compiere un'indagine statistica sugli ambiti di
interesse di ciascun utente registrato, è stata limitata la scelta a un numero finito di settori
della fisica. Nel secondo caso ad ogni interesse è associata una stringa univoca, più interessi
sono separati da caratteri separatori (nel caso specifico “ | ”).
1.2.2 Il sistema di distribuzione del software
L'accesso al sistema di distribuzione del software avviene collegandosi al sito web dal quale
4 Il web server Apache (nello specifico la versione 2.0) permette di creare delle sottodirectory protette il cui accesso è riservato solo agli utente correttamente autenticati e autorizzati. Questo sistema è descritto dettagliatamente alla pagina internet “http://httpd.apache.org/docs/2.0/howto/htaccess.html”. Nei file htaccess specificano tra le sue direttive il nome del file delle password utilizzate per l'autenticazione.
5 Il valore BAD è predefinito per il campo sourcePrv, mentre può essere assunto dal campo packagePrv solo se l'amministratore volesse bloccare un particolare utente.
l'utente utilizzatore può eseguire le seguenti procedure:
– registrazione di un nuovo utente
– autenticazione e autorizzazione degli accessi all'area personale
– visualizzazione del profilo personale
– distribuzione del software
– gestione della lista utenti da parte dell'amministratore
Procedura di registrazione
Dopo che l'utente ha confermato l'inserimento dei dati tramite internet browser, il server
elabora i dati richiesti ed esegue le seguenti operazioni:
– analisi della correttezza dei dati inseriti
– ricerca nell'archivio dei dati per verificare che l'indirizzo di posta elettronica non sia già
presente, e nel caso lo fosse, l'utente verrà informato attraverso un messaggio
– verifica dell'esistenza del dominio dell'indirizzo di posta elettronica tramite analisi dei
record DNS
– verifica dei permessi, basandosi sull'indirizzo di posta elettronica. Se risulta all'interno
della lista proibita allora verrà notificato all'utente tramite un messaggio
– ricerca nell'archivio dei dati per la generazione del nome utente (si veda la descrizione del
campo fuid nella sezione precedente )
– inserimento dei dati se nessun errore è occorso durante le precedenti verifiche e
salvataggio di tutti i dati contenuti
– aggiornamento del file delle password delle aree protette nelle quali sono presenti i
pacchetti scaricabili se l'utente ha ottenuto i permessi
Il sistema preesistente 14
– gestione della lista utenti da parte dell'amministratore
Al termine della registrazione l'utente viene informato del risultato della procedura. Se tutte le
operazioni sono state eseguite con successo l'account è stato inserito nell'archivio dei dati. Il
permesso di scaricare i pacchetti software viene concesso, come già detto in precedenza, solo
se il dominio dell'indirizzo di posta elettronica appartiene alla lista dei domini consentiti,
altrimenti la decisione di abilitare o disabilitare l'accesso all'area download viene demandata
all'amministratore.
Il permesso di scaricare i pacchetti sorgente viene negato a tutti i nuovi utenti registrati.
Coloro i quali dovessero essere interessati ai sorgenti dovranno inviare una richiesta via mail
all'amministratore, chiedendone l'abilitazione.
Procedura di autenticazione e autorizzazione
La procedura ricerca i dati all'interno dell'archivio dei dati ottenendo la password cifrata e
viene confrontata con la cifratura della password inserita, se le due password sono identiche
allora l'accesso viene autorizzato altrimenti viene visualizzato un messaggio di errore
opportuno.
Questa procedura è riservata esclusivamente agli utenti registrati attraverso la nuova
interfaccia di registrazione.
Procedura di visualizzazione del profilo personale
Ogni utente può visualizzare i dati del proprio profilo previo accesso all'area personale
tramite la procedura di autenticazione e autorizzazione descritta sopra. Da quest'area è
possibile richiede la modifica dei dati oppure la cancellazione dell'account personale.
Il sistema preesistente 15
Procedura di distribuzione del software
I pacchetti software si trovano in specifiche cartelle sul file system del server, protette
dall'accesso di utenti non autorizzati. Da web browser si accede alla pagina di download dei
pacchetti, cliccando sul nome del file, si effettua una richiesta HTTP6 al server all'area
protetta dove è mantenuto il file.
In risposta il server richiede l'autenticazione per l'accesso e automaticamente il browser apre
all'utente un finestra popup nella quale viene richiesto l'inserimento di username e password.
Si invia così una seconda richiesta HTTP al server il quale autorizza o nega l'accesso7 a tale
area e di conseguenza l'utente potrà iniziare il download del file richiesto.
Gestione della lista utenti da parte dell'amministratore
L'amministratore ha la possibilità di visualizzare la lista degli utenti registrati accedendo alla
perte amministrativa del sito web. Da tale selezione è possibile visualizzare tutti gli utenti
contenuti nell'archivio dei dati oppure effetture ricerche scegliendo tra un ristretto numero di
possibilità, non personalizzabili dell'amministratore, esempio: tutti gli utenti registrati nelle
ultime ventiquattro ore oppure tutti gli utenti in stato decisionale.
Dopo aver visualizzato la lista è possibile accedere al profilo del singolo utente
modificandolo o eliminandolo, secondo quanto richiesto dall'utente stesso oppure secondo le
esigenze dell'amministratore.
6 Alla prima richiesta HTTP il web server risponde con il codice 401 che significa “richiesta di autorizzazione” all'area protetta [4]
7 Alla seconda richiesta HTTP viene aggiunta l'opzione Authorization con i valori username e password codificati in base64. Il server risponde con codice 200 se è autorizzato altrimenti risponde ancora con codice 401.
Il sistema preesistente 16
1.3 Nuovi requisiti
Il gruppo di ricerca ha espresso la necessità di acquisire nuovi dati, con l'obiettivo di
aumentare il controllo sull'operato degli utenti e sulla distribuzione del software.
Il gruppo di ricerca ha evidenziato un forte interesse all'analisi statistica dei dati.
Il sistema dovrà tenere traccia dei download effettuati con successo da un particolare utente,
memorizzando data e ora del completamento, l'indirizzo IP da cui è stato effettuato, che file è
stato richiesto e data ora di creazione del file sul server, per distinguere le varie versioni del
singolo pacchetto a parità di nome.
Sono state richieste maggiori informazioni utilizzando l'indirizzo IP, ricavandone il nome
dell'host nella rete, a quale ente, organizzazione o azienda appartiene e in quale nazione si
trova sfruttando i database RIPE e il servizio DNS.
