Community - Cloud AWS su Google+ Cloud AWS Amazon Web Services cloud-aws.com Amazon Data Pipeline Hangout 28 del 28.08.2014 ● Davide Riboldi ● Massimo Della Rovere Oggi vediamo le caratteristiche generali del servizio di Data Pipeline per spostare dati tra servizi AWS. CLOUD AWS #cloudaws
Transcript
Community - Cloud AWS su Google+
Cloud AWS
Amazon Web Services
cloud-aws.com
Amazon Data Pipeline
Hangout 28 del 28.08.2014
● Davide Riboldi● Massimo Della Rovere
Oggi vediamo le caratteristiche generali del servizio di Data Pipeline per spostare dati tra servizi AWS.
CLOUD AWS
#cloudaws
AWS Data Pipeline - Introduzione
Cloud AWS
● AWS Data Pipeline è un servizio web utilizzabile per automatizzare la trasformazione e lo spostamento dei dati tra risorse AWS o risorse on-premise.
● È possibile definire dei flussi di lavoro basati sui dati, facendo in modo che le varie attività dipendano dal completamento delle attività precedenti.
● Ad esempio possiamo archiviare i log di un web server in S3, per poi avviare settimanalmente un cluster Amazon EMR che li analizza e genera un report.
AWS Data Pipeline - Introduzione
Cloud AWS
● Tramite questo servizio possiamo disegnare complessi flussi di operazioni, spostare dei dati e memorizzare dei risultati tra i servizi AWS, tutto senza dover scrivere complicati script e mettere in produzione risorse specifiche per questo tipo di elaborazioni.
● Tutti gli eventuali errori o la disponibilità dei servizi vengono gestiti direttamente dal servizio che si preoccupa di eseguire e fermare le elaborazioni nei momenti giusti, eseguendo anche dei controlli di stato per eseguire le operazioni successive.
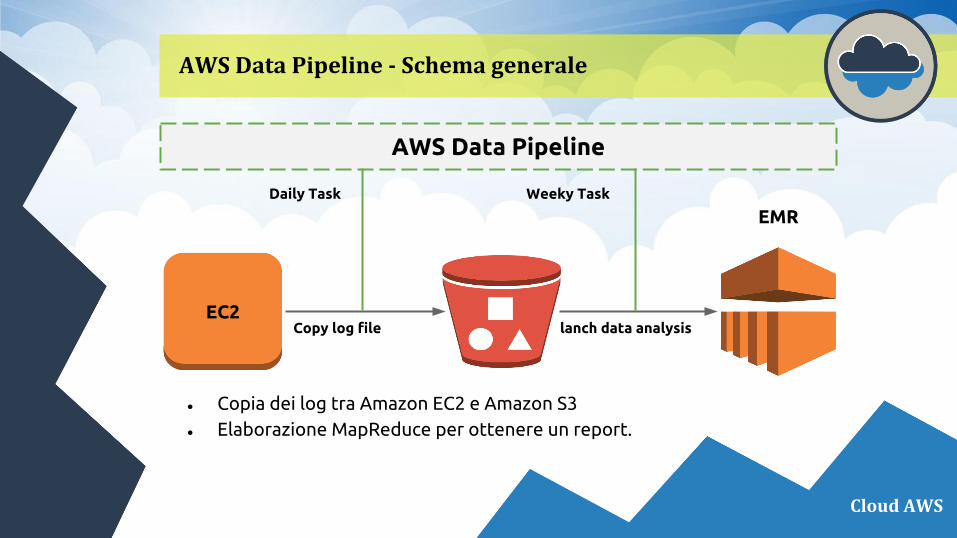
AWS Data Pipeline - Schema generale
Cloud AWS
AWS Data Pipeline
Copy log file lanch data analysis
Daily Task Weeky Task
EC2
EMR
● Copia dei log tra Amazon EC2 e Amazon S3● Elaborazione MapReduce per ottenere un report.
