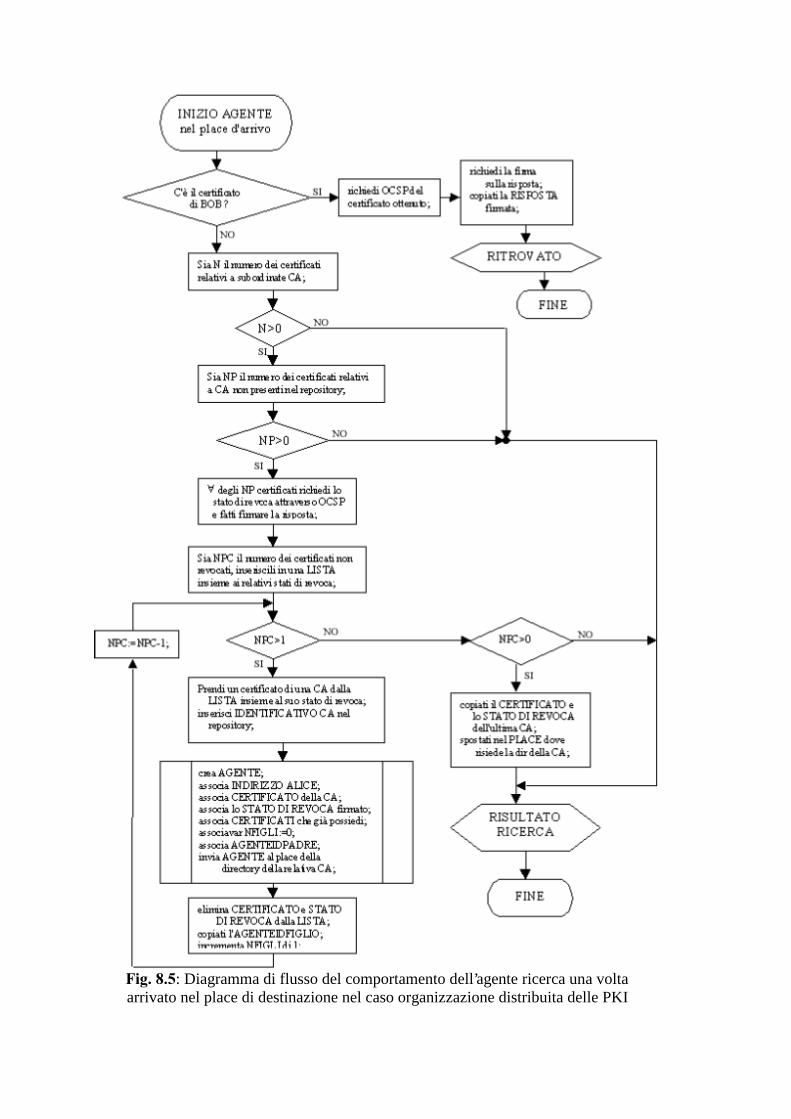
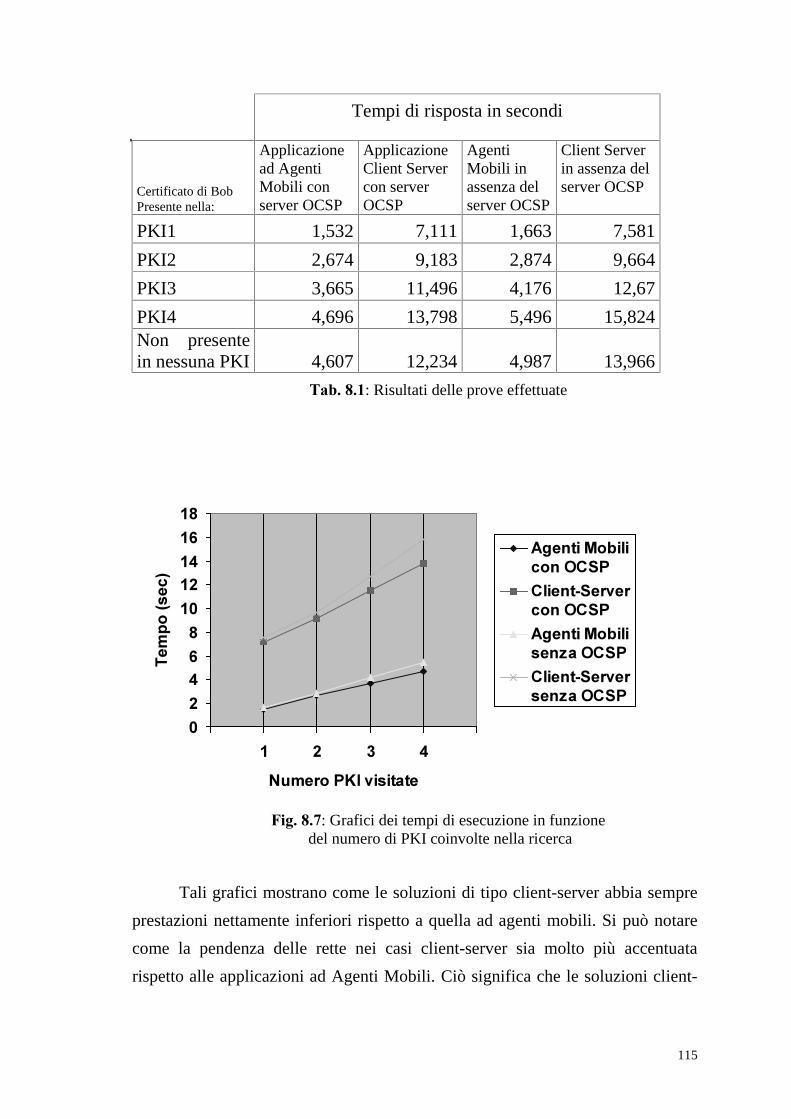
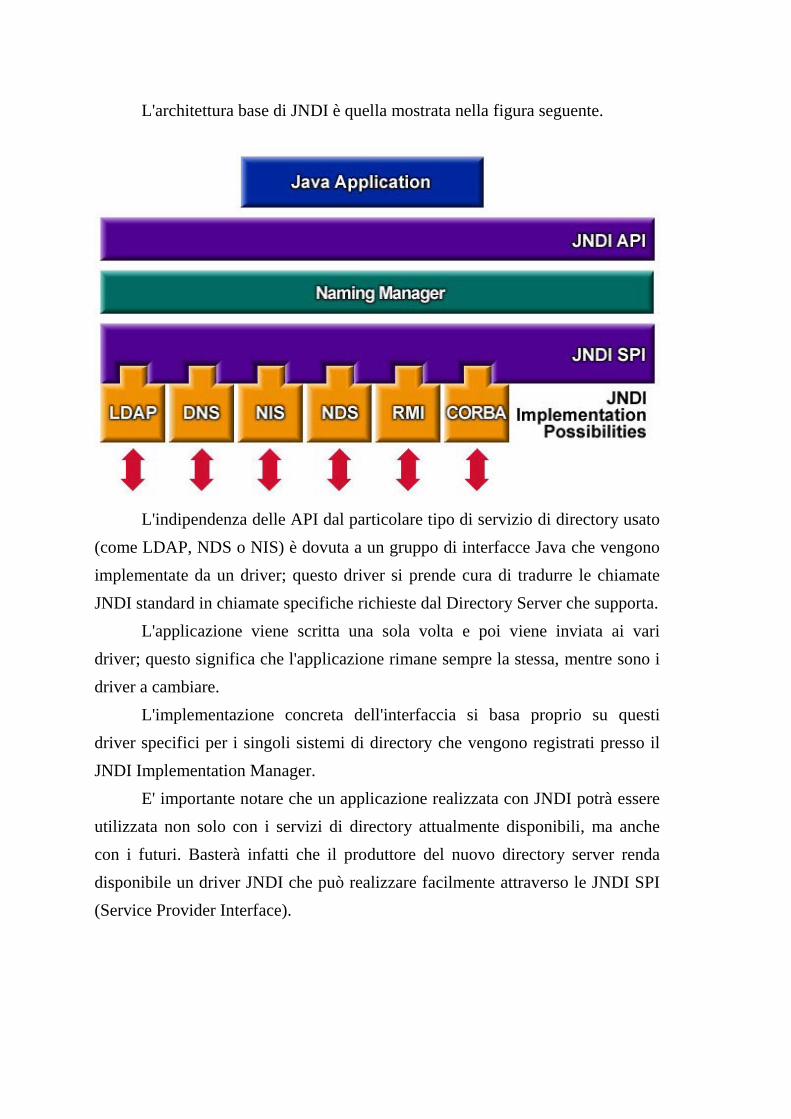
Page 1
8QLYHUVLWj��GHJOL��6WXGL��GL��%RORJQD
FACOLTA’ DI INGEGNERIA
Corso di Laurea in Ingegneria Informatica
Reti di Calcolatori
,QIUDVWUXWWXUH�D�&KLDYH�3XEEOLFD�H
$JHQWL�0RELOL�SHU�LO�UHFXSHUR�H�OD
FRQYDOLGD�GHL�&HUWLILFDWL�(OHWWURQLFL
Tesi di Laurea di: Relatore:
ANGELO COLANTONIO Chiar.mo Prof. Ing. ANTONIO CORRADI
Correlatori:
Chiar.mo Prof. Ing. EUGENIO FALDELLA
Dott.ssa Ing. REBECCA MONTANARI
��$QQR�$FFDGHPLFR��������
Page 2
3DUROH�&KLDYH�
Sicurezza
Agenti Mobili
Firma Digitale
Sistemi di Certificazione
Liste di Revoca
Page 3
$L�PLHL�JHQLWRUL
FRQ�LPPHQVR�DPRUH
Page 5
I
,1',&(
,1752'8=,21(����������������������������������������������������������������������������������������������������������� �
&$3,72/2����6,&85(==$�(�&5,772*5$),$����������������������������������������������������� �
1.1 INTRODUZIONE ..................................................................................................... 31.2 CRITTOGRAFIA A CHIAVE SIMMETRICA ................................................................. 51.3 CRITTOGRAFIA A CHIAVE PUBBLICA ..................................................................... 71.4 LA FIRMA DIGITALE .............................................................................................. 91.5 LA NECESSITÀ DI COPPIE DI CHIAVI DISTINTE PER CIFRATURA E FIRMA............... 121.6 CERTIFICATI ELETTRONICI.................................................................................. 14
&$3,72/2����6,67(0,�',�&(57,),&$=,21(���������������������������������������������������� ��
2.1 INTRODUZIONE ................................................................................................... 172.2 GESTIONE DEI CERTIFICATI ELETTRONICI............................................................ 18����� *HVWLRQH�GHOOH�FKLDYL ����������������������������������������������������������������������������������� ������� &LFOR�GL�YLWD�GHL�FHUWLILFDWL��������������������������������������������������������������������������� ��
2.3 LO STANDARD X.509 PER I CERTIFICATI............................................................. 21
&$3,72/2����,1)5$67587785(�$�&+,$9(�38%%/,&$������������������������������� ��
3.1 INTRODUZIONE ................................................................................................... 253.2 REQUISITI DI UNA PKI ........................................................................................ 263.3 COMPONENTI DI UNA PKI ................................................................................... 273.4 DEFINIZIONE DI CAMMINO DI CERTIFICAZIONE.................................................... 293.5 FUNZIONALITÀ DI UNA PKI................................................................................. 313.6 LA REVOCA DI UN CERTIFICATO.......................................................................... 333.7 MODELLI ORGANIZZATIVI DI PKI........................................................................ 37����� 6WUXWWXUD�JHUDUFKLFD ����������������������������������������������������������������������������������� ������� 6WUXWWXUD�GLVWULEXLWD������������������������������������������������������������������������������������ ��
&$3,72/2����6,67(0,�',�',5(&725<��������������������������������������������������������������� ��
4.1 INTRODUZIONE ................................................................................................... 434.2 ALCUNI ESEMPI DI DIRECTORY SERVICE E LORO LIMITAZIONI. ........................... 444.3 LA SOLUZIONE ATTRAVERSO LA DEFINIZIONE DI UNO STANDARD:X.500............ 454.4 IL MODELLO INFORMATIVO ................................................................................ 484.5 IL MODELLO FUNZIONALE .................................................................................. 494.6 IL PROTOCOLLO DI COMUNICAZIONE DAP.......................................................... 524.7 METODI PER LA RICERCA DELLE INFORMAZIONI. ................................................ 544.8 UN PROTOCOLLO "LEGGERO" DI ACCESSO ALLE DIRECTORY PER INTERNET LDAP55
&$3,72/2����6,67(0,�',675,%8,7,�(�02%,/,7$�'(/�&2',&(��������������� ��
5.1 INTRODUZIONE ................................................................................................... 575.2 I SISTEMI DISTRIBUITI ......................................................................................... 575.3 MODELLO CLIENT-SERVER................................................................................. 615.4 MOBILITÀ DEL CODICE........................................................................................ 625.5 CONTROLLO SULLA LOCAZIONE DELLE RISORSE................................................. 635.6 LINGUAGGI A CODICE MOBILE............................................................................. 64
Page 6
5.7 PARADIGMI DI PROGETTAZIONE BASATI SULLA MOBILITÀ DEL CODICE................66����� 5HPRWH�(YDOXDWLRQ �������������������������������������������������������������������������������������������� &RGH�RQ�GHPDQG ������������������������������������������������������������������������������������������������ $JHQWL�PRELOL �������������������������������������������������������������������������������������������������
5.8 AGENTI MOBILI ...................................................................................................69����� 0LJUD]LRQH ��������������������������������������������������������������������������������������������������������� &RPXQLFD]LRQH�WUD�DJHQWL ��������������������������������������������������������������������������������� 6LFXUH]]D �������������������������������������������������������������������������������������������������������
5.8.3.1 Riservatezza ed integrità ..........................................................................735.8.3.2 Autenticazione..........................................................................................735.8.3.3 Autorizzazione e controllo degli accessi ..................................................73
5.9 JAVA UN LINGUAGGIO ADATTO PER I SISTEMI AD AGENTI ....................................745.10 SISTEMI ESISTENTI AD AGENTI MOBILI.................................................................78������ 7HOHVFULSW ������������������������������������������������������������������������������������������������������������� 2GLVVH\����������������������������������������������������������������������������������������������������������������� $JOHWV ������������������������������������������������������������������������������������������������������������������� 9R\DJHU ���������������������������������������������������������������������������������������������������������
&$3,72/2����620$�81�6,67(0$�$'�$*(17,�02%,/, �����������������������������������
6.1 INTRODUZIONE ....................................................................................................836.2 ARCHITETTURA GENERALE DEL SISTEMA ............................................................846.3 AGENTI MOBILI...................................................................................................856.4 MOBILITÀ ............................................................................................................866.5 COMUNICAZIONE.................................................................................................87����� &RPXQLFD]LRQH�WUD�$JHQWL�VLWXDWL�VX�SODFH�GLYHUVL ������������������������������������������� &RPXQLFD]LRQH�WUD�$JHQWL�VLWXDWL�VXOOR�VWHVVR�SODFH �����������������������������������
6.6 SICUREZZA ..........................................................................................................89����� 3URWH]LRQH�GHOODPELHQWH ����������������������������������������������������������������������������������� 3URWH]LRQH�GHJOL�DJHQWL ���������������������������������������������������������������������������������
&$3,72/2����6,67(0,�3(5�,/�5(&83(52�'(,�&(57,),&$7,�����������������������
7.1 INTRODUZIONE....................................................................................................917.2 RICERCA E CONVALIDA DEI CAMMINI DI CERTIFICAZIONE ...................................91����� 3.,�FRQ�VWUXWWXUD�JHUDUFKLFD ���������������������������������������������������������������������������� 3.,�FRQ�VWUXWWXUD�GLVWULEXLWD ����������������������������������������������������������������������������� &RQIURQWR�WUD�OH�GXH�RUJDQL]]D]LRQL�GL�3.,�������������������������������������������������
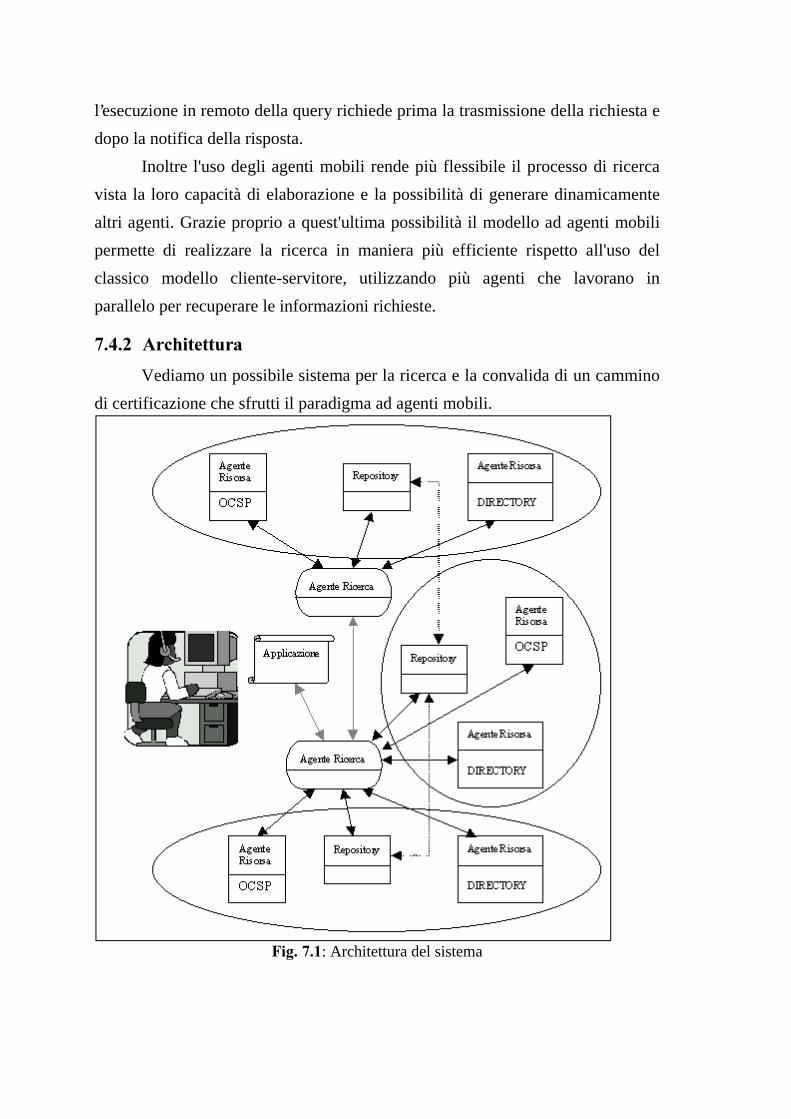
7.3 SISTEMA CLIENT/SERVER: I PROTOCOLLI LDAP E OCSP...................................957.4 UN SISTEMA AD AGENTI MOBILI PER LA RICERCA E CONVALIDA DEI CERTIFICATI95����� 0RWLYD]LRQL��������������������������������������������������������������������������������������������������������� $UFKLWHWWXUD �������������������������������������������������������������������������������������������������������� $JHQWL�GL�VHUYL]LR�H�VHUYL]L�UHDOL]]DWL������������������������������������������������������������������ 8WLOL]]R�GHL�YDUL�DJHQWL ��������������������������������������������������������������������������������������� 7HFQLFD�GL�ULFHUFD�H�FRQYDOLGD�GHO�FDPPLQR�GL�FHUWLILFD]LRQH ��������������������
7.4.5.1 PKI con struttura gerarchica.....................................................................987.4.5.2 Gestione dell’insuccesso...........................................................................99
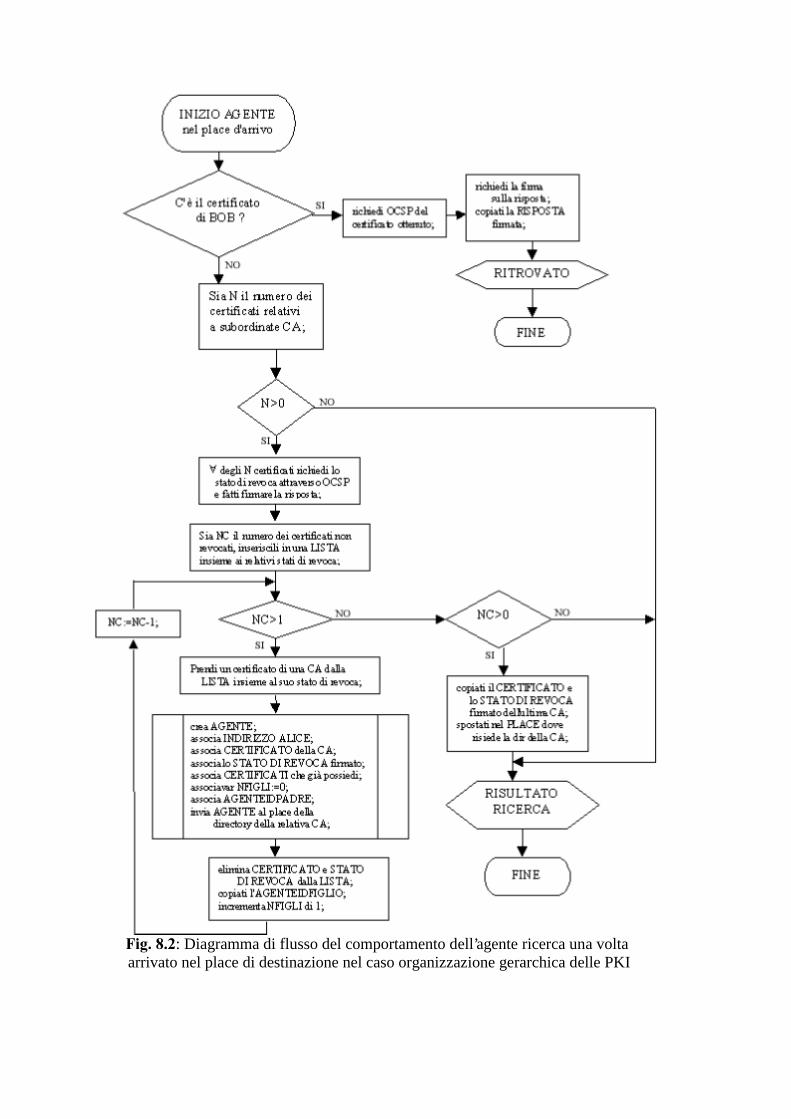
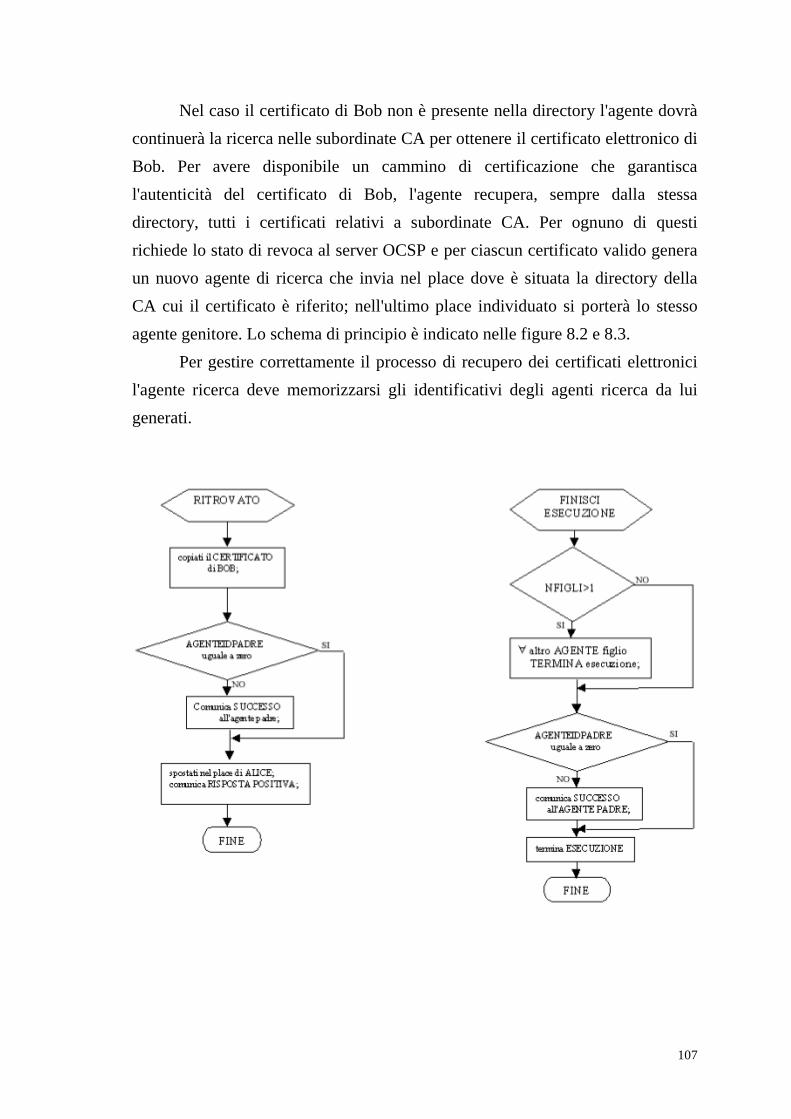
����� 3.,�FRQ�VWUXWWXUD�GLVWULEXLWD ����������������������������������������������������������������������������� &RQYDOLGD�GHO�FDPPLQR�LQ�DVVHQ]D�GHO�VHUYL]LR�2&63 ����������������������������������� 2VVHUYD]LRQL�H�SRVVLELOL�PLJOLRULH ����������������������������������������������������������������
&$3,72/2����,03/(0(17$=,21(�(�5,68/7$7, ��������������������������������������������
Page 7
III
8.1 INTRODUZIONE ................................................................................................. 1038.2 LA SCELTA DEL SUPPORTO ................................................................................ 1038.3 L’INTERFACCIA TRA IL SISTEMA E I SERVIZI DI DIRECTORY............................... 1048.4 IL SISTEMA PER IL RECUPERO E LA CONVALIDA DEI CERTIFICATI AD AGENTI
MOBILI........................................................................................................................ 1048.5 LA SICUREZZA DEGLI AGENTI RICERCA ............................................................. 111����� 3URWH]LRQH�VXOOD�UHWH�GL�FRPXQLFD]LRQH ��������������������������������������������������� �������� 3URWH]LRQH�QHL�SODFH�GL�HVHFX]LRQH����������������������������������������������������������� �������� /H�YDULDELOL�LQWHUQH ����������������������������������������������������������������������������������� ���
8.6 I TEST DELL’APPLICAZIONE E L’ANALISI DELLE PRESTAZIONI ............................ 112
&$3,72/2����&21&/86,21,�������������������������������������������������������������������������������� ���
$33(1',&(��$&&(662�$�',5(&725<�(�/,1*8$**,2�-$9$���-1',� ���� ���
%,%%/,2*5$),$ ������������������������������������������������������������������������������������������������������ ���
Page 9
1
,1752'8=,21(
La sempre maggiore diffusione delle reti di calcolatori, grazie soprattutto
all’espansione di Internet e del Web, sta portando profonde innovazioni nei
processi economici e sociali, offrendo l’opportunità di realizzare su rete servizi di
tipo amministrativo, commerciale e finanziario. Indubbiamente l’utilizzo della
rete comporta innumerevoli vantaggi dalla possibilità di scambiare informazioni
in tempi rapidissimi e senza vincoli geografici, alla praticità di trattamento e di
archiviazione dei dati.