Per aumentare la sicurezza e il controllo dell'accesso all'area download, il sistema dovrà
tenere traccia dell'ultimo accesso effettuato con successo da parte dell'utente,
memorizzandone data e ora.
Capitolo 2 17
Capitolo 2
Progettazione dell'applicazione e della base di dati
In questo capitolo verranno analizzate le criticità del sistema presentato nel capitolo
precedente e verranno proposte soluzioni alternative riprogettando o integrando i moduli già
presenti.
L'analisi delle criticità è presentata nel Sottocapitolo 2.1.
Nei Sottocapitoli successivi verrà descritta in dettaglio la progettazione dell'applicazione e
della base di dati a supporto.
2.1 Analisi delle criticità
Nella Sezione 2.3.1 verranno esposte le criticità relative alla base di dati, mentre nella
Sezione 2.3.2 quelle relative al sistema nel suo complesso.
2.1.1 La base di dati
Una base di dati realizzata come descritto nella Sezione 1.2.1, se da un lato, permette un
facile ampliamento del numero di campi contenuto all'interno nel singolo file data la struttura
Progettazione dell'applicazione e della base di dati 18
molto semplice, dall'altro risulta molto onerosa la progettazione di procedure che la
interroghino, soprattutto in funzione delle nuove esigenze del gruppo di ricercatori (vedi
Sottocapitolo 1.1). La difficoltà nella creazione di codice che elabori i dati, sta nel fatto che
ogni campo deve essere interpretato dal suo valore in stringa al suo significato semantico, per
poter effettuare così confronti oppure analisi statistiche. Si creerebbero così delle procedure
ad hoc per ogni richiesta differente, minimizzando la riusabilità del codice e con prestazioni
medie inferiori rispetto all'utilizzo di una base di dati relazionale.
2.1.2 L'applicazione
La procedura di distribuzione dei pacchetti software, presentata nel precedente sottocapitolo,
risulta incapace di soddisfare la richiesta del gruppo di ricercatori di avere un controllo
dettagliato sugli scaricamenti. Non esiste, nell'implementazione attuale, una procedura in
grado di verificare se un download è stato completato con successo e da quale host nella rete
internet è stato effettuato. Queste informazioni risiedono esclusivamente nei file di log del
server web Apache8, la cui lettura e analisi9 risulta molto onerosa.
Nell'attuale sistema solo agli utenti registrati attraverso il nuovo sito è consentito l'accesso
all'area di visualizzazione del profilo personale. La procedura di autorizzazione è in grado di
verificare le credenziali degli utenti che utilizzano la password cifrata con il nuovo algoritmo.
L'amministratore del sito può effettuare solo un numero limitato di ricerche all'interno della
8 Per la struttura dettagliata e personalizzabile dei file di log del server web Apache sito internet “http://httpd.apache.org/docs/2.0/logs.html”
9 Per verificare se un utente ha effettuato il download con successo è necessario osservare i seguenti campi del file di log: nome dell'utente remoto, richiesta GET HTTP, numero di byte inviati nella risposta, codice della risposta. Il numero di byte deve essere uguale alla dimensione del file e il codice di di risposta deve essere 200.
mail_address Contiene l'indirizzo mail specificato al momento della
registrazionefname Nome dell'utentelname Cognome dell'utente
experience Esperienza nell'uso del softwareaffiliation Organizzazione presso cui l'utente è ospitatofluka_use Tipo di utilizzo del software
dml_subscribe Iscrizione alla mailing list delle generica di discussione (FLUKA
discuss) uml_subscribe Iscrizione alla mailing list degli utenti utilizzatori di FLUKAsource_prv Privilegi di scaricare pacchetti in formato sorgentepackage_prv Privilegi di scaricare pacchetti in formato compilato
status Stato dell'utentedate_registration Data e ora di registrazione dell'utente
date_update Data e ora di modifica del profilo utentelast_access Data e ora dell'ultimo accesso autenticato al sistema ( si vedano le
specifiche capitolo xxx)
Tabella 2.1: descrizione entità USER
Il campo status è stato introdotto per condensare il significato dei campi update_me e
delete_me della Tabella 1.1, e della stato dell'utente, DECISION o GOOD, dopo la
registrazione. Tale scelta è basata sul fatto che l'assunzione di uno dei valori escluda
Progettazione dell'applicazione e della base di dati 21
automaticamente gli altri.
La conseguenza di questo cambiamento comporta che i campi source_prv e
package_prv assumono solo valori booleani.
L'entità INTEREST completa il quadro dell'utente e rappresenta i suoi interessi nell'ambito
di settori della fisica. Viene descritta nella tabella 2.2
Attributo DescrizioneName_interst Identificatore debole dell'entità e rappresenta un interesse in ambito fisico
dell'utente
Tabella 2.2: descrizione dell'entità INTEREST
L'entità HOST,che specifica un particolare host nella rete internet, è descritta nella tabella 2.3
Attributo DescrizioneIP Identificatore dell'entità rappresentante indirizzo IP
Name_Host Nome dell'host tramite risoluzione DNSAffiliation Nome dell'organizzazione presso cui l'host risiedeCountry Paese di appartenenza
Tabella 2.3: descrizione dell'entità HOST
L'entità DOWNLOAD,descrive un download avvenuto con successo da parte di uno specifico
utente da un particolare host in un preciso istante temporale con granularità di un secondo.
Tale entità è descritta nella tabella 2.4.
Progettazione dell'applicazione e della base di dati 22
Tutte le associazioni dello schema ER sono di cardinalità uno a molti, da cui segue che gli
attributi chiave nelle entità con cardinalità maggiore, nell'associazione considerata, vengano
aggiunti all'insieme di attributi dell'entità con cardinalità minore e venga creato un vincolo di
integrità referenziale tra i campi delle due tabelle relazionali, ad esempio l'attributo
Register_Host della tabella USER si riferisce alla chiave della tabella HOST.
Progettazione dell'applicazione e della base di dati 24
2.3 Progettazione dell'applicazione web
In questo sottocapitolo verrà presentata la progettazione dell'applicazione web mostrandone
le funzionalità, descrivendo le modifiche progettuali apportate al vecchio sistema,
specificando quali funzionalità sono state ridisegnate e quali solo modificate, in funzione dei
nuovi requisiti descritti nel Sottocapitolo 1.1.
Le funzionalità del sistema sono descritte dal diagramma degli Use Case UML in Figura 2.2
per l'utente utilizzatore e in Figura 2.3 per l'amministratore.