AWS Data Pipeline - Accesso al servizio
Cloud AWS
● Per accedere al servizio basta entrare nella management console, selezionare la regione geografica e il menu di AWS Data Pipeline. I passaggi fondamentali del servizio sono racchiusi in tre operazioni: Definizione, schedulazione e attivazione.
AWS Data Pipeline - Definizione
Cloud AWS
● specifica la logica della gestione dei dati e determina le attività che dovranno essere eseguite, le schedula e le assegna ai task runner. (vediamo in seguito)
● Se un’attività non viene completata, si ritenta l’operazione in base alle opzioni, e se necessario, il servizio le può riassegnare ad un altro task runner.
● Se l’attività fallisce ripetutamente, è possibile configurare la pipeline per l’invio di una notifica.
● La definizione può essere creata tramite: la console, un file JSON oppure attraverso AWS SDK.
AWS Data Pipeline - Task Runner
Cloud AWS
● Effettua un polling al servizio di Data Pipeline, in cerca di attività da eseguire. Quando una attività viene assegnata ad un task runner, quest’ultimo esegue tale attività e mantiene informato il servizio di Data Pipeline sul suo stato di esecuzione.
● Può essere installato in automatico sulle risorse che vengono lanciate dal servizio o essere installato manualmente sulle risorse che gestiamo, come istanze EC2 o server all’interno della nostra azienda.
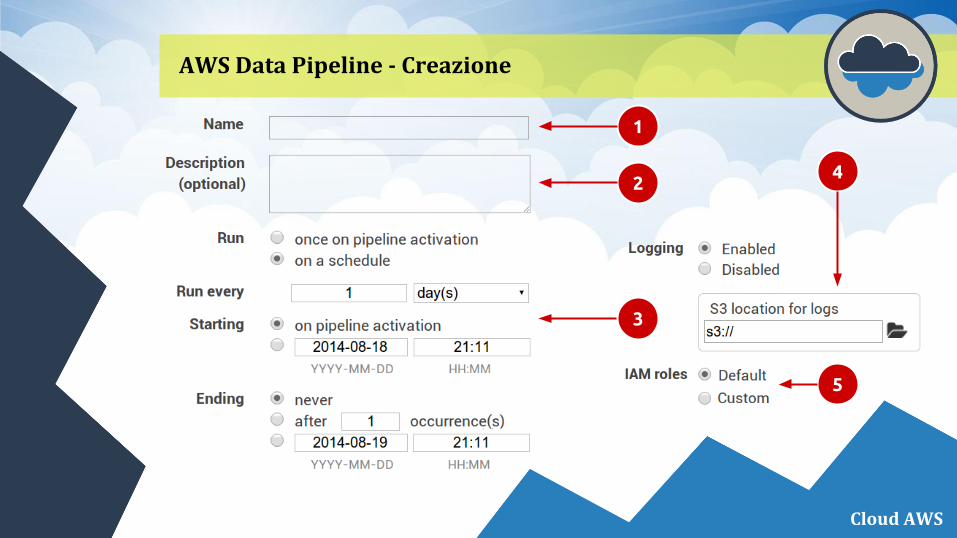
AWS Data Pipeline - Creazione
Cloud AWS
1
2
3
4
5
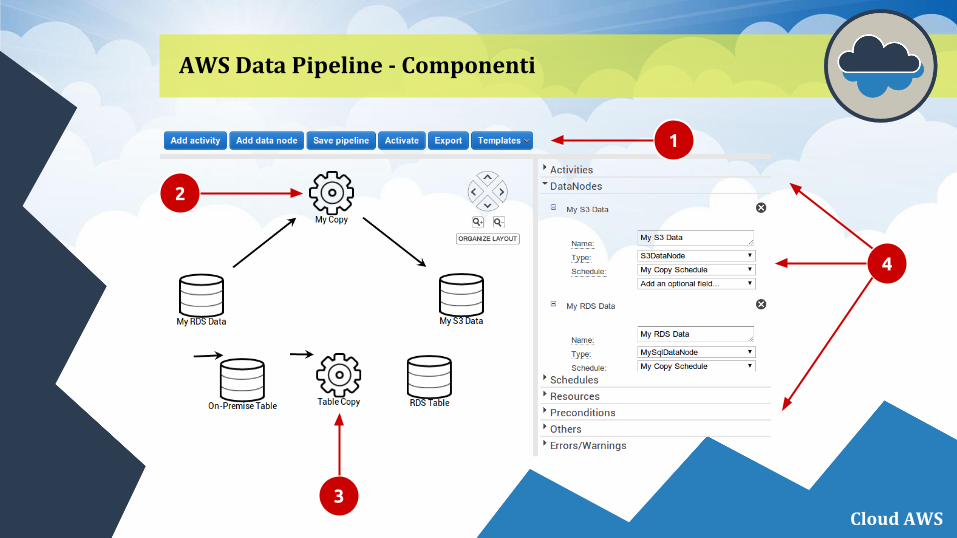
AWS Data Pipeline - Componenti
Cloud AWS
1
2
4
3
AWS Data Pipeline - Attività
Cloud AWS
● Activities: è una componente della pipeline che definisce il lavoro da eseguire. AWS Data Pipeline fornisce una serie di attività preimpostate che possono coprire gli scenari più comuni, ad esempio: spostare i dati da una posizione ad un’altra, l’esecuzione di una query Hive e così via. Le attività sono estendibili, in modo da poter eseguire i propri script personalizzati e supportare infinite combinazioni. Le attività supportate sono:
○ CopyActivity – copia i dati da una posizione all’altra. ○ EmrActivity – esegue un’attività su un Cluster EMR. ○ HiveActivity – esegue una Query Hive su un cluster Amazon EMR. ○ HiveCopyActivity – esegue una query Hive su cluster EMR con supporto avanzato. ○ PigActivity – esegue uno script di Pig su un cluster Amazon EMR. ○ RedshiftCopyActivity – copia i dati da e verso le tabelle di Amazon Redshift. ○ ShellCommandActivity – esegue un comando personalizzato di shell UNIX/Linux. ○ SqlActivity – esegue una query SQL su un database.
AWS Data Pipeline - DataNodes e Schedules
Cloud AWS
● DataNodes: il DataNodes definisce la posizione e il tipo di dati che una Activity Pipeline utilizza come input o output. Il servizio supporta i seguenti tipi di nodi:
○ DynamoDBDataNode – una tabella DynamoDB che contiene i dati da utilizzare. ○ RedshiftDataNode – una tabella di Amazon Redshift con i dati da utilizzare. ○ S3DataNode – una posizione in Amazon S3 che contiene uno o più file da utilizzare. ○ SqlDataNode – query di database e tabella MySQL con i dati da utilizzare.
● Schedules: questo componente definisce la tempistica di un evento programmato, ad esempio quando viene eseguita un’attività. Le opzioni possono essere: una sola esecuzione al momento dell’attivazione della pipeline, oppure ripetute nel tempo attivando la schedulazione (esecuzioni giornaliere, settimanali, mensili etc.).
AWS Data Pipeline - Resources e Preconditions
Cloud AWS
● Resources: è una risorsa computazionale che esegue un lavoro specificato in una Activity Pipeline. AWS Data Pipeline supporta i seguenti tipi di risorse:
○ Ec2Resource – istanza EC2 che esegue il lavoro definito da un’attività di pipeline. ○ EmrCluster – Un cluster Amazon EMR che esegue il lavoro definito da un’attività.
● Preconditions: contiene le condizioni che devono essere verificate prima che un’attività possa essere eseguita. Ad esempio, è possibile verificare che i dati all’interno di un nodo siano presenti prima di iniziare un’attività di copia. Ci sono due tipi di Preconditions:
○ System managed: viene eseguito dal servizio e non richiede risorse computazionali. ○ User managed: viene eseguito solo su risorse computazionali da noi specificate.