METODI DI CLASSIFICAZIONE Mario Romanazzi 1 Introduzione Iniziamo la presentazione dei metodi di classificazione con un esempio rappresentativo della problematica generale. Esempio 1 Molti programmi per la gestione della posta al computer comprendono metodi per la classificazione di messaggi posta spazzatura (SPAM) o come posta regolare (NON SPAM). Di solito la classificazione ` e basata su caratteristiche stilistiche del messaggio, come la frequenza di particolari parole o caratteri. La Tabella 1 mostra un esempio di 5 messaggi, 3 SPAM e 2 NON SPAM sui quali vengono rilevate tre caratteristiche, W 1 , W 2 e W 3 . In ciascun messaggio W 1 ` e la frequenza relativa % della parola mail’, W 2 ` e la frequenza relativa % delle lettere maiuscole e W 3 ` e la frequenza relativa % del carattere !mail’. I dati suggeriscono che W 2 e W 3 tendono ad assumere valori pi` u elevati nei messaggi SPAM rispetto ai NON SPAM, aiutando dunque a discriminare tra le due classi. W 1 non sembra invece avere particolari capacit` a discriminatorie. CLASSE W 1 (%) W 2 (%) W 3 (%) SPAM 1.21 7.05 0.77 SPAM 0.98 3.46 0.55 SPAM 1.30 2.91 0.83 NON SPAM 1.41 1.04 0.09 NON SPAM 0.85 1.28 0.22 Tabella 1: Caratteristiche stilistiche di messaggi di posta al computer e classificazione come SPAM o NON SPAM. In via del tutto euristica, supponiamo di classificare come SPAM tutti i messaggi tali che W 2 > 2% ∩ W 3 > 0.5%. Questo criterio pu` o fungere da regola di attribuzione per assegnare messaggi di cui non si conosce la classe di appartenenza ad una delle possibili classi. La Tabella 2 riguarda due messaggi di posta al computer, di classe ignota, su cui sono state per` o rilevate le caratteristiche W 1 , W 2 e W 3 . In base al criterio precedente, il primo messaggio verrebbe attribuito alla classe NON SPAM, il secondo alla classe SPAM. Quali sono gli elementi che concorrono a definire un modello di classificazione? L’E- sempio 1 mostra che ci sono tre elementi principali. 1
Transcript
METODI DI CLASSIFICAZIONE
Mario Romanazzi
1 Introduzione
Iniziamo la presentazione dei metodi di classificazione con un esempio rappresentativodella problematica generale.
Esempio 1 Molti programmi per la gestione della posta al computer comprendono metodiper la classificazione di messaggi posta spazzatura (SPAM) o come posta regolare (NONSPAM). Di solito la classificazione e basata su caratteristiche stilistiche del messaggio,come la frequenza di particolari parole o caratteri. La Tabella 1 mostra un esempio di5 messaggi, 3 SPAM e 2 NON SPAM sui quali vengono rilevate tre caratteristiche, W1,W2 e W3. In ciascun messaggio W1 e la frequenza relativa % della parola mail’, W2 e lafrequenza relativa % delle lettere maiuscole e W3 e la frequenza relativa % del carattere!mail’. I dati suggeriscono che W2 e W3 tendono ad assumere valori piu elevati neimessaggi SPAM rispetto ai NON SPAM, aiutando dunque a discriminare tra le due classi.W1 non sembra invece avere particolari capacita discriminatorie.
Tabella 1: Caratteristiche stilistiche di messaggi di posta al computer e classificazionecome SPAM o NON SPAM.
In via del tutto euristica, supponiamo di classificare come SPAM tutti i messaggi taliche W2 > 2% ∩W3 > 0.5%. Questo criterio puo fungere da regola di attribuzione perassegnare messaggi di cui non si conosce la classe di appartenenza ad una delle possibiliclassi. La Tabella 2 riguarda due messaggi di posta al computer, di classe ignota, su cuisono state pero rilevate le caratteristiche W1, W2 e W3. In base al criterio precedente, ilprimo messaggio verrebbe attribuito alla classe NON SPAM, il secondo alla classe SPAM.
Quali sono gli elementi che concorrono a definire un modello di classificazione? L’E-sempio 1 mostra che ci sono tre elementi principali.
1
1 INTRODUZIONE 2
CLASSE VERA W1 (%) W2 (%) W3 (%)IGNOTA 0.92 1.17 0.16IGNOTA 1.18 3.44 0.75
Tabella 2: Classificazione di messaggi di posta al computer in base a caratteristichestilistiche.
1. Un insieme S avente come elementi le unita, o oggetti, da classificare (corrispondentiai messaggi dell’Esempio 1).
2. Una partizione di S in un numero finito M di sottoinsiemi C1, . . . , CM (corrispon-denti alle classi SPAM e NON SPAM dell’Esempio 1). Per definizione di partizioneogni unita appartiene ad una ed una sola classe.
3. Un certo numero di caratteristiche X1, . . . , Xp, o variabili discriminanti, rilevabilisu ogni unita (le caratteristiche stilistiche W1, W2, W3 dell’Esempio 1).
In pratica le variabili discriminanti sono le componenti di un vettore aleatorio X =(X1, . . . , Xp)T , la cui distribuzione varia a seconda della classe. Inoltre, ad ogni classe siassocia la corrispondente probabilita iniziale pm = P (Cm), m = 1, . . . ,M , operativamenteinterpretabile come la probabilita che un’unita casualmente estratta da S appartenga aCm.
Un metodo di classificazione e una regola che assegna le unita di S alle classi in modoottimale. Il criterio di ottimalita naturale e la minimizzazione dell’errore di classificazione.A tale proposito risulta utile rappresentare i risultati di una classificazione mediante lacosiddetta matrice di confusione. La matrice di confusione e una tabella con M righeed altrettante colonne. Le righe corrispondono alle classi vere cui le unita apparten-gono mentre le colonne corrispondono alle classi previste o stimate mediante un metododi classificazione. L’elemento generico della tabella fornisce la probabilita condizionaleP (classe stimata Cj|classe vera Ci) ≡ pij, i, j = 1, . . . ,M . Le celle diagonali della matriceforniscono le probabilita condizionali di classificazioni esatte mentre le celle non diagonaliforniscono le probabilita condizionali di classificazioni errate. Indichiamo con A l’eventoche un’unita casualmente estratta da S sia classificata correttamente. In base al teoremadella probabilita totale (vedi Appendice A) otteniamo
P (A) =M∑
m=1
P (Cm)P (classe stimata Cm|classe vera Cm) =M∑
m=1
pm · pm,m .
La probabilita che un’unita casualmente estratta da S sia classificata erroneamentee P (AC) = 1 − P (A). La matrice di confusione riveste un’importanza fondamentaleperche permette di valutare i risultati di un metodo di classificazione e di confrontaremetodi alternativi. Metodi di classificazione validi avranno valori diagonali della matricedi confusione vicini a 1. La probabilita di classificazione corretta P (A) fornisce un criterio
1 INTRODUZIONE 3
quantitativo scalare, ottenuto ponderando gli elementi della matrice di confusione con leprobabilita iniziali, idoneo a riassumere il comportamento complessivo di un metodo diclassificazione.
Gli Esempi 2 e 3 forniscono illustrazioni molto semplici delle definizioni precedenti.