L'autenticazione è stata completamente riprogettata per rendere possibile l'accesso anche ai
vecchi utenti e soddisfare il requisito di conoscenza dell'ultimo accesso autenticato
dell'utente. Con l'obiettivo di uniformare l'accesso alle aree protette del sito web,
l'autenticazione è necessaria per accedere alla sezione di download dei file oltre che
all'accesso al profilo personale, come già avveniva nel precedente sistema (vedi Sezione
1.2.2).
Figura 2.2: Use Case utente
Progettazione dell'applicazione e della base di dati 25
La visualizzazione del profilo personale e registrazione da parte dell'utente sono state
modificate nella parte relativa all'interazione con la base di dati. Il cambiamento di tipologia
di base di dati ha comportato una rivisitazione della struttura cambiando il modulo di
interfaccia, passando dall'archivio di dati in formato testo alla base di dati utilizzando un
sistema DBMS.
Lo scaricamento pacchetti è stato riprogettato al fine di verificare il completamento del
download da parte di uno specifico utente. Per soddisfare questo requisito il modulo si occupa
direttamente della distribuzione del pacchetto, potendo così monitorare l'avvenuto successo
dello scaricamento. In fase di progettazione di questa funzionalità sono state considerate
diverse ipotesi senza dover ricorrere alla già esistente lettura integrale di file di log. Una della
prime idee è stata considerare lo scaricamento di un pacchetto da parte di un utente prima di
inviarlo, inserendo i dati prima dell'effettiva operazione di download dal server. Tale
soluzione è però inefficace ai fini dei requisiti, in quando un download non completato non
viene distinto da uno avvenuto con successo. La soluzione adottata è risultata efficace
riuscendo a distinguere nettamente i download completati da quelli falliti ( si veda il Capitolo
Figura 2.3: Use Case amministratore
Progettazione dell'applicazione e della base di dati 26
3 per l'implementazione di questa funzionalità).
Il nuovo sistema, soprattutto per la parte riguardante l'utente utilizzatore del software, è stato
progettato in modo tale da non stravolgere l'utilizzo dell'applicazione web alla quale l'utente
era già abituato. In caso di sostanziale cambiamento sono stati previsti appositi messaggi atti
a guidare l'utente all'utilizzo della nuova funzionalità.
Nella parte amministrativa dell'applicazione sono state introdotte due nuove funzionalità:
ricerca avanzata e sincronizzazione con il vecchio archivio dei dati.
La ricerca avanzata è stata introdotta per soddisfare le richieste di analisi statistiche sui dati
degli utenti registrati. La sua progettazione è tale da risultare dinamica e flessibile ad aggiunte
future di nuovi dati di interesse e presuppone l'esistenza di una base di dati relazionale. Il
modulo prevede una componente in grado di generare automaticamente query da sottoporre
alla base di dati in funzione degli specifici dati richiesti dall'amministratore, selezionati
attraverso un'intuitiva schermata di ricerca.
La funzionalità di sincronizzazione della base di dati è stata progettata per permettere la
conversione dei valori dei campi della vecchia base di dati nel nuovo formato. Durante la fase
di progettazione di questa funzionalità si è assunto che il vecchio archivio dei dati fosse
coerente e non contenesse errori nel formato dei campi. Qualora in fase di analisi dei dati
siano state incontrate incongruenze sono state immediatamente risolte contattando
direttamente l'amministratore del sistema.
Capitolo 3 27
Capitolo 3
Sviluppo dell'applicazione web e della base di dati
In questo capitolo verrà descritto in maniera dettagliata lo sviluppo dell'applicazione relativo
alle parti modificate o completamente reimplementate dell'applicazione preesistente,
rispecchiando le decisioni progettuali descritte nel capitolo precedente.
Nel Sottocapitolo 3.1 verranno presentate brevemente le tecnologie utilizzate motivandone il
loro impiego. Nel Sottocapitolo 3.2 verra descritta l'implementazione fisica della base di dati
presentata nel capitolo precedente. Nel Sottocapitolo 3.3 verranno descritti dettagliatamente i
moduli software realizzati focalizzando l'attenzione sulle scelte implementative effettuate.
3.1 Tecnologie utilizzate
La scelta delle tecnologie è stata fatta in accordo con i software già installati e configurati sul
sistema del web server di FLUKA. Il sistema operativo è una distribuzione Linux, nello
specifico Red Hat Enterprise[5] sulla quale è installato Apache 2.0[6] come server web. Il
sito internet è sviluppato in PHP 5[7] e JavaScript[8] (nella sola parte riguardante il modulo
di ricerca avanzata).
Il sito web sfrutta entrambi i protocolli HTTP[4] e HTTPS[9] utilizzando il secondo nelle
aree personali, nell'area dell'amministratore e per l'invio delle credenziali durante la fase di
autenticazione.
Sviluppo dell'applicazione web e della base di dati 28
I nuovi moduli dell'applicazione, dovendo fondersi con i preesistenti, sono stati realizzati con
lo stesso linguaggio, utilizzando le funzioni di libreria standard.
Inoltre sono state installate le seguenti librerie:
– PECL[10] per l'estensione delle funzionalità di gestione del protocollo HTTP
– MCrypt[11] per utilizzare la libreria Mcrypt in PHP10
Per la base di dati è stato utilizzato MySQL 5.0[12] come software DBMS.
L'utilizzo di questi software è in accordo con la filosofia open source11 dell'ente di ricerca
presso cui è stata realizzata l'applicazione.
3.2 Implementazione base di dati
3.2.1 Progettazione fisica
Verranno descritte le tabelle realizzate descrivendo le particolari scelte dei tipi di dato, gli
indici in aggiunta a quelli sulle chiavi primarie e le viste realizzate in funzione delle attività
statistiche e amministrative che verranno svolte.
Tutte le tabelle sono state implementate usando InnoDb[13] come metodo di memorizzazione
su disco di MySQL per consentire di creare e mantenere i vincoli di integrità referenziale dei
dati e quindi la consistenza interna nella base di dati.
Tabella Host
10 La libreria Mcrypt di PHP necessita che sia installato il pacchetto di sistema libmcrypt. 11 Per la definizione di “open source” si rimanda al seguente sito: “http://it.wikipedia.org/wiki/Open_source”.
Sviluppo dell'applicazione web e della base di dati 29
Codice SQLCREATE TABLE Host ( ip varchar(50) PRIMARY KEY,
name_host varchar(60), affiliation varchar(1000), country varchar(60)) ENGINE = InnoDb;
Tabella 3.1: codice della definizione della tabella Host
L'attributo ip è stato dimensionato per tenere conto della rappresentazione IPv6 degli
indirizzi, allo stato attuale il web server utilizza IPv4, ma in un futuro potrebbe registrare gli
indirizzi nella nuova versione del protocollo ip, come già fanno alcune utility di rete presenti
del server.