Tuttavia le informazioni che viaggiano attraverso una rete così aperta
possono essere intercettate e subire alterazioni e contraffazioni. Al fine di
proteggere le comunicazioni su rete dai pericoli derivanti da un uso illecito delle
informazioni è quindi indispensabile fornire contromisure di sicurezza mirate a
garantire l’integrità, l’autenticità, la riservatezza e il non ripudio dei dati.
La tecnologia della crittografia a chiave pubblica sembra fornire la
risposta più adeguata a queste esigenze di sicurezza, che una rete distribuita come
Internet richiede; in particolare permette l’autenticazione dell’origine dei dati,
l’integrità e il supporto per il non ripudio attraverso la firma digitale, e garantisce
la riservatezza tramite operazioni di cifratura dei dati.
Affinché tale tecnica sia utilizzabile su larga scala, si richiede la
realizzazione di infrastrutture a chiave pubblica (PKI), con il compito specifico
di gestire il ciclo di vita delle chiavi crittografiche. In uno scenario costituito da
una molteplicità di PKI è impensabile che ogni utente abbia diretta conoscenza
delle chiavi pubbliche di ogni potenziale interlocutore, sotto forma di certificati
elettronico, o delle chiavi pubbliche delle corrispondenti autorità di certificazione
competenti. Occorre, quindi, disporre di un meccanismo corretto di ritrovamento
e convalida dei certificati elettronici degli interlocutori appartenenti a differenti
domini di sicurezza.
Nella costruzione di infrastrutture a chiave pubblica scalabili, una delle
difficoltà principali consiste nell’individuare e successivamente validare una
sequenza di certificati che garantisca la corretta associazione tra una chiave
Page 10
pubblica e una certa identità fisica. A tal fine nasce l'esigenza di progettare
sistemi affidabili ed efficienti per il recupero e la verifica dei certificati.
Si ritiene che la ricerca dei certificati elettronici in ambiente distribuito
possa essere notevolmente migliorata, sia in termini di efficienza che di riduzione
del traffico di rete, utilizzando il paradigma di programmazione ad Agenti
Mobili; le caratteristiche peculiari di questo modello lo rendono particolarmente
adatto alla ricerca di informazioni in sistemi distribuiti.
Lo scopo di questa tesi è quello di proporre e sperimentare delle soluzioni
efficaci, basate su agenti mobili, per costruire e verificare cammini di
certificazione in tempi brevi.
Inizialmente è stata svolta un’analisi dei requisiti progettuali e funzionali
di un’infrastruttura a chiave pubblica con particolare attenzione al processo di
ricerca dei certificati e di determinazione dei cammini di certificazione (Capitoli
1-3); si è in particolare analizzato l’organizzazione dei sistemi di Directory
X.500 per comprendere come i certificati possono essere pubblicati e recuperati
(Capitolo 4). Successivamente è stato analizzato il modello di programmazione
ad agenti mobili per comprendere lo stato dell’arte di tale tecnologia e il suo
utilizzo per applicazioni di ricerca di informazioni (Capitoli 5-6). Una volta a
disposizione delle conoscenze e degli strumenti necessari, si è passati alla
definizione delle specifiche di un sistema ad agenti mobili per il recupero e la
convalida dei certificati e alla realizzazione di un'applicazione prototipale
(Capitoli 7-8). Infine si è svolta un’analisi delle prestazioni del sistema realizzato
(Capitoli 8-9).
Page 11
3
&DSLWROR����6,&85(==$�(�&5,772*5$),$
���� ,QWURGX]LRQH
Molti dizionari definiscono la sicurezza come misura necessaria per
proteggersi da situazioni di spionaggio, di attacco o di crimine in genere. Dal
punto di vista dell'informatica, per sicurezza si intendono tutte le attività che
permettono la protezione dei sistemi aziendali attraverso la verifica delle
autorizzazioni, dove solo utenti identificati dovrebbero essere abilitati all'accesso
alle reti, ai sistemi, alle applicazioni, ai dati e questo sulla base di liste per il
controllo degli accessi.
Per inquadrare meglio il problema è opportuno rifarsi al modello di
riferimento proposto dall'ISO (International Organization for Standardization)
che individua cinque classi di funzionalità necessarie per garantire il desiderato
livello di sicurezza. Queste sono:
1) FRQILGHQ]LDOLWj:� con tale funzionalità si vuole impedire di rilevare
informazioni riservate ad entità non autorizzate alla conoscenza di tali
informazioni;
2) LQWHJULWj�GHL�GDWL:� i servizi di integrità dei dati proteggono contro gli attacchi
attivi1 finalizzati ad alterare illegittimamente il valore di un dato; l'alterazione
di un messaggio può comprendere la cancellazione, la modifica, o il
cambiamento dell'ordine dei dati;
3) DXWHQWLFD]LRQH: i servizi di autenticazione garantiscono l'accertamento
dell'identità e si suddividono in:
• servizi di autenticazione dell'entità: in questo caso si autentica l'identità
presentata ad un entità remota che partecipa ad una sessione di
1 Si definisce attacco passivo un attacco con cui un intrusore intercetta semplicemente un flusso di
informazioni, senza apportare alcun genere di modifiche; con un attacco attivo, invece, l’intrusoreintroduce alterazioni al flusso di dati che possono comprendere modifica del contenuto informativo,eliminazione di tutto o solo di alcune parti del messaggio o trattenimento del messaggio per poi replicarloin tempi successivi.
Page 12
comunicazione (le password sono un esempio tipico di strumenti atti ad
ottenere autenticazione dell'entità);
• servizi di autenticazione dell'origine dei dati: in questo caso si autentica
l'identità che il mittente di un messaggio rivendica di avere;
4) FRQWUROOR�GHJOL�DFFHVVL:�una volta che l'autenticazione è avvenuta, è possibile
eseguire un controllo degli accessi in modo tale da verificare che siano
utilizzate solo quelle risorse o servizi ai quali si è autorizzati;
5) VHUYL]L�GL�QRQ�ULSXGLR�� tali servizi hanno la finalità di impedire che un'entità
riesca successivamente a rinnegare con successo la partecipazione a
transazione o comunicazione a cui in realtà ha preso parte; i servizi di non
ripudio non prevengono la sconfessione di una comunicazione o di una
transazione, forniscono, invece, gli elementi per dimostrare in caso di
contenzioso l'evidenza dei fatti. Se è vero che autenticazione ed integrità dei
dati sono elementi essenziali nell'implementazione di un servizio di non
ripudio senza, il non ripudio, tuttavia, va oltre le problematiche di
autenticazione ed integrità: è, infatti, lo strumento con cui dimostrare ad una
terza parte e dopo l'accadimento del fatto che una comunicazione o
transazione è stata originata o avviata da una certa entità o consegnata ad una
certa entità. Si pensi ad esempio al caso di una persona, Alice, che invia un
ordine di acquisto di beni a Bob; la paternità dell'ordine di acquisto viene
attribuita con assoluta certezza ad Alice se si adotta un servizio corretto di
non ripudio; in caso di contenzioso Bob può dimostrare con assoluta certezza
che l'ordine di acquisto è stato spiccato da Alice. Nei documenti cartacei,
quali contratti, ordini, bonifici, è la firma autografa ad essere utilizzata per
garantire il servizio di non ripudio, nei documenti elettronici è, invece, la
tecnica crittografica di firma digitale2.
La crittografia [FAQC98] [S96] con le sue tecniche di cifratura e di firma
digitale è in grado di fornire i servizi di sicurezza sopra descritti; pertanto
rappresenta una componente basilare nell'implementazione di un sistema di
sicurezza.
2 Vedremo nei paragrafi seguenti cosa si intende veramente
Page 13
5
La crittografia è lo studio della codifica e della decodifica dei dati. Il
termine FULWWRJUDILD viene dalle parole greche NU\SWRV che significa QDVFRVWR, e
JUDSKLD che significa VFULWWXUD.
Le tecniche crittografiche permettono quindi di cifrare e successivamente
decifrare un testo scritto; questo è possibile grazie all'algoritmo crittografico che
fornisce le funzioni di trasformazione di un testo da testo in chiaro a testo cifrato
e viceversa. Gli algoritmi crittografici si suddividono in due classi distinte:
DOJRULWPL�D�FKLDYH�VLPPHWULFD e�DOJRULWPL D�FKLDYH�SXEEOLFD�
���� &ULWWRJUDILD�D�FKLDYH�VLPPHWULFD
Gli algoritmi simmetrici utilizzano un singola "chiave" matematica sia per
la codifica che per la decodifica dei dati. Un messaggio sicuro viene cifrato dal
mittente utilizzando una chiave nota solamente a lui ed al destinatario.
Il principio matematico su cui si basa l'algoritmo è che cifrando un testo in
chiaro con una certa chiave e decifrando il testo cifrato con la medesima chiave
si ottiene nuovamente il testo in chiaro.
)LJ�����: Schema di funzionamento di un algoritmo Simmetrico
Vediamo ora l'implementazione di un protocollo crittografico sicuro che
utilizza la tecnica di crittografia a chiave simmetrica, finalizzato a garantire una
comunicazione confidenziale tra due interlocutori, lo schema di funzionamento è
indicato in figura 1.1.
Chiave Segreta Chiave Segreta
Testo Testo Testoin chiaro criptato in chiaro
Codifica Decodifica
Algoritmo Algoritmo
Page 14
Siano Alice e Bob i due interlocutori che si devono inviare messaggi
confidenziali, siano Eve3 e Mallet i potenziali intrusori, l’uno passivo, l’altro
attivo. Definiti gli attori in gioco, i passi del protocollo si possono sintetizzare
nei seguenti:
1) Alice e Bob concordano, innanzitutto, un sistema crittografico, ossia il tipo di
algoritmo simmetrico e la lunghezza della chiave da utilizzare;
2) Alice e Bob concordare e si distribuiscono una chiave segreta;
3) Alice cifra il messaggio in chiaro utilizzando l’algoritmo e la chiave di cui ai
punti precedenti;
4) Alice invia il messaggio cifrato a Bob;
5) Bob decifra il messaggio con lo stesso algoritmo e la stessa chiave.
Tale protocollo presenta alcune vulnerabilità ed è soggetto ad attacchi sia
passivi che attivi. Il punto critico del protocollo è sicuramente quello in cui Alice
e Bob concordano quale chiave segreta utilizzare. È di fondamentale importanza
che la distribuzione della chiave segreta avvenga in modo assolutamente sicuro.
Data anche per assunta una distribuzione sicura della chiave, vediamo a
quali tipi di attacchi è soggetto il protocollo.
Che cosa potrebbe fare Eve, che ricopre il ruolo di un intrusore passivo, se
intercettasse le comunicazioni tra Alice e Bob? E se fosse Mallet che ha il ruolo
di intrusore attivo, ad interporsi tra Alice e Bob?
Se Eve non ha in alcun modo la possibilità di conoscere la chiave segreta
concordata tra Alice e Bob, l'unico tipo di attacco di crittoanalisi possibile è
quello cosiddetto "ciphertextonly attack"4 a cui la maggior parte degli algoritmi
sono, tuttavia, resistenti; se, invece, Eve conosce la chiave simmetrica di
cifratura, è in grado ovviamente di interpretare il contenuto dei messaggi tra
Alice e Bob.
Mallet, invece, può intercettare i messaggi scambiati tra Alice e Bob,
alterarne il contenuto inficiandone l'integrità del contenuto, o effettuare delle
sostituzioni.. Se Mallet è venuto a conoscenza della chiave segreta che Alice e
3 Eve richiama il termine inglese "eavesdropper" con cui si indica colui che sta in ascolto; Eve è l'attore
in gioco che nei protocolli crittografici ricopre il ruolo dell'intrusore passivo. Mallet, invece, sta per"malicious active attacker" e ricopre il ruolo dell'intrusore attivo.
4 Il crittoanalista dispone solo di campioni di testo cifrato; a partire da tali campioni tenta di dedurre lachiave di cifratura o di trovare un algoritmo alternativo attraverso risalire al testo in chiaro.
Page 15
7
Bob hanno concordato, Mallet può intercettare i messaggi inviati da Alice a Bob
e sostituirli con messaggi non autentici. Alla ricezione, Bob non è in grado di
distinguere chi effettivamente è il vero mittente dei messaggi, continua a pensare
che l'originatore dei dati sia Alice; il protocollo descritto, quindi, non fornisce
alcun tipo di autenticazione dell'origine dei dati.
Dalle considerazioni di cui sopra emerge chiaramente che i protocolli
crittografici di comunicazione realizzati con algoritmi simmetrici presentano sia
difficoltà implementative che limiti di sicurezza. Il problema implementativo
principale è legata alla difficoltà di distribuire le chiavi simmetriche in modo
sicuro e su larga scala; se si assume che una chiave distinta è richiesta per ogni
coppia di interlocutori, il numero di chiavi da distribuire aumenta drasticamente
all'aumentare delle parti in gioco; se, infatti, n sono le parti coinvolte, il numero
di chiavi da distribuire è pari a n*(n-l)/2. 1 limiti di sicurezza, invece, sono dati
dalla mancanza, a livello di protocollo, di strumenti che garantiscano integrità ed
autenticazione dell'origine dei dati.
���� &ULWWRJUDILD�D�FKLDYH�SXEEOLFD
Fino a poco più di vent'anni fa erano conosciuti solo gli algoritmi a chiave
simmetrica; nel 1976 Diffie ed Hellman [DH76] presentarono un protocollo per
lo scambio di una chiave segreta attraverso un canale insicuro; tale meccanismo
era stato inteso essenzialmente per risolvere il problema dell'avvio di un normale
sistema di cifratura a chiavi simmetriche, ma in realtà ha posto le basi della
crittografia a chiave pubblica.
Gli algoritmi a chiave pubblica o altrimenti detti asimmetrici, sono
progettati in modo tale che la chiave di codifica risulta differente dalla chiave di
decodifica. Quello che viene cifrato con la chiave di codifica, detta chiave
pubblica, può essere decifrato solo con l'altra chiave di decodifica, detta chiave
privata. La conoscenza della chiave pubblica non permette di determinare quella
privata (si tratta di un problema computazionalmente complesso). Questo è il
motivo per cui la chiave di cifratura può essere resa pubblica senza
compromettere la sicurezza del sistema.
Page 16
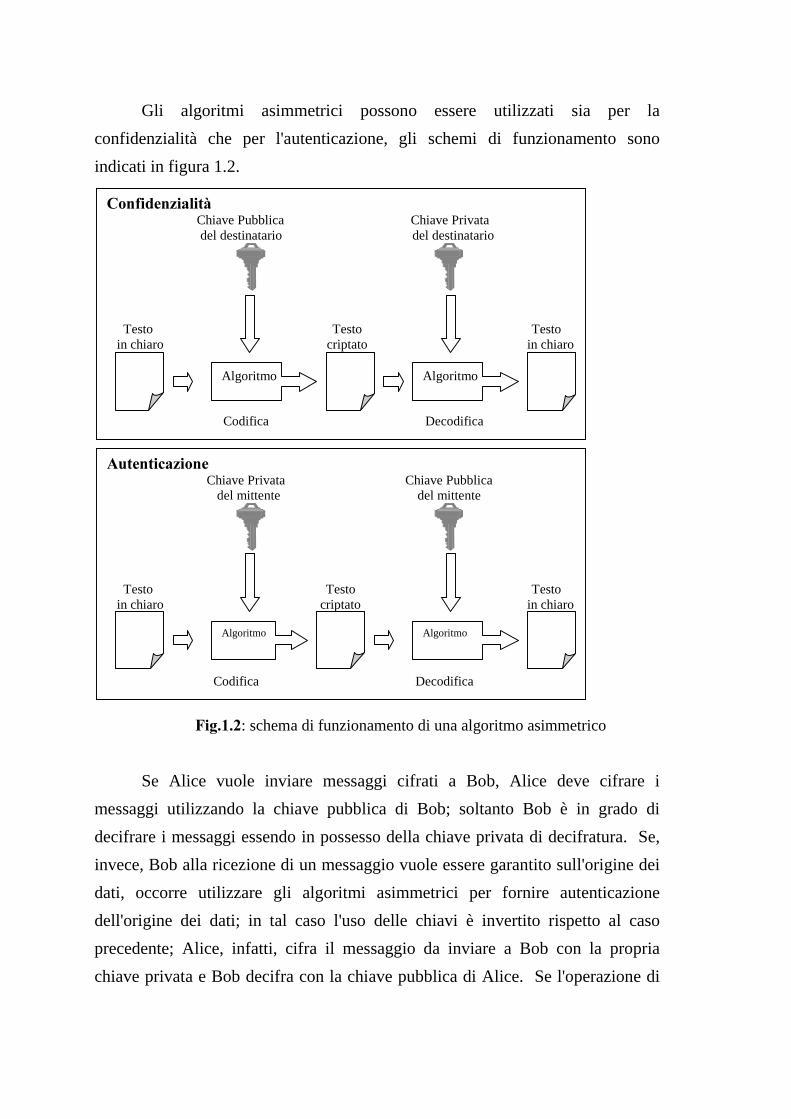
Gli algoritmi asimmetrici possono essere utilizzati sia per la
confidenzialità che per l'autenticazione, gli schemi di funzionamento sono
indicati in figura 1.2.
)LJ����: schema di funzionamento di una algoritmo asimmetrico
Se Alice vuole inviare messaggi cifrati a Bob, Alice deve cifrare i
messaggi utilizzando la chiave pubblica di Bob; soltanto Bob è in grado di
decifrare i messaggi essendo in possesso della chiave privata di decifratura. Se,
invece, Bob alla ricezione di un messaggio vuole essere garantito sull'origine dei
dati, occorre utilizzare gli algoritmi asimmetrici per fornire autenticazione
dell'origine dei dati; in tal caso l'uso delle chiavi è invertito rispetto al caso
precedente; Alice, infatti, cifra il messaggio da inviare a Bob con la propria
chiave privata e Bob decifra con la chiave pubblica di Alice. Se l'operazione di
&RQILGHQ]LDOLWj Chiave Pubblica Chiave Privata del destinatario del destinatario
Testo Testo Testo in chiaro criptato in chiaro
Codifica Decodifica
$XWHQWLFD]LRQH Chiave Privata Chiave Pubblica del mittente del mittente
Testo Testo Testo in chiaro criptato in chiaro
Codifica Decodifica
Algoritmo Algoritmo
Algoritmo Algoritmo
Page 17
9
decodifica ha successo, data la corrispondenza biunivoca tra le chiavi privata e
pubblica, soltanto Alice può essere effettivamente il mittente dei dati.
Per gestire la distribuzione delle chiavi in un ambiente aperto come
Internet, gli algoritmi a chiave pubblica presentano, evidentemente, vantaggi
sostanziali. Con tali algoritmi, infatti, non è necessario prevedere un canale
sicuro per la trasmissione della chiave, ma essendo la chiave di decifratura
distinta da quella di cifratura, è possibile distribuire quest'ultima in maniera non
riservata tramite dei server pubblici. Se, poi, n sono gli utenti coinvolti, n è
anche il numero di chiavi da distribuire e non n*(n-1)/2 come nel caso degli
algoritmi simmetrici.
���� /D�ILUPD�GLJLWDOH
Fino a pochissimo tempo fa la firma autografa era considerata l'unico
strumento adeguato per attribuire con certezza la paternità di un messaggio : un
documento originale, stampato su carta e firmato in maniera autografa, è ritenuto,
infatti, legalmente valido. Tale validità legale è attribuita ritenendo che:
• sia possibile rilevare alterazioni o abrasioni della carta che ne indichino una
contraffazione ;
• sia possibile ricondurre con certezza (quantomeno "legale") la firma apposta
in calce ad un documento alla persona la cui firma è apposta, e alla
manifestazione della sua volontà di sottoscrivere, accettare o richiedere
quanto esposto nel documento stesso.
La certezza dell'autenticità della firma, come è ben evidente a chiunque
abbia falsificato la firma di un conoscente, è assai lontana dalla realtà. E tuttavia
la legge tutela questa forma di manifestazione della volontà, e la considera
talmente valida da richiedere che certi documenti, di cui si ipotizza una futura
contestazione, debbano essere conservati per lunghi periodi di tempo.
La firma digitale, invece, è, oggi, la tecnologia con cui possono essere
effettivamente soddisfatti tutti i requisiti richiesti per dare validità legale ad un
documento elettronico firmato digitalmente; garantisce i servizi di integrità,
autenticazione e non ripudio.
Page 18
Analizziamo quali sono le proprietà richieste al processo di apposizione di
una firma, proprietà che nel caso della firma autografa si assume siano garantite,
nel caso della firma digitale, invece, se ne ha la certezza:
• autenticità della firma: la firma deve assicurare il destinatario del documento
che il mittente ha deliberatamente sottoscritto il contenuto del documento;
• non falsificabilità: la firma è la prova che solo il firmatario e nessun altro ha
apposto la firma sul documento;
• non riusabilità: la firma fa parte integrante del documento, non deve essere
utilizzare su un altro documento;
• non alterabilità: una volta firmato, il documento non deve poter essere
alterato;
• non contestabilità: il firmatario non può rinnegare con successo la paternità
dei documenti firmati; la firma attesta la volontà del firmatario di
sottoscrivere quanto contenuto nel documento.
Grazie alla tecnologia di firma digitale tutte le proprietà di cui sopra sono
assolutamente soddisfacibili. La firma digitale può essere realizzata tramite
tecniche crittografiche sia simmetriche che a chiave pubblica. Dati gli svantaggi
di scalabilità introdotti da schemi di firma digitale che utilizzano la crittografia
simmetrica, la firma digitale viene implementata con la crittografia a chiave
pubblica.
L'algoritmo di cifratura a chiave pubblica è intrinsecamente inefficiente ed
applicarlo all'intero testo che può essere molto lungo può richiedere troppo
tempo; l'utilizzo di particolari funzioni matematiche, chiamate funzioni hash
unidirezionali (l'unidirezionalità è dovuta al fatto che dato x è facile calcolare
f(x), dato, invece, f(x) è computazionalmente difficile risalire a x) permette di
ridurre questo tempo.
Il processo di firma digitale, indicato in figura 1.3, si compone di tre parti:
1) Generazione dell'impronta digitale del testo.
2) Generazione della firma.
3) Apposizione della firma.
Inizialmente fase viene applicata al documento in chiaro una funzione
hash appositamente studiata che produce una stringa binaria di lunghezza
Page 19
11
costante e piccola, tipicamente 128 o 160 bit, chiamata GLJHVW� PHVVDJH, ossia
impronta digitale. Questo hash costruito viene cifrato con la chiave privata del
mittente, il risultato non è altro che la firma digitale, la quale viene aggiunta in
una posizione predefinita, normalmente alla fine, al testo; ottenendo così il
documento firmato.
)LJ����: generazione della firma
Il ricevente verifica la firma digitale ricalcolando, con la medesima
funzione usata nella fase di firma, un hash nuovo a partire dal documento in
chiaro ricevuto; poi decifra l'hash ricevuto e cifrato dal firmatario; controlla se
l'hash nuovo calcolato corrisponde all'hash ricevuto e se i due hash coincidono il
processo di verifica si conclude con successo.
)LJ����: verifica della firma
Page 20
Lo schema del processo di verifica è indicato in figura 1.4.
L’algoritmo per la firma digitale più utilizzato è RSA [RSA78], mentre
per le funzioni hash citiamo SHA-1 [S96] e MD5 [RFC1321].
���� /D�QHFHVVLWj�GL�FRSSLH�GL�FKLDYL�GLVWLQWH�SHU�FLIUDWXUD�HILUPD
L'algoritmo a chiave pubblica ha la proprietà di permettere sia operazioni
di cifratura sia operazioni di firma digitale con la stessa coppia di chiavi
crittografiche; tuttavia un tale uso doppio della coppia di chiavi è sconsigliato. 1
motivi sono deducibili dall'esame dei requisiti di gestione che sono differenti nel
caso in cui le chiavi siano utilizzate per la cifratura o per la firma digitale.
Per la coppia di chiavi di firma digitale si devono, infatti, rispettare i
seguenti requisiti [F94]:
• la chiave privata di firma deve essere custodita durante l'intero periodo di
validità in modo tale che solo il suo legittimo possessore può averne accesso;
tale requisito, si ribadisce nuovamente, è un presupposto fondamentale per
fornire supporto a servizi di non ripudio; è comunemente raccomandato,
talvolta imposto, che la chiave di firma sia custodita all'interno dello stesso
dispositivo in cui sarà utilizzata;
• una chiave privata di firma non necessita, in generale, di essere sottoposta a
backup a protezione contro perdite accidentali della chiave privata; se la
chiave di firma, infatti, viene accidentalmente persa, una nuova coppia di
chiavi di firma può essere facilmente generata; sottoporre a backup la chiave
privata di firma contrasterebbe con il primo requisito;
• una chiave privata di firma non necessita di essere archiviata; l'archiviazione
contrasterebbe con il primo requisito; una chiave privata di firma deve essere
distrutta in modo sicuro allo scadere della sua validità; se, infatti, si potesse
risalire al suo valore anche dopo la cessazione del suo utilizzo, tale chiave
privata potrebbe ugualmente essere utilizzata per falsificare la firma su vecchi
documenti; l'impiego di servizi di opposizione di un timbro orario
(time/stamping) sicuro ridurrebbe il rischio conseguente ad una mancata
Page 21
13
rilevazione di firma falsa; tuttavia, i servizi di time/stamping non sono ancora
diffusamente implementati;
• una chiave pubblica di firma necessita di essere archiviata; tale chiave
potrebbe essere utilizzata per la verifica di firme apposte su documenti in
tempi successivi alla scadenza della validità della coppia di chiavi di firma.