Esempio 2 Su un lontano pianeta maschi e femmine hanno caratteristiche fisiche iden-tiche ma indossano abiti di colore tendenzialmente diverso. In termini specifici, per lefemmine la probabilita di vestire di rosso e pari a 0.9 mentre per i maschi e pari a 0.2.Inoltre la probabilita iniziali sono 0.6 per la classe Femmina e 0.4 per la classe Ma-schio. Sulla scorta di questi dati consideriamo la seguente regola di classificazione: se unindividuo veste rosso e classificato femmina, se veste non rosso e classificato maschio.La matrice di confusione e riportata nella Tabella 3. La probabilita che un individuocasualmente scelto sia classificato correttamente e
P (A) = 0.6 · 0.9 + 0.4 · 0.8 = 0.86
e la probabilita che sia classificato in modo errato e 1− P (A) = 0.14.
CLASSE STIMATACLASSE VERA FEMMINA MASCHIOFEMMINA 0.9 0.1MASCHIO 0.2 0.8
Tabella 3: Matrice di confusione della classificazione di maschi e femmine dell’Esempio 2.
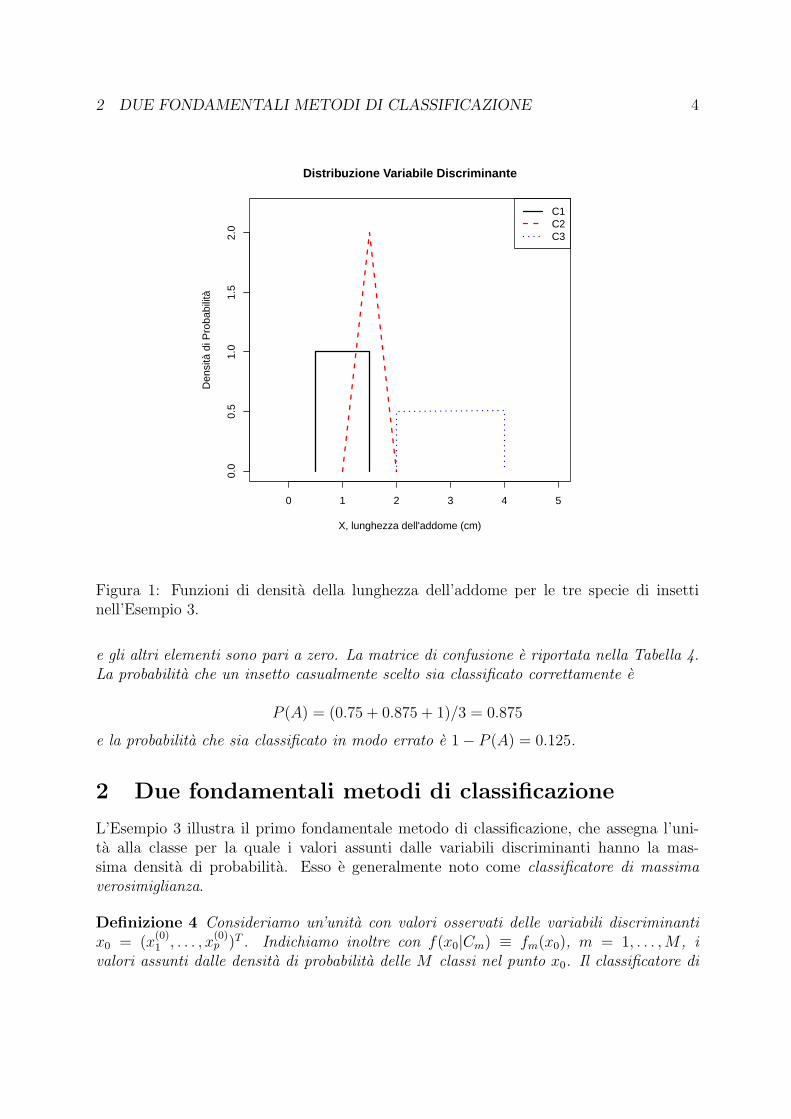
Esempio 3 Un insetto puo appartenere a tre diverse specie, C1, C2, C3, aventi le stesseprobabilita iniziali. La variabile discriminante X e la lunghezza dell’addome. Il graficodelle tre funzioni di densita e riportato nella Figura 1. Esso mostra che, per gli insettidi classe C1, 0.5 ≤ X ≤ 1.5; per quelli di classe C2, 1 ≤ X ≤ 2; per quelli di classeC3, 2 ≤ X ≤ 4. E evidente che, se 0.5 ≤ X ≤ 1, l’insetto e di classe C1 e che, se2 ≤ X ≤ 4, l’insetto e di classe C3 perche le altre classi hanno densita pari a zero inquesti intervalli. Ma come si devono classificare gli insetti con 1 < X ≤ 1.5? Un criterioragionevole e quello di attribuire l’insetto alla classe con la densita piu alta. Pertanto laregola di classificazione e: se 0.5 ≤ X ≤ 1.25 assegna l’insetto a C1, se 1.25 < X ≤ 2assegna l’insetto a C2 e se 2 < X ≤ 3 assegna l’insetto a C3.
Valutiamo la corrispondente matrice di confusione. Risulta
p11 =
∫ 1.25
0.5
f1(x)dx = 0.75 , p12 =
∫ 1.5
1.25
f1(x)dx = 0.25 , (1)
p22 =
∫ 2
1.25
f2(x)dx = 0.875 , p21 =
∫ 1.25
1
f2(x)dx = 0.125 , (2)
p33 =
∫ 3
2
f3(x)dx = 1 (3)
2 DUE FONDAMENTALI METODI DI CLASSIFICAZIONE 4
0 1 2 3 4 5
0.0
0.5
1.0
1.5
2.0
Distribuzione Variabile Discriminante
X, lunghezza dell'addome (cm)
Den
sità
di P
roba
bilit
àC1C2C3
Figura 1: Funzioni di densita della lunghezza dell’addome per le tre specie di insettinell’Esempio 3.
e gli altri elementi sono pari a zero. La matrice di confusione e riportata nella Tabella 4.La probabilita che un insetto casualmente scelto sia classificato correttamente e
P (A) = (0.75 + 0.875 + 1)/3 = 0.875
e la probabilita che sia classificato in modo errato e 1− P (A) = 0.125.
2 Due fondamentali metodi di classificazione
L’Esempio 3 illustra il primo fondamentale metodo di classificazione, che assegna l’uni-ta alla classe per la quale i valori assunti dalle variabili discriminanti hanno la mas-sima densita di probabilita. Esso e generalmente noto come classificatore di massimaverosimiglianza.
Definizione 4 Consideriamo un’unita con valori osservati delle variabili discriminantix0 = (x
(0)1 , . . . , x
(0)p )T . Indichiamo inoltre con f(x0|Cm) ≡ fm(x0), m = 1, . . . ,M , i
valori assunti dalle densita di probabilita delle M classi nel punto x0. Il classificatore di
2 DUE FONDAMENTALI METODI DI CLASSIFICAZIONE 5
CLASSE STIMATACLASSE VERA C1 C2 C3
C1 0.75 0.25 0C2 0.125 0.875 0C3 0 0 1
Tabella 4: Matrice di confusione della classificazione degli insetti dell’Esempio 3.
massima verosimiglianza assegna l’unita alla classe che attribuisce a x0 il massimo valoredella densita di probabilita.
Nota 5 Il riferimento al metodo di stima di massima verosimiglianza non e casuale.Nei problemi di classificazione il parametro da stimare e la classe cui attribuire l’unitain esame. Esso assume un numero finito, M , di modalita distinte. Dato il valore x0
delle variabili discriminanti, la stima di massima verosimiglianza si ottiene pertanto a)calcolando il corrispondente valore della densita fm(x0) per ogni classe e b) individuandola classe C∗m col massimo valore della densita.
Il classificatore di massima verosimiglianza e un caso particolare del classificatore diBayes, basato sull’omonimo teorema (vedi Appendice A).