Tabella User
Codice SQLCREATE TABLE User ( fuid varchar(20) PRIMARY KEY,
pwd varchar(100) NOT NULL, f_name varchar(30) NOT NULL, l_name varchar(30) NOT NULL, mail_address varchar(100) UNIQUE NOT NULL, experience varchar(30) NOT NULL, affiliation varchar(100) NOT NULL, fluka_use varchar(60) NOT NULL, dml_subscribe char(1), uml_subscribe char(1), source_prv varchar(20) NOT NULL, package_prv varchar(20) NOT NULL, status varchar(20) NOT NULL, date_registration datetime NOT NULL, date_update datetime, last_access datetime, ip varchar(50),
Tabella 3.3: codice della definizione della tabella Interest
Tabella Download
Codice SQLCREATE TABLE Download (id serial PRIMARY KEY,
date_time datetime NOT NULL, file varchar(40) NOT NULL, date_creation_file datetime NOT NULL, fuid varchar(20) NOT NULL,ip varchar(50) NOT NULL,FOREIGN KEY(fuid) REFERENCES User(fuid),
Tabella 3.6: codice della definizione della vista view_state_decision
La vista rappresenta tutti gli utenti cui lo stato di registrazione è uguale a DECISION, per il
significato di tale stato si vedano specifiche Sottocapitolo 1.1 , riportando gli attributi che lo
identificano e l'informazione completa riguardo all'host da cui ha effettuato la richiesta di
registrazione. L'importanza di questa informazione è rilevante per l'amministratore del sito.
Vista view_download_stat
Codice SQLCREATE VIEW view_download_stat ASSELECT YEAR(date_time) AS year, MONTH(date_time) AS month, COUNT(*) AS total, COUNT(DISTINCT fuid) AS
user_unique_download FROM DownloadGROUP BY YEAR(date_time),MONTH(date_time);ORDER BY YEAR(date_time) ASC,MONTH(date_time) ASC
Tabella 3.7: codice della definizione della vista view_download_stat
In questa vista vengono rappresentate le quantità, divise per anno e per mese, dei download
effettuati.
Si considerano due quantità: tutti i download effettuati in uno specifico mese di uno specifico
anno e nello stesso periodo si contano quanti utenti hanno scaricato, descritta in SQL da
COUNT(DISTINCT fuid).
Sviluppo dell'applicazione web e della base di dati 32
Vista view_registration_stat
Codice SQLCREATE VIEW view_registration_stat AS
SELECT YEAR(date_registration) AS year,MONTH(date_registration) AS month, COUNT(*)as total
FROM UserWHERE status<>'DECISION'GROUP BY YEAR(date_registration),MONTH(date_registration)ORDER BY YEAR(date_registration) ASC,MONTH(date_registration)
ASC;
Tabella 3.8: codice della definizione della vista view_registration_stat
La vista rappresenta la quantità di registrazioni avvenute divise per anno e per mese. Gli
utenti devono essere in uno stato diverso da DECISION perchè come da specifiche l'utente
non è considerato registrato se è in questo stato.
Funzione read_interest
Il codice della funzione read_interest è descritto nella tabella 3.9
CREATE DEFINER = 'site_admin'@'localhost' FUNCTION read_interest(user VARCHAR(20)) RETURNS VARCHAR(2000) BEGIN
DECLARE num INT DEFAULT 0; DECLARE end_rows INT DEFAULT 0; DECLARE user_int VARCHAR(2000) DEFAULT ''; DECLARE temp_int VARCHAR(100); DECLARE cur CURSOR FOR SELECT name_interest
FROM Interest where fuid = user;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET end_rows = 1; scansiono gli interessi OPEN cur ; REPEAT
SET temp_int=''; FETCH cur INTO temp_int; aggiungo il carattere separatore solo se non è il primo elemento IF num > 0 THEN
SET user_int = CONCAT(user_int,'|'); END IF; concatenazione col nuovo interesse trovato SET user_int= CONCAT(user_int,temp_int); SET num = num+1;
Sviluppo dell'applicazione web e della base di dati 33
UNTIL end_rows END REPEAT; CLOSE cur; RETURN user_int;
END;
Tabella 3.9: codice della funzione read_interest()
Questa funzione viene utilizzata dall'applicazione web per la visualizzazione del profilo
utente. Preleva tutti gli interessi dell'utente specificato in argomento e restituisce una stringa
contenente tutti gli interessi divisi da un separatore (” | ” nel codice).
3.2.2 Sicurezza
L'accesso alla base di dati è consentito solo a due tipi di utenti: amministratore della base di
dati e amministratore del sito web, che sono a tutti gli effetti utenti del DBMS.
L'amministratore della base di dati
Questo tipo di utente ha il completo controllo sulla base di dati. L'utilizzo di questo utente
deve essere limitato solo in casi in cui è necessario alterare la struttura del database, è
fortemente sconsigliato l'utilizzo di questo tipo di utente per interagire12 col sito internet, per
evitare che errori di programmazione all'interno del codice del sito web comportino
alterazioni strutturali nella base di dati.
L'amministratore del sito web
Possiede permessi limitati alla gestione dei dati (inserimento, modifica, aggiornamento e
12 L'interazione tra sito web realizzato in PHP e il database avviene attraverso una connessione TCP dal web server Apache al server MySQL. Nei parametri della connessione devono essere specificati l'utente e la password con i quali si vole connettersi al server.
Sviluppo dell'applicazione web e della base di dati 34
cancellazione). Inoltre possiede i permessi di esecuzione della funzione read_interest.
Questo tipo di utente può essere utilizzato per l'interazione con il sito web.
L'utente registrato nel sistema non possiede invece alcun utente a livello DBMS, in quanto si
è preferito evitare la creazione di un account per ogni utente con un maggiori restrizioni e
controlli di sicurezza.
L'autenticazione e autorizzazione degli utenti è lasciata alla parte web che verrà descritta nel
successivo sottocapitolo. La sicurezza nel controllo degli accessi è stata spostata a livello
dell'implementazione in PHP del sito web.
3.3 Architettura software
In questo sottocapitolo verranno presentati tutti i moduli realizzati suddivisi in sezioni. Per
ogni modulo verranno descritti funzionalità, interazione tra i moduli e dettagli implementativi
rilevanti.
Le componenti realizzate sono le seguenti:
– modulo di interazione con la base di dati
– modulo di autenticazione (login)
– modulo download pacchetti
– modulo di ricerca avanzata degli utenti
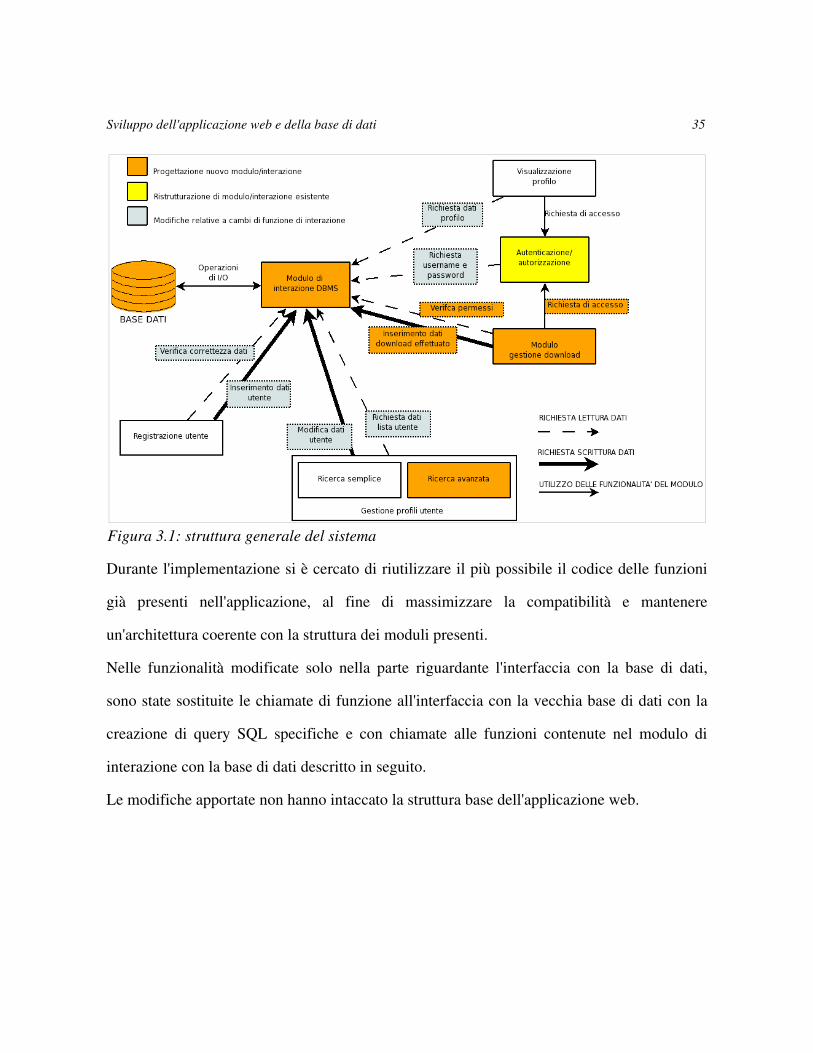
La struttura generale del nuovo sistema e l'interazione tra i moduli sono rappresentate nella
Figura 3.1, che mette in risalto i cambiamenti rispetto al vecchio sistema rappresentato in
Figura 1.1
Sviluppo dell'applicazione web e della base di dati 35
Durante l'implementazione si è cercato di riutilizzare il più possibile il codice delle funzioni
già presenti nell'applicazione, al fine di massimizzare la compatibilità e mantenere
un'architettura coerente con la struttura dei moduli presenti.
Nelle funzionalità modificate solo nella parte riguardante l'interfaccia con la base di dati,
sono state sostituite le chiamate di funzione all'interfaccia con la vecchia base di dati con la
creazione di query SQL specifiche e con chiamate alle funzioni contenute nel modulo di
interazione con la base di dati descritto in seguito.
Le modifiche apportate non hanno intaccato la struttura base dell'applicazione web.
Figura 3.1: struttura generale del sistema
Sviluppo dell'applicazione web e della base di dati 36
3.3.1 Interazione base di dati
Questo modulo costituisce l'interfaccia tra la base di dati e l'applicazione web. Tutte le
funzioni implementate in questo modulo vengono richiamate ogni qual volta sia necessario
l'accesso ai dati contenuti all'interno della base di dati.
Le funzionalità implementate sono:
– apertura della connessione con la base di dati
– chiusura della connessione con la base di dati
– esecuzione di query
– esecuzione di una transazione
– sincronizzazione dei dati con la vecchia base di dati
Per lo sviluppo è stato utilizzato il modulo di interfaccia tra PHP e MySQL che è un
componente delle librerie di PHP13.
L'apertura e la chiusura della connessione sono semplici wrapper creati al fine di gestire
potenziali errori che potrebbero occorrere durante l'esecuzione delle funzioni di libreria.
La funzione di esecuzione delle query è in grado di gestire i quattro principali tipi di query di
manipolazione dati: insert, delete, upadate e select. Il flusso di esecuzione è differente a
seconda che sia un'interrogazione alla base di dati oppure inserimento, cancellazione e
modifica dei dati.
La funzione che gestiste l'esecuzione di una transazione14 è stata creata in quanto MySQL
rifiutava una stringa unica contenente tutte le operazioni, che sono infatti inserite all'interno
13 La libreria per la gestione dei database MySQL non è direttamente installata nel core di PHP, ma necessita l'installazione di un pacchetto aggiuntivo vedi pagina internet: “http://it.php.net/manual/en/book.mysql.php”.
14 Una transazione è un programma in esecuzione che forma un'unità logica di elaborazione sulla base di dati. [14]Paragrafo 15.1.2.
Sviluppo dell'applicazione web e della base di dati 37
di un vettore PHP. Tale vettore viene processato sottoponendo al DBMS l'operazione, se
l'esecuzione avviene con successo si continua l'iterazione sul vettore altrimenti viene eseguita
un'operazione di rollback. Se nessun errore è occorso allora viene eseguita un'operazione di
commit. Rollback e commit vengono esplicitamente sottoposte al DBMS tramite codice
PHP.
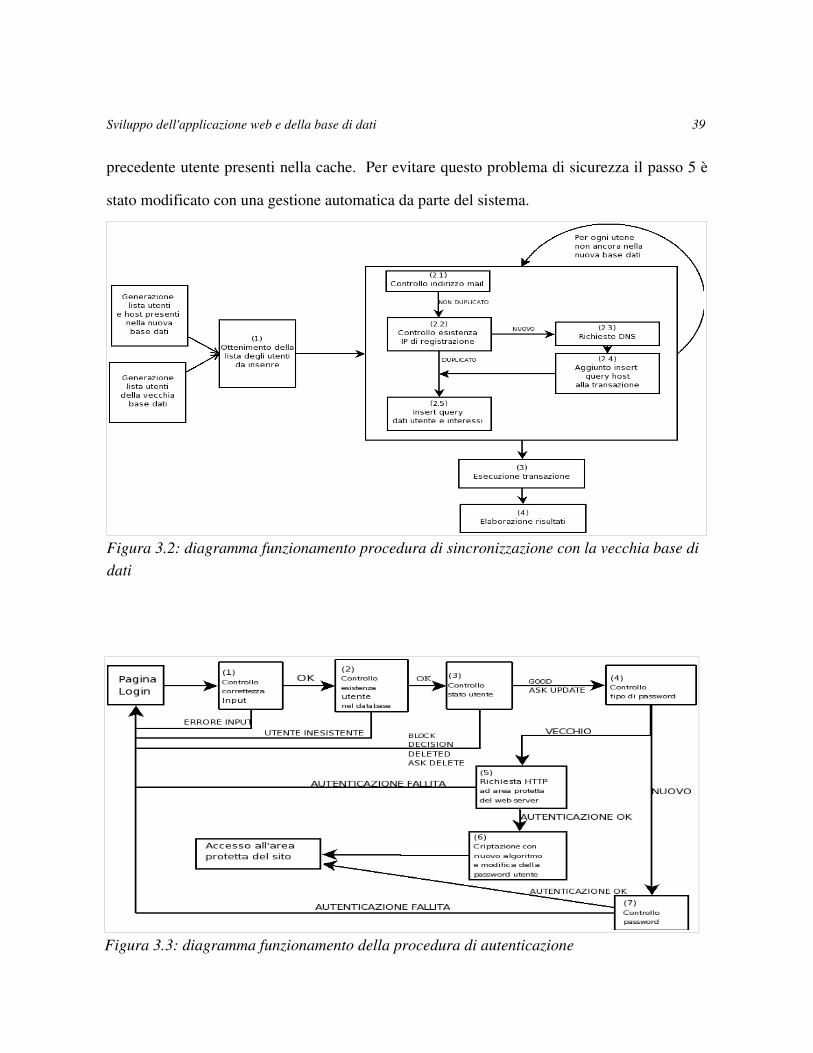
Il funzionamento della funzione di sincronizzazione con la vecchia base di dati è descritto
nella Figura 3.2.
La criticità in termini prestazionali sta nell'invio di due richieste DNS (al passo 2.3) per ogni
nuovo indirizzo IP trovato che richiedono un tempo molto variabile da una richiesta e l'altra,
dipendente dalla presenza nelle cache degli apparati di rete dei record DNS richiesti.
Al passo 2.1 avviene il controllo dell'esistenza dell'indirizzo mail, rispettando quanto detto
nei requisisti, in cui viene specificato che non possono esistere due utenti con lo stesso
indirizzo di posta elettronica (vedi Capitolo 1).
L'elaborazione dei risultati della transazione permette all'amministratore di conoscere il
successo o il fallimento dell'operazione, il tempo impiegato per eseguire la sincronizzazione,
il numero di nuovi utenti trovati e quanti effettivamente inseriti per via dei possibili duplicati
di mail.
L'implementazione suppone che la base di dati da cui vengono estratti i dati sia coerente e che
i formati dei campi siano quelli documentati alla Sezione 1.2.1. L'ordine con cui vengono
inserite le query all'interno del vettore della transazione è fondamentale per garantire
l'integrità referenziale tra le tabelle della base di dati (si veda Sezione 2.2.2).
3.3.2 Procedura di autenticazione
Sviluppo dell'applicazione web e della base di dati 38
La procedura consente ad un utente di autenticarsi al sistema fornendo le proprie credenziali
tramite form web. L'autenticazione viene gestita attraverso una pagina non accessibile
all'utente per motivi di sicurezza. Tale pagina richiama l'effettiva procedura di autenticazione
che è descritta nella Figura 3.3. Se l'autenticazione è avvenuta con successo si procede con
l'aggiornamento dei dati dell'ultimo accesso e il settaggio delle variabili di sessione15. Al
passo 4 la procedura verifica il tipo di password attivando 2 differenti metodi di controllo
della password. Se si tratta del nuovo tipo semplicemente controlla la password con quella
presente nella base di dati, se invece il tipo è vecchio il sistema effettua una richiesta HTTP
ad una zona protetta usando i file htaccess di Apache16( passo 5 ). Se l'accesso viene
autorizzato la password viene cifrata col nuovo algoritmo e vengono modificati i dati
dell'utente ( passo 6 ).
Questa implementazione permette di avere un gestione trasparente dell'accesso di vecchi e
nuovi utenti, durante la realizzazione del sistema il passo 5 non era eseguito dal sistema, ma
era semplicemente gestito tramite una redirezione alla zona protetta. All'utente compariva una
finestra popup nella quale veniva richiesto il reinserimento di username e password. Una
volta inserite le credenziali queste venivano memorizzate nella cache del browser fino alla
sua chiusura. In caso di accesso dallo stesso browser di utenti differenti ( sempre di vecchio
tipo ) le credenziali che venivano passate erano quelle presenti nella cache, senza la
visualizzazione della finestra popup, questo comportava che ai passi 2 l'utente si presentava
con le credenziali inserite nel form web, invece al passo 5 si presentava con le credenziali del
15 Le variabili di sessione impostate sono: validUser ( a valori boolean indica utente valido autenticato) e userName(username dell'utente autenticato).
16 Vedi nota 7 per l'utilizzo di HTTP e nota 4 per le zone protette del web server Apache.
Sviluppo dell'applicazione web e della base di dati 39
precedente utente presenti nella cache. Per evitare questo problema di sicurezza il passo 5 è
stato modificato con una gestione automatica da parte del sistema.
Figura 3.3: diagramma funzionamento della procedura di autenticazione
Figura 3.2: diagramma funzionamento procedura di sincronizzazione con la vecchia base di dati
Sviluppo dell'applicazione web e della base di dati 40
3.3.3 Modulo download pacchetti software
L'implementazione di questa funzionalità ha due obiettivi: soddisfare i requisiti dei ricercatori
di tenere traccia dei download effettuati con successo e permettere all'utente di continuare la
navigazione all'interno del sito web durante lo scaricamento dei pacchetti.
Nell'applicazione web la persistenza tra le richieste HTTP è gestita tramite le sessioni
PHP[15], permettendo l'identificazione dell'utente che intende effettuare il download tramite
una variabile definita all'interno del vettore di sessione. Una prima implementazione
realizzata riusciva a raggiungere solo il primo dei due obiettivi preposti, infatti l'utente non
riusciva a continuare la navigazione all'interno del sito sino al termine della procedura di
download. Tale problema era dovuto al fatto che qualunque richiesta successiva fatta
dall'utente al web server, veniva riconosciuta come appartenente alla stessa sessione nella
quale era già in esecuzione un'altra richiesta, cioè lo scaricamento del pacchetto e veniva
quindi accodata. Per ovviare a questo problema durante la procedura di download la sessione
PHP è disabilitata, rendendo cosi' ogni richiesta di download indipendente dal contenuto della
variabile di sessione. Questa implementazione permette di raggiungere entrambi gli obiettivi,
ma comporta l'introduzione di alcuni accorgimenti di sicurezza che verranno descritti in
seguito.
Il diagramma di funzionamento della procedura è descritto nella Figura 3.4.
Sviluppo dell'applicazione web e della base di dati 41
Al passo 1 vengono controllati i permessi dell'utente utilizzando come chiave il valore
contenuto nella variabile di sessione. I problemi di sicurezza sorgono nel momento in cui le
funzionalità della sessione PHP vengono disabilitate, in quanto ogni richiesta è anonima (nel
senso che non appartiene a nessun utente che ha effettuato la procedura di autenticazione) e
quindi chiunque potrebbe richiedere il download del file, costruendo una richiesta HTTP ad
hoc, vanificando cosi' la sicurezza introdotta dalla procedura di login e dal controllo dei
permessi al passo 1. Per ovviare a questo problema è stato introdotto un campo aggiuntivo al
form, i cui dati sono inviati tramite il metodo POST, della pagina di download (trattasi della
nuova finestra visualizzata dopo il passo 3), che specifica quale utente abbia intenzione di
scaricare il pacchetto. Tali contromisure non bastano in quando il nome utente è visualizzato
in chiaro nel codice della pagina web, quindi i valori dei campi vengono cifrati utilizzando
una cifratura tramite l'uso dell'algoritmo a chiave simmetrica Blowfish[16] utilizzato nella
Figura 3.4: diagramma di funzionamento della procedura di download
Sviluppo dell'applicazione web e della base di dati 42
modalità CFB17. Questa cifratura unita all'utilizzo del protocollo HTTPS[9] consente di
risolvere i problemi di sicurezza esposti sino ad ora. Come ulteriore misura al passo 6
vengono nuovamente controllati i permessi dell'utente, ma differentemente da quanto
avveniva al passo 1, viene usato come chiave il valore contenuto nel parametro di POST.
Al passo 7 avviene il download vero e proprio utilizzando la funzione della libreria
http_send_file della libreria PECL. Se la funzione termina con successo vengono inseriti i dati
all'interno della tabella Download.
3.3.4 Modulo di ricerca avanzata
Questo modulo consente all'amministratore del sistema di effettuare ricerche avanzate sulla
lista degli utenti registrati. Per questa funzionalità è stata realizzata un'interfaccia grafica, con
controllo della correttezza e consistenza degli input lato client realizzato in JavaScript.
Attraverso quest'interfaccia l'amministratore seleziona i campi di interesse rendendo dinamica
e personalizzabile la ricerca di particolari categorie di utenti.
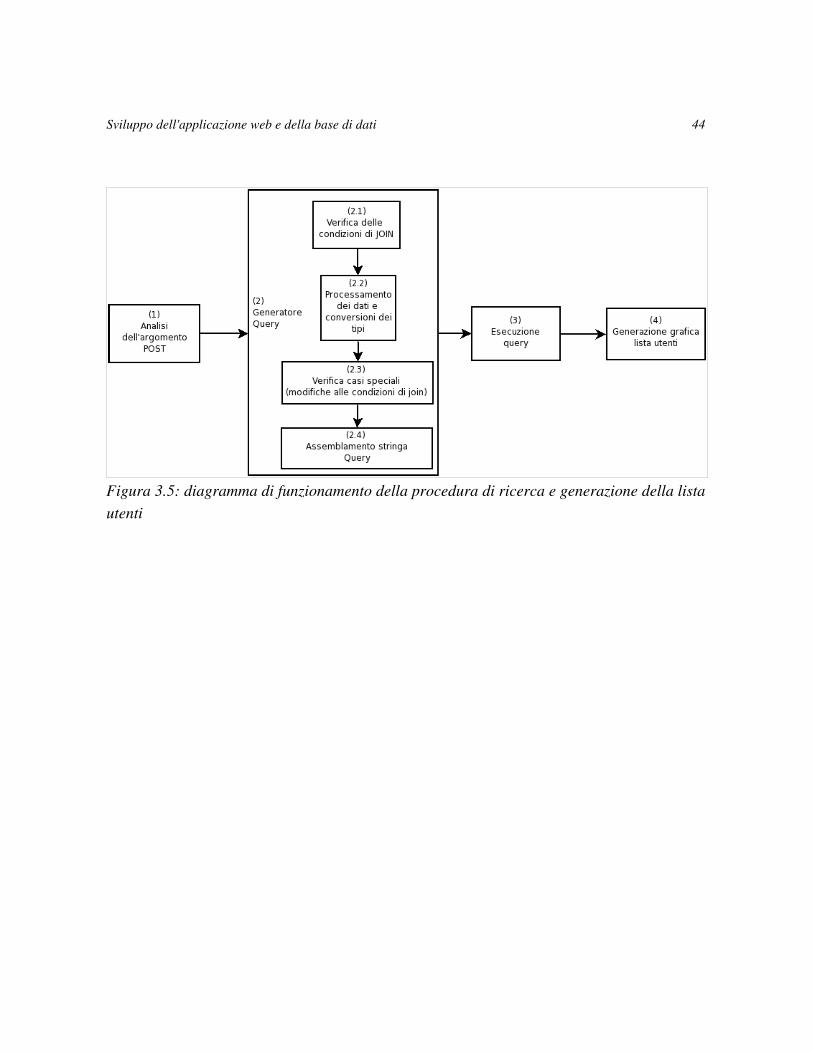
La generazione della lista degli utenti è gestita totalmente dalla procedura descritta nella
Figura 3.5.
Il passo 1 riceve in input l'argomento POST della richiesta HTTP il quale è strutturato in
modo tale da consentire alla procedura di riconoscere quali tabelle e quali campi sono
coinvolti nella ricerca. Tale meccanismo è stato realizzato nominando in modo opportuno i
campi del form HTML di ricerca secondo il seguente formato:
17 CF B acronimo di Cipher Feedback è una delle modalità di cifratura a blocchi per algoritmi a chiave simmetrica.
Sviluppo dell'applicazione web e della base di dati 43
tipo_nomeTabella_nomeCampo, rispettivamente il tipo di box all'interno del form18,
una delle tabelle contenute nella base di dati e nome del campo relativo alla specifica tabella.
In questa fase di implementazione si preferito mantenere indipendenti i nomi presenti nel
form HTML dai nomi presenti nella base di dati. A tale proposito è stato creato un vettore che
funziona da wrapper tra l'applicazione e la base di dati. Il passo 1 al termine dell'esecuzione
restituisce una vettore nel quale sono contenute le tabelle interessate, i campi e i loro valori.
Al passo 2 avviene la generazione effettiva della query SQL secondo i parametri della
ricerca. Riceve in input il risultato del passo 1 e immediatamente verifica le condizioni di join
tra le tabelle interessate, processa i valori dei campi convertendoli nel formato adatto alla
base di dati (essenziale per i campi contenenti valori di data e ora).
Al passo 2.3 si verifica la presenza di casi eccezionali che comportano il cambiamento delle
condizioni di join precedentemente inserite. Durante la fase di testing di questa procedura si è
rivelato necessario gestire un solo caso particolare, cioè il caso in cui l'amministratore scelga
di trovare gli utenti che non hanno effettuato lo scaricamento dei pacchetti, in questo caso la
condizione di where conteneva la seguente stringa “WHERE User.fuid NOT IN
(SELECT fuid FROM Download)” eliminando la condizione di join tra la tabella
User e Download.
Il passo 3 è semplicemente l'esecuzione della query generata al passo precedente utilizzando
le funzioni descritte sopra nella Sezione 3.2.1. Il passo 4 genera il codice HTML della lista
ottenuta processando il risultato dell'esecuzione della query.
18 Di tutti i box esistenti sono stati usati solo checkBox e selectBox guidando quindi l'utente nella selezione dei valori dei campi, facilitando da un lato il controllo di consistenza e dall'altro evitando l'inserimento da parte dell'utente di stringhe arbitrarie.
Sviluppo dell'applicazione web e della base di dati 44
Figura 3.5: diagramma di funzionamento della procedura di ricerca e generazione della lista utenti
Capitolo 4 45
Capitolo 4
Esempi d’uso
In questo capitolo verranno presentati alcuni esempi d'uso dell'applicazione web attraverso
schermate realizzate durante la fase di testing. Le schermate sono state scelte selezionando le
funzionalità che hanno comportato un cambiamento nell'interfaccia web.
4.1 Funzionalità di ricerca avanzata
Nella figura 4.1 è rappresentata la funzionalità di ricerca avanzata effettuata
dall'amministratore realizzata in JavaScript.
Figura 4.1: schermata della ricerca avanzata
Esempi d’uso 46
L'interfaccia risulta semplice, intuitiva e da la possibilità all'amministratore di effetture
ricerche anche articolate utili per monitorare gli utenti.
Il risultato della ricerca effettuata è rappresentato nella Figura 4.2
4.2 Funzionalità di download dei pacchetti software
Nella figura 4.3 rappresenta una schermata dell'area di download pacchetti, l'utente ha già
Figura 4.2: risultato della ricerca
Figura 4.3: pagina di download pacchetti
Esempi d’uso 47
selezionato il pacchetto software e gli è apparsa una finestra dalla quale iniziare lo
scaricamento.
Il messaggio della finestra conferma che l'utente ha i permessi per scaricare questo tipo di
file, in caso contrario l'unica azione possibile sarà la chiusura di tale finestra.
Nella Figura 4.4 è riportato il codice della pagina relativa alla finestra popup nella quale i
campi nascosti del form HTML sono cifrati.
4.3 Funzionalità di sincronizzazione con il vecchio archivio dei dati
Nella Figura 4.5 è rappresentato il risultato della funzione di sincronizzazione tra la vecchia e
la nuova base di dati. Viene riportato nella schermata di output il risultato di successo o
fallimento, quanti nuovi utenti sono stati trovati, quanti inseriti e quanti indirizzi mail
duplicati sono state travati. Per la parte riguardante la tempistica di esecuzione si noti l'elevata
differenza tra la generazione della transazione rispetto alla sua esecuzione, dovuta alle
richieste DNS effettuate duranti la sua creazione.
Figura 4.4: codice HTML della pagina
Esempi d’uso 48
Figura 4.5: risultato della procedura di sincronizzazione
49
Conclusioni e sviluppi futuri
La realizzazione del modulo di ricerca avanzata ha soddisfatto le esigenze di ottenimento di
maggiori dati statistici ai fini della comprensione della diffusione del software di simulazione
FLUKA, per ottimizzarne i contenuti.
Con il sistema realizzato è ora possibile controllare la distribuzione dei pacchetti risalendo
all'utente che ha effettuato il download, da quale indirizzo IP e che pacchetto ha richiesto,
attraverso la gestione dei dati dello scaricamento da parte del sistema.
Attraverso la nuova procedura di autenticazione tutti gli utenti, anche quelli con il vecchio
tipo di password, possono accedere alle stesse funzionalità rendendo cosi' omogenea 'utilizzo
del sito. Inoltre la gestione delle differenze di password avviene in maniera trasparente
all'utente, evitando possibili difficoltà di comprensione nell'utilizzo dell'applicazione.
Il lavoro svolto è ora autosufficiente e rappresenta una nuova release del sistema che è
utilizzabile da subito. I ricercatori stanno valutandolo in fase di test per una introduzione in
produzione a breve.
Tra i miglioramenti futuri, si potrebbero realizzare strumenti atti ad automatizzare la
generazione di statistiche, attraverso la creazione di moduli che gestiscano la creazione
automatica di grafici sfruttando i dati contenuti nella base di dati. La progettazione di tali
moduli dovrà essere preceduta da una accurata analisi di quali statistiche sono rilevanti per il
Conclusioni e sviluppi futuri 50
gruppo di ricercatori.
Un altro sviluppo futuro proposto consiste nell'eseguire un'analisi del carico di rete del web
server in modo tale da dimensionare la banda utilizzata durante lo scaricamento dei pacchetti
software.lo steering dei progetti in corso, ovvero modifiche al piano di lavoro inizialmente
concordato anche sulla base delle metriche raccolte.
Bibliografia
[1]: G. Battistoni, S. Muraro, P.R. Sala, F. Cerutti, A. Ferrari,S. Roesler, A. Fasso`, J. Ranft,
The FLUKA code: Description and benchmarking, 2007
[2]: A. Fasso`, A. Ferrari, J. Ranft, and P.R. Sala, FLUKA: a multiparticle transport code,