Per la coppia di chiavi di cifratura, invece, si devono rispettare i seguenti
requisiti, in contrasto con i precedenti:
• la chiave privata, utilizzata nelle operazioni di decifratura, necessita
generalmente di essere sottoposta a backup od archiviata; solo tramite
l'archiviazione o backup è possibile risalire dai dati cifrati al corrispondente
testo in chiaro (si ottiene il recupero dei dati tramite il cosiddetto meccanismo
di recovery); se una chiave privata è andata persa (i motivi possono essere
dovuti o alla corruzione del dispositivo di protezione della chiave o alla
dimenticanza o perdita da parte del legittimo possessore del segreto utilizzato
per sbloccare l'accesso al dispositivo di protezione) e non ci sono meccanismi
di recupero della chiave, è inaccettabile perdere irrimediabilmente l'accesso ai
dati cifrati con quella chiave;
• la chiave pubblica utilizzata per la cifratura dei dati non necessita
generalmente di archiviazione; l'algoritmo utilizzato determina se un backup
della chiave pubblica è necessario o meno (se si utilizza un meccanismo di
trasporto delle chiavi basato su RSA, il backup non è necessario, può
diventarlo se si utilizza, invece, Diffie-Hellmann per lo scambio delle chiavi);
• la chiave privata non deve essere distrutta allo scadere della sua validità di
impiego per poter continuare a decifrare in futuro i documenti cifrati con la
corrispondente chiave pubblica.
Alla luce delle considerazioni elencate è evidente, quindi, che sarebbe
impossibile garantire il soddisfacimento contemporaneo di tutti i requisiti se si
impiega un'unica coppia di chiavi sia per la cifratura che per la firma.
Page 22
Alla precedente ragione si aggiungono anche, in seconda istanza, altri
motivi:
• le implementazioni a chiave pubblica utilizzate a supporto della cifratura sono
tipicamente soggette a limiti di esportazioni più restrittivi rispetto a quelli
previsti per la firma digitale; ad esempio la lunghezza della chiave di cifratura
può essere limitata ad un valore più basso rispetto a quella di firma;
• le chiavi di firma e di cifratura possono avere validità temporali differenti per
motivi di politica organizzativi/gestionali e di sicurezza;
• non tutti gli algoritmi a chiave pubblica hanno la proprietà di effettuare sia
cifratura sia firma con la stessa coppia di chiavi.
���� &HUWLILFDWL�HOHWWURQLFL
Nella tecnologia di crittografia a chiave pubblica sia in fase di cifratura
che in fase di verifica di una firma digitale, occorre ritrovare la chiave pubblica o
del destinatario di un messaggio o del firmatario del messaggio firmato. In
entrambi i casi il valore delle chiavi pubbliche non è confidenziale; la criticità del
reperimento delle chiavi sta nel garantire non la confidenzialità, ma l'autenticità
delle chiave pubbliche, ossia sta nell'assicurare che una certa chiave pubblica
appartenga effettivamente all'interlocutore per cui si vuole cifrare o di cui si deve
verificare la firma. Se, infatti, una terza parte prelevasse la chiave pubblica del
destinatario sostituendola con la propria, il contenuto dei messaggi cifrati sarebbe
disvelato e le firme digitali potrebbero essere falsificate.
La distribuzione delle chiavi pubbliche è, pertanto, il problema cruciale
della tecnologia a chiave pubblica. In un dominio con un numero limitato di
utenti si potrebbe anche ricorrere ad un meccanismo manuale di distribuzione
delle chiavi: due interlocutori che abbiano una relazione di conoscenza già
stabilita, potrebbero, ad esempio, scambiarsi reciprocamente le chiavi attraverso
floppy disk. Meccanismi di distribuzione manuali diventano, tuttavia,
assolutamente inadeguati ed impraticabili in dominio scalabile dove non c'è
alcuna diretta conoscenza prestabilita tra gli interlocutori.
Il problema della distribuzione delle chiavi pubbliche è risolto tramite
l'impiego dei certificati elettronici. I certificati a chiave pubblica costituiscono,
Page 23
15
infatti, lo strumento affidabile e sicuro attraverso cui rispondere ad esigenze di
scalabilità; attraverso i certificati elettronici le chiavi pubbliche vengono
distribuite e rese note agli utenti finali con garanzia di autenticità ed integrità.
L'utilizzo dei certificati elettronici presuppone, tuttavia, l'esistenza di un'autorità
di certificazione (Certification Authority o CA) che li emetta e li gestisca.
Ogni certificato è una struttura dati costituita da una parte dati contenente
al minimo:
• informazioni che identificano univocamente il possessore di una chiave
pubblica (ad esempio il nome);
• il valore della chiave pubblica;
• il periodo di validità temporale del certificato;
e da una parte contenente la firma digitale della autorità di certificazione con cui
si assicura l'autenticità della chiave e l'integrità delle informazioni contenute nel
certificato.
Page 25
17
&DSLWROR����6,67(0,�',�&(57,),&$=,21(
���� ,QWURGX]LRQH
Il sistema di distribuzione delle chiavi tramite certificati è caratterizzato da
una certa facilità di implementazione; la semplicità del meccanismo di
distribuzione delle chiavi è diretta conseguenza delle caratteristiche stesse dei
certificati: i certificati, infatti, possono essere distribuiti senza dover
necessariamente ricorrere ai tipici servizi di sicurezza di confidenzialità,
integrità, ed autenticazione delle comunicazioni.
Per le proprietà della crittografia a chiave pubblica non c'è infatti alcun
bisogno di garantire la riservatezza del valore della chiave pubblica; durante il
processo di distribuzione, poi, non ci sono requisiti di autenticazione ed integrità
dal momento che il certificato è per costruzione una struttura già protetta (la
firma digitale dell'autorità di certificazione sul certificato fornisce, infatti, sia
autenticazione sia integrità).
Se, quindi, un intrusore tentasse, durante la pubblicazione del certificato,
di alterarne il contenuto, la manomissione sarebbe immediatamente rilevata in
fase di verifica della firma sul certificato; il processo di verifica fallirebbe e
l'utente finale sarebbe avvertito della non integrità della chiave pubblica
contenuta nel certificato.
Le caratteristiche stesse del certificato permettono quindi di distribuire i
certificati a chiave pubblica anche mediante canali non sicuri (file server insicuri
o sistemi di directory o protocolli di comunicazione intrinsecamente insicuri).
Page 26
���� *HVWLRQH�GHL�FHUWLILFDWL�HOHWWURQLFL
La gestione dei certificati si articola lungo tutto il suo ciclo di vita
(generazione, distribuzione, aggiornamento, sospensione e revoca) ed è
influenzata dai requisiti e dalle fasi che caratterizzano la gestione delle
corrispondenti coppie di chiavi crittografiche. I processi di generazione della
coppia di chiavi e del relativo certificato possono talvolta essere integrati.
������ *HVWLRQH�GHOOH�FKLDYL
La gestione delle coppie di chiavi (NH\�PDQDJHPHQW) si può suddividere
nelle seguenti fasi:
• JHQHUD]LRQH� GHOOD� FRSSLD� GL� FKLDYL: quando una coppia di chiavi viene
generata, è necessario provvedere ad un trasferimento sicuro sia della chiave
privata che della chiave pubblica; la chiave privata deve essere trasferita sul
sistema crittografico del possessore della coppia di chiavi e se ne è richiesta
l'archiviazione, sul sistema di archiviazione; la chiave pubblica deve, invece,
essere inviata ad una o più autorità di certificazione perché sia certificata.
Esistono due approcci alternativi per la generazione delle chiavi:
� la coppia di chiavi è generata sul sistema del possessore in cui la chiave
privata sarà poi effettivamente memorizzata ed utilizzata; nel caso che la
coppia di chiavi sia utilizzata per la firma digitale, questo approccio è
obbligatorio onde non contravvenire al requisito del non ripudio; in questo
modo si aumenta il livello di garanzia che nessun altro al di fuori del
legittimo possessore possa entrare in possesso ed utilizzare
illegittimamente la chiave privata;
� la coppia di chiavi è generata in un sistema centrale, possibilmente
associato e gestito dall'autorità di certificazione garante dell'autenticità del
corrispondente certificato elettronico; la chiave privata è poi trasferita in
modo sicuro sul sistema del suo utilizzatore; questo schema risulta
adeguato nel caso in cui sia richiesta l'archiviazione della chiave privata
utilizzata nelle operazioni di decifratura; non può, invece, essere
impiegato se la coppia di chiavi generata viene utilizzata per la firma;
Page 27
19
• SURWH]LRQH� GHOOD� FKLDYH� SULYDWD: il materiale crittografico deve essere
custodito in modo sicuro, solo il legittimo possessore deve avere accesso alla
propria coppia di chiavi; l'accesso è controllabile mediante meccanismi di
autenticazione personale;
• DJJLRUQDPHQWR�GHOOD�FRSSLD�GL�FKLDYL: una politica di sicurezza adeguata deve
prevedere un aggiornamento delle chiavi con scadenze regolari o in
conseguenza a compromissioni sospettate delle chiave privata; quando una
nuova coppia di chiavi viene generata, è evidente che deve essere generato
anche un nuovo certificato
Bisogna anche mantenere una copia delle chiavi dal fatto che l'eventuale
perdita delle chiavi comporta l'impossibilità di decifrare i messaggi codificati e
verificare i documenti firmati. Spesso le organizzazioni richiedono un backup
delle chiavi dei loro membri per evitare che l'onere di mantenimento delle copie
sia esclusivamente di questi ultimi. Tali organizzazioni possono avere la
necessità di verificare documenti digitalmente firmati dai loro membri anche
oltre la validità temporale di tali chiavi e non possono fidarsi unicamente delle
eventuali copie di backup fatte dal possessore delle chiavi.
������ &LFOR�GL�YLWD�GHL�FHUWLILFDWL
L'emissione effettiva di un certificato elettronico da parte di un'autorità di
certificazione deve essere preceduta da una fase di UHJLVWUD]LRQH� dell'utente
richiedente il certificato elettronico. Attraverso il processo di registrazione
l'utente richiedente un servizio di certificazione si identifica presso l'autorità
preposta al servizio di registrazione; le credenziali che in questa fase l'utente
deve sottoporre all'autorità di registrazione dipendono fortemente dalle modalità
e procedure di registrazione definite nell'ambito di una politica di sicurezza.
Il processo di registrazione stabilisce una relazione iniziale tra utente
finale ed autorità di certificazione; l'utente finale, una volta attestata l'autenticità
della sua identità, viene registrato nel dominio di fiducia gestito dall'autorità di
certificazione. L'obiettivo, quindi, di primaria importanza del processo di
registrazione è garantire che la chiave pubblica di cui un certo utente finale
Page 28
richiede la certificazione sia realmente associata e quindi appartenga, solo al
nome del richiedente e non a quello di qualcun altro utente.
Terminata la fase di registrazione, l'utente può richiedere l'emissione di un
certificato elettronico. La procedura di JHQHUD]LRQH di un certificato elettronico
consiste dei seguenti passi:
• l'utente finale sottopone all'autorità di certificazione le informazioni da
certificare;
• l'autorità di certificazione può verificare l'accuratezza delle informazioni
presentate in accordo a politiche e standard applicabili;
• l'autorità di certificazione firma le informazioni generando il cosiddetto
certificato; generato il certificato, l'autorità di certificazione può direttamente
pubblicarlo sul sistema scelto per la distribuzione dei certificati;
opzionalmente l'autorità di certificazione può archiviare una copia del
certificato; ogni operazione di generazione di certificati elettronici viene
registrata su un archivio di registrazione dati.
Ogni certificato elettronico generato ha una validità temporale limitata al
cui termine va sostituito; il periodo di validità di un certificato, in assenza di
compromissioni o usi illeciti, garantisce l'utente che deve utilizzare tale
certificato che la chiave pubblica può essere utilizzata per lo scopo per cui è stata
generata e che l'associazione tra la chiave pubblica e le altre informazioni
contenute nel certificato è ancora valida.
Anche le chiavi crittografiche dovrebbero essere periodicamente sostituite
per ragioni di sicurezza; l'aggiornamento delle chiavi comporta
conseguentemente un aggiornamento dei certificati elettronici corrispondenti;
l'aggiornamento dei certificati può essere richiesto e realizzato manualmente o
mediante un processo trasparente al possessore del certificato; questo significa
che il possessore si ritrova ad avere un certificato valido senza essersi registrato
nuovamente e senza aver esplicitamente richiesto la generazione di un nuovo
certificato. Se, tuttavia, l'autorità di certificazione prevede una politica di
sicurezza che obbliga l'utente finale a presentarsi periodicamente per
riconfermare la validità delle informazioni contenute nel certificato, è evidente
Page 29
21
che il processo di aggiornamento non può essere trasparente al possessore del
certificato.
Un certificato elettronico, una volta generato ed eventualmente
aggiornato, deve essere distribuito pubblicamente; il meccanismo di distribuzione
comunemente utilizzato impiega un servizio di directory; una tecnologia
completa di servizio di directory distribuito è stato sviluppato e standardizzato
attraverso la cooperazione tra l'Intemational Telecommunication Union (ITU) e
l'International Organization for Standardization (ISO) sotto la sigla di
raccomandazioni X.500. L'adozione e l'implementazione di directory X.500,
soprattutto all'interno di grosse organizzazioni, sta solo attualmente aumentando
soprattutto grazie alla tecnologia a chiave pubblica. Analizzeremo i servizi di
directory nel quarto capitolo.
Ogni certificato elettronico ha una ben definita data di scadenza naturale,
ma in presenza di compromissioni o usi illeciti il certificato viene revocato e
cessa la sua validità. L'operazione di revoca è una fase del ciclo di vita dei
certificati ad alta criticità e prevede degli specifici sistemi di gestione che
vedremo in dettaglio nel prossimo capitolo.
���� /R�VWDQGDUG�;�����SHU�L�FHUWLILFDWL
Lo standard ormai diffusamente riconosciuto di definizione del formato
dei certificati è quello descritto nello standard X.509 ISO/IEC/ITU [RFC2459]
(Visa e MasterCard hanno ad esempio adottato le specifiche X.509 come base
per la definizione dello standard per il commercio elettronico SET, Secure
Electronic Transaction). Lo standard X.509 costituisce il "framework" di
autenticazione disegnato per supportare i servizi di directory X.500. Le versioni
proposte per il formato dei certificati X.509 sono attualmente tre: la prima
versione definita nel 1988, la seconda versione uscita nel 1993 e la terza versione
del 1996.
Negli anni 1993-94, quando sono stati avviate le prime sperimentazioni
basate su X.509 su larga scala, è emerso chiaramente che le prime due versioni
dei certificati X.509 erano insufficienti a risolvere molte delle problematiche che
si presentavano.
Page 30
)LJ�������formato dei certificati X.509 versione 1 e 2
Si è resa evidente la necessità di introdurre nel formato dei certificati
relativo alle versioni 1 e 2 delle modifiche; molteplici sono le motivazioni che
giustificano le aggiunte, tra cui le principali si possono sintetizzare nelle
seguenti:
• ogni utente può avere più certificati per chiavi differenti; è indispensabile
inserire un meccanismo con cui poter distinguere univocamente i diversi
certificati appartenenti allo stesso possessore;
• i certificati necessitano, nell'ambito di alcune applicazioni, di riportare
all'interno informazioni dell'utente aggiuntive rispetto al semplice nome
(indirizzo di e-mail ad esempio);
• i certificati possono essere emessi secondo politiche di certificazione e per
finalità differenti; ad esempio l'autorità di certificazione potrebbe aver
emesso un certificato ad un utente affinché sia utilizzato solo per operazioni
di cifratura e non per operazioni di firma su transazioni ad alto valore
finanziario;
• le autorità di certificazione stabiliscono relazioni di fiducia reciproche; deve
essere possibile introdurre dei vincoli che regolino il trasferimento di fiducia
da un dominio di sicurezza ad un altro.
&HUWLILFDWH�IRUPDW�YHUVLRQ
&HUWLILFDWH�VHULDO�QXPEHU
6LJQDWXUH�DOJRULWP�LGHQWLILHU
,VVXHU�;�����QDPH
9DOLG�SHULRG
6XEMHFW�;�����QDPH
6XEMHFW�SXEOLF�NH\�LQIRUPDWLRQ
,VVXHU�8QLTXH�,GHQWLILHU
6XEMHFW�8QLTXH�,GHQWLILHU
Identifica la versione del formato
Identifica univocamente il certficato
Identificatore dell’algoritmo utilizzato dalla CA per firmare il certificato
Nome della CA nella forma X.500
Periodo di validità del cerificato
Nome del possessore nella forma X.500
Valore della chiave pubblica
Stringa di bit aggiuntivi, opzionali nel caso che nella struttura ad albero dei nomi X.500 ci siano due CA omonime
Stringa di bit aggiuntivi, opzionali nel caso che nella struttura ad albero dei nomi X.500 ci siano due CA omonime
&$�VLJQDWXUH
NoninVer.1
Page 31
23
Alla luce di queste motivazioni, è stata definita la versione 3 dei certificati
X.509; tale versione ha lo stesso formato della versione 2 ad eccezione di
estensioni aggiuntive finalizzate a rispondere ai requisiti sopra elencati.
)LJ�������formato dei certificati X.509 versione 3
Il campo delle estensioni prevede tre sottoinsiemi: l'identificatore del tipo
di estensione, un indicatore di criticità e il valore effettivo dell'estensione;
l'indicatore di criticità facilita l'interoperabilità tra sistemi che non utilizzano
certificati con determinate estensioni e sistemi che, invece, interpretano tutte le
estensioni definite a livello di standard; l'indicatore di criticità è semplicemente
un flag che stabilisce se l'estensione è critica o non critica; se l'estensione non è
critica, significa che il sistema che deve elaborare il certificato può
eventualmente ignorare l'estensione in questione se non è in grado di
interpretarla.
Le estensioni standard definite nella versione 3 dei certificati X.509, si
suddividono fondamentalmente in quattro gruppi:
• estensioni contenenti informazioni sulla chiave pubblica; un'estensione ad
esempio specifica il tipo di utilizzo per cui è stata emessa una certa chiave;
&HUWLILFDWH�IRUPDW�YHUVLRQ
&HUWLILFDWH�VHULDO�QXPEHU
6LJQDWXUH�DOJRULWP�LGHQWLILHU
,VVXHU�;�����QDPH
9DOLG�SHULRG
6XEMHFW�;�����QDPH
6XEMHFW�SXEOLF�NH\�LQIRUPDWLRQ
,VVXHU�8QLTXH�,GHQWLILHU
6XEMHFW�8QLTXH�,GHQWLILHU
Identifica la versione del formato
Identifica univocamente il certficato
Identificatore dell’algoritmo utilizzato dalla CA per firmare il certificato
Nome della CA nella forma X.500
Periodo di validità del cerificato
Nome del possessore nella forma X.500
Valore della chiave pubblica
Stringa di bit aggiuntivi, opzionali nel caso che nella struttura ad albero dei nomi X.500 ci siano due CA omonime
Stringa di bit aggiuntivi, opzionali nel caso che nella struttura ad albero dei nomi X.500 ci siano due CA omonime
([WHQVLRQ
&$�VLJQDWXUH
([WHQVLRQ�7\SH &ULW��1RQ�FULW ([WHQVLRQ�)LHOG�9DOXH
Page 32
una coppia di chiavi, infatti, può essere utilizzata per scopi differenti: per la
firma di certificati da parte dell'autorità di certificazione, per la firma digitale
da parte di utenti finali, per la cifratura dei dati, per il trasferimento di chiavi
simmetriche o per effettuare lo scambio di chiavi di cifratura tramite Diffie-
Hellmann;
• estensioni contenenti informazioni aggiuntive relative all'autorità di
certificazione e all'utente possessore del certificato (ad esempio nomi
alternativi per la CA e per l'utente, quali indirizzo di e-mail o identificativo
URL);
• estensioni contenenti informazioni sulle politiche di emissione e sulle finalità
di utilizzo dei certificati; l'estensione "certificate policy", infatti, specifica la
politica sotto cui un certificato è stato emesso; ogni certificato può avere
definite una o più politiche di certificazione; l'estensione "policy mapping",
invece, si applica quando un'autorità di certificazione crea una relazione di
fiducia con un'altra autorità di certificazione; l'estensione "policy mapping"
fornisce il meccanismo con cui controllare la compatibilità tra le politiche
differenti di autorità di certificazione;
• estensioni contenenti informazioni sui vincoli di spazio dei nomi o di politica
da imporre durante il ritrovamento o la verifica di un certificato appartenente
ad un dominio di fiducia esterno.
Page 33
25
&DSLWROR����,1)5$67587785(�$�&+,$9(
38%%/,&$
���� ,QWURGX]LRQH
Le infrastrutture a chiave pubblica (Public Key Infrastructure o PKI)
forniscono il supporto necessario affinché la tecnologia di crittografia a chiave
pubblica sia utilizzabile su larga scala. Le infrastrutture offrono servizi relativi
alla gestione delle chiavi, dei certificati e delle politiche di sicurezza. Le autorità
di certificazione e la gestione dei certificati elettronici costituiscono, infatti, il
cuore delle infrastrutture a chiave pubblica. Quando, tuttavia, si cercano di
applicare i concetti relativi alla gestione dei certificati in un contesto ampio e di
elevata complessità, emergono problematiche sottili per la cui risoluzione si
rende necessaria l'adozione di servizi di infrastruttura di natura sia tecnologica
che legale aggiuntivi rispetto a quelli esaminati nelle sezioni precedenti. In uno
scenario di infrastrutture costituite da molteplici autorità di certificazione, le
problematiche da esaminare riguardano le modalità con cui trovare e validare un
cammino di certificazione5 tra autorità di certificazione, con cui organizzare e
strutturare le relazioni di fiducia tra autorità di certificazione e con cui associare
politiche di sicurezza e vincoli ai diversi cammini di certificazione.
Un'infrastruttura a chiave pubblica introduce il concetto di WKLUG�SDUW\
WUXVW, che si verifica quando due generiche entità si fidano implicitamente l'una
dell'altra senza che abbiano precedentemente stabilito una personale relazione di
fiducia.
5 I cammini di certificazione sono i mezzi attraverso cui è possibile verificare l'integrità dei certificatielettronici degli attori di una comunicazione sicura appartenenti a domini di sicurezza distinti; vedremo inseguito cosa si intende esattamente
Page 34
Questo è possibile perché entrambe le entità condividono una relazione di
fiducia con una terza parte comune.
)LJ����:�7KLUG�SDUW\�WUXVW
7KLUG�SDUW\� WUXVW [CUR95] è un requisito fondamentale per qualsiasi
implementazione su larga scala che utilizzi crittografia a chiave pubblica e in una
PKI viene realizzata attraverso l'autorità di certificazione.
���� 5HTXLVLWL�GL�XQD�3.,
L'implementazione di un'infrastruttura a chiave pubblica deve tener conto
di una serie di requisiti progettuali che si possono sintetizzare nei seguenti:
• scalabilità;
• supporto per applicazioni multiple; a beneficio degli utenti finali in
termine di convenienza, sicurezza ed economia, una stessa infrastruttura
deve garantire il supporto per molteplici applicazioni (posta elettronica
sicura, applicazioni Web, trasferimento di file sicuro); il modello di
gestione della sicurezza deve essere consistente e uniforme per tutte le
applicazioni;
• interoperabilità tra infrastrutture differenti; non è certo una soluzione
praticabile quella di implementare un'unica infrastruttura rispondente alle
necessità di sicurezza di un dominio di utenti su scala globale; è evidente
Page 35
27
che si deve ricorrere a domini di sicurezza distinti, ognuno amministrato
da un'infrastruttura specifica. L'interoperabilità, tuttavia, di tali
infrastrutture distinte deve essere assicurata ed è richiesta per garantire il
raggiungimento di un buon livello di scalabilità;
• supporto per una molteplicità di politiche; cammini di certificazione
considerati appropriati per un'applicazione, possono non essere considerati
altrettanto validi per un'altra applicazione; ci si potrebbe ad esempio fidare
di un'autorità di certificazione che certifica web server relativamente a
transazioni commerciali di bassa entità, ma non relativamente a
transazioni di elevato valore; per rispondere, quindi, ad entrambi i
requisiti di scalabilità e supporto per applicazioni multiple, è necessario
implementare meccanismi che permettano da un lato di attribuire politiche
differenti ai vari cammini di certificazione dall'altro di associare ad ogni
applicazione una politica di sicurezza specifica;
• conformità agli standard; una vera interoperabilità tra PKI distinte è
ottenibile soltanto con l'adozione di standard che definiscono i protocolli
funzionari e di comunicazione relativi ai componenti costitutivi di
un'infrastruttura a chiave pubblica.
���� &RPSRQHQWL�GL�XQD�3.,
Vediamo quali sono i componenti fondamentali di un'infrastruttura a
chiave pubblica [L97], dalla cui interazione deriva il corretto funzionamento
della PKI:
• DXWRULWj� GL� UHJLVWUD]LRQH� �5$�: l'accertamento dell'identità
dell'utente richiedente un certificato elettronico, deve precedere l'effettiva
emissione del certificato; è indispensabile procedere a tale verifica dato che con
l'emissione di un certificato elettronico si rende pubblicamente valida
l'associazione tra una certa chiave pubblica e una certa entità. Una volta attestata
la validità dell'identità dell'utente attraverso una serie di procedure definite
nell'ambito di una precisa politica di sicurezza, l'autorità di registrazione ha il
compito di abilitare l'utente come appartenente ad uno specifico dominio di
fiducia; la funzionalità di autorità di registrazione può essere espletata
Page 36
dall'autorità di certificazione stessa oppure delegata ad altre entità; in uno
scenario ampio è consigliabile ricorrere ad una molteplicità di autorità di
registrazione distribuite su scala geografica;
• DXWRULWj�GL�FHUWLILFD]LRQH��&$�: costituisce la componente chiave
di una PKI; la sua principale funzione consiste nel creare certificati elettronici
per quegli utenti precedentemente abilitati nella fase di registrazione al dominio
di fiducia di cui la CA è garante; un'autorità di certificazione non si deve limitare
esclusivamente alla generazione dei certificati, ma deve poterne gestire l'intero
ciclo di vita. Deve quindi occuparsi anche delle fasi di aggiornamento (nel caso
in cui il certificato stia per perdere validità temporale), sostituzione (nel caso di
scadenza della validità temporale) e revoca (nel caso in cui le condizioni di
emissione del certificato non siano più valide). Un ulteriore compito dell'autorità
di certificazione è stabilire relazioni di fiducia con altre CA.