Definizione 6 Nelle stesse ipotesi della Definizione 4, usando il teorema di Bayes, laprobabilita finale della classe Cm e pari a:
P (Cm|x0) =pm · fm(x0)∑Mi=1 pi · fi(x0)
,m = 1, · · · ,M.
Il classificatore di Bayes assegna l’unita alla classe avente massima probabilita finale.
Nota 7 La quantita che appare a denominatore delle probabilita finali assume lo stessovalore per tutte le classi ed e pertanto irrilevante per quanto riguarda l’identificazione dellaclasse ottimale. A tal fine bastera determinare la classe col massimo valore di pm ·fm(x0),o equivalentemente, ln pm + lnfm(x0), m = 1, · · · ,M .
Nota 8 La Nota 7 chiarisce la relazione tra il classificatore di Bayes e quello di massimaverosimiglianza. Il classificatore di Bayes pondera i valori delle verosimiglianze fm(x0)con le probabilita iniziali pm. Questo permette di integrare l’informazione fornita dallevariabili discriminanti (il valore x0 e le corrispondenti densita) con le probabilita iniziali.Se queste sono costanti, i due classificatori sono equivalenti.
Il classificatore di Bayes gode di un’importante proprieta, riportata nel Teorema 9.
Teorema 9 Il classificatore di Bayes della Definizione 6 e ottimale, cioe produce il mi-nimo valore della probabilita di classificazioni errate. Una dimostrazione si puo trovarenei testi di analisi multivariata, ad esempio Mardia et al., Multivariate Analysis, 1979.
2 DUE FONDAMENTALI METODI DI CLASSIFICAZIONE 6
−0.3 −0.2 −0.1 0.0 0.1 0.2 0.3 0.4
01
23
45
Distribuzione Variabile Discriminante
X, utili/fatturato
Den
sità
di P
roba
bilit
àC1C2
Figura 2: Funzioni di densita del rapporto utili su fatturato per le due classi di impresedell’Esempio 11.
Nota 10 Il classificatore di Bayes richiede una conoscenza molto dettagliata del proble-ma in esame, in particolare a) le probabilita iniziali e b) le distribuzioni di probabilitadelle variabili discriminanti di ogni classe. Pertanto, si potra essere fiduciosi di aver ot-tenuto il classificatore ottimale, cioe con la minima probabilita d’errore, solo quando sonodisponibili stime attendibili di pm e fm(x0), m = 1, . . . ,M .
Esempio 11 Metodi di classificazione sono frequentemente usati per studiare l’affidabilita,o solvibilita, delle imprese per quanto riguarda la concessione di credito da parte dellebanche. In queste indagini, l’universo delle imprese e diviso in due classi C1 e C2 com-prendenti rispettivamente le imprese non affidabili e affidabili. Le variabili discriminantisono indicatori di solvibilita solitamente ricavati dai bilanci. In questo esempio semplifi-cato consideriamo una sola variabile discriminante X, data dal rapporto utili su fatturato,e assumiamo che le funzioni di densita di probabilita siano
f1(x) = (5− 25x)/2 , −0.2 ≤ x ≤ 0.2 , (4)
f2(x) = (5/2 + 25x)/2 , −0.1 ≤ x ≤ 0.3 . (5)
2 DUE FONDAMENTALI METODI DI CLASSIFICAZIONE 7
Il grafico delle due distribuzioni e riportato nella Figura 2. Le probabilita iniziali delleclassi sono p1 = 0.8, p2 = 1− p1 = 0.2. Mostreremo ora che il classificatore di Bayes, inaccordo col Teorema 9, e migliore del classificatore di massima verosimiglianza per quantoriguarda la probabilita totale d’errore. Siccome f1(x) = f2(x) per x = 0.05, il classificatoredi massima verosimiglianza e:
• assegna l’unita a C1 se x ≤ 0.05,
• assegna l’unita a C2 se x > 0.05.
Pertanto
p(ML)11 =
∫ 0.05
−0.2
f1(x)dx = 0.859375 , p(ML)22 =
∫ 0.3
0.05
f2(x)dx = 0.859375 , (6)
e P (A)(ML) = p1 · p(ML)11 + (1− p1) · p(ML)
22 = 0.859375.Consideriamo ora il classificatore di Bayes. L’uguaglianza p1f1(x) = p2f2(x) e verifi-
cata per x = 0.14 e il classificatore di Bayes e:
• assegna l’unita a C1 se x ≤ 0.14,
• assegna l’unita a C2 se x > 0.14.
I valori nelle celle diagonali della matrice di confusione sono
p(B)11 =
∫ 0.14
−0.2
f1(x)dx = 0.9775 , p(B)22 =
∫ 0.3
0.14
f2(x)dx = 0.64 , (7)
e P (A)(B) = p1 ·p(B)11 +(1−p1) ·p(B)
22 = 0.91. Il risultato conferma la proprieta generale sta-bilita dal Teorema 9. Il vantaggio del classificatore di Bayes rispetto a quello di massimaverosimiglianza e |0.91− 0.859375| ' 0.05. Esso e causato dall’aumento del valore soglia,da 0.05 a 0.14, determinato dalla ponderazione con le probabilita iniziali. Osserviamo,infine, che mentre la matrice di confusione del classificatore di massima verosimiglianzae simmetrica, cioe p
(ML)12 = p
(ML)21 , quella del classificatore di Bayes e asimmetrica, con
p(B)12 � p
(B)21 . Cio significa che, per il classificatore di Bayes, la probabilita di classificare
come affidabile un’impresa che non lo e risulta molto piu bassa della probabilita di clas-sificare come non affidabile un’impresa che invece lo e, in linea col comportamento moltoprudente nella concessione di credito da parte delle banche.
3 VARIABILI DISCRIMINANTI CON DISTRIBUZIONE NORMALE 8
3 Variabili discriminanti con distribuzione normale
3.1 Distribuzione normale multivariata
La distribuzione normale in p dimensioni e un modello distributivo in base al quale idati sono simmetricamente disposti attorno ad un centro, il vettore delle medie µ =(µ1, . . . , µp)T , e la dispersione e controllata dalla matrice di covarianza Σ = (σij), i, j =1, . . . , p. Gli elementi diagonali di Σ, σii, sono le varianze delle distribuzioni marginaliunivariate e gli elementi non diagonali, σij = ρij
√σiiσjj, i 6= j, sono le covarianze delle
distribuzioni marginali bivariate. Qui −1 ≤ ρij ≤ 1 indica il coefficiente di correlazionelineare della coppia Xi, Xj.
Il modello distributivo normale e largamente usato nei problemi di classificazioneperche consente di descrivere classi con posizione e dispersione arbitrarie. Tuttavia, lasimmetria ellittica implicita nella distribuzione normale – le curve di livello costante delladensita normale sono ellissi in due dimensioni, ellissoidi in tre dimensioni, ecc. – si rivelaspesso un’ipotesi restrittiva. In questi casi puo essere utile far ricorso alla distribuzio-ne normale sghemba (Azzalini, The Skew-normal Distribution and Related MultivariateFamilies, Scandinavian Journal of Statistics, 2005).
Nel seguito usiamo la simbologia X ∼ Np(µ,Σ) per indicare che il vettore di variabiliX = (X1, . . . , Xp)T ha una distribuzione normale p-dimensionale con vettore delle medieµ e matrice di covarianza Σ. La funzione di densita normale e
fX(x) =1
(2π)p/2(det Σ)1/2exp{−1
2d2
M(x, µ)} ,
dove
dM(x, µ) =√
(x− µ)T Σ−1(x− µ)
e la distanza di Mahalanobis di x ∈ Rp dal centro µ. Nel caso univariato, p = 1, dM(x, µ) =|x1−µ1|/σ11 si riduce al valore assoluto del valore standardizzato di x1. La Figura 3 mostrale curve di valore costante della densita di due normali bivariate.
La densita normale dipende dunque dal valore della distanza di Mahalanobis (alquadrato), assumendo il valore massimo se x = µ. E utile ricordare qualche proprieta ditale distanza. La distanza euclidea di x da µ e
dE(x, µ) =√
(x− µ)T (x− µ) .
Questo mostra che dM(x, µ) = dE(x, µ) se Σ = Ip, dove Ip e la matrice identita d’ordine p,cioe la distanza di Mahalanobis si riduce alla distanza euclidea quando le variabili a) sonolinearmente indipendenti (e dunque anche stocasticamente indipendenti, data la partico-lare struttura di dipendenza della normale multivariata) e b) hanno varianza unitaria. Incaso contrario essa e diversa dalla distanza euclidea perche le variabili sono ponderatecon coefficienti dipendenti dagli elementi di Σ−1. Ad esempio, se Σ = diag(σ11, . . . , σpp),allora Σ−1 = diag(σ−1
11 , . . . , σ−1pp ) e
3 VARIABILI DISCRIMINANTI CON DISTRIBUZIONE NORMALE 9
Curve di Livello Densità Normale (RHO = −0.6 )
X
Y
0.01
0.02
0.03
0.04
0.05
0.06
0.07 0.08
0.09
−6 −4 −2 0 2 4 6
−4
−2
02
4
*
Curve di Livello Densità Normale (RHO = 0.3 )
X
Y
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
−6 −4 −2 0 2 4 6−
6−
4−
20
24
6
*
Figura 3: Curve di livello della densita normale bivariata.
dM(x, µ) =√
(x− µ)T Σ−1(x− µ) =
√√√√ p∑j=1
(xj − µj)2
σjj
,
e dunque la ponderazione prodotta dalla distanza di Mahalanobis equivale in questo casoall’uso della distanza euclidea sui dati standardizzati.
E facile verificare che Y = Σ−1/2(X − µ) ∼ Np(0p, Ip), cioe le componenti di Y sonovariabili normali standardizzate e stocasticamente indipendenti. Allora
∑p1 Y
2j ha una
distribuzione chi-quadrato con p gradi di liberta. Poiche
p∑1
Y 2j = Y TY = (X − µ)T Σ−1(X − µ) = d2
M(X,µ) ,
il quadrato della distanza di Mahalanobis da µ di un vettore normalmente distribuito hauna distribuzione chi-quadrato con p gradi di liberta.
3.2 Classificatore di Bayes
Sia x0 = (x(0)1 , . . . , x
(0)p )T il vettore dei valori osservati delle variabili discriminanti. Quando
le variabili discriminanti hanno in ogni classe una distribuzione congiunta normale, cioeX|Cm ∼ Np(µm,Σm), il classificatore di Bayes dipende principalmente dalle distanze diMahalanobis di x0 dai centri delle classi. Vediamo il risultato in dettaglio.
3 VARIABILI DISCRIMINANTI CON DISTRIBUZIONE NORMALE 10
1. In base alla Nota 7, si deve ricercare max1≤m≤M pm · fm(x0) o, equivalentemente,max1≤m≤M ln pm + ln fm(x0). Sostituendo l’espressione della densita normale, otte-niamo
ln pm + ln fm(x0) = −1
2{d2
M(x0, µm) + ln det Σm − 2 ln pm + p ln(2π)} .
Il massimo di questa espressione per 1 ≤ m ≤M coincide col minimo di d2M(x0, µm)+
ln det Σm − 2 ln pm, pertanto l’unita da classificare verra assegnata alla classe percui
2. Se le probabilita iniziali sono costanti, nella precedente espressione il termine−2 ln pm
diventa irrilevante e l’unita da classificare verra assegnata alla classe per cui
d2M(x0, µm) + ln det Σm = (x0 − µm)T Σ−1
m (x0 − µm) + ln det Σm
assume il valore minimo. Questo criterio fornisce anche il classificatore di massimaverosimiglianza.
3. Quando le classi sono due, l’unita da classificare verra assegnata a C1 se
d2M(x0, µ1) < d2
M(x0, µ2) + 2{ln p1√det Σ1
− lnp2√
det Σ2
}.
4. Infine, se le classi sono due e le matrici di covarianza sono uguali, cioe Σ1 = Σ2 = Σ,l’unita da classificare verra assegnata a C1 se
(µ2 − µ1)T Σ−1(x0 −
µ1 + µ2
2) < ln
p1
p2
.
Quest’ultima espressione prende il nome di funzione discriminante lineare perche, adifferenza delle precedenti, dipende linearmente da x0.
Esempio 12 I metodi di classificazione sono largamente usati nella diagnostica clinica,per discriminare tra soggetti affetti (classe C1) e non affetti (classe C2) da particolaripatologie. Qui consideriamo un caso univariato. Per diagnosticare una malattia vieneimpiegato un test clinico X tale che X|C1 ∼ N(µ1 = 5, σ1 = 1.5) e X|C2 ∼ N(µ2 =3, σ2 = 0.5). Le probabilita iniziali sono p1 = 0.05, p2 = 1− p1 = 0.95. Dal caso 3) vistosopra, ricaviamo che un’unita verra assegnata a C1 se
3 VARIABILI DISCRIMINANTI CON DISTRIBUZIONE NORMALE 11
0 2 4 6 8 10 12
0.0
0.2
0.4
0.6
0.8
Distribuzione Variabile Discriminante
X, risultato del test clinico
Den
sità
di p
roba
bilit
àC1C2
Figura 4: Funzioni di densita del valore del test clinico per i soggetti malati (C1) e nonmalati (C2) dell’Esempio 12. I segmenti verticali indicano l’intervallo di attribuzione algruppo C2 secondo il classificatore di massima verosimiglianza.
(x0 − µ1
σ1
)2 < (x0 − µ2
σ2
)2 + 2(lnp1
σ1
− lnp2
σ2
) ,
cioe
(x0 − 5
1.5)2 < (
x0 − 3
0.5)2 − 8.086103 .
Dunque un’unita con x0 = 3.5 viene assegnata a C2 mentre un’unita con x0 = 4.5 vieneassegnata a C1. Si puo verificare che il classificatore di Bayes e
• assegna l’unita a C1 se x < 1.143 o x > 4.357,
• assegna l’unita a C2 se 1.143 ≤ x ≤ 4.357,
mentre il classificatore di massima verosimiglianza e
• assegna l’unita a C1 se x < 1.696 o x > 3.804,
4 DATI CAMPIONARI 12
• assegna l’unita a C2 se 1.696 ≤ x ≤ 3.804.
La Figura 4 mostra l’andamento delle due funzioni di densita e l’intervallo di at-tribuzione al gruppo C2 secondo il classificatore di massima verosimiglianza. L’intervallodi attribuzione al gruppo C2 secondo il classificatore di Bayes e piu ampio perche p2 > p1.
Concludiamo l’esempio con la matrice di confusione. Per il classificatore di Bayes,
p(B)11 =
∫ 1.143
−∞f1(x)dx+
∫ ∞4.357
f1(x)dx ' 0.671 , p(B)12 ' 0.329 , (8)
p(B)22 =
∫ 4.357
1.143
f2(x)dx ' 0.997 , p(B)21 ' 0.003 , (9)
e PB(A) ' 0.980. Per il classificatore di massima verosimiglianza,
p(ML)11 =
∫ 1.696
−∞f1(x)dx+
∫ ∞3.804
f1(x)dx ' 0.801 , p(ML)12 ' 0.199 , (10)
p(ML)22 =
∫ 3.804
1.696
f2(x)dx ' 0.941 , p(ML)21 ' 0.058 , (11)
e PML(A) ' 0.935 < PB(A), in accordo col Teorema 9. Anche se la probabilita totaledi una classificazone corretta e molto alta, va notato che la probabilita subordinata che iltest non scopra che un paziente e malato e elevata, in particolare per il classificatore diBayes, e questo costituisce un aspetto negativo.
4 Dati campionari
In precedenza abbiamo sempre supposto che le probabilita iniziali e le distribuzioni dellevariabili discriminanti fossero note. In realta, le une e le altre devono sempre esserestimate sulla base di dati campionari. Per quanto riguarda le probabilita iniziali pm,m = 1, . . . ,M , esse vengono solitamente stimate per mezzo delle frequenze relative nm/n,dove nm e il numero delle unita appartenenti a Cm nel campione osservato mentre n e lanumerosita totale del campione. Per quanto riguarda invece le distribuzioni delle variabilidiscriminanti, ci sono due situazioni molto diverse, a seconda del grado di accuratezza dellenostre informazioni. Se le distribuzioni sono note nella loro forma funzionale, a meno deiparametri che le caratterizzano, si sostituiscono i parametri con le loro stime campionariee si procede come mostrato nelle sezioni precedenti. E quanto accade quando si assumeche le variabili discriminanti abbiano una distribuzione normale. I vettori delle medieµm e le matrici di covarianza Σm sono rimpiazzati dalle loro stime, i vettori delle mediecampionarie xm e le matrici di covarianza campionarie Sm. Se invece le distribuzioni dellevariabili discriminanti non sono note, si ricorre alla loro stima con metodi non parametrici.Un esempio notevole e il cosiddetto k-th nearest neighbour che verra trattato nella Sezione5.
4 DATI CAMPIONARI 13
1
1
1
1
1
1
11
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
11
1
1
1
1
11
1
1
1
1
1
11
1
11
1
1
1
1
1
1
1
1
1
2
2 2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
22
22
2
2
2
2
2
2
2
2
2
2
2
22
2
2
2
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3
3 3
3
3
3
3
3
3
33
3
3
3
3
3
3 33
3
33
3
3
3
3
3
−3 −2 −1 0 1 2 3
−2
−1
01
2
Componenti Principali dei Dati Iris
PC1 (73%)
PC
2 (2
3%)
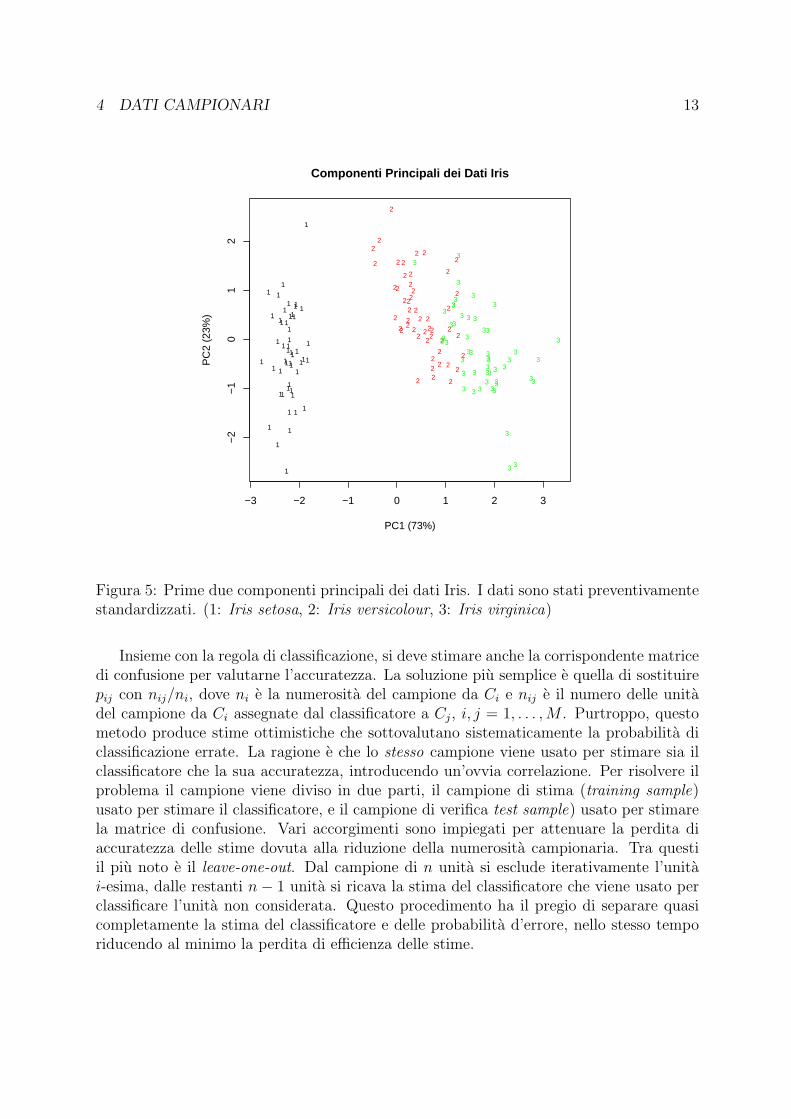
Figura 5: Prime due componenti principali dei dati Iris. I dati sono stati preventivamentestandardizzati. (1: Iris setosa, 2: Iris versicolour, 3: Iris virginica)
Insieme con la regola di classificazione, si deve stimare anche la corrispondente matricedi confusione per valutarne l’accuratezza. La soluzione piu semplice e quella di sostituirepij con nij/ni, dove ni e la numerosita del campione da Ci e nij e il numero delle unitadel campione da Ci assegnate dal classificatore a Cj, i, j = 1, . . . ,M . Purtroppo, questometodo produce stime ottimistiche che sottovalutano sistematicamente la probabilita diclassificazione errate. La ragione e che lo stesso campione viene usato per stimare sia ilclassificatore che la sua accuratezza, introducendo un’ovvia correlazione. Per risolvere ilproblema il campione viene diviso in due parti, il campione di stima (training sample)usato per stimare il classificatore, e il campione di verifica test sample) usato per stimarela matrice di confusione. Vari accorgimenti sono impiegati per attenuare la perdita diaccuratezza delle stime dovuta alla riduzione della numerosita campionaria. Tra questiil piu noto e il leave-one-out. Dal campione di n unita si esclude iterativamente l’unitai-esima, dalle restanti n− 1 unita si ricava la stima del classificatore che viene usato perclassificare l’unita non considerata. Questo procedimento ha il pregio di separare quasicompletamente la stima del classificatore e delle probabilita d’errore, nello stesso temporiducendo al minimo la perdita di efficienza delle stime.
4 DATI CAMPIONARI 14
CLASSE STIMATADiscr. Lineare Discr. Quadratico
CLASSE VERA C1 C2 C3 C1 C2 C3
C1 50 0 0 50 0 0C2 0 48 2 0 47 3C3 0 1 49 0 1 49
Tabella 5: Matrice di confusione dei dati Iris dell’Esempio 13. Risultati basati sul classi-ficatore bayesiano con ipotesi di normalita delle varabili discriminanti. Gli elementi dellamatrice di confusione sono stati ottenuti col metodo leave-one-out.
Esempio 13 I dati di questo esempio riguardano l’attribuzione di fiori di iris alle rispet-tive specie. Ci sono tre classi corrispondenti alle specie Iris setosa (C1), Iris versicolour(C2), Iris virginica (C3). Le variabili discriminanti sono quattro, lunghezza e larghezzadei sepali, lunghezza e larghezza dei petali. Per ciascuna classe abbiamo un campione di50 elementi. La Figura 5 mostra la proiezione dei dati, preventivamente standardizzati,sulle prime due componenti principali. L’approssimazione e buona dato che la percentualespiegata della varianza totale supera il 95%. Il grafico suggerisce che Iris setosa abbia ca-ratteristiche completamente diverse da quelle delle altre due specie, mentre Iris versicoloure Iris virginica hanno un certo grado di sovrapposizione.
Per la classificazione abbiamo usato la versione campionaria del classificatore bayesianobasato sull’ipotesi di normalita delle variabili discriminanti. I risultati sono stati ottenutiper mezzo delle funzioni R lda e qda che differiscono solo per il trattamento delle ma-trici di covarianza. La prima si basa sull’ipotesi che le matrici di covarianza dei gruppisiano uguali. Le matrici di confusione campionarie (vedi Tabella 5), ottenute col metodoleave-one-out, sono molto simili e forniscono stime delle probabilita d’errore pari a 2%per la funzione discriminante lineare, 2.67% per quella quadratica. Gli errori riguardanosolo Iris versicolour e Iris virginica. Il metodo della convalida incrociata conferma questirisultati. Ciascun campione e stato diviso a caso in un sotto-campione di stima del clas-sificatore e un sotto-campione di verifica di pari numerosita. Il procedimento, ripetuto 20volte, ha fornito in media le seguenti stime delle probabilita d’errore: 2.2% per la funzionediscriminante lineare, 2.4% per quella quadratica.
4.1 Capacita discriminatoria delle variabili
Le variabili discriminanti non hanno tutte la stessa importanza ai fini della classificazioneed e pertanto utile riconoscere quelle che riescono meglio a discriminare tra le diverseclassi. A tale proposito conviene ricordare il teorema di scomposizione della matrice dicovarianza (vedi Appendice B): quando le unita campionarie sono divise in gruppi in-compatibili ed esaustivi, la matrice di covarianza campionaria e identicamente ugualealla somma della matrici di covarianza within-groups e between-groups. La seconda com-ponente fornisce la misura della variabilita delle medie dei gruppi rispetto alla mediagenerale ed e interpretabile come una misura del grado di separazione dei gruppi. Quanto
5 K-NEAREST NEIGHBOURS 15
●
Set Ver Vir
2.0
2.5
3.0
3.5
4.0
IRIS
Specie
Larg
hezz
a de
i Sep
ali
●
●
Set Ver Vir
12
34
56
7
IRIS
Specie
Lung
hezz
a de
i Pet
ali
Figura 6: Distribuzione della larghezza dei sepali e della lunghezza dei petali dei dati Iris.
maggiore la componente between-groups rispetto a quella within-groups tanto piu i gruppisono coesi e separati. Queste considerazioni suggeriscono di calcolare il rapporto tra glielementi diagonali della matrice di covarianza between-groups e i corrispondenti elementidiagonali della matrice di covarianza totale, onde ottenere un ordinamento delle variabilisecondo la capacita discriminatoria.
Esempio 14 Per le variabili dei dati Iris, i rapporti (%) varianza between-groups suvarianza totale risultano pari a 61.9, 40.1, 94.1, 92.9. In questo caso tutte le variabili han-no un rapporto abbastanza elevato ma i valori raggiunti dalla terza e quarta variabile,lunghezza e larghezza dei petali, sono eccezionali. La Figura 6 permette di interpretarequesti risultati.
5 K-nearest neighbours
Il metodo di classificazione K-nearest neighbours (KNN), che si puo rendere in italia-no come vicini piu vicini, e basato su presupposti completamente diversi dai metodiparametrici, come quello discusso nella Sezione 4.
Supponiamo di avere un campione di dimensione n, con nm unita appartenenti allaclasse Cm, m = 1, . . . ,M . Supponiamo inoltre di dover classificare un’unita di cui conosci-amo il valore delle variabili discriminanti, indicato con x0 = (x
(0)1 , . . . , x
(0)p )T . Ricordiamo
che x0 si interpreta geometricamente come un punto nello spazio euclideo p-dimensionale.Il primo passo e la costruzione di un intorno di x0. Si calcolano i valori d1, . . . , dn delledistanze euclidee di x0 dai punti campionari x1, . . . , xn, di =
√(x0 − xi)T (x0 − xi), e si
5 K-NEAREST NEIGHBOURS 16
●●
●
●
●
●
●
●
●
●
●
●
●
−2 −1 0 1 2
−2
−1
01
Illustrazione Metodo KNN
K = 3Peso (Unità Standard)
Sta
tura
(U
nità
Sta
ndar
d)
FF
F
F
F
F
F
F
M
M
M
M
M
*
#
+
Figura 7: Geometria del metodo di classificazione KNN su dati simulati di peso e staturadi due campioni di femmine (F) e maschi (M). I cerchi sono gli intorni dei punti P1 =(58, 163)T (∗), P2 = (70, 174)T (#), P3 = (55, 168)T (+) per K = 3. I dati sono statipreventivamente standardizzati.
individua il K-esimo valore nel vettore delle distanze ordinate in senso crescente. Siad(K) il corrispondente valore numerico. L’intorno di x0 e la sfera p-dimensionale centratain x0 e avente come raggio d(K). Se i valori delle distanze di sono distinti, nell’intorno(all’interno della sfera o sulla sua frontiera) ci sono esattamente K punti del campioneosservato, i K punti piu vicini a x0. La regola di classificazione e ora ovvia: x0 e assegnatoalla classe avente il maggior numero di punti nell’intorno definito in precedenza.
Esempio 15 Assumiamo che la distribuzione congiunta di peso e statura sia normale conparametri diversi per femmine e maschi. Specificamente, assumiamo che i vettori dellemedie e delle deviazioni standard siano rispettivamente µF = (60, 165)T , µM = (75, 178)T ,σF = (8, 10)T , σM = (9, 10)T e che il coefficiente di correlazione lineare sia ρF = ρM =0.7. Simuliamo due campioni di numerosita nF = 8, nM = 5 dalle due distribuzionie usiamo questi dati per classificare i tre punti P1 = (58, 163)T , P2 = (70, 174), P3 =(55, 168). Poiche le unita di misura e l’ordine di grandezza delle variabili sono diverse,per evitare distorsioni della distanza euclidea, tutti i dati compresi quelli di P1, P2, P3
sono pre-standardizzati usando medie e deviazioni standard del campone totale di nF +nM
5 K-NEAREST NEIGHBOURS 17
unita. Ai fini della classificazione poniamo K = 3, cioe consideriamo intorni di P1, P2, P3
comprendenti i tre punti piu vicini del campione. La Figura 7 illustra i risultati. Gliintorni di P1 e P3 comprendono tre femmine pertanto i due punti sono classificati comefemmine. L’intorno di P2 comprende due maschi e una femmina ed il punto e classificatocome maschio.
Esaminiamo di seguito alcuni aspetti del metodo KNN.
Scelta della distanza La distanza piu usata e quella euclidea ma non vanno esclusealtre soluzioni come la distanza di Mahalanobis con un’opportuna matrice di pon-derazione. Nell’Esempio 15 e stata usata la distanza
√(x− y)TD−1(x− y) con
D = diag S dove S e la matrice di covarianza campionaria. Questa scelta equivalealla standardizzazione dei dati.
Stima della probabilita d’errore. Per ottenere stime non distorte si divide il campio-ne in due sotto-campioni disgiunti usati rispettivamente per la stima del classifi-catore e la sua verifica. Le unita del campione di verifica sono classificate usandole unita del campione di stima per costruire gli intorni. Il metodo leave-one-out emolto popolare. In questo caso ogni unita campionaria e usata a turno come centrodell’intorno ed e classificata usando le restanti n− 1 unita.
Valore di K E raccomandabile usare il valore di K che minimizza la stima della proba-bilita d’errore.
C’e un legame del KNN con i metodi di riferimento, il classificatore di Bayes e quellodi massima verosimiglianza? Consideriamo un generico punto x0 dello spazio e sia ∆(K)la misura dell’intorno di x0 (l’area per p = 2, il volume per p = 3, ecc.). Indichiamoinoltre con nm/K la frequenza relativa della classe Cm nell’intorno, m = 1, . . . ,M . Ilrapporto nm/(K∆(K) e una stima di fm(x0), la densita di probabilita nel punto x0 dellaclasse Cm e converge a fm(x0) al divergere della numerosita campionaria per ogni fissatovalore di K. Pertanto KNN si basa su un principio simile a quello del classificatore dimassima verosimiglianza, salvo il fatto che i valori delle funzioni di densita sono stimaticon un metodo non parametrico.
Esempio 16 Riconsideriamo i dati Iris usando questa volta il classificatore KNN. Vistal’eterogeneita delle deviazioni standard delle variabili i dati sono stati standardizzati. Ilvalore ottimale di K (vedi Figura 8) e pari a 13 e produce una stima della probabilitad’errore pari a 3.33%, di poco peggiore del classificatore bayesiano basato sull’ipotesi dinormalita. Il procedimento di convalida incrociata, eseguito come nell’Esempio 13 fornisceuna stima pari a 5.8%.
A APPENDICE. PROBABILITA TOTALE E FORMULA DI BAYES 18
● ● ●
●● ●
● ● ●
●●
●●
● ● ● ● ●
●
●
●● ●
●
●● ●
●
● ●●
●● ●
●●
●● ●
● ● ●●
●● ●
●
● ●
● ●
●
●
●
●
●
●
0 20 40 60 80 100
010
2030
4050
KNN con Dati Iris
Leave−one−outK
Stim
a P
roba
bilit
à d'
Err
ore
(%)
Figura 8: KNN con dati Iris. Andamento della stima col metodo leave-one-out dellaprobabilita d’errore al variare di K. I dati sono stati preventivamente standardizzati.
A Appendice. Probabilita totale e formula di Bayes
Consideriamo un evento casuale E che puo verificarsi in concomitanza con eventiA1, . . . , AM ,M ≥ 2, che formano una partizione dello spazio campionario S. Per definizione gli eventiAm sono a) a due a due incompatibili, cioe non hanno eventi elementari in comune, e b)la loro unione da l’intero spazio campionario. Quando si studiano i risultati di un test,E e l’evento “un soggetto, scelto casualmente, supera il test” e la partizione dello spaziocampionario comprende gli eventi A1 : “il soggetto non e preparato” e A2 : “il soggettoe preparato”. Nel controllo di qualita, in cui si deve valutare se un lotto di prodottie accettabile, E e l’evento “il controllo di un campione casuale di n pezzi del lotto haevidenziato la presenza di 0 ≤ k ≤ n pezzi difettosi” e la partizione e formata da A1 : “illotto non e conforme allo standard di qualita”, A2 : “il lotto e conforme allo standard diqualita”. Nella diagnosi di una malattia mediante test clinici, E e l’evento “un soggetto erisultato positivo al test” e la partizione e la coppia di eventi A1 : “il soggetto e malato”,A2 : “il soggetto non e malato”.
Supponiamo di conoscere le probabilita P (Am) degli eventi della partizione e anche leprobabilita subordinate P (E|Am), m = 1, . . . ,M . Il problema risolto dal teorema della
A APPENDICE. PROBABILITA TOTALE E FORMULA DI BAYES 19
probabilita totale e la probabilita non subordinata di E.
Teorema 17 (Probabilita totale) La probabilita totale di E e
P (E) =M∑
m=1
P (Am)P (E|Am)
Dimostrazione. Vale la seguente identita:
E = E ∩ S = E ∩ (∪Mm=1Am) (12)
= ∪Mm=1(E ∩ Am) , (13)
in cui gli eventi E∩Am, m = 1, . . . ,M , sono a due a due incompatibili. Possiamo pertantousare l’assioma di addivita e scrivere
P (E) = P (∪Mm=1(E ∩ Am)) =
M∑m=1
P (E ∩ Am) .
Per il teorema del prodotto, P (E ∩ Am) = P (Am)P (E|Am), pertanto
P (E) =M∑
m=1
P (E ∩ Am) =M∑
m=1
P (Am)P (E|Am) .
La formula di Bayes riguarda le probabilita subordinate degli eventi Am se e noto chel’evento E si e verificato.
Teorema 18 (Formula di Bayes) Per m = 1, . . . ,M , la probabilita subordinata P (Am|E)e
P (Am|E) =P (Am)P (E|Am)∑Mj=1 P (Aj)P (E|Aj)
Dimostrazione. La dimostrazione e basata sulla definizione di probabilita subordi-nata:
P (Am|E) =P (Am ∩ E)
P (E).
La formula di Bayes si ottiene sostituendo a) a numeratore, ancora per la regola delprodotto, P (Am)P (E|Am) e b) a denominatore la probabilita totale di E.
A APPENDICE. PROBABILITA TOTALE E FORMULA DI BAYES 20
Esempio 19 Un test comprende 10 domande indipendenti l’una dall’altra. Per ogni do-manda sono fornite tre risposte, una sola delle quali e esatta. Se uno studente e prepara-to, sceglie la risposta esatta di ogni domanda con probabilita 0.8. Se uno studente none preparato, sceglie a caso la risposta di ogni domanda. La probabilita che uno studentesia preparato si assume pari a 0.7. Il test e considerato sufficiente con almeno 6 risposteesatte. Vogliamo calcolare a) la probabilita che uno studente superi il test, qualunque siala sua preparazione e b) la probabilita che uno studente, pur avendo superato il test, siain realta non preparato.
a) Indichiamo con A l’evento che uno studente casualmente scelto sia preparato e con AC
il suo complementare. Indichiamo inoltre con E l’evento che uno studente superi iltest. La probabilita richiesta e chiaramente la probabilita totale
P (E) = P (A)P (E|A) + P (AC)P (E|AC) , (14)
con P (A) = 0.7. Ma come si valutano P (E|A) e P (E|AC)? Data la strutturadel test, con domande indipendenti, possiamo vederlo come un insieme di 10 provedicotomiche indipendenti con probabilita p costante di successo. Il numero dei suc-cessi (successo qui significa risposta esatta) e una variabile aleatoria binomialeBi(n = 10, p) e la probabilita di superare il test e
10∑x=6
(10
x
)px(1− p)10−x . (15)
Se lo studente e preparato p = 0.8 e dalla (15) otteniamo P (E|A) = 0.9672065.Se lo studente non e preparato, cerca di indovinare la risposta esatta. In tal casop = 1/3 e dalla (15) otteniamo P (E|AC) = 0.07656353. Inserendo i due risultatinella (14) otteniamo infine P (E) = 0.7000136.
b) Dobbiamo trovare P (AC |E). Usando la formula di Bayes
P (AC |E) =P (AC)P (E|AC)
P (E)=
0.02296905
0.7000136= 0.03281229 .
Questo risultato va confrontato con la probabilita iniziale P (AC) = 0.3. Se e no-to che lo studente ha passato il test, la probabilita che non sia preparato scende a0.03281229, circa un decimo del valore iniziale. La differenza fornisce la misuradell’efficacia della prova per discriminare tra studenti preparati e non. Si puo ren-dere il test ancor piu selettivo? Basta, ad esempio, aumentare il numero dellealternative per ogni domanda. E facile verificare che, se ci sono quattro alterna-tive per ogni domanda, P (E|A) rimane invariata mentre P (E|AC) = 0.01972771,P (E) = 0.6829629 e P (AC |E) = 0.005918313/0.6829629 = 0.008665643 < 0.01.
B APPENDICE. TEOREMA DI SCOMPOSIZIONE DELLA VARIANZA 21
B Appendice. Teorema di scomposizione della va-
rianza
Consideriamo un vettore aleatorio p-dimensionale X = (X1, . . . , Xp)T con valore attesoE(X) = µ = (µ1, . . . , µp)T , con µi = E(Xi), i = 1, . . . , p, e matrice di covarianza V (X) =Σ = (σij), dove σii = σ2
i = E{(Xi − µi)2} e la varianza di Xi, i = 1, . . . , p, e σij =
E{(Xi − µi)(Xj − µj)} e la covarianza di Xi e Xj, i, j = 1, . . . , p, i 6= j. Supponiamoinoltre che lo spazio campionario sia dotato di una partizione di eventi Cm con probabilitapm = P (Cm), m = 1, . . . ,M . Gli eventi Cm sono spesso interpretabili come gruppi o classiin cui una popolazione e suddivisa. In tale ipotesi i vettori aleatori subordinati X|Cm,m = 1, . . . ,M hanno, in generale, distribuzioni diverse. Per m = 1, . . . ,M indichiamocon µ(m) e Σ(m) il vettore dei valori medi e la matrice di covarianza di X|Cm.
Il teorema di scomposizione della varianza descrive la relazione tra le matrici di cova-rianza subordinate, Σ(m), e quella non subordinata, Σ. Preliminare ad esso e un semplicelemma che descrive invece la relazione tra valori medi subordinati, µ(m), e quello nonsubordinato, µ.
Lemma 20 Se gli eventi {C1, . . . , CM} sono una partizione dello spazio campionario Scon pm = P (Cm), m = 1, . . . ,M , allora il valore atteso di X e identicamente uguale allamedia ponderata dei valori attesi di X|Cm:
µ = E(X) = EC(E(X|Cm)) =M∑
m=1
P (Cm)E(X|Cm) (16)
=M∑
m=1
pmµ(m) . (17)
Indichiamo con ΣW e ΣB le matrici di covarianza within-groups e between-groups lecui espressioni sono rispettivamente uguali a
ΣW =M∑
m=1
P (Cm)V (X|Cm) =M∑
m=1
pmΣ(m) , (18)
ΣB =M∑
m=1
P (Cm)(E(X|Cm)− E(X))(E(X|Cm)− E(X))T (19)
=M∑
m=1
pm(µ(m) − µ)(µ(m) − µ)T . (20)
Teorema 21 Se gli eventi {C1, . . . , CM} sono una partizione dello spazio campionario Scon pm = P (Cm), m = 1, . . . ,M , allora la matrice di covarianza di X e identicamenteuguale alla somma delle matrici di covarianza within-groups e between-groups:
B APPENDICE. TEOREMA DI SCOMPOSIZIONE DELLA VARIANZA 22
Σ = V (X) = EC(V (X|Cm) + VC(E(X|Cm) (21)
=M∑
m=1
pmΣ(m) +M∑
m=1
pm(µ(m) − µ)(µ(m) − µ)T (22)
= ΣW + ΣB . (23)
Qui i simboli EC(.) e VC(.) indicano gli operatori valore atteso e varianza rispetto aglieventi della partizione {C1, . . . , CM}. Nel caso campionario, il Lemma 20 e il Teorema 21continuano a valere, con parametri delle distribuzioni rimpiazzati dalle rispettive stime, lemede campionarie e le matrici di covarianza campionarie, quest’ultime con divisore parialla numerosita campionaria. Per maggior chiarezza ne riportiamo di seguito l’espressione.
x =M∑
m=1
nm
nx(m) , (24)
S =M∑
m=1
nm
nS(m) +
M∑m=1
nm
n(x(m) − x)(x(m) − x)T (25)
= SW + SB . (26)
Esempio 22 In un campione di studenti universitari comprendente nF = 63 femmine enM = 71 maschi abbiamo rilevato i dati del peso (X1, kg) e della statura (X2, cm). LaFigura 9 mostra la distribuzione congiunta delle vriabili. I vettori delle medie e le matricidi covarianza dei due gruppi sono riportati di seguito.
x(F ) =
(56.31905166.6317
), S(F ) =
(51.93011 12.1865412.18654 34.82217
), (27)
x(M) =
(75.8338180.8211
), S(M) =
(114.66590 40.8625340.86253 36.41096
). (28)
Qual e la matrice di covarianza complessiva? E qual e la frazione della varianzacomplessiva attribuibile alle differenze tra le medie dei due gruppi? Iniziamo a rispondereai due quesiti calcolando la media complessiva come media ponderata delle medie parziali.
x =nF
nx(F ) +
nM
nx(M) =
63
134
(56.31905166.6317
)+
71
134
(75.8338180.8211
)=
(66.6590174.1500
).
Iniziamo ad usare il teorema di scomposizione della varianza calcolando la matrice dicovarianza within-groups. Essa e la media ponderata delle matrici di covarianza parziali.
B APPENDICE. TEOREMA DI SCOMPOSIZIONE DELLA VARIANZA 23
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
● ●
●
●
●
●●
●
●
●
●
●
● ●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
40 50 60 70 80 90 100
160
170
180
190
Peso (kg)
Sta
tura
(cm
)FM
●
●
FM
Figura 9: Diagramma di dispersione del peso e della statura di un campione di studenti(F: femmina, M: maschio).
SW =nF
nS(F ) +
nM
nS(M)
=63
134
(51.93011 12.1865412.18654 34.82217
)+
71
134
(114.66590 40.8625340.86253 36.41096
)'(
85.17072 27.3805327.38053 35.66399
).
Calcoliamo ora la matrice di covarianza between-groups, definita come la matrice divarianza delle medie parziali.
B APPENDICE. TEOREMA DI SCOMPOSIZIONE DELLA VARIANZA 24
SB =nF
n
(x(F ) − x
)(x(F ) − x)T +
nM
n
(x(M) − x
)(x(M) − x)T
=63
134
(−10.33995−7.5183
)(−10.33995 −7.5183
)+
71
134
(9.17486.6711
)(9.1748 6.6711
)=
63
134
(106.91457 77.7388577.73885 56.52483
)+
71
134
(84.17696 61.2060161.20601 44.50358
)'(
94.867 68.97968.979 50.155
).
Siamo giunti al passaggio finale. La matrice di covarianza S e la somma delle matricidi covarianza within-groups e between-groups:
S = SW + SB
'(
85.171 27.38127.381 35.664
)+
(94.867 68.97968.979 50.155
)=
(180.038 96.36096.360 85.819
).
Siamo ora in grado di calcolare la frazione della varianza totale dovuta alle differenzedelle medie parziali dalla media generale. Per il peso, X1, il rapporto s
(B)11 /s11 e circa pari
a 52.7% mentre per la statura, X2, il rapporto s(B)22 /s22 e leggermente piu alto, 58.4%. In
entrambi i casi il rapporto e elevato indicando un importante contributo delle differenzetra le medie parziali alla variabilita generale. In questo esempio, il peso relativo dellavariabilita entro i gruppi e della variabilita tra i gruppi e simile.