• VLVWHPD� GLVWULEXLWR� GL� GLUHFWRU\: costituisce un elemento
fondamentale per la distribuzione su larga scala delle chiavi pubbliche utilizzate
nella cifratura e nella firma dei dati. Il sistema di directory contiene i certificati a
chiave pubblica, reperibili dagli utenti quando necessario, e le liste contenenti i
certificati a chiave pubblica sottoposti a revoca; l'obiettivo che si intende
raggiungere disponendo di directory pubbliche è facilitare la gestione e la
distribuzione di certificati elettronici su larga scala;
• 3.,� GDWDEDVH: oltre al sistema di directory, di solito c'è un'altra
struttura dedicata alla memorizzazione delle chiavi è il database gestito
esclusivamente dalla CA nel quale viene fatto un backup delle chiavi e vengono
archiviate le chiavi scadute. Questo database, a differenza della directory, è
privato ad è accessibile solo dalla CA.
• XWHQWL� ILQDOL� ��gli utenti finali sono dotati di software in grado di
interagire con la PKI in tutte le fasi in cui sia richiesta un'interazione tra le
applicazioni client e la CA o la directory (ad esempio un'interazione
fondamentale interviene nella fase di inizializzazione dell'utente, fase nella quale
vengono creati i relativi certificati di cifratura o di firma) .
Page 37
29
)LJ�����: componenti di una PKI
���� 'HILQL]LRQH�GL�FDPPLQR�GL�FHUWLILFD]LRQH
Se si potesse disporre di un'unica autorità di certificazione su scala
globale, il problema della distribuzione, del reperimento e della verifica della
validità delle chiavi pubbliche non sussisterebbe; tuttavia una tale soluzione non
è praticabile per motivi di scalabilità, flessibiltà e sicurezza. Diventa, quindi,
inevitabile ricorrere ad un modello costituito da autorità di certificazione multiple
tra loro concatenate secondo differenti modelli organizzativi, detti anche modelli
di fiducia.
In uno scenario costituito da una molteplicità di autorità di certificazione
su larga scala, strutturate secondo un certo modello organizzativo, non è
pensabile che ogni utente abbia diretta conoscenza delle chiavi pubbliche di ogni
potenziale interlocutore, sotto forma di certificato elettronico, o delle chiavi
pubbliche delle corrispondenti autorità di certificazione competenti. Occorre,
quindi, disporre di un meccanismo corretto di ritrovamento dei certificati
elettronici degli interlocutori appartenenti a domini di sicurezza esterni. Il
modello generale su cui si basano tutti i sistemi di distribuzione su larga scala,
delle chiavi pubbliche sotto forma di certificati elettronici, utilizza le cosiddette
catene di certificazione, altrimenti conosciute come cammini di certificazione.
Il problema del ritrovamento di una catena di certificazione consiste
sostanzialmente nel trovare, se esiste, una serie di certificati che permetta di
Page 38
verificare l'autenticità del certificato elettronico di uno specifico utente remoto a
partire da un insieme di chiavi pubbliche, assunte come radici del cammino, di
cui si ha diretta e sicura conoscenza. La risoluzione del problema, quindi, assume
per assegnate certe condizioni iniziali che si identificano nelle chiavi di
specifiche autorità di certificazione.
Supponiamo che Alice sia stata certificata dall'autorità di certificazione A
ed abbia conseguentemente diretta fiducia nella chiave di firma di tale autorità di
certificazione; Alice vuole comunicare in modo sicuro con Bob certificato
dall'autorità C; deve pertanto reperire il certificato di Bob e verificarne
l'autenticità, ossia deve verificare la firma apposta dall'autorità C sul certificato di
Bob; Alice dispone solo della chiave pubblica della propria autorità di
certificazione, cioè di A, e non della chiave pubblica di C; si pone, quindi, il
problema di come ritrovare in modo sicuro la chiave pubblica di C in modo da
poterla utilizzare nel processo di verifica della firma del certificato di Bob; il
problema si risolve se è possibile ritrovare una catena di certificati verificabili a
partire dalla chiave pubblica dell'autorità di certificazione A.
)LJ�������esempio di catena di certificati
Facendo riferimento alla figura 3.3, la catena è costituita dai certificati 1, 2
e 3; la presenza del certificato 1 garantisce Alice dell'autenticità della chiave
pubblica dell'autorità di certificazione B; Alice può, quindi, utilizzare la chiave
pubblica di B per verificare l'autenticità del certificato 2; la presenza del
Page 39
31
certificato 2 garantisce ora Alice dell'autenticità della chiave pubblica
dell'autorità di certificazione C; ora Alice può utilizzare la chiave pubblica
dell'autorità di certificazione C per verificare l'autenticità della chiave pubblica di
Bob; se fosse mancato il certificato 2, Alice non avrebbe potuto verificare
l'autenticità del certificato elettronico di Bob e conseguentemente avviare con
Bob una comunicazione sicura.
���� )XQ]LRQDOLWj�GL�XQD�3.,
Ogni implementazione di infrastruttura a chiave pubblica rispecchia
specifici requisiti funzionali; il requisito funzionale che dovrebbe essere, tuttavia,
garantito in qualunque implementazione è quello relativo alla trasparenza; gli
utenti finali devono poter usufruire delle tecniche crittografiche di cifratura e
firma digitale con assoluta semplicità e devono essere mantenuti il più possibile
all'oscuro delle problematiche relative sia alla gestione del cielo di vita delle
chiavi e dei certificati elettronici sia ai processi di cifratura o verifica di una
firma digitale.
Le funzionalità che un'implementazione completa ed efficace di
infrastruttura a chiave pubblica deve fornire si possono classificare nei seguenti
punti:
• funzionalità relative alla gestione delle chiavi e dei certificati; si tratta delle
operazioni di emissione, revoca, distribuzione ed aggiornamento automatico
e trasparente dei certificati, e recupero delle chiavi di decifratura (si tratta del
cosiddetto "key recovery" che si rende necessario nella maggior parte delle
realtà lavorative, costituisce uno strumento di recupero di informazioni
precedentemente cifrate a beneficio del legittimo possessore delle
informazioni; risponde principalmente ad esigenze aziendali e commerciali;
il meccanismo di recupero delle chiavi di decifratura è diverso da quello
impiegato per fare "key escrow"; il "key escrow" risponde, invece, ad
esigenze di controlli da parte di autorità governative; il "key escrow"
costituisce un argomento di acceso dibattito, rappresenta un campo in cui le
esigenze di controllo governativo entrano nettamente in contrasto con i diritti
di libertà individuale e tutela della privacy del singolo cittadino);
Page 40
• funzionalità atte a garantire il supporto al non ripudio della firma digitale;
• funzionalità atte a garantire il supporto affinché una PKI stabilisca relazioni
di fiducia con PKI esterne (in questo caso si parla di cosiddetta "cross
certification") e le applicazioni client siano in grado di verificare la
correttezza e l'autenticità dei cammini di certificazione che si vengono a
creare in presenza di cross-certification;
• funzionalità atte a garantire un'interazione trasparente tra le applicazioni
client che utilizzano l'infrastruttura per i servizi di sicurezza e l'infrastruttura
stessa; la PKI deve fornire sul lato client il software necessario affinchè tutte
le applicazioni interagiscano con la PKI in modo consistente relativamente ai
servizi di gestione delle chiavi crittografiche e dei certificati elettronici; al
fine di soddisfare il requisito di trasparenza, il software sul lato client deve
garantire:
� il controllo sia della validità della firma digitale dell'autorità di
certificazione sui certificati a chiave pubblica che della loro validità
temporale;
� la generazione delle chiavi di firma da parte del software sul lato client per
sopportare il non ripudio della firma digitale;
� il completamente di un processo di recupero di dati precedentemente
cifrati;
� l'avvio del processo di aggiornamento delle chiavi crittografiche e dei
corrispondenti certificati se risulta ancora confermata la validità delle
condizioni iniziali di registrazione; l'operazione di aggiornamento è
realizzata in conformità alle politiche di sicurezza definite nell'ambito
della PKI e in modo consistente e trasparente per tutte le applicazioni che
utilizzano cifratura e firma digitale;
� la verifica dello stato di ogni certificato elaborato; in modo trasparente, sia
in fase di cifratura che in fase di verifica di una firma digitale, il software
sul lato client deve controllare che il certificato da elaborare non sia stato
revocato; il controllo dello stato del certificato non può essere delegato
all'arbitrio dell'utente finale visto la criticità dell'operazione;
� la verifica dello stato di ogni certificato presente su un cammino di
certificazione in presenza di cross-certification; lo stato di ogni certificato
Page 41
33
relativo ad un'autorità di certificazione, presente nella catena di fiducia
deve essere controllato accuratamente; la validazione di un certo cammino
di certificazione fallisce in presenza anche di un solo certificato revocato o
di un certificato emesso secondo politiche non compatibili;
Solo una PKI rispondente a tutte le caratteristiche sopra descritte è in
grado di stabilire e mantenere la sicurezza di un ambiente distribuito in modo
consistente, garantendo un sistema di gestione delle chiavi e dei certificati
utilizzabile in modo automatico e trasparente.
���� /D�UHYRFD�GL�XQ�FHUWLILFDWR
Ogni PKI deve garantire contromisure efficaci per gli usi fraudolenti o
illeciti di un certificato. Il certificato elettronico deve poter essere revocato in
presenza delle seguenti condizioni:
• compromissione rilevata o semplicemente sospettata della chiave privata
corrispondente alla chiave pubblica contenuta nel certificato;
• cambiamento di una qualsiasi delle informazioni contenute nel certificato
elettronico o delle condizioni iniziali di registrazione.
La revoca del certificato elettronico è effettuata dall'autorità di
certificazione, generalmente viene avviata su richiesta dello stesso utente finale;
in questo caso, data la criticità e le implicazioni dell'operazione di revoca, è
indispensabile predisporre, un sistema di autenticazione della richiesta di revoca.
La difficoltà legata al processo di revoca sta nel garantire una corretta
notifica su larga scala dell'avvenuta revoca di un particolare certificato;
ogniqualvolta un utente finale intende utilizzare un certificato o per cifrare dati o
per verificare una firma, deve essere informato sullo stato di quel certificato.
Il meccanismo più comunemente utilizzato per la notifica su larga scala di
avvenute revoche fa uso delle cosiddette liste di revoca dei certificati (Certificate
Revocation List o CRL); la gestione di tali liste è delegata alla CA nell'ambito
del dominio amministrato, ogni CA pubblica periodicamente una struttura dati
contenente l'elenco dei certificati revocati, chiamata lista di revoca dei certificati
Page 42
(CRL); una CRL è appunto una lista, firmata digitalmente dall'autorità di
certificazione, che riporta i certificati revocati, la data temporale in cui è
avvenuta la revoca ed eventualmente il motivo della revoca; i motivi per cui
anche la CRL deve essere firmata digitalmente sono analoghi a quelli descritti
nel caso dei certificati elettronici.
La CRL, al pari dei certificati, deve essere pubblicata in modo che sia
consultabile da qualunque utente. La frequenza di pubblicazione di una CRL
dipende fortemente dalla politica di sicurezza definita all'interno
dell'organizzazione; una determinata politica potrebbe richiedere la
pubblicazione di una nuova CRL ogniqualvolta si richiede una revoca; tale
procedura risulta, tuttavia, molto dispendiosa dal punto di vista amministrativo.
Generalmente, la CA rilascia liste di revoca dei certificati su base periodica, con
intervalli di periodicità definibili a livello di politica di sicurezza.
)LJ�������formato delle CRL secondo lo standard X.509
Le liste di revoca giocano un ruolo di fondamentale importanza in tutti i
processi crittografici, in quanto devono essere consultate sia in fase di cifratura
che in fase di verifica di una firma. Prima di cifrare un messaggio, va verificato
che la chiave pubblica che si deve usare appartenga ad un certificato valido.
Analogo discorso vale la verifica di una firma, che può essere ritenuta valida solo
se il certificato del firmatario, oltre ad essere autentico e integro, non è stato
revocato; l'autenticità e l'integrità del certificato si controlla verificando la firma
,VVXHU�1DPH
&5/�,VVXH�7LPH�'DWH
&HUWLILFDWH�VHULDO�QXPEHU
5HYRFDWLRQ�7LPH�'DWH
«
«
«
&HUWLILFDWH�VHULDO�QXPEHU
5HYRFDWLRQ�7LPH�'DWH
&$�VLJQDWXUH
Page 43
35
della CA che ha emesso il certificato, lo stato di revoca si controlla verificando
che il certificato in questione non compaia nella lista di revoca emessa dalla CA
competente.
La dimensione di una CRL è di fondamentale importanza nelle prestazioni
del processo di verifica dato che sia in fase di cifratura che in fase di verifica di
una firma si deve comunque elaborarne una; se la dimensione di una CRL è
considerevole, è evidente che si introducono overhead sia di traffico di rete che
di elaborazione.
Il problema della crescita illimitata delle CRL è stato risolto con
l'introduzione dei cosiddetti punti di distribuzione delle CRL (definiti nella
versione2 dello standard X.509 relativo alle CRL); è, infatti, possibile dividere in
modo arbitrario il numero di certificati revocati da una CA in partizioni, ognuna
delle quali associata ad un punto di distribuzione; in questo modo la massima
dimensione che può raggiungere una singola partizione è controllata dall'autorità
di certificazione grazie all'utilizzo di metodi di riallocazione dinamica delle
partizioni [AZ98]; i punti di distribuzione facilitano, pertanto, l'elaborazione
delle CRL e ne riducono i tempi di reperimento.
Il metodo di distribuzione della notifica di revoca attraverso CRL
distribuite periodicamente dall'autorità di certificazione è detto di tipo SXOO�� il
nome del metodo deriva, infatti, dal fatto che sono gli stessi utenti finali a
reperire le CRL dal sistema di distribuzione quando necessario.
Il limite legato al metodo di distribuzione delle notifiche delle revoche
tramite CRL, è quello della latenza introdotta. Esistono transazioni in cui è
necessario garantire revoca in tempo reale e che non possono tollerare finestre
temporali in cui le CRL non sono perfettamente allineate; il metodo sopra
descritto presenta proprio la limitazione che la latenza introdotta nelle notifiche
delle revoche dipende dalla periodicità di emissione delle CRL. Se, ad esempio,
viene revocato un certificato nell'intervallo di tempo tra due emissioni periodiche
previste, la revoca viene effettivamente comunicata alla successiva emissione di
CRL prevista; il tempo di latenza può, quindi, essere non tollerabile. È evidente
che l'autorità di certificazione può forzare l'emissione di una CRL fuori
sequenza; se, tuttavia, viene avviato un attacco attivo finalizzato ad impedire la
pubblicazione di tale lista di revoca fuori sequenza, non c'è un meccanismo
Page 44
affidabile che permetta di rilevare con assoluta certezza la mancata pubblicazione
di tale CRL.
Per ridurre il consumo di risorse di rete richiesto da una pubblicazione di
una nuova CRL sono state introdotte le Delta CRL che rappresentano
un'integrazione alle CRL. Viene definita una CRL base che è pubblicata con
stabilita frequenza, a cui viene associata una Delta CRL che contiene gli
aggiornamenti alla CRL base. Date le dimensioni abbastanza ridotte le Delta
CRL possono essere pubblicate con maggiore frequenza senza comportare un
eccessivo consumo di risorse di rete. Ogni certificato conterrà oltre ad un
identificativo del frammento di CRL che lo riguarda anche un riferimento alla
Delta CRL relativa, oppure questo riferimento sarà incluso nello stesso
frammento di CRL[AZ98].
L'utilizzo delle Delta CRL riduce il periodo di aggiornamento delle CRL,
ma non risolve il problema della revoca in tempo reale che può essere affrontata
solo con metodi alternativi.
Un primo approccio è quello che utilizza un metodo di tipo SXVK� in cui è
l'autorità di certificazione ad inviare in modalità "broadcast" le CRL non appena
sopravviene una nuova revoca. Se, da un lato, questo metodo garantisce tempi di
distribuzione delle CRL estremamente veloci, tuttavia, dall'altro lato presenta
alcuni svantaggi che lo rendono non diffusamente impiegato; innanzitutto
metodo richiede un sistema di distribuzione sicuro che garantisca che le CRL
effettivamente raggiungano i sistemi degli utenti finali previsti, in secondo luogo
può dar luogo ad un incremento considerevole di traffico sulla rete, in terzo
luogo tale metodo non presenta né uno standard, né una proposta di definizione
che ne permetta un'implementazione diffusa.
Il programma MISSI del Dipartimento della Difesa americano (Multi-
level Infonnation System Security Initiative) che fornisce un'infrastruttura per il
sistema di messaggeria della Difesa presenta un esempio del metodo push.
Un altro metodo di notifica delle revoche, alternativo a quelli precedenti,
consiste nell'effettuare una transazione RQ�OLQH di verifica dello stato del
certificato; è basato sul protocollo OCSP, "Online Certificate Status Protocol"
[RFC2560].
Page 45
37
L'autorità di certificazione deve mettere a disposizione un server on-line
dedicato a questo servizio che garantisca disponibilità ed accessibilità continua
del servizio.
Questo metodo, sicuramente molto dispendioso data la presenza di un
server dedicato, rappresenta la soluzione più affidabile e tempestiva per la
gestione delle revoche e viene sempre più adottata per garantire gli utenti più
importanti o critici. La revoca dei certificati degli altri utenti sarà gestita con la
classica CRL e le sue varianti, in modo da non appesantire troppo il server.
L'utilizzo del protocollo OCSP risolve, così, il problema della revoca in
tempo reale; richiede però l'utilizzo di un canale sicuro di collegamento con il
server o, in alternativa, la possibilità da parte del server stesso di firmare le
risposte alle richieste OCSP.
���� 0RGHOOL�RUJDQL]]DWLYL�GL�3.,
Nella costruzione di infrastrutture a chiave pubblica scalabili su larga
scala, una delle difficoltà principali consiste nell'individuare e successivamente
validare cammini di certificazione sufficientemente brevi; dipendentemente dal
modello organizzativo di infrastruttura (o anche detto modello di fiducia) che si
adotta, il cammino di certificazione è più o meno ottimizzato.
La convenienza in termini di prestazioni ed efficienza dei cammini di
certificazione non è, l'unico fattore che determina l'adozione di un particolare
modello di fiducia; nella scelta, e nella successiva implementazione, incidono
anche il modello di politica di sicurezza definito e il modello di propagazione di
tale politica di sicurezza che si intende imporre attraverso i vari componenti
dell'architettura organizzativa adottata.
������ 6WUXWWXUD�JHUDUFKLFD
Per costruire cammini di certificazione di lunghezza accettabile si fa
riferimento alla teoria dei grafi da cui si vede che le strutture organizzate ad
albero o gerarchiche forniscono una soluzione efficiente al problema.
Nel modello gerarchico stretto la certificazione è realizzata solo dalle
autorità superiori nei confronti di quelle gerarchicamente inferiori, come indicato
Page 46
nella figura 3.5. Tutti i cammini di certificazione partono dal vertice, tutti gli
utenti devono quindi fidarsi della radice e conoscere la relativa chiave pubblica. I
vantaggi di tale struttura sono principalmente due:
1) Esiste un unico cammino di certificazione per tutti gli utenti e la scoperta di
tale cammino è abbastanza semplificata.
2) Data la sua struttura ad albero è particolarmente adatto per tutte quelle
organizzazioni internamente gestite in modo gerarchico.
)LJ����: struttura strettamente gerarchica
Lo svantaggio è che tutti i cammini di certificazione coinvolgono la radice
e quindi la fiducia è completamente riposta nella sicurezza della radice.
Un esempio di implementazione di infrastruttura a chiave pubblica
conforme al modello gerarchico è la PEM (Privacy Enhancement for Internet
Electronic Mail) [RFC 1421-1424].
Una variante al modello gerarchico stretto prevede che nella struttura ad
albero le autorità di certificazione si fidano l'una dell'altra e si siano rilasciate
reciprocamente dei certificati elettronici. Questo è il modello gerarchico
generale.
Con riferimento alla figura 3.6, l'autorità di certificazione CA1 ha
certificato la chiave pubblica dell'autorità di certificazione CA2 e viceversa;
Alice è stata, invece, certificata da CA4, Bob da CA5.
Page 47
39
)LJ����: struttura gerarchica generale
In tale struttura, risulta relativamente semplice costruire dei cammini di
certificazione tra coppie di interlocutori appartenenti a domini di fiducia
differenti (per singolo dominio di fiducia s’intende un dominio di utenti gestito da
una specifica autorità di certificazione), indipendentemente da quale autorità di
certificazione si assume quale radice del cammino. Supponiamo ora che Alice
assuma come radice la CA4; dato il tipo di architettura, Alice è in grado di
trovare sistematicamente un cammino di certificazione per qualunque
interlocutore; se Alice vuole verificare l'autenticità della chiave pubblica di Bob,
Alice deve verificare il cammino costituito dai seguenti certificati:
• il certificato contenente la chiave pubblica dell'autorità di certificazione CA2
emesso dalla CA4;
• il certificato contenente la chiave pubblica dell'autorità di certificazione CA5,
emesso dalla CA2;
• il certificato di Bob emesso dalla CA5
Il modello gerarchico generale è caratterizzato da un buon livello di
scalabilità ed efficienza. Il fattore non soddisfacente relativo a tale modello
riguarda la propagazione della fiducia attraverso il cammino dei certificati.
Ogni utente finale, quando verifica una determinata catena di certificati,
deve necessariamente fidarsi di ogni autorità di certificazione presente sul
cammino; si deve, cioè, fidare dell'accuratezza delle politiche di sicurezza di tutte
le autorità di certificazione presenti sul cammino, anche di quelle con cui
probabilmente non ha alcuna relazione diretta. In aggiunta, la maggior parte dei
Page 48
cammini di certificazione passano comunque attraverso la radice della gerarchia
(la radice nella figura 3.7 è l'autorità di certificazione CA1); virtualmente, quindi,
tutti gli appartenenti all'infrastruttura a chiave pubblica devono necessariamente
fidarsi ancora della radice; se un intrusore riuscisse a compromettere la chiave
privata della radice, la sicurezza dell'intera infrastruttura sarebbe
irrimediabilmente minata. E' di fondamentale importanza, quindi, implementare
sistemi sofisticati di protezione della chiave privata della radice della gerarchia.
Un modello derivante da quello precedente consiste in una struttura
gerarchica generale con connessioni aggiuntive tra i vari nodi; per tali
connessioni, non previste nel modello gerarchico generale, si parla di
certificazione incrociata (FURVV��FHUWLILFDWLRQ).
)LJ�������struttura gerarchica con collegamenti addizionali
La presenza di connessioni aggiuntive, quale quella in figura tra la CA2 e
la CA6, accorcia ulteriormente le lunghezze dei cammini di certificazione; le
connessioni aggiuntive possono essere sia unidirezionali sia bidirezionali, quale
quella tra CA5 e CA6. Si sottolinea che lo standard X.509 non impone alcun tipo
di struttura organizzativa; tuttavia, il modello gerarchico generale con
connessioni aggiuntive è implicitamente suggerito.
L'utilizzo del modello gerarchico o di una sua variante è consigliato nei
casi in cui la struttura organizzativa stessa dell'organizzazione è gerarchica.
������ 6WUXWWXUD�GLVWULEXLWD
Il problema principale legato al modello di fiducia gerarchico è che non
sempre tutti i fruitori di un'infrastruttura a chiave pubblica condividono l'assunto
Page 49
41
di doversi fidare di un'unica autorità di certificazione radice per qualunque
finalità. Tale considerazione si rafforza soprattutto negli ambiti commerciali e
finanziari.; è, infatti difficile trovare una singola autorità di cui tutte le
organizzazioni commerciali si fidano per la gestione delle loro informazioni
critiche.
Se, quindi, in un ambiente governativo, un modello gerarchico può essere
adeguato alle politiche operative e di sicurezza, in ambienti aziendali, finanziari o
commerciali è preferibile adottare modelli di fiducia cosiddetti distribuiti.
Un modello distribuito prevede la presenza di infrastrutture a chiave
pubblica distinte che a discrezione, secondo accordi reciprocamente pattuiti, si
certificano vicendevolmente. Ogni singola infrastruttura gestita autonomamente
da una o più organizzazioni che partecipano all'infrastruttura in questione, può
essere strutturata al suo interno secondo il modello di fiducia ritenuto più
adeguato alle esigenze interne.
)LJ�����: struttura distribuita
Il vantaggio è l'assenza di un'unica autorità di certificazione radice di cui
doversi completamente fidare. Lo svantaggio è che la struttura che ne deriva non
ha più una topologia ben definita che individui univocamente un cammino di
certificazione tra due utenti.
I due modelli organizzati di PKI visti sono i casi più estremi, esistono
varie realizzazioni intermedie in cui si cerca di mediare tra l'esigenza di una
Page 50
struttura efficiente e una struttura sicura ed indipendente. Un esempio è il
modello semplificato di ICE-TEL [YCC96] in cui la cross-certification non può
essere transitiva e quindi la ricerca di un cammino di certificazione si può
interrompere in presenza di due cross-certification.
Page 51
43
&DSLWROR����6,67(0,�',�',5(&725<
���� ,QWURGX]LRQH
I mezzi di comunicazione al giorno d’oggi sono basati sull’utilizzo di reti,
basti pensare alla rete postale, alla rete telefonica, ad Internet; per poter utilizzare
tali reti l’utente deve essere a conoscenza di alcune informazioni fondamentali
come ad esempio l’indirizzo o il numero di telefono della persona che vuole
contattare.
Ricordare questa informazione per un ristretto numero di amici non è un
grande problema basta gestire un'agendina personale, invece ci sono più
difficoltà quando si cerca di contattare una persona per la prima volta, di cui
probabilmente si conosce il nome, ma non il suo indirizzo postale o elettronico.
Nello stesso tempo anche se abbiamo già contattato qualcuno nel passato è
possibile che tale persona possa aver cambiato indirizzo e che non ci abbia
informato.
La soluzione a questo problema nel mondo telefonico è stata quella di
creare gli elenchi telefonici che vengono aggiornati una volta l'anno.
Comunque anche questa tecnica inizia a mostrare i suoi limiti in quanto
sono sempre più le persone che telefonano al di fuori del loro dominio. Per
questo motivo alcune compagnie telefoniche, come ad esempio la France
Telecom, hanno già prodotto elenchi telefonici elettronici.
Sarebbe utile che nel futuro tutte queste informazioni potessero essere
unite e si potesse creare un elenco globale in cui poter trovare il numero
telefonico, l'indirizzo di e-mail ed anche l'indirizzo postale delle persone.
La parola inglese Directory non è altro che l'equivalente italiano di elenco.
Page 52
Avere un database centralizzato per questa guida elettronica non è utile
principalmente per due motivi:
• una base di dati che copre tutte le informazioni delle reti del pianeta sarebbe
troppo grande e di conseguenza molto lenta nell'accedere ad una entry
individuale;
• chi dovrebbe mantenere questo database? Mantenimento e caricamento dei
dati sarebbero dispendiosi e poco efficienti.
Per queste ed altre ragioni un'organizzazione distribuita e localmente
amministrata è la soluzione migliore. Ogni elemento locale avrà cura del
caricamento dei dati, del loro mantenimento, delle istanze di sicurezza e della
gestione del servizio delle richieste degli utenti locali.
Inoltre sarà possibile fornire un servizio di informazione anche per tutti gli
utenti le cui richieste non possono essere soddisfatte nel loro dominio.
���� $OFXQL�HVHPSL�GL�'LUHFWRU\�6HUYLFH�H�ORUR�OLPLWD]LRQL�
Analizzeremo di seguito due servizi basati sui sistemi di directory per
comprendere meglio i loro limiti ed introdurre, successivamente, una possibile
soluzione.
Il servizio WHOIS [RFC954] è mantenuto dalla DDN NIC (Defence Data
Network, Network Information Center) e per la porzione Ip di Internet è
attualmente mantenuta dal GSI.
Contiene informazioni relative alle reti IP, ai managers di rete IP e relative
in modo specifico ai sistemi MILNET.
Il database WHOIS è grande abbastanza per mostrare i difetti di un
database centralizzato. In primo luogo la locazione centralizzata del database
WHOIS causa una risposta molto lenta durante i periodi in cui il numero delle
richieste è elevato, portando a limitazioni di memorizzazione dei dati; inoltre
l'intero servizio è inutilizzabile se il link al GSI è bloccato.
In secondo luogo l'amministrazione del database è centralizzata e questo
comporta che ogni cambiamento al database debba essere apportato a mano, in
modo da non rendere immediata la propagazione delle modifiche ed inoltre
Page 53
45
introduce un’altra possibile causa di errore nell’accuratezza delle informazioni.
Questo in particolare è un problema che affligge la maggior parte dei sistemi che
tentano di realizzare delle Directory Service con un database centralizzato.
Analizziamo ora il servizio DNS [RFC1034-5] (Domain Name Service)
che contiene informazioni sul mapping host tra nome di dominio, ad esempio
"deis.unibo.it", ed il relativo indirizzo numerico IP. Il sistema è stato realizzato
in quanto è molto più facile ricordare nomi di macchine piuttosto che stringhe di
numeri.
Il tutto viene mantenuto in modo distribuito: ogni server DSN fornisce il
nameservice solo per un numero limitato di domini. Inoltre nameservice
secondari possono essere identificati per ogni dominio, cosicché una rete fuori
portata non sarà necessariamente tagliata fuori dal nameservice. D'altra parte
nonostante il DNS sia eccellente nel fornire tali servizi, ci sono dei problemi che
lo caratterizzano.
Il DNS ha una capacità di ricerca molto limitata ed in secondo luogo
supporta solamente un piccolo numero di tipi di dati ed aggiungere nuovi tipi di
dati implicherebbe dei cambiamenti molto rilevanti.
���� /D�VROX]LRQH�DWWUDYHUVR�OD�GHILQL]LRQH�GL�XQRVWDQGDUG�;����
CCITT (Comite Consultatif International Telegrafic et Telephonique) e
ISO (International Standard Organization) hanno congiuntamente sviluppato
degli standard per i servizi di directory. La versione del CCITT è stata
pubblicata nel 1988 attraverso l'insieme di raccomandazioni che va da X.500 a
X.521; la versione equivalente ISO è stata approvata nel 1990 con il nome di ISO
9594 ed è composta di otto parti [DIR]. Questi standard sono stati ampliati nel
1993 per supportare la replicazione delle informazioni.
Page 54
&&,77 ,62 7,7/(
X.500 9594-1 Overview of Concepts, Models and Services
X.501 9594-2 Models
X.509 9594-8 Authentication Framework
X.511 9594-3 Abstract Service Definition
X.518 9594-4 Procedures for Distributed Operation
X.519 9594-5 Protocol Specifications
X.520 9594-6 Selected Attribute Types
X.521 9594-7 Selected Object Classes
X.525 9594-9 Replication
Tabella 4.1
La definizione dell'X500 data dal CCITT è:
�XQD�FROOH]LRQH�GL�VLVWHPL�DSHUWL�FKH�FR�RSHUDQR�SHU�PDQWHQHUH�XQ
GDWDEDVH�ORJLFR�GL�LQIRUPD]LRQL�VX�XQD�VHULH�GL�RJJHWWL�GHO�PRQGR�UHDOH�
*OL�XWHQWL�GHOOD�'LUHFWRU\�SRVVRQR�OHJJHUH�R�PRGLILFDUH�OLQIRUPD]LRQH��R
SDUWH�GL�HVVD��VROR�VH�KDQQR�L�SULYLOHJL�QHFHVVDUL�
Il CCITT chiama la Directory in singolare per riflettere l'intenzione di
creare una Directory globale singola.
X.500 è un protocollo definito a livello application dello standard OSI
(Open System Interconnection), che specifica un modello per connettere
Directory Service locali per formare una Directory Service globale e distribuita. I
databases locali contengono e mantengono parte del database globale e la
directory di informazione è resa disponibile da un server locale. All'utente
sembra che l'intera directory sia accessibile dal server locale.
Mentre la maggior parte delle informazioni disponibili al giorno d'oggi
tramite X.500 sono sulle persone e sulle organizzazioni, il disegno della directory
X.500 permetterebbe anche di caricare dati su altre entità (o oggetti) come risorse
di rete, applicazioni o hardware.
Page 55
47
Un servizio di Directory basato su X.500 offre i seguenti vantaggi:
• 'HFHQWUDOL]]D]LRQH� ogni sito in cui gira X.500 è responsabile solamente per
la sua parte locale della Directory, così il mantenimento e l'aggiornamento dei
dati può essere fatto istantaneamente.
• $ELOLWj� GL� ULFHUFD�� X.500 permette delle facilitazioni nella ricerca che
permettono all'utente di formulare richieste anche molto complesse.
• 1DPHVSDFH� RPRJHQHR�� X.500 permette un singolo namespace omogeneo
all'utente. Inoltre rispetto al DNS il namespace dell'X.500 è più flessibile ed
esteso.
• 'LUHFWRU\� 6HUYLFH� VWDQGDUGL]]DWD�� Fosì come X.500 può essere usato per
costruire una directory standardizzata, le applicazioni che richiedono
informazioni di directory (e-mail, allocatori di risorse automatizzati...)
possono accedere a tutto l'universo delle informazioni in modo uniforme, non
c'è problema dove esse girino in quel momento.
Grazie a tali caratteristiche X.500 è stato usato per fornire la struttura di
un servizio di White Pages globale. D'altra parte tale protocollo è basato su degli
standards e ci sono, quindi, pochissime incompatibilità tra le varie versioni di
servizi di directory basati su X.500. Inoltre il namespace è consistente e,
pertanto le informazioni nella directory possono essere facilmente individuate e
recuperate.
Ci sono comunque alcune limitazioni che si devono prendere in
considerazione. Sono legate alla tecnologia dell'X.500 così come è attualmente
realizzata. Un prezzo che si deve pagare per la flessibilità in ricerca è il declino
delle prestazioni. Questo poiché la ricerca in un namespace distribuito può dover
attraversare l'intera rete.
Un secondo problema con le implementazioni è che per ragioni di
sicurezza solo una piccola parte di tutte le informazioni sono fornite all'utente.
Inoltre se una ricerca comprende parecchie entries solo un piccolo numero viene
ritornato all'utente.
Page 56
���� ,O�0RGHOOR�,QIRUPDWLYR
L’X.500 chiama il completo database della Directory: Directory
Information Base� (DIB) e lo considera come un database singolo, logico e
globale; che può essere distribuito attraverso la rete.
La DIB immagazzina le informazioni sotto forma di oggetti, le cui
caratteristiche sono definite dai suoi attributi. Tutti gli oggetti sono identificati
da un entry.
Allo scopo di localizzare la corretta "entry" all'interno del DIB,
l'informazione contenuta deve essere definita senza ambiguità. Un modo
possibile per ottenere questo è utilizzare una struttura gerarchica ad albero.
L'X.500 definisce un albero logico per il DIB, chiamato Directory
Information Tree (DIT). Lo standard non definisce l'ordinamento degli oggetti
all'interno del DIT. Comunque, ci si aspetterà che i DIT seguiranno una struttura
dove le entries di livello più alto nell'albero rappresenteranno gli oggetti come
nazioni o organizzazioni, mentre quelle di livello più basso saranno le persone.
)LJ�����: Directory Information Tree, struttura gerarchica dei nomi
Root node
Country =AU Country=US Country=UK
Organization =ABC Ltd
Locality =New York
Organization =ABC Ltd
Org. Unit =Sales
Common Name= F. Jones
Org. Unit =Production
Common Name= A. Chew
Common Name= Fax Machine
Common Name= J. Smart
Page 57
49
Le informazioni riguardanti un oggetto della Directory si recuperano
attraverso il Distinguished Name (DN) dell'entry. Il DN è la chiave dell'entry, in
quanto identifica univocamente e senza ambiguità l'oggetto in questione
all'interno del DIT.
Ad ogni entry è associato anche un Relative Distinguished Name (RDN),
il quale definisce univocamente un oggetto all'interno di un certo contesto.
Il modo più semplice per spiegare la differenza tra DN e RDN è di
utilizzare un'analogia con il telefono che analogamente usa una struttura ad
albero per il suo indirizzamento. Ad esempio, numeri telefonici uguali in aree
diverse sono contraddistinti dai rispettivi prefissi del distretto e del paese.
Per esempio, la Trattoria al Ponte di Bologna ha il numero 242223 che
viene distinto all'interno del distretto di Bologna, il numero 051-242223 è
distinguibile all'interno dell'Italia, infine il numero +39-051-242223 identifica la
trattoria nel mondo intero.
)LJ�����: Esempi di DN e RDN
Il DN è formato dall'unione della sequenza di RDN, ripercorrendo il DIT
dalla posizione dell'oggetto fino alla radice.
���� ,O�0RGHOOR�)XQ]LRQDOH
La struttura complessiva della Directory X.500 è schematizzata nella
figura 4.3 che segue.
Page 58
)LJ�����: Struttura di un sistema di Directory
L’idea di base consiste nel fatto che le informazioni locali di una
organizzazione, come ad esempio una università, siano mantenute localmente in
una o più DSA (Directory System Agents). È importante sottolineare che
"localmente" assume un significato flessibile in questo contesto in quanto è
possibile che un DSA mantenga informazioni di più organizzazioni, od anche
l'opposto che la Directory dei dati di una grande organizzazione può risiedere in
DSA multipli.
Un DSA è essenzialmente un database con due caratteristiche
fondamentali:
• le informazioni sono caricate in accordo con il modello dell'X.500
• è possibile, se necessario, scambiare dei dati con altri DSA attraverso l'uso
del protocollo DSP (Directory System Protocol) dell'X.500.
Gli utenti vedono la Directory come unica e non ci interagiscono
direttamente, ma tramite un DUA (Directory User Agent). I DUA richiedono
servizi ai DSA nell'interesse degli utenti della Directory.
Page 59
51
I DSA sono i soli che accedono e mantengono il database della Directory.
Ogni DSA mantiene una parte separata della Directory. Naturalmente la
Directory potrà essere composta anche da un solo DSA, in tal caso la Directory è
centralizzata.
Nella maggior parte dei casi, la Directory sarà distribuita e composta da
numerosi DSA.
Tutte le DSA nella Directory X.500 sono interconnesse in accordo con il
modello predefinito DIT (Directory Information Tree); i dati caricati nelle DSA
hanno una struttura ad albero che contiene parte del DIT globale.
Ogni DSA per poter rispondere correttamente alle richieste del DUA e
comunicare con gli altri DSA deve possedere due tipi di informazioni: la
directory information che è l’insieme di entry che lui ha memorizzato e la
knowledge information che è l’insieme di conoscenze necessarie per individuare
la sua posizione all’interno del DIT ed è espressa in termini di riferimenti interni
o esterni.
Queste informazioni sono descritte nel DSA Information Model [CHA96
par. 2.13] e sono contenute nelle speciali entry DSA (DSE). Il nome e l’indirizzo
di un remoto DSA è chiamato Access Point ed è contenuto nel Knowledge
references [CHA96 par. 4.2].
Sono stati definiti otto tipi di Knowledge reference: superior reference,
subordinate reference, non-specific subordinate reference, cross reference,
immediate superior reference, supplier reference, consumer reference e master
reference [CHA96 par. 9.2]. Grazie a queste informazioni è possibile navigare
all'interno della Directory.
Un esempio di Knowledge Information è indicato in figura 4.4.
Page 60
)LJ�����: Knowledge information
���� ,O�3URWRFROOR�GL�FRPXQLFD]LRQH�'$3
La Directory User Agent rappresenta il primo livello di astrazione e permette
all’utente di accedere ai servizi di Directory. Questi servizi sono stati
standardizzati, e comprendono una serie di operazioni che possono essere
compiute sulla Directory dall’utente. Esiste un protocollo che regola tali
DIRECTORY INFORMATION TREE
D S A 2 DSA3
DSA4 DSA1
Root node
Country=USCountry=AU
Organization= ABC Ltd
Org. Unit =Production
Org. Unit =Sales
Common Name= John Smith
Common Name= Wendy Smart
Locality =Victoria
Locality =New York
Org. Unit =Marketing
Common Name= Frank Jones
KNOWLEDGE INFORMATION FOR DSA3
Context prefix: C=AU, O=ABC LtdSuperior reference: DSA2, PSAP address
Internal reference: O=ABC Ltd, PTR
Internal referenceOU=ProductionPTR
Internal referenceOU=SalesPTR
Non-specfic subordinatereference: DSA4, PSAPaddress
Internal referenceCN=John SmithPTR
Internal referenceCN=Wendy SmartPTR
Page 61
53
operazioni ricavato da due servizi OSI: il Remote Operation Service (ROSE) e il
Association Central Service (ACSE).
Il protocollo risultante è conosciuto come Directory Access Protocol (DAP) ed è
usato dal DUA per trasmettere la richiesta al DSA.
Le operazioni che possono essere richieste sono di bind, di interrogazione, di
abbandono e di modifica.
L'operazione di Bind è la prima da effettuare, in quanto, permette di stabilire una
connessione con un DSA.
Le operazioni di interrogazione possono essere, così, classificate:
• di lettura: forniscono all'utente il valore di un particolare attributo tenuto in
una specifica entry della Directory. Gli argomenti in input sono i nomi e le
indicazioni delle informazioni che si vogliono consultare. Il risultato di questa
operazione è dato dal nome dell'entry, e dai tipi e valori degli attributi
richiesti;
• di comparazione: sono usate per confrontare un valore di un attributo con
quello già esistente nell'entry. Gli argomenti in input consistono di un valore
di un attributo ed il corrispondente nome. L'output è dato dal valore di
Vero/Falso indicante la presenza dell'attributo;
• di List: elencano tutte le entries nel livello sottostante nell'albero gerarchico;
• di ricerca: sono usate per ricercare particolari porzioni del DIT e ritornano le
informazioni riguardanti le entries selezionate. L'argomento di input identifica
l'entry base dalla quale far partire la ricerca e la parte del DIT dove
effettuarla.
L'operazione di abbandono permette all'utente di chiudere la sessione.
Le operazioni di modifica offrono la possibilità di modificare un nome,
aggiungere, rimuovere e modificare un'entry.
Page 62
���� 0HWRGL�SHU�OD�ULFHUFD�GHOOH�LQIRUPD]LRQL�
Analizziamo ora come una richiesta viene inoltrata all’interno della Directory. Le
tecniche utilizzate sono due, la prima conosciuta con il nome di FKDLQLQJ prevede
che quando una richiesta arriva ad un DSA quest’ultimo esegue le operazioni di
cui è responsabile e, se necessario, richiede ad un altro DSA di completare la
richiesta. Per non ripetere più volte la stessa operazione, il DSA aggiunge delle
informazioni utili per notificare quali parti della richiesta sono state processate.
Queste informazioni sono generate dal primo DSA e gradualmente modificate
dagli altri DSA ed infine ritornate all'utente.
Si forma quindi una FDWHQD tra DSA che viene ripercorsa due volte prima che la
risposta sia inoltrata all'utente.
)LJ�����: Chaining
L'altra tecnica utilizzata è chiamata UHIHUUDO e prevede che il DUA inoltra la
richiesta al suo DSA di riferimento che, allorché non possieda l'informazione
invia la domanda ad un altro DSA. Qualora i dati richiesti non siano presenti
nell'ultimo DSA, questi ritorna la risposta al primo DSA con l'indicazione di un
DSA referente a cui chiedere l'informazione. A questo punto il primo DSA invia
la richiesta al DSA referenziato e ottiene la risposta.
Page 63
55
)LJ�����: Referral
���� 8Q�SURWRFROOR��OHJJHUR��GL�DFFHVVR�DOOH�GLUHFWRU\�SHU,QWHUQHW�/'$3
La comunità di Internet ha definito una versione semplificata del protocollo
DAP, chiamato Lightweight Directory Access Protocol (LDAP) che si posiziona
come uno standard universale per l'accesso alle directory attraverso la rete
Internet [RFC1777]. Un aspetto chiave del LDAP è proprio quello di porsi
direttamente sopra il TCP/IP.
LDAP utilizza la stessa struttura di base del DAP, ma fa circolare i dati sulla rete
sotto forma di catene di caratteri.
Il modello di comunicazione utilizzato da LDAP è il classico client-server. Il
client trasmette la sua richiesta al server tramite LDAP. Il server che è l'unico che
può accedere alla directory elabora la richiesta ed invia la risposta al client
sempre tramite LDAP.
L'idea di LDAP è stata quella di semplificare il lato client in modo da rendere
accessibili a tutti i servizi di directory.
Page 64
Le operazioni che possono essere richieste attraverso il protocollo LDAP sono
quelle classiche di collegamento, ricerca, modifica e abbandono definite dal
DAP.
I servizi di directory è considerato il miglior sistema per pubblicare certificati e
CRL, quindi LDAP è il protocollo ideale per recuperarli.
Una descrizione su come usare LDAP per recuperare certificati e CRL è riportata
in [RFC2559]; sono state proposte anche delle estensioni al protocollo per
supportare meglio le PKI basate sui certificati X.509 [LDAPv3].
Page 65
57
&DSLWROR����6,67(0,�',675,%8,7,�(�02%,/,7$
'(/�&2',&(
���� ,QWURGX]LRQH
I sistemi distribuiti sono da tempo oggetto di studio, e un’attenzione
particolare è stata dedicata loro negli ultimi anni, soprattutto per il crescente
sviluppo di quella che può essere considerata la rete geografica per eccellenza:
Internet. Questa tendenza è certamente connessa all'importanza assunta da
numerosi servizi di rete, che inducono ad un sempre crescente interesse del
mercato verso la "interconnessione globale".
I modelli progettuali che erano stati concepiti per sistemi distribuiti
convenzionali, formati da piccole reti locali, risultano non ottimizzati e quindi
inefficienti per una distribuzione su larga scala, evidenziando problemi legati alla
flessibilità, alla scalabilità e alla tolleranza ai guasti.
Questi problemi hanno portato alla ricerca di nuove soluzioni e nuovi
modelli, in cui non è necessariamente presente un livello di trasparenza delle
risorse, che risulta spesso di inefficiente realizzazione. In questo contesto nasce
l'idea della mobilità del codice, che consente di cambiare dinamicamente il
collegamento tra un frammento di codice e la locazione della sua esecuzione.
���� ,�VLVWHPL�GLVWULEXLWL
I primi sistemi informatici erano caratterizzati da strutture imponenti e
molto costose, che solo importanti centri di ricerca potevano permettersi: le
grosse risorse di calcolo erano rappresentate dai mainframe. Queste macchine
imponenti non erano certo progettate per essere facilmente collegate tra loro,
quindi lavoravano tipicamente in modo indipendente l'una dall'altra.
I progressi elettronici e le innovazioni tecnologiche hanno portato notevoli
miglioramenti di prestazioni e di dimensioni nell'ambito informatico, offrendo
Page 66
sul mercato macchine accessibili, economicamente, anche a livello di piccole
aziende. Questa novità ha rivoluzionato l'atteggiamento nei confronti dei sistemi
informatici: nella tecnologia a mainframe, si doveva comprare la macchina più
grande che ci si potesse permettere, perché con una spesa maggiore si ottenevano
prestazioni notevolmente migliori [T94]. Con la nuova tecnologia dei
microprocessori, la soluzione più efficace rispetto al costo è quella di
raggruppare un numero maggiore di CPU (Central Process Unit) in un singolo
sistema: con lo stesso investimento si può ottenere un rapporto prezzo prestazioni
più favorevole rispetto ai grandi sistemi centralizzati, che può portare ad una
potenza di calcolo teoricamente infinita, raggruppando un numero sempre
crescente di microprocessori.
La diffusione di massa degli elaboratori ha spinto velocemente all'acquisto
di più computer da affiancare sia per trarre benefici dall'incremento di prestazioni
che ne consegue, sia per la natura intrinsecamente distribuita di alcune
applicazioni. Da qui la creazione di reti locali, LAN (Local Area Network), per
collegare i calcolatori e quindi in generale tutte le risorse utilizzabili, hardware e
software. Queste reti offrono la possibilità di accedere da ogni macchina a tutte le
risorse disponibili, come le stampanti, le unità di memorizzazione o altre
periferiche, indispensabili durante lo svolgimento delle attività lavorative, ma
componenti costosi che utilizzati da più macchine, aumentando l'efficienza totale
del sistema.
I collegamenti di rete, consentono una distribuzione efficiente del carico
su tutte le macchine disponibili, costruendo un sistema flessibile, affidabile e
aperto: le scelte di gestione si adattano alle risorse disponibili, gli eventuali guasti
non causano la totale caduta del sistema, e le aumentate esigenze sono soddisfatte
con l'inserimento di nuovi elementi, che permettono una crescita incrementale
della rete.
Il numero sempre crescente di macchine collegabili e la distanza sempre
più elevata che li separa, ha introdotto la terminologia di VLVWHPL�GLVWULEXLWL��per
evidenziarne la contrapposizione alla tecnologia classica dei sistemi centralizzati.
I sistemi distribuiti sono una “FROOH]LRQH� GL� FDOFRODWRUL� DXWRQRPL�� FROOHJDWL
WUDPLWH�XQD�UHWH�GL�LQWHUFRQHVVLRQH�H�GRWDWL�GL�VRIWZDUH�FKH�KD�OR�VFRSR�GL�FUHDUH
VHUYL]L�LQWHJUDWL” [CDK94].
Page 67
59
Con il termine servizi integrati si intendono servizi che possono essere
implementati tramite la coordinazione di vari nodi del sistema ma che sono
percepiti dall’utente come un unico servizio.
Per poter parlare di sistema distribuito, non è sufficiente avere dei
calcolatori collegati in retedamentale, è necessario che questi sistemi abbiano un
obiettivo comune da raggiungere, come ad esempio la condivisione di un insieme
di risorse ubicate in vari punti della rete.
Per ricavare un vantaggio reale e completo dall'utilizzo di sistemi
distribuiti, si devono rispettare ed ottenere alcune caratteristiche:
• &RQGLYLVLRQH�GHOOH�ULVRUVH�� i vari componenti di un sistema distribuito sono
dotati di risorse di vario tipo (CPU, file, basi di dati , stampanti, ecc.). La
condivisione di queste risorse da parte dei nodi del sistema consente di ridurre
i costi complessivi, evitando un’inutile replicazione.
• $SHUWXUD�� indica l’estendibilità del sistema, cioè la sua capacità di accettare
nuove risorse sia di tipo fisico (nuovo hardware, nuovi nodi, ecc.) che logico
(nuovi protocolli di comunicazione, nuovi servizi, ecc.), in maniera dinamica.
Ciò è possibile adottando interfacce standard di comunicazione tra i
componenti del sistema.
• &RQFRUUHQ]D� la presenza di diverse unità computazionali e di una
molteplicità di applicazioni e servizi crea la possibilità di esecuzione
concorrente (in cui più processi si contendono l’uso della stessa CPU) e
parallela (in cui più processi eseguono contemporaneamente su CPU diverse).
• 6FDODELOLWj� indica la capacità del sistema di funzionare mantenendo le
proprie caratteristiche peculiari (in particolare l’efficienza delle applicazioni e
dei servizi) indipendentemente dalla dimensione del sistema (intesa
principalmente come numero di nodi interconnessi).
• 7ROOHUDQ]D�DL�JXDVWL� permette al sistema di funzionare correttamente anche
in presenza di guasti ad uno o più componenti. Viene ottenuta tramite
ridondanza e procedure di ripristino (recovery).
Page 68
• 7UDVSDUHQ]D� indica la possibilità per l’utente di vedere il sistema come
un’unica entità anziché come un insieme di calcolatori interconnessi. Si
applica in vari contesti. I principali tipi di trasparenza a cui si è interessati
sono:
� 7UDVSDUHQ]D� QHOO¶DFFHVVR�� permette di accedere nel medesimo modo a
risorse locali e remote.
� 7UDVSDUHQ]D� QHOO¶DOORFD]LRQH� permette di accedere alle risorse senza
sapere dove queste sono allocate.
� 7UDVSDUHQ]D� QHOOD� FRQFRUUHQ]D�� permette a più processi di eseguire
concorrentemente ed utilizzando le stesse risorse senza che vi sia
interferenza reciproca.
� 7UDVSDUHQ]D� QHOOD� UHSOLFD]LRQH�� permette di avere più copie di una
medesima risorsa (con obiettivi di tolleranza ai guasti e/o migliori
prestazioni) senza che ciò sia visibile agli utilizzatori della risorsa.
� 7UDVSDUHQ]D� QHL� JXDVWL� permette alle applicazioni di funzionare
correttamente anche in presenza di malfunzionamenti o guasti.
� 7UDVSDUHQ]D�QHOOD�PLJUD]LRQH� permette il movimento di risorse senza che
l’utente ne abbia conoscenza.
� 7UDVSDUHQ]D� QHOOH� SUHVWD]LRQL� permette di variare la configurazione del
sistema per far fronte a variazioni di carico computazionale o di altro tipo.
� 7UDVSDUHQ]D� QHOOH� GLPHQVLRQL� permette al sistema e alle applicazioni di
variare in dimensioni senza che la struttura del sistema e gli algoritmi
delle applicazioni ne risentano.
• 6LFXUH]]D�� la possibilità di poter accedere alle informazioni disponibili su
tutto il sistema consente ad ogni utente di reperire qualsiasi tipo di dato,
anche quello che non si vorrebbe diffondere. Le informazioni private, inserite
in un sistema distribuito, devono, quindi, essere protette da accessi
indesiderati, per evitare di farle consultare o modificare.
Page 69
61
���� 0RGHOOR�&OLHQW�6HUYHU
La comunicazione nei sistemi distribuiti è un aspetto molto importante.
Essa permette infatti di coordinare i componenti del sistema per raggiungere
l’obiettivo comune.
Il tradizionale modello di comunicazione su cui si basano i sistemi
distribuiti è il Client-Server, nella sua definizione si è cercato di garantire tutte le
caratteristiche delineate nel paragrafo precedente. In questo modello esistono due
tipi di entità il cui ruolo è ben distinto: il servitore che è in grado di erogare
servizi (in generale accesso e manipolazione delle risorse del sistema), ed il
cliente che interagisce con il servitore per ottenere i servizi di cui ha bisogno.
I servitori hanno accesso diretto alle risorse e offrono un’interfaccia
tramite la quale interagire con esse. I clienti utilizzano le risorse invocando i
servizi della suddetta interfaccia. In questo modo è possibile ottenere un accesso
controllato e trasparente alle risorse.
La comunicazione tra clienti e servitori avviene tramite precisi protocolli
che stabiliscono come invocare i servizi e come si riceveranno le relative
risposte. In ogni caso clienti e servitori scambiano tra loro esclusivamente dati.
L'impiego di questo modello comporta i seguenti vantaggi:
• Le interazioni dirette con le risorse avvengono generalmente in ipotesi di
località (il servitore è locale alle risorse che gestisce) e in modo controllato
(attraverso una rigida interfaccia).
• Non è necessario conoscere l’allocazione delle risorse ma solo un nome
(globale) che le identifica: si raggiunge l’obiettivo di trasparenza alla
allocazione adottando un servizio di risoluzione dei nomi.
• E’ possibile implementare meccanismi di fault tolerance attraverso l’uso di
server multipli, gestiti anche in modo trasparente.
• L’eterogeneità è superata adottando protocolli standard di comunicazione (si
trasmettono solo dati e dunque è sufficiente accordarsi per uno standard sulla
loro rappresentazione).
D’altra parte al modello sono state poste diverse critiche, legate al
sovrautilizzo delle risorse di interconnessione (accettabile in un ambiente locale,
Page 70
dove le reti sono tipicamente a larga banda e bassa latenza, ma non più in
ambiente geografico) e alla scarsa flessibilità e dinamicità dei servizi offerti.
L’elevato traffico di rete si riscontra in quei servitori che forniscono solo
servizi di basso livello, costringendo i clienti a trasferire grosse moli di dati da
elaborare poi localmente.
Si pensi al caso in cui si voglia ottenere la media di una serie di valori
presenti in una tabella gestita da un apposito servitore: se il servitore è in grado
solo di leggere e scrivere una determinata riga della tabella l’unico modo per
ottenere l’elaborazione voluta è trasferire tutta la tabella sul cliente ed eseguire lì
i dovuti calcoli.
Una possibile soluzione è di implementare sul servitore tutte le
funzionalità (anche di alto livello) di cui i possibili clienti potranno avere
bisogno, rendendo però così inutilmente complesso il servitore. In genere è
necessario individuare il giusto trade off tra traffico generato e complessità.
I tentativi di superare questi limiti si sono mossi nella direzione della
programmabilità dei server, introducendo la possibilità di inviare assieme alle
richieste di servizio, anche il codice che esegue il servizio stesso.
���� 0RELOLWj�GHO�FRGLFH
Per superare i limiti di flessibilità del modello cliente/servitore sono nati
una serie di approcci basati sulla mobilità del codice. La mobilità del codice è la
capacità di cambiare dinamicamente il collegamento tra frammenti di codice e la
locazione in cui sono eseguiti [CPV97]. Dalla definizione emerge che l'ambiente
di azione naturale della mobilità del codice sono i sistemi distribuiti.
Le tecniche che si basano sulla mobilità del codice tentano di risolvere i
principali problemi che caratterizzano il tradizionale approccio ai sistemi
distribuiti: l'obiettivo ultimo è di offrire direttamente al programmatore forme di
controllo sullo spostamento di ogni entità tra i vari nodi, inserendo un supporto
run-time che implementi tutti i meccanismi necessari per la ricerca e la mobilità
dei componenti, e che sia capace di adattarsi alla particolare politica di gestione
scelta dall'amministratore di sistema.
Page 71
63
Questa nuova visione del sistema appesantisce il ruolo del programmatore,
che in prima persona deve saper sfruttare le caratteristiche ed i vantaggi della
mobilità del codice. Infatti la mobilità permette di modificare GLQDPLFDPHQWH� il
collegamento tra un frammento di codice e la locazione in cui eseguirlo,
scegliendo la locazione in funzione delle esigenze attuali. Per trarre benefici, si
può decidere di spostare l'esecuzione sul nodo meno carico, su quello in cui
risiede la risorsa con cui interagire, su quello attualmente più stabile o su quello
che offre i collegamenti più affidabili.
���� &RQWUROOR�VXOOD�ORFD]LRQH�GHOOH�ULVRUVH
L'obiettivo tradizionale dei sistemi operativi distribuiti era quello di non
fornire all'utente alcuna informazione sulla locazione delle risorse, anzi di non
fare neppure trasparire l'esistenza stessa di nodi remoti. Le funzionalità di alto
livello messe a disposizione da un sistema operativo realmente distribuito,
consentono l'astrazione della posizione fisica degli oggetti nella rete, per cui tutte
le risorse sono utilizzate come se fossero locali (Figura 5.2). Questo consente al
programmatore di sviluppare applicazioni con facilità referenziando le risorse
locali e remote con gli stessi meccanismi, indipendentemente dal nodo in cui
risiedono.
)LJ�����: Nei sistemi distribuiti tradizionali la locazione deicomponenti è trasparente per l'utente.
Nei sistemi distribuiti che supportano la mobilità, al contrario di quanto
appena visto, è consentita la rilocazione dinamica dei i componenti, intesi sia
Page 72
come unità di esecuzione (ad esempio un 'frammento di codice) sia come risorse
utilizzate o condivise dalle unità appena citate (ad esempio un file).
Il codice mobile stravolge il tradizionale approccio verso i sistemi
distribuiti: l'utente deve conoscere in modo esplicito la posizione fisica in cui le
varie entità sono allocate nella rete, per poterle referenziare direttamente (Figura
5.3). Al programmatore è affidato il compito di sfruttare la conoscenza della
locazione dei componenti per mettere in pratica i vantaggi della mobilità del
codice. Per esempio l'utente deve sapere dove risiedono le risorse da utilizzare
per trasferire, nella stessa macchina, il frammento di codice interessato
all'interazione con la risorsa, per il beneficio di realizzare una esecuzione locale.
)LJ�����:�I sistemi basati sulla mobilità permettono la rilocazionedinamica dei componenti, per cui si deve avere conoscenza
esplicita della posizione di ognuno di essi.
���� /LQJXDJJL�D�FRGLFH�PRELOH
Sono stati proposti numerosi linguaggi di programmazione finalizzati ad
un uso su Intemet, con la caratteristica comune di fornire aspetti legati alla
mobilità del codice, che a differenza i dell'approccio tradizionale client-server,
integrano una mobilità su reti a larga scala.
Prima di confrontare i linguaggi tradizionali e quelli a codice mobile,
definiamo alcuni concetti chiave indispensabili per proseguire [FPV98]:
• DPELHQWH� GL� HVHFX]LRQH (&(: &RPSXWDWLRQDO� (QYLURQPHQW): rappresenta
l'identità della locazione in cui si svolge l'esecuzione.
• XQLWj�GL�HVHFX]LRQH�((8: ([HFXWLRQ�8QLW): rappresenta un flusso sequenziale
di esecuzione, che comprende oltre al codice, lo i stato di esecuzione e lo
Page 73
65
spazio dei dati; esempi di EU sono un singolo Thread in un sistema multi-
Thread o un qualunque processo sequenziale.
• ULVRUVD: rappresenta un entità che può essere condivisa tra più unità di
esecuzione, per esempio una variabile, un file o un oggetto in un sistema
object-oriented.
Nei linguaggi tradizionali, come il C o il Pascal, ogni unità di esecuzione
si svolge totalmente in un unico ambiente, ed il collegamento al suo codice è
generalmente di tipo statico. Nei linguaggi basati sulla mobilità del codice
[CGPV97], invece, le parti fondamentali di una unita di esecuzione, cioè il
segmento di codice, lo stato di esecuzione e lo spazio dei dati, possono spostarsi
dall'ambiente di esecuzione in cui risiedono ad un altro, in modo autonomo.
Distinguiamo i linguaggi di programmazione in funzione del tipo di
mobilità che supportano [CPV97], per evidenziare il livello di spostamento
consentito.
♦ 0RELOLWj�IRUWH (6WURQJ�0RELOLW\):�un linguaggio supposta la mobilità forte se
consente alle sue unità di esecuzione di ,spostarsi dall'ambiente in cui
eseguono ad un altro, trasportando ile loro parti caratteristiche: codice, stack e
spazio dei dati. Prima della trasmissione, il flusso di esecuzione viene
bloccato per essere poi ripristinato nell'ambiente di destinazione. Questo
permette al flusso di esecuzione di bloccarsi non appena si esegue l'istruzione
di trasferimento e di riprendere l'esecuzione nell'ambiente di destinazione
esattamente dall'istruzione successiva: questa proprietà consente al linguaggio
di essere più efficiente rispetto al caso successivo.
♦ 0RELOLWj�GHEROH (:HDN�0RELOLW\): un linguaggio supposta la mobilità debole
se consente lo spostamento di codice (ed eventualmente del suo spazio dei
dati), o di oggetti nel caso di un linguaggio object-oriented. Le unità di
esecuzione, al contrario del caso precedente, non hanno la capacità di
spostarsi: all'interno dell'ambiente di esecuzione destinatario si effettua un
collegamento dinamico tra un'unità di esecuzione dell'ambiente stesso e il
codice proveniente da un altro ambiente o scaricato dalla rete. L'unità di
Page 74
esecuzione che si associa al codice in arrivo può essere creata appositamente,
su necessità ("by need"), oppure se ne può sfruttare una preesistente.
Affinchè un linguaggio sia adatto per lo sviluppo di agenti deve essere
dotato di alcune proprietà:
• 3RUWDELOLWj��i sistemi ad agenti mobili sono tendenzialmente sistemi aperti, è
essenziale dunque che gli agenti siano in grado di eseguire su qualunque
piattaforma. Per questo motivo vengono preferiti i linguaggi interpretati,
dotati di macchine virtuali portabili.
• 6LFXUH]]D�� dal punto di visto della protezione dell’ambiente rispetto alle
azioni degli agenti. Sono preferibili linguaggi dotati di controllo stretto sui
tipi, incapsulamento, accesso controllato alla memoria.
• 5DSLGD� SURWRWLSD]LRQH� la possibilità di scrivere agenti velocemente è una
caratteristica importante. Per questo molti dei sistemi reali si basano su
linguaggi di scripting oppure su linguaggi object oriented. I primi però
soffrono di una scarsa modularità. Nel modello object oriented gli agenti sono
oggetti di prima classe, ed incapsulano sia lo stato che il codice.
���� 3DUDGLJPL�GL�SURJHWWD]LRQH�EDVDWL�VXOOD�PRELOLWj�GHOFRGLFH
Un paradigma di progettazione è la specifica configurazione dei
componenti e delle loro interazioni all'interno di un sistema, cioè la
configurazione che il progettista usa per definire l'architettura di una applicazione
[FPV98].
La progettazione di applicazioni software richiede la scelta di un adeguato
linguaggio di programmazione; quando si parla di mobilità del codice e
l'ambiente di esecuzione è distribuito su larga scala, è anche importante
considerare da subito quale paradigma di progettazione utilizzare. Preferire un
paradigma piuttosto che un altro, è assolutamente indipendente dal linguaggio
utilizzato e dalla architettura su cui l'applicazione sarà eseguita, mentre può
influenzare notevolmente le prestazioni finali o provocare conseguenze non
irrilevanti in termini di affidabilità.
Page 75
67
I sistemi che usano la mobilità consentono ai componenti di modificare
dinamicamente la loro posizione tra le macchine della rete: i concetti
fondamentali quindi diventano la locazione e la distribuzione delle risorse nel
sistema; per esempio, l'interazione tra due componenti che risiedono su host
remoti è molto più .onerosa del caso in cui la stessa interazione avvenga
localmente.
Si fornisce di seguito, una classificazione concettuale dei paradigmi di
progettazione basati sulla mobilità del codice, secondo i criteri descritti in
[CPV97]: una particolare attenzione deve essere rivolta alla locazione delle
risorse, ai componenti responsabili dell'esecuzione del codice e a dove realmente
il codice viene eseguito.
������ 5HPRWH�(YDOXDWLRQ
Nel modello client-server, il cliente può richiedere un servizio, solo se
appartenente a quelli messi a disposizione dal server. Infatti non è possibile
eseguire un codice arbitrario, poiché ad ogni servizio è associato un programma
prestabilito, con cui non si può interagire.
Il paradigma Remote Evaluation permette ad un programma di sfruttare
una entità remota, fornendo il codice da eseguire al sito in cui essa risiede. Così
si rende più flessibile l'utilizzo delle risorse, lasciando al programma la scelta di
come sfruttarle, attraverso una esecuzione più veloce, perché svolta localmente,
ed eventualmente bloccandosi in attesa di un risultato.
Se si presenta la necessità di creare un nuovo servizio, o di modificarne
uno esistente, non si deve riorganizzare il servitore (cioè la macchina in cui
risiede la risorsa), impedendo ad altri clienti di sfruttare le sue funzionalità
durante la fase di riorganizzazione, ma e sufficiente realizzare un frammento di
codice che soddisfi le nuove specifiche.
Il paradigma Remote Evaluation permette di realizzare un VHUYLWRUH
HODVWLFR�� cioè aperto e disponibile ad eseguire ogni tipo di codice,� GLQDPLFR�
poiché interagisce con le sue risorse in funzione dei cambiamenti e delle nuove
esigenze dei clienti che gli si rivolgono, ed anche JOREDOH��perché può eseguire
tutti i programmi presenti nel sistema.
Page 76
Un semplice esempio di questo modello è la richiesta di stampa di un file
postscript su una periferica remota: il documento in questione rappresenta il
codice da eseguire, sempre diverso ad ogni richiesta.
������ &RGH�RQ�GHPDQG
Anche questo paradigma ha come obiettivo lo svolgimento di un servizio,
sfruttando la mobilità del codice, ma a differenza di prima, l'esecuzione avviene
all'interno della macchina che fa la richiesta.
La situazione iniziale è duale rispetto alla precedente: le risorse necessarie
sono già presenti localmente, e manca la conoscenza di come sfruttarle. L'host
remoto spedisce il codice in conseguenza di una esplicita richiesta che è eseguito
localmente sulla macchina richiedente. Così, le entità in esecuzione si rendono
dinamicamente estensibili, poiché possono ampliare la loro capacità di
esecuzione, avvalendosi di qualunque codice disponibile sulla rete. Anche in
questo caso, si realizza un HQWLWj GLQDPLFD� IOHVVLELOH� H� JOREDOH�� che esegue i
programmi dinamicamente disponibili nell'intero sistema.
Un'applicazione molto diffusa che sfrutta questo paradigma, è utilizzata
ogni volta che un utente richiede al proprio browser di visualizzare una pagina
web in cui è inserita una applet: il server riceve la richiesta e spedisce, alla
macchina dell'utente, il codice Java necessario da applicare alle risorse locali per
visualizzare gli effetti dell'applet.
������ $JHQWL�PRELOL
Gli agenti mobili sono unità di esecuzione (EU) che agiscono in nome di
un utente e che sono in grado di muoversi in modo autonomo all'interno di una
rete.
Questo paradigma è molto differente dai precedenti: in Remote Evaluation
e Code on Demand l'attenzione è rivolta allo spostamento di codice tra
componenti in esecuzione; ora invece è il componente stesso che si sposta,
trasportando anche i suoi dati, il suo codice e il suo stato di esecuzione.
Questo paradigma, che sarà affrontato in modo più approfondito nel
prossimo paragrafo, riduce al minimo lo scambio di messaggi sulla rete, per
Page 77
69
evitare eventuali congestioni, e si avvantaggia della velocità delle esecuzioni
locali.
���� $JHQWL�0RELOL
Possiamo definire un DJHQWH� come una unità di esecuzione (EU che
comprende oltre al codice, lo stato di esecuzione e lo spazio dei dati) che agisce
autonomamente per conto di una persona o di una organizzazione [CHK95]. Il
termine "agente" deriva proprio dalla capacità di agire in nome dell'utente, per
raggiungere l'obiettivo finale, scegliendo in modo autonomo quali operazioni
intraprendere. Ogni agente ha il proprio flusso di esecuzione, in modo da
eseguire su propria iniziativa i compiti assegnatigli.
Un agente è� VWD]LRQDULR se agisce esclusivamente sul nodo su cui ha
iniziato la sua esecuzione; un agente, invece, è PRELOH� se ha l'abilità di
trasportare se stesso all'interno di una rete da una macchina ad un'altra, senza
essere vincolato a quella in cui ha iniziato la sua esecuzione; si sposta nel sistema
in cui si trova l'oggetto con cui vuole interagire, per trarre il beneficio di eseguire
operazioni locali [KT98].
In realtà, nel campo della "Intelligenza Artificiale" si definisce anche un
altro tipo di agenti, gli agenti intelligenti, che sono caratterizzati dalla capacità di
inferire nuova conoscenza durante il loro tempo di vita. Gli agenti intelligenti
sono tipicamente agenti stazionari, perché, a causa della loro natura, rischiano di
avere dimensioni elevate; gli agenti mobili, invece, essendo trasferiti
frequentemente devono essere snelli ("light weight"), per evitare di subire
spostamenti lenti, che congestionano la rete. Spesso i termini agenti mobili e
agenti intelligenti sono usati come sinonimi e ci si riferisce ad essi in generale col
termine agenti.
Le caratteristiche computazionali più importanti degli agenti possono
essere riassunte in questi termini:
• $XWRQRPL: ogni agente ha la capacità di scegliere, in funzione delle sue
informazioni, cosa fare, dove andare e quando spostarsi.
• $VLQFURQL: tutti gli agenti hanno un proprio flusso di esecuzione che possono
eseguire in modo asincrono.
Page 78
• ,QWHUD]LRQL�ORFDOL: i loro spostamenti sono finalizzati ad eseguire interazioni
locali, per ridurre il costo, da effettuare con altri agenti mobili o in generale
con oggetti stazionari che risiedono localmente.
• (IILFLHQWL: l’uso degli agenti consente di ridurre il traffico di rete, soprattutto
nel realizzare interazioni remote complicate.
• ,QGLSHQGHQWL�GDOOD�UHWH: gli agenti possono eseguire i loro compiti anche se
la connessione di rete è al momento disattiva, interagendo con le risorse
locali. Qualora sia necessario uno spostamento, si attende che il
collegamento con la macchina remota si ripristini.
• (VHFX]LRQH�SDUDOOHOD: la distribuzione degli agenti su più macchine permette
di eseguire in parallelo i compiti intermedi che conducono al risultato finale,
riducendo i tempi di attesa.
• 2EMHFW�SDVVLQJ: la tecnologia più comoda per realizzare un agente mobile è
quella object-oriented, in modo che quando deve essere spostato, si trasferisce
l'intero oggetto, che comprende i dati, il codice e lo stato di esecuzione
dell'agente.
Queste caratteristiche permettono di ottimizzare ed ampliare i servizi
disponibili sulla rete, riducendone il traffico e quindi il rischio di congestione.
Per avere una visione più completa delle proprietà generali di un agente
mobile, analizzeremo le sue prerogative più interessanti, rappresentate dalla
capacità di migrare su macchine remote, dalla possibilità di comunicare con altri
agenti e dalle garanzie di sicurezza che deve fornire e che deve ricevere
dall'ambiente di esecuzione.
������0LJUD]LRQH
La caratteristica degli agenti mobili è di agire in modo autonomo, avendo
conoscenza degli interessi dell'utente e cercando di soddisfarli, attraverso lo
spostamento tra le macchine della rete. La migrazione è la conseguenza
dell'invocazione di un'istruzione, che provoca il trasferimento del codice
dell'agente e del suo stato di esecuzione.
Page 79
71
L’attuazione del comando di spostamento si sviluppa seguendo queste fasi:
1) tutti i processi attivi dell’agente sono sospesi e insieme allo stato dell’agente
(cioè i dati, il codice e lo stato di esecuzione) sono elaborati per essere
incapsulati in un messaggio, espresso in una forma indipendente dalla
macchina;
2) il messaggio così creato, può essere indirizzato esplicitamente al destinatario
finale, o ad un nodo intermedio con funzioni di routing;
3) quando arriva nel sistema di destinazione, il messaggio deve raggiungere
l'ambiente di esecuzione a cui era destinato tra quelli presenti, e poi qui
l'agente viene ricomposto;
4) attraverso il suo stato di esecuzione e il valore dei suoi attributi, l'agente può
riprendere la sua esecuzione dall'istruzione successiva a quella della
migrazione.
Dopo la migrazione, l'agente può interagire con le funzioni applicative del
nuovo ambiente (servitore) e procedendo nella sua esecuzione potrebbe
intraprendere ancora una operazione di migrazione in modo analogo a quanto
appena descritto.
Quando si dice che raggiunto l'ambiente di destinazione l'esecuzione
dell'agente riprende dall'istruzione successiva a quella della migrazione, si
intende semplicemente che il flusso di esecuzione si riattiva in accordo con lo
stato e gli attributi che lo caratterizzano. E quindi una affermazione del tutto
generica che dovrebbe essere approfondita in considerazione del caso specifico
che il linguaggio considerato supporti un tipo di mobilità forte o debole.
Nel caso in cui la ripresa del flusso di esecuzione coincida esattamente
con l'istruzione successiva a quella dello spostamento, significa che la mobilità
supportata è di tipo forte. Se invece la ripresa necessita di una fase di preambolo,
che richiede la partenza da un punto prestabilito per consentire di ripristinare la
consistenza, allora il tipo di mobilità supportata è debole.
������ &RPXQLFD]LRQH�WUD�DJHQWL
In un sistema ad agenti, è necessario definire il modo in cui gli agenti
possono interagire tra loro per raggiungere il loro obiettivo. Gli stili di
Page 80
comunicazione possono essere suddivisi in due categorie, in funzione del tipo di
interazione, stretta o lasca, che offrono:
♦ ,QWHUD]LRQH�VWUHWWD�� la comunicazione che si basa su una interazione stretta
tra due agenti, richiede una loro conoscenza esplicita. Si ottiene attraverso la
condivisione di oggetto o attraverso a diretta invocazione dì un metodo
remoto (per esempio, in 5HPRWH� 0HWKRG� ,QYRFDWLRQ�� 50, [RMI98], il
chiamante deve conoscere staticamente l'interfaccia del metodo remoto da
invocare [Java]). Questa è una comunicazione di alto livello e richiede una
conoscenza specifica degli oggetti o degli agenti remoti con cui interagire: per
inserire dinamicità, deve essere presente nel sistema un protocollo di
acquisizione di informazioni remote, che si mantenga aggiornato sulle ultime
modifiche e su eventuali spostamento, senza ricadere nella visione classica
dei sistemi distribuiti in cui si offre uno strato di trasparenza alla locazione.
La realizzazione di interazioni strette è abbastanza costosa ed è quindi da
utilizzare solo in casi realmente necessari.
♦ ,QWHUD]LRQH�ODVFD��la comunicazione che si basa su una interazione lasca, non
necessita di una conoscenza rigida tra gli agenti interessati. Un primo
meccanismo per realizzare una interazione lasca è lo VFDPELR�GL�PHVVDJJL, è
necessaria ancora una forma di conoscenza tra i due interlocutori, ma è meno
rigida, e può dipendere per esempio dal fatto di essere nati nello stesso
ambiente di esecuzione o di discendere dalla stessa famiglia.
Un altro metodo per realizzare interazione lasca, è costituito dalla
FRPXQLFD]LRQH�DQRQLPD��quando due agenti devono comunicare, ma non hanno
alcuna conoscenza reciproca, né hanno caratteristiche tali da potersi scambiare
messaggi, si può realizzare un supporto che permetta di conoscere facilmente il
nome di altri agenti, oppure è possibile realizzare astrazioni come la
"Blackboard" oppure uno "spazio delle tuple" [CG89].
������ 6LFXUH]]D
Il problema della sicurezza è molto importante in un sistema ad agenti
mobili, poiché questi si pongono l’obiettivo di spaziare su reti molto vaste, in cui
le risorse non sono direttamente amministrabili e controllabili.
Page 81
73
I rischi esistono sia dal punto di vista dei nodi del sistema, che devono
essere protetti dagli attacchi di agenti non fidati, sia per quanto riguarda gli
agenti, che devono proteggere le informazioni sensibili trasportate dall’attacco di
ambienti ostili.
��������5LVHUYDWH]]D�HG�LQWHJULWj
Gli agenti possono trasportare dati sensibili, che non devono essere
mostrati se non al corretto destinatario (si pensi ad esempio al numero di carta di
credito in un’applicazione di commercio elettronico). E’ dunque necessario che
lo stato dell’agente sia nascosto mediante tecniche crittografiche, almeno durante
il trasporto. E’ anche possibile che l’agente debba concedere la visione di parti
diverse dello stato a server diversi: deve dunque essere possibile nascondere
porzioni di stato.
Un altro problema consiste nel mantenere l’integrità dell’agente, cioè
nell’assicurare che nessuno possa modificare l’agente (il codice e/o lo stato)
durante il tragitto. In realtà questo è impossibile, ma ciò che si può fare è
individuare un’avvenuta modifica tramite l’uso di message digest.
��������$XWHQWLFD]LRQH
Quando un agente si sposta su una nuova macchina, questa deve effettuare
l'autenticazione dell'utente, che è il mittente dell'agente, e viceversa l'agente deve
autenticare l'ambiente di esecuzione in cui si inserisce. Si parla di PXWXD
DXWHQWLFD]LRQH.
��������$XWRUL]]D]LRQH�H�FRQWUROOR�GHJOL�DFFHVVL
Una volta che è avvenuta la mutua autenticazione è necessario garantire
che ad ogni agente siano concessi solo i diritti di accesso alle risorse stabiliti da
una precisa politica di autorizzazione.
Perché ciò avvenga è necessario associare ad ogni agente i permessi
adeguati (utilizzando meccanismi quali le Access Control List, le Capabilities o
le Sealed Labels) e assicurare che l’ambiente esegua un corretto controllo sugli
accessi.
Un problema più difficile da risolvere è quello opposto: garantire che il
sistema interagisca con l’agente secondo una politica stabilita. Una soluzione a
Page 82
questo problema può derivare solo da un supporto hardware ad hoc. Uno di
questi sistemi è descritto in [WSB98].
���� -DYD�XQ�OLQJXDJJLR�DGDWWR�SHU�L�VLVWHPL�DG�DJHQWL
Java è un linguaggio object-oriented, progettato con lo scopo di fornire un
prodotto di piccole dimensioni, semplice, facile da imparare, portabile su diverse
piattaforme e adatto ad ogni dominio applicativo (general-purpose).
Java è un linguaggio, sintatticamente simile al C++, da cui derivano infatti
parte della sintassi e della struttura ad oggetti, ma nonostante la somiglianza, le
parti più complesse del linguaggio C++ sono state escluse, in modo da mantenere
la semplicità, senza sacrificare le potenzialità. Infatti in Java, a differenza del
C++, non è consentito l'uso dei puntatori a livello utente, ed è presente una
gestione automatica della memoria: in C++ è compito del programmatore
deallocare lo spazio di memoria nel momento in cui si elimina un puntatore,
mentre in Java questo avviene automaticamente, attraverso l'introduzione di uno
strumento detto �JDUEDJH�FROOHFWRU��che periodicamente libera dalla memoria gli
elementi non referenziati.
Nella programmazione ad oggetti, il meccanismo GHOOHUHGLWDULHWj
consente di specificare nella definizione di una classe solo le differenze rispetto
ad un'altra già esistente, considerando "ereditate" tutte le caratteristiche non
espressamente citate. Legato a questo aspetto, nel C++ esiste un meccanismo
non semplice da gestire, che è l'eredità multipla, cioè la possibilità per una classe
di ereditare le caratteristiche da più di una classe già esistente. Per semplificarne
la gestione, in Java questo strumento è disponibile solo per le LQWHUIDFFH� che
rappresentano le funzionalità disponibili in una classe senza la descrizione di
come siano realizzate.
Limitiamo a questi pochi esempi le differenze a livello di programmazione
tra Java e C++ (un confronto esaustivo è disponibile in [Nie98]) e soffermiamoci
invece sulla caratteristica che rende -DYD�XQ� OLQJXDJJLR�SDUWLFRODUPHQWH�DGDWWR
SHU�OD�UHDOL]]D]LRQH�GL�DSSOLFD]LRQL�GLVWULEXLWH��DYHQGR�OD�SRVVLELOLWj��VXSHUDUH
OHWHURJHQHLWj�LQWULQVHFD�GHL�VLVWHPL�DSHUWL. La realizzazione di una applicazione
in C++, o in qualunque altre linguaggio, prevede la fase di scrittura del codice e
Page 83
75
di compilazione: il compilatore traduce il programma in un linguaggio
comprensibile alla macchina su cui si lavora (e a tutte quelle compatibili), ma per
eseguirlo su una architettura diversa si deve compilare nuovamente il codice
sorgente con un compilatore diverso dal precedente e adatto al nuovo sistema.
In Java, invece, il codice sviluppato dal programmatore passa attraverso
due componenti: un compilatore e un interprete. Il compilatore Java trasforma il
codice sorgente (invece che in linguaggio macchina) in una forma intermedia e
indipendente dalla piattaforma, il cosiddetto E\WH�FRGH��per riuscire ad eseguire il
programma, realizzato dall’utente, il byte code deve essere interpretato da una
macchina virtuale stack-based, detta -DYD 9LUWXDO� 0DFKLQH (JVM).
L’introduzione dell’innovativo codice intermedio indipendente dalla piattaforma,
permette a Java di essere un linguaggio altamente portabile, destinato ad essere
utilizzato con successo in tutti i sistemi con architetture eterogenee, che sono
l’ambiente di sviluppo naturale per le applicazioni ad agenti mobili.
Un fattore chiave del successo di Java è la totale LQWHJUD]LRQH FRQ� OD
WHFQRORJLD� :::: i browser web includono nelle loro estensioni la JVM e
questo permette sia di realizzare con estrema facilità pagine interattive, animate
con effetti speciali, da parte di programmatori principianti, sia progetti complessi
per utenti più esperti. Così il linguaggio Java è entrato nel mondo informatico,
sia a livello professionistico che dilettantistico, affermandosi come leader in tutte
le applicazioni distribuite.
Vediamo in dettaglio le caratteristiche che offre questo linguaggio e
verifichiamo se sono adatte per la realizzazione di un sistema ad agenti mobili.
Un primo vantaggio dell'utilizzo del byte code è OHOHYDWD SRUWDELOLWj�di
Java, come di ogni altro linguaggio interpretato, che può eseguire in tutte le
piattaforme per cui esista una JVM. Data la popolarità che ha acquistato in
questi anni, si può dire che praticamente tutti i tipi di macchina forniscano un
interprete Java, rendendo veritiero lo slogan che Sun usa a proposito di Java:
"write once, run anywhere". L'ambiente di esecuzione del paradigma ad agenti
mobili è un sistema distribuito in cui convivono diversi tipi di macchine: usare
Java come strumento di programmazione offre il beneficio di poter far migrare
gli agenti in tutti i siti remoti in cui sia presente una JVM, e questo implica una
elevata portabilità. E giusto sottolineare che i linguaggi interpretati offrono,
Page 84
come svantaggio, una diminuzione delle prestazioni, rispetto ai linguaggi
compilati; per ottenere le stesse prestazioni, Java mette a disposizione un
compilatore di byte code, detto JIT (Just In Time), per sfruttare il linguaggio
macchina nativo.
Il secondo vantaggio deriva dalla possibilità di svolgere un SURFHVVR� GL
YHULILFD�sul codice prima dell'esecuzione, con il quale si eliminano le operazioni
che potrebbero scatenare un overflow dello stack, e si controlla che i metodi
degli oggetti referenziati siano invocati con il corretto numero e tipo di
argomenti. Questa verifica è agevolata dal fatto che in Java non è prevista
l'esistenza di tipi di dato, come i puntatori, che possono condurre all'accesso
indiretto di aree non consentite.
Se durante l'esecuzione di un programma, si presenta un riferimento al
nome non risolto di una classe, la JVM invoca a runtime il FODVV�ORDGHU��che è un
meccanismo di programmazione che ricerca e carica dinamicamente �G\QDPLF
OLQN�� le classi necessarie. Il class loader prima controlla che il frammento di
codice non sia una classe di sistema, poi verifica che non sia già in memoria,
altrimenti cerca di recuperarla da quale sito remoto; a questo punto il codice
scaricato comincia la sua esecuzione. L'aspetto interessante è che Java fornisce
al programmatore la possibilità di implementare un proprio class loader,
ereditando le caratteristiche fondamentali da quello di sistema; con questo
strumento possiamo caricare il codice di un agente da una qualunque macchina
della rete.
Una caratteristica relativamente nuova in Java (perché introdotta solo con
il jdk 1.1) è la possibilità di VHULDOL]]DUH�gli oggetti; questo permette a qualunque
oggetto di essere trasformato in modo reversibile in una rappresentazione adatta
per la memorizzazione su disco o per la trasmissione in rete. Con questo
meccanismo è possibile trasferire ad una macchina remota un Thread o un
qualunque oggetto creato dal programmatore; l'unica e semplice condizione è che
implementi l'interfaccia Serializable, cosa che tutte le classi possono fare. Nel
paradigma ad agenti, la serializzazione è sfruttata per trasmettere lo stato
dell'agente nel momento in cui vuole spostarsi.
Anche la gestione del QHWZRUNLQJ� q� affrontata in Java, offrendo al
programmatore un'interfaccia semplice e chiara, che facilita le operazioni su un
Page 85
77
canale di comunicazione con macchine remote (per esempio, il pacchetto di
gestione delle VRFNHW�� q�più intuitivo rispetto ad altri linguaggi, come il C++).
Quando si progetta un sistema che implementa un paradigma basato sulla
mobilità, la gestione dei collegamenti di rete riveste un ruolo molto importante
per lo spostamento del codice.
Il vantaggio della programmazione distribuita è la possibilità di sfruttare
l'esecuzione concorrente e Java offre a questo riguardo caratteristiche di
VLQFURQL]]D]LRQH�a livello di linguaggio, cioè è possibile scrivere sezioni critiche
in modo pulito ed elegante, con istruzioni specifiche: la clausola �V\QFKURQL]HG�
permette di gestire la sincronizzazione tra thread o risorse, ricordando però che è
sempre compito del programmatore utilizzare in modo opportuno questo
strumento.
Un punto debole di molti linguaggi è il livello di VLFXUH]]D�che offrono;
Java nella jdk 1.2 ha introdotto un nuovo modello di sicurezza [Gong98],
ampliando quello assai limitato costituito dalla sand box presentata nella versione
iniziale del jdk 1.0, e già migliorato da una più efficiente granularità nella jdk 1.1
[Gong97]. In un sistema ad agenti mobili si devono prevedere meccanismi per
proteggere sia gli host che gli agenti in arrivo su nuovi ambienti.
Esiste anche un principale limite nell'utilizzo di Java per gli agenti mobili:
per ragioni di sicurezza non è possibile accedere allo stack di esecuzione di un
programmi, e quindi non è possibile ripristinarlo, per esempio, in seguito ad una
serializzazione. Questo significa che quando un agente decide di spostarsi, non è
possibile interrompere la sua esecuzione per farla riprendere dallo stesso punto
sulla macchina remota: dalle definizioni viste in precedenza, possiamo affermare
che Java non supporta la mobilità forte.
Se non si vuole comunque rinunciare alla "strong mobility", si deve
accedere allo stato interno della JVM, realizzando una di queste due soluzioni.
♦ &KHFNSRLQWLQJ� Si deve monitorare completamente l'esecuzione del codice,
per collezionare i dati necessari alla migrazione, dati che, quando l'agente si
sposta, si spediscono alla macchina remota. Nel sito remoto, durante la fase
di ripristino delle informazioni si devono sfruttare i FKHFNSRLQW� (inseriti dal
sistema su cui l'agente eseguiva precedentemente) che segnalano dei punti
stabili del codice da cui è possibile riprendere l'esecuzione. Per sfruttare
Page 86
questa tecnica, è necessario realizzare un post-compilatore in grado di inserire
all'interno del byte code gli accorgimenti necessari per coordinare le due
macchine.
♦ 0RGLILFD�GHOOD�PDFFKLQD�YLUWXDOH���All'interno della macchina virtuale sono
già presenti tutti i dati relativi allo stato di esecuzione degli agenti, che
possono essere estratti con qualche modifica della stessa JVM. Ma questi
cambiamenti comportano, come grave conseguenza, la perdita della
portabilità.
Per non rinunciare comunque al vantaggio della portabilità che offre
questo linguaggio, è possibile implementare una mobilità debole: nel nuovo
ambiente gli agenti riprenderanno la loro esecuzione a partire da un punto
stabilito a priori.
Dopo un bilancio totale delle caratteristiche positive e negative che Java
offre allo sviluppo di sistemi ad agenti mobili, concludiamo affermando che, a
nostro parere, si tratta di un linguaggio molto adatto con cui sviluppare
applicazioni distribuite, realizzate con un qualunque paradigma di mobilità del
codice.
�������6LVWHPL�HVLVWHQWL�DG�DJHQWL�PRELOL
La recente popolarità del codice mobile, ha portato alla nascita di un
numero elevato di sistemi ad agenti. Viene fornito di seguito un breve excursus
su alcuni dei sistemi più diffusi. In questa presentazione, in particolare, si è
cercato di sottolineare le caratteristiche di mobilità attribuite agli agenti e di
estrarre le proprietà peculiari più significative di ogni sistema.
������� 7HOHVFULSW
Telescript [Teles94], sviluppato dalla General Magic, è stato il primo
sistema commerciale ad agenti mobili e quindi lo citiamo per l'importanza storica
che riveste.
Telescript è realizzato con un linguaggio proprietario, chiamato /RZ
7HOHVFULSW��object-oriented e simile a Java e al C++. In ogni macchina della rete
Page 87
79
sono implementati uno o più ambienti di esecuzione virtuali, detti SODFH. Gli
agenti si spostano tra le macchine del sistema attraverso il metodo JR,
riprendendo la loro esecuzione dal punto in cui avevano terminato nel nodo
precedente: la mobilità supportata è di tipo forte. L'interazione avviene in due
modi distinti: il comando PHHW�permette agli agenti di invocare metodi di altri
agenti che risiedano sullo stesso place, mentre il comando FRQQHFW�consente il
collegamento remoto tra agenti, per lo scambio di oggetti.
Questo sistema è stato considerato da subito un buon prodotto, anche per i
meccanismi di sicurezza che fornisce. Quando un agente si sposta, presenta al
place di destinazione delle informazioni, dette FUHGHQ]LDOL��che sono necessarie al
nuovo ambiente di esecuzione, per autenticare l'identità dell'utente creatore e in
funzione delle quali il sistema assegna all'agente stesso un adeguato grado di
fiducia; durante la migrazione, le credenziali sono protette da eventuali
manipolazioni esterne con l'uso di tecniche crittografiche. In più ad ogni agente
sono assegnati dei permessi che autorizzano all'uso delle risorse disponibili:
questi permessi sono concessi dai place, che in tal modo si proteggono da
eventuali comportamenti maligni.
Telescript offre anche un buon sistema di tolleranza ai guasti: in ogni
macchina è presente un server che con continuità memorizza su un supporto non
volatile lo stato di esecuzione di tutti gli agenti locali, così che diventi semplice il
ripristino dello stato consistente in caso di caduta del nodo.
Nonostante Telescript sia un prodotto con una buona tolleranza ai guasti,
sicuro ed efficiente, la General Magic ha subìto una battuta d'arresto sul mercato
a causa della rapida e sempre crescente attenzione dedicata a Java dal mondo
informatico e a causa della mancanza di apertura del sistema, basato su un
linguaggio proprietario.
������� 2GLVVH\
Odissey [Odi98] è il sistema che la General Magic ha sviluppato per
sostituire Telescript: in generale offre le stesse caratteristiche, a parte il fatto che
il linguaggio utilizzato è Java. Questo cambiamento influisce anche sul tipo di
mobilità sopportato; come si è già notato, Java non fornisce le caratteristiche
necessarie per catturare lo stato completo di un programma in esecuzione,
Page 88
fornendo, di default, una mobilità di tipo debole. Per mantenere la compatibilità
con tutte le JVM, l'istruzione go non può più presentare le stesse caratteristiche
offerte in Telescript. La General Magic ha imposto che gli agenti Odissey
possano scegliere solo tra queste due alternative: la prima semplicemente
consente di ricominciare da capo l'esecuzione dopo lo spostamento su un nodo
remoto, mentre la seconda permette di creare, prima di iniziare a navigare per la
rete, una lista di compiti da svolgere sulle determinate macchine che si intende
visitare, lista che può essere anche modificata dinamicamente.
Odissey non è un prodotto commerciale, a differenza di Telescript, ed è
usato dalla General Magic per svolgere la realizzazione di servizi ed applicazioni
interni alla società.
������� $JOHWV
Aglets è il sistema realizzato da Ibm, che oggi sembra riscuotere il
maggiore interesse tra quelli disponibili sul mercato [IBM96]. Il termine $JOHWV
deriva dalla fusione di DJHQW�H�DSSOHW��per il fatto che le API riprendono concetti
e terminologia propri delle applet [LC96].
L'ambiente di esecuzione degli agenti, il FRQWH[W�� è indipendente dal
sistema su cui si lavora e per trasferire gli agenti sulla rete si utilizza O$JHQW
7UDQVIHU� 3URWRFRO� (ATP) [LA97]. Questo protocollo è stato progettato per un
uso su Intemet, è uniforme e indipendente dalla piattaforma e permette quindi di
trasferire agenti tra qualunque tipo di macchina. L'ATP cerca di porsi come
punto di connessione tra i tanti sistemi presenti, ciascuno con le proprie scelte
implementative e con i propri linguaggi di programmazione: un passo importante
per raggiungere un primo livello di standardizzazione nel campo della mobilità.
Il sistema di Ibm è totalmente scritto in Java e supporta solo una mobilità
di tipo debole: dopo ogni spostamento l'agente deve ricominciare l'esecuzione da
un punto prestabilito, pur mantenendo i valori delle interazioni avvenute in
precedenza.
Il trasferimento degli Aglet può avvenire secondo due modalità differenti
[MKO98]. La primitiva GLVSDWFK� sposta un frammento di codice o
un'applicazione stand-alone sulla macchina il cui nome è fornito come
argomento, in modo asincrono e immediato. Al contrario, la primitiva UHWUDFW
Page 89
81
impone all’agente di ritornare nel contesto di origine, in cui ha iniziato la sua
esecuzione.
������� 9R\DJHU
Voyager è il tool di sviluppo proposto da ObjectSpace [OBJ97], realizzato
in Java, con mobilità debole, e compatibile con lo standard proposto da Corba
[CORBA].
Voyager permette dì costruire oggetti remoti, di spedire loro messaggi e di
spostarli tra le applicazioni secondo necessità. Un agente è visto come un
particolare tipo di oggetto e quindi, sfruttando la sintassi standard di Java, è
possibile creare agenti remoti. Un'altra novità introdotta da Voyager è un
servizio di nomi integrato, che associa ad ogni oggetto (e quindi in particolare
anche agli agenti) un alias, con il quale in seguito è possibile referenziare
dinamicamente l'oggetto stesso anche se è stato mosso (l'associazione infatti non
si riferisce all'indirizzo della macchina in cui risiede l'elemento considerato).
Un agente per spostarsi si auto-spedisce il messaggio PRYH7R indicando la
meta del trasferimento e il metodo da eseguire una volta arrivato. La
destinazione può essere una locazione oppure un oggetto; questo gli permette di
raggiungere la risorsa con cui interagire, anche quando questa si muove. Il
tempo di vita degli agenti Voyager può essere determinato dall'utente, dando la
preferenza ad una delle cinque possibilità disponibili: un agente può vivere
finché ha riferimenti attivi (locali o remoti), per una certa quantità di tempo, fino
ad un particolare istante, finché non rimane inattivo per un tempo prestabilito
oppure per sempre. Di default, gli agenti Voyager vivono per un giorno.
Page 91
83
&DSLWROR����620$�81�6,67(0$�$'�$*(17,
02%,/,
���� ,QWURGX]LRQH
Il sistema SOMA (Secure and Open Mobile Agent) è un ambiente di
sviluppo per applicazioni ad agenti mobili, realizzato presso il dipartimento di
elettronica, informatica e sistemistica (DEIS) dell'Università di Bologna;
progettato nell’ambito del "Project Design Methodologies and Tools of High
Performance Systems for Distributed Applications" fondato dal Ministero
dell’Università e della Ricerca Scientifica e Tecnologica (MURST). Al sistema è
dedicato un sito web [SOMA], costantemente aggiornato da parte dei
responsabili del progetto, in cui è possibile reperire tutte le informazioni più
recenti, insieme al codice, che è distribuito liberamente.
SOMA è stato sviluppato materialmente da studenti della Facoltà di
Ingegneria dell’Università di Bologna nell’ambito delle loro Tesi di Laurea, che
descrivono accuratamente l’evoluzione del progetto nelle sue fasi successive
[Tar98] [Ten98] [Chi98] [Coc98] [Cav98] [Pro98].
Il sistema è realizzato interamente tramite il linguaggio Java e sfrutta
dunque le caratteristiche che rendono questo linguaggio adatto per la
realizzazione di applicazioni ad agenti mobili.
L'architettura su cui lavorano gli agenti SOMA, presenta tutte le
caratteristiche di un sistema ad agenti descritte nel capitolo precedente. In
particolare le proprietà principali dell’ambiente sono:
♦ VLFXUH]]D: è realizzata la protezione sia dal lato degli agenti che da quello
degli ambienti in cui eseguono. L'accesso al sistema è protetto da password,
così che solo utenti autorizzati possono creare agenti SOMA in grado di
viaggiare nel sistema;
Page 92
♦ DSHUWXUD: il sistema aderisce alla standardizzazione proposta da OMG, cioè è
prevista l'interazione di agenti SOMA con applicazioni CORBA-compliant e
con gli agenti degli altri sistemi che aderiscono allo stesso standard;
♦ GLQDPLFLWj: esistono strumenti per la gestione delle modifiche dinamiche della
configurazione e dell'inserimento dinamico di nuovi utenti;
♦ SRUWDELOWj: attraverso l’uso del linguaggio Java, l’ambiente può essere
utilizzato su un vasto numero di piattaforme eterogenee;
♦ VFDODELOLWj: è disponibile a vari livelli, dalla configurazione del sistema, la cui
topologia può essere estesa a piacimento, alla gestione degli utenti e al
numero di agenti in esecuzione, assolutamente non limitati;
♦ SUHVWD]LRQL: l’uso degli agenti mobili consente di migliorare le performance di
una applicazione, rispetto al tradizionale paradigma cliente-servitore; la
gestione della sicurezza è configurabile in maniera flessibilità permettendo di
raggiungere il compromesso prestazioni/sicurezza desisderato;
♦ IDXOW� WROHUDQFH: i nodi del sistema possono non essere tutti attivi in un
determinato momento, il sistema gestisce la possibilità di avere nodi attivi e
non attivi sistema;
♦ WRRO� JUDILFL: tutte le operazioni utente (es., l'attivazione di un agente) sono
accompagnate da una interfaccia grafica chiara ed intuitiva.
���� $UFKLWHWWXUD�JHQHUDOH�GHO�VLVWHPD
L’architettura di SOMA nasce dall’imitazione della struttura di un sistema
complesso come Internet. E' caratterizzato da una serie di località organizzate in
gerarchia, ognuna con le proprie caratteristiche, dal punto di vista
dell’amministrazione, della gestione e della sicurezza. Le varie località sono
connesse tra loro in maniera dinamica, con una topologia variabile nel tempo.
SOMA cerca di modellare una simile struttura, introducendo diverse
astrazioni di località, che descrivono le tipiche località di Internet e forniscono
nel contempo un ambiente in cui sia possibile sviluppare applicazioni secondo il
modello degli agenti mobili.
Page 93
85
Le astrazioni di località introdotte sono:
• 3ODFH�� rappresenta l’ambiente di esecuzione degli agenti (il CE), come
astrazione del concetto di nodo. Al suo interno gli agenti possono interagire
con le risorse locali e cooperare con altri agenti residenti sul place. Ogni place
è caratterizzato da un nome (classe 3ODFH1DPH). Ogni nodo può contenere
più place, mentre ogni place deve essere confinato all’interno di un nodo.
• 'RPLQLR� rappresenta un’aggregazione di place, come astrazione del concetto
di rete locale, che presentano caratteristiche comuni di tipo fisico
(appartenenza alla medesima LAN) o logico (amministrazione e politiche
comuni). Ogni dominio è caratterizzato da un nome (classe 'RPDLQ1DPH).
I place di un dominio sono strettamente correlati tra loro, si conoscono a
vicenda e sono in grado di comunicare direttamente. Le interazioni che
coinvolgono due diversi domini sono invece mediate da un particolare place,
detto “*DWHZD\” o “'HIDXOW�3ODFH”. I Gateway hanno conoscenza uno dell’altro e
sono in grado di comunicare direttamente. Il Gateway rappresenta dunque l’unico
punto di accesso verso l’esterno di un dominio; può essere visto come
un’astrazione dei Gateway (eventualmente con funzioni di Firewall) che
collegano le diverse reti locali in ambiente Internet.
���� $JHQWL�0RELOL
Un agente mobile in SOMA è implementato come istanza di una classe
derivata dalla classe astratta di base “Agent.java”, che definisce le proprietà e le
caratteristiche comuni di tutti gli agenti.
Ogni agente ha un identificatore unico ($JHQW,') nel sistema composto
dai nomi del Dominio e del Place dove è stato creato e da un numero progressivo
unico locale al place. Possiede una Mailbox, per gestire lo scambio di messaggi,
un set di preferenze e un set di credenziali; il campo “Traceable” che indica se
l'agente è rintracciabile o meno, ossia se è possibile spedirgli dei messaggi.
All'agente ha dei metodi pubblici per gestire la fase di avvio, per la migrazione
intra ed inter dominio, per ottenere l'identificatore, per aggiungere preferenze e
per richiedere credenziali ad un place.
Page 94
L’agente è un oggetto passivo, su ogni place è gestito da un thread, detto
":RUNHU", che ha il compito di associare all'agente un flusso di esecuzione. Ciò è
indispensabile perché la JVM non permette la migrazione di un'EU (un thread),
ma solo di oggetti passivi, implementando esclusivamente la mobilità debole.
Quando un agente nasce viene subito affidato ad un Worker che fa partire
la sua esecuzione dal metodo specificato nel campo Start, che di default coincide
con il metodo run(), e poi attende la sua terminazione. Nel momento in cui
l'agente decide di spostarsi, il suo Worker è sostituito con un altro appositamente
creato sull’ambiente di destinazione: anch’esso si limita a lanciare il metodo
specificato come argomento nel comando go(), in questo modo si riesce a
simulare il controllo di flusso tipico della mobilità forte. Per inserire un agente
nel sistema, l’utente può utilizzare il tool grafico “AgentLauncher”.
���� 0RELOLWj
La migrazione degli agenti è implementata attraverso il comando go(), che
può essere invocato dagli agenti in un qualunque momento.
L’effetto di questa invocazione è il seguente: l’esecuzione dell’agente è
sospesa, l’oggetto in cui è implementato è serializzato e spedito all’ambiente di
destinazione. Il comando go() prevede due argomenti: il primo rappresenta la
località di destinazione, mentre il secondo, specifica il nome del metodo da cui
riprendere l’esecuzione.
La destinazione di uno spostamento può essere espressa in termini di
nome del Place su cui spostarsi oppure di nome del Dominio da raggiungere. Il
primo caso segnala al sistema la volontà dell’agente di effettuare una migrazione
interna al Dominio, che rientra nella gestione intra Dominio. Il secondo caso,
invece, specifica che il trasferimento coinvolge un Dominio diverso da quello
attuale e quindi si impone il passaggio attraverso il Gateway. Infatti, nella
gestione inter Dominio, ogni tipo di interazione con entità esterne al Dominio
deve essere sottoposta al controllo del Gateway.
Un agente che desidera cambiare il Dominio di esecuzione deve invocare
il comando go(), specificando come destinazione il nome del Dominio da
raggiungere: come conseguenza, l’agente è affidato dal Place attuale al suo
Page 95
87
Gateway, che lo consegna al Default Place del Dominio remoto. Nel nuovo
Dominio poi l’agente può scegliere su quale Place riprendere la sua esecuzione.
Se durante uno spostamento si verifica un problema che non consente all’agente
di raggiungere il suo obiettivo, il sistema segnala all’agente stesso una situazione
anomala attraverso l’eccezione “CantGoException”.
L’invocazione del comando go() può segnalare un evento imprevisto,
come per esempio, il fatto che, in una transizione intra Dominio, il Place da
raggiungere non sia attivo oppure che, durante una migrazione inter Dominio, si
segnali la disattivazione del Gateway locale. Quando è sollevata l’eccezione
CantGoException, è possibile eseguire delle azioni alternative che consentano
all’agente di aggiornare le sue scelte: per fare questo è sufficiente gestire
l’eccezione attraverso i meccanismi messi a disposizione da Java.
Quando l’agente è arrivato a destinazione, si consulta il nome del metodo
da cui ripartire, che è specificato come secondo argomento del comando go(). La
mobilità debole di Java, impone di ricominciare l’esecuzione da un punto preciso
e in SOMA si è scelto di farlo corrispondere con l’inizio di un metodo: come
conseguenza di questa decisione, è bene che il comando go() risulti l’ultima
istruzione di ogni metodo.
���� &RPXQLFD]LRQH
Nel progettare i meccanismi di comunicazione di SOMA è stato seguito
un criterio molto rigido: i meccanismi di LQWHUD]LRQH�VWUHWWD sono ammessi solo
fra agenti che si trovano nello stesso place. Questo criterio è fondato su uno dei
principi base del paradigma ad agenti mobili, che prevede la non trasparenza
della località delle risorse e degli agenti sulla rete. In quest'ottica non ha senso
prevedere forte accoppiamento fra agenti che si trovano su place diversi, quindi i
meccanismi di interazione stretta vanno riservati alle comunicazioni nell'ambito
dello stesso place.
������ &RPXQLFD]LRQH�WUD�$JHQWL�VLWXDWL�VX�SODFH�GLYHUVL
SOMA fornisce un solo meccanismo di comunicazione tra agenti che si
trovano in place diversi: lo scambio di PHVVDJJL.
Page 96
Un messaggio è un oggetto composto da 3 elementi:
1) L’identificatore dell’agente mittente.
2) L’identificazione dell’agente destinatario.
3) Il contenuto del messaggio, un oggetto di qualsiasi tipo, che possa essere
trasferito da un place all’altro.
Un agente può spedire un messaggio ad un altro agente indipendentemente
dal place in cui si trova il destinatario. Il mittente non è neanche tenuto a
conoscere la posizione attuale dell’agente destinatario, che potrebbe anche essere
in una fase di spostamento. L’unica informazione necessaria per la spedizione è
l’identità del destinatario.
Spedito un messaggio, l’agente non riceve alcuna conferma di ricezione da
parte del destinatario, ma il sistema garantisce il recapito del messaggio, se il
destinatario si trova su un place raggiungibile.
Ogni agente dispone di una Mailbox, che conserva i messaggi ricevuti e
non ancora letti. È possibile vedere in maniera nonbloccante se sono presenti
messaggi nella mailbox, oppure attenderli in maniera bloccante.
Non tutti gli agenti dispongono del servizio di messaggeria. Infatti, per
poter recapitare un messaggio a un agente, il sistema deve sempre tenere traccia
dei suoi spostamenti, e questo comporta un certo overhead, soprattutto in termini
di utilizzo della rete. Si è quindi deciso di poter creare agenti QRW�WUDFHDEOH��non
rintracciabili, e quindi privi di Mailbox, per migliorare l’efficienza di
applicazioni che non necessitano di questo servizio. In ogni caso, a default ogni
agente è WUDFHDEOH.
������ &RPXQLFD]LRQH�WUD�$JHQWL�VLWXDWL�VXOOR�VWHVVR�SODFH
Per quanto riguarda invece la comunicazione fra agenti che si trovano
nello stesso place, oltre lo scambio di� PHVVDJJL si possono utilizzare altri due
meccanismi di comunicazione di tipo LWHUD]LRQH�VWUHWWD:
• La FRQGLYLVLRQH�GL�RJJHWWL: oggetti di qualsiasi tipo possono essere depositati
in uno speciale contenitore, ricevendo in cambio un identificatore con il quale
sarà possibile accedere di nuovo all’oggetto da parte dello stesso o di un altro
agente.
Page 97
89
• La EODFNERDUG�� una lavagna su cui lasciare messaggi del tipo �FKLDYH�
FRQWHQXWR�, dove FKLDYH�è una stringa di descrizione e PHVVDJJLR�un oggetto
qualsiasi.
La differenza è che la FKLDYH�della EODFNERDUG�è di tipo stringa, e fornisce
una descrizione “in chiaro” del contenuto, a differenza dell’identificatore del
caso precedente che, invece, viene fornito dal sistema. Così, affinché un altro
agente possa aver accesso ad un oggetto condiviso, deve essergli fornito
l’identificatore da colui che lo ha depositato, mentre nel caso della blackboard è
sufficiente accordarsi sul “nome” (FKLDYH) da dare ad un certo tipo di
informazione.
In sostanza la blackboard è l’unico dei tre meccanismi visti che permette
di comunicare con agenti di cui non si conosca già l’identificatore (LQWHUD]LRQH
DQRQLPD), e può essere utilizzato proprio per mettere in contatto agenti che
altrimenti non si potrebbero conoscere.
���� 6LFXUH]]D
SOMA fornisce sistemi di sicurezza sia per la protezione dell'ambiente
che degli agenti.
La definizione di differenti astrazioni di località consente di assicurare
politiche di sicurezza nelle quali le azioni sono controllate sia a livello di place
che a livello di dominio. Il dominio definisce una politica di sicurezza globale
che impone autorizzazioni e proibizioni generali; ogni place può solo applicare
restrizioni ai permessi consentiti a livello di dominio.
������ 3URWH]LRQH�GHOODPELHQWH
Gli agenti entranti in un dominio o in un place sono autenticati sulla base
di una serie di informazioni: il nome del place e del dominio di origine, i nomi
delle classi che implementano gli agenti, e il nome degli utenti per i quali gli
agenti lavorano.
In funzione di questa autenticazione viene assegnato all'agente un certo
grado di fiducia che si traduce nei diritti di accesso ed uso di un numero limitato
Page 98
e predefinito di risorse del place in accordo alla politica di sicurezza; ogni risorsa
ha una sua specifica access control list per tutti i SULQFLSDO che potenzialmente
possono accedervi.
Inoltre i place sono protetti grazie al fatto che gli agenti possono accedere
alle risorse di un nodo solo per mezzo di interfacce.
������ 3URWH]LRQH�GHJOL�DJHQWL
Senza un supporto hardware adeguato, non è possibile evitare che
l'ambiente di esecuzione di un place faccia quello che vuole su un agente. Quello
che si può fare, è cercare di scoprire, in un place di fiducia, le eventuali
manomissioni subite da un agente quando torna da un place non fidato.
In SOMA, vengono protetti l’integrità del codice e la riservatezza dei dati
di un agente quando questo è trasmesso su un canale di comunicazione.
L’integrità si garantisce sottoponendo l’agente al processo della firma con la
chiave privata del 3ULQFLSDO creatore. Mentre la riservatezza si raggiunge
sottoponendo l’agente a cifratura, prima che questi sia spedito sulla rete. In
realtà, in SOMA, è possibile cifrare ogni tipo di oggetto scambiato tra due
Places.
Page 99
91
&DSLWROR����6,67(0,�3(5�,/�5(&83(52�'(,
&(57,),&$7,
���� ,QWURGX]LRQH
Il recupero di un certificato per un possibile interlocutore appartenente a
un dominio di fiducia diverso richiede la determinazione e la convalida di un
cammino di certificazione. Uno standard per la convalida non è stato definito
[L97 pag. 45], la procedura di convalida può essere realizzata in vari modi
[RFC2459 cap. 6]. L’importante è che il risultato sia lo stesso qualsiasi
procedimento si adotti.
Il metodo più utilizzato per controllare la validità di un singolo certificato
è vedere se è contenuto nella Certificate Revocation List (CRL) che può essere
recuperata dal sistema di directory a cui si appoggia la CA responsabile.
Le autorità di certificazione possono anche mettere a disposizione un
server on-line dedicato per notificare lo stato di revoca dei certificati. In questo
caso la verifica della validità dei certificati può essere richiesta direttamente
attraverso delle query OCSP [RFC2560].
Questo secondo metodo di verifica è preferibile, sempre che sia
disponibile, in quanto garantisce la massima certezza sulla validità dei certificati,
come evidenziato nel paragrafo 3.6.
Le tecniche di ricerca e validazione che si possono realizzare dipendono
fortemente dalla struttura delle PKI.
���� 5LFHUFD�H�FRQYDOLGD�GHL�FDPPLQL�GL�FHUWLILFD]LRQH
Per costruire cammini di certificazione di lunghezza accettabile si fa
riferimento alla teoria dei grafi da cui si vede che le strutture organizzate ad
albero o gerarchiche forniscono una soluzione efficiente al problema.
Page 100
������ 3.,�FRQ�VWUXWWXUD�JHUDUFKLFD
Nel modello gerarchico stretto la certificazione è realizzata solo dalle
autorità superiori nei confronti di quelle gerarchicamente inferiori. Tutti i
cammini di certificazione partono dal vertice, ogni utente deve quindi fidarsi
della radice e conoscere la relativa chiave pubblica.
Il vantaggio di tale struttura è che per ogni utente esiste un unico cammino di
certificazione e la sua determinazione è abbastanza semplificata.
Lo svantaggio è che tutti i cammini di certificazione coinvolgono la radice
e quindi la fiducia è completamente riposta nella sicurezza della radice.
Un esempio di implementazione di infrastruttura a chiave pubblica
conforme al modello gerarchico è la PEM (Privacy Enhancement for Internet
Electronic Mail) [RFC 1421-1424]. Questa infrastruttura prevede che quando un
utente spedisce un messaggio firmato ad un altro utente includa al messaggio
anche il cammino dal vertice della gerarchia a se stesso [RFC 1422 pag. 24]. Il
cammino di certificazione è così già conosciuto, visto che ogni utente si fida
della radice e possiede la relativa chiave. Quando invece un utente vuole spedire
un messaggio crittografato ad un altro utente non conosce il cammino di
certificazione, ma data la struttura gerarchica, può essere determinato con
algoritmi di ricerca in un albero. In PEM sono disponibili servizi che lo
determinano, ma la cui implementazione è lasciata ad un sistema di directory.
Trovare il cammino più corto tra due punti in una struttura ad albero è un
problema già affrontato e risolto da vari ricercatori con diverse metodologie.
Algoritmi applicabili sono quelli classici dell’ottimizzazione combinatoria
[CMT79] per determinare un cammino dalla radice ad un nodo; in questo caso
una foglia che rappresenta il certificato del destinatario del messaggio.
In assenza di informazioni si può applicare solo una strategia in avanti o
"forward", partendo dalla radice si cercherà di raggiungere il nodo foglia
corrispondente al certificato da trovare. La ricerca può avvenire in due modi
differenti: in profondità (depth first) o in ampiezza (breadth first). Nella prima si
cerca di raggiungere rapidamente una soluzione visitando ad ogni passo sempre il
nodo più lontano dalla radice, viceversa nella tecnica in ampiezza dove il nodo
scelto per la visita è il più vicino alla radice. La ricerca in profondità è più
Page 101
93
efficiente nel caso di struttura strettamente gerarchica, ma in presenza di cross-
certification (connessione aggiuntiva di due nodi) tra due diverse CA può
generare dei loop, al contrario della ricerca in ampiezza che è completa.
Spesso il sistema di PKI mette a disposizione una funzione di ricerca dei
certificati (ad esempio PEM e ICE-TEL) per gli utenti e le CA, tramite servizi di
directory globale od altri meccanismi. Questa funzione ha, nel caso generale,
come input l’entità di cui ricerchiamo un certificato e fornisce come output tutti i
certificati pubblicati per quell’entità. Se si ha a disposizione questa funzione si
può applicare anche un algoritmo di ricerca del cammino di certificazione con
strategia all'indietro o "backward". Prima si ricerca un certificato per il
destinatario, si vede la CA che lo certifica se è fidata si termina altrimenti si
cerca un certificato per questa CA e si prosegue, nel peggiore dei casi ci si arresta
alla radice. Si può notare quest’algoritmo è applicabile anche in presenza di
cross_certification.
������ 3.,�FRQ�VWUXWWXUD�GLVWULEXLWD
Prevede la presenza di PKI distinte che a discrezione, secondo accordi
reciprocamente pattuiti, si certificano vicendevolmente. Ogni singola
infrastruttura è gestita autonomamente e può essere strutturata internamente
secondo il modello di fiducia ritenuto più idoneo. Il vantaggio è l’assenza di
un’unica autorità di certificazione radice di cui doversi completamente fidare.
Lo svantaggio è che la struttura che ne deriva non ha più una topologia ben
definita che individui univocamente un cammino di certificazione tra due utenti.
Possibili algoritmi di ricerca del cammino di certificazione sono, in questo
caso, quelli che determinano un cammino in un grafo, citiamo ad esempio lo
Shortest Path [AMO93] con il quale in tempo polinomiale nella dimensione dello
spazio di ricerca (che è formato da tutti i possibili nodi) si ottiene una soluzione.
La ricerca deve essere esaustiva, perché ci possono essere più cammini e bisogna
cercare quello più breve, spesso si rinuncia a questo tipo di ricerca perché ha
complessità esponenziale e ci ferma al primo cammino trovato.
In assenza di informazioni si può applicare solo una strategia forward con
ricerca in ampiezza in quanto la ricerca in profondità potrebbe generare
facilmente dei loop. L’algoritmo partirà dalla CA del mittente cercherà tra tutti i
Page 102
certificati da essa pubblicati quello del destinatario, se lo trova si fermerà,
altrimenti lo cercherà nelle CA di cui ha trovato un certificato; proseguirà così in
avanti finché non lo troverà oppure avrà esaminato tutte le CA certificate.
Se il sistema di PKI mette a disposizione una funzione di ricerca dei
certificati (ad esempio ICE-TEL) per gli utenti e le CA, tramite servizi di
directory globale od altri meccanismi, si può applicare anche un algoritmo di
ricerca del cammino di certificazione con strategia backward. Prima si ricercano
tutti i certificati per il destinatario, si vedono le CA che lo certificano, se almeno
una è fidata si termina, altrimenti si cercano tutti i certificati per queste CA e si
prosegue finché o si trova un certificato firmato da una CA di fiducia oppure non
si hanno a disposizione più certificati da verificare. Quest’algoritmo è usato da
ICE-TEL [YCC96].
������ &RQIURQWR�WUD�OH�GXH�RUJDQL]]D]LRQL�GL�3.,
L'adozione di un particolare modello organizzativo delle infrastrutture a
chiave pubblica influenza il processo di individuazione di un cammino di
certificazione e ne determina i tempi di recupero.
La struttura distribuita è quella più penalizzata perché, proprio per le sue
peculiari caratteristiche, richiede un processo di ricerca non ben definito,
variabile a secondo delle informazioni reperite durante l'esecuzione. La durata
della ricerca non quindi è prevedibile e potrebbe essere inaccettabile.
I due modelli organizzativi di PKI visti sono i casi estremi, esistono varie
realizzazioni intermedie in cui si cerca di mediare tra l’esigenza di una struttura
efficiente e una struttura sicura ed indipendente. Gli algoritmi di ricerca dei
cammini di certificazione in questi casi risultano modifiche degli algoritmi
proposti per i due modelli, nei quali si cerca di sfruttare le informazioni sulla
struttura organizzativa delle PKI. Un esempio è il modello semplificato di ICE-
TEL in cui la cross_certification non può essere transitiva e quindi la ricerca di
un cammino di certificazione si può interrompere in presenza di due
cross_certification.
Page 103
95
���� 6LVWHPD�&OLHQW�6HUYHU��L�SURWRFROOL�/'$3�H�2&63
Tutte le informazioni necessarie alla ricerca e convalida di un cammino di
certificazione possono essere richieste ai Directory Server attraverso il protocollo
LDAP basato sul classico modello cliente-servitore; le motivazioni della scelta di
questo protocollo e il modo di utilizzarlo per recuperare certificati e CRL sono
indicato in [RFC2559].
L’applicazione utente che si occupa del recupero e della convalida dei
certificati elettronici dovrà aprire una connessione con il Directory Server
effettuare una richiesta LDAP, attendere la risposta, analizzarla e di conseguenza
interrogare un altro sistema di directory se il certificato non è stato trovato, o
passare alla fase di convalida nel caso il certificato sia stato recuperato.
Il processo di convalida di un certificato elettronico comporta a sua volta
una connessione con il Directory Server dell'autorità di certificazione che ha
pubblicato il certificato per recuperare la lista di revoca CRL. In alternativa la
convalida del certifica comporta una connessione con il server on-line OCSP
dell'autorità di certificazione competente per richiedere direttamente lo stato di
revoca del certificato.
���� 8Q�VLVWHPD�DG�DJHQWL�PRELOL�SHU�OD�ULFHUFD�H�FRQYDOLGD�GHLFHUWLILFDWL
������ 0RWLYD]LRQL
La nostra idea è quella di utilizzare il modello di comunicazione ad agenti
mobili, in modo da elaborare in locale le informazioni che man mano vengono
raccolte senza dover ritornare ogni volte al sito d'origine.
Le richieste LDAP dovranno comunque essere effettuate, in quanto
rappresentano l'unico accesso ai servizi di directory, ma la loro esecuzione
avverrà localmente nel sito della directory stessa in cui precedentemente un
agente si sarà portato.
L'esecuzione locale porterà ad una riduzione del tempo di elaborazione
della query. Anche l'utilizzo della rete di comunicazione diminuirà, infatti,
l'agente si sposterà solo una volta per eseguire una singola richiesta, mentre
Page 104
l’esecuzione in remoto della query richiede prima la trasmissione della richiesta e
dopo la notifica della risposta.
Inoltre l'uso degli agenti mobili rende più flessibile il processo di ricerca
vista la loro capacità di elaborazione e la possibilità di generare dinamicamente
altri agenti. Grazie proprio a quest'ultima possibilità il modello ad agenti mobili
permette di realizzare la ricerca in maniera più efficiente rispetto all'uso del
classico modello cliente-servitore, utilizzando più agenti che lavorano in
parallelo per recuperare le informazioni richieste.
������ $UFKLWHWWXUD
Vediamo un possibile sistema per la ricerca e la convalida di un cammino
di certificazione che sfrutti il paradigma ad agenti mobili.
)LJ�����: Architettura del sistema
Page 105
97
La figura mostra come il sistema sia organizzato per componenti
interagenti. Ogni componente è un agente. Gli agenti possono essere statici (GL
VHUYL]LR) o mobili (GL� ULFHUFD). Gli agenti di servizio stazionano in un place e
sono in grado di svolgere un particolare compito. Gli agenti di ricerca sono in
grado di spostarsi di place in place (ed eventualmente di dominio in dominio),
interagendo con gli agenti di servizio per portare a termine i propri obiettivi.
������ $JHQWL�GL�VHUYL]LR�H�VHUYL]L�UHDOL]]DWL
Gli agenti di servizio consentono l’accesso a specifiche funzionalità
rintracciabili nel place in cui sono situati. Ad esempio gli $JHQWL� 5LVRUVD
consentono di accedere alle informazioni contenute in una particolare directory.
Vediamo brevemente quali sono gli agenti di servizio del sistema:
• $JHQWH�5LVRUVD��consente di accedere al servizio di directory e al servizio
OCSP, estrapolandone le informazioni che interessano. Nasconde
completamente la struttura, l’organizzazione fisica e i metodi di accesso ai
dati.
• $JHQWH� 5HSRVLWRU\�� un repository memorizza e consente di individuare
oggetti di varia natura, utili ai vari componenti del sistema. Tutti gli agenti
possono inserire e recuperare oggetti dal repository.
������ 8WLOL]]R�GHL�YDUL�DJHQWL
L’ DSSOLFD]LRQH crea un DJHQWH� ULFHUFD che si può muovere tra i diversi
place e domini e può generare altri agenti ricerca.
L’agente ricerca inserisce sull’DJHQWH�UHSRVLWRU\ tutti i certificati delle CA
che andrà a visitare direttamente o tramite i suoi figli.Nell’agente repository si memorizzano tutti i certificati delle CA in
esplorazione, in modo da non esplorarle più di una volta. Un DJHQWH� ULFHUFD
prima di esplorare una nuova CA verifica che non ci sia nessun certificato ad
essa associata nel repository.
Si può pensare ad un unico agente repository, ubicato in un particolare
place, od a più di uno, replicati in maniera opportuna anche in ogni place.
Page 106
������ 7HFQLFD�GL�ULFHUFD�H�FRQYDOLGD�GHO�FDPPLQR�GL�FHUWLILFD]LRQH
Illustriamo gli algoritmi utilizzando i classici interlocutori, noti in
letteratura, Alice e Bob. Alice non dispone della chiave pubblica di Bob e, per
poter comunicare in sicurezza con lui, ha bisogno di un cammino di
certificazione che li leghi.
Gli algoritmi sono descritti con riferimento al sistema ad agenti mobili,
visto precedentemente. Tratteremo separatamente i due modelli organizzativi di
PKI.
��������3.,�FRQ�VWUXWWXUD�JHUDUFKLFD
In una struttura gerarchica stretta Alice possiede la chiave pubblica della
radice della organizzazione di PKI a cui appartiene.
L’applicazione principale genera un agente di ricerca inviandolo nel place
dove risiede la directory della root ed aspetta il ritorno da parte dello stesso
agente o di un suo discendente. L’agente di ricerca una volta arrivato nel place di
destinazione (quello della root), controlla se tra i certificati contenuti nella
directory c'è quello di Bob; se lo trova richiede al rispettivo server OCSP lo stato
corrente del certificato. Ricevuta una risposta firmata l'agente ritorna con
successo al place d'origine di Alice riportando con sé il certificato di Bob e la
risposta firmata che ne indichi lo stato di revoca.
Nel caso il certificato di Bob non è presente nella directory della root
l'agente dovrà continuerà la ricerca nelle subordinate CA per ottenere il
certificato elettronico di Bob. Per avere disponibile un cammino di certificazione
che garantisca l'autenticità del certificato di Bob, l'agente recupera, sempre dalla
stessa directory della root, tutti i certificati relativi a subordinate CA. Per ognuno
di questi richiede lo stato di revoca al server OCSP e per ciascun certificato
valido genera un nuovo agente di ricerca che invia nel place dove è situata la
directory della CA cui il certificato è riferito (in realtà viene creato un agente in
meno, perché in un place si porterà lo stesso agente genitore).
Ad ogni agente è associato il rispettivo certificato pubblicato dalla root e
la relativa risposta OCSP firmata, in modo da aver disponibile alla fine tutta la
catena di certificazione.
Page 107
99
Questi agenti controlleranno nelle rispettive directory di destinazione la
presenza del certificato di Bob se uno di essi lo trova allora verifica la sua
validità attraverso una richiesta OCSP al server competente ed lo ingloba al suo
interno (insieme alla risposta firmata) e ritorna al place di Alice dove porterà con
se l’intero cammino di certificazione e le risposte firmate che ne assicurano
l'autenticità. Inoltre comunica a tutti gli altri agenti di ricerca collegati di
concludere la loro esecuzione.
Nel caso in cui il certificato di Bob non viene trovato, si procede
similmente con la generazione di nuovi agenti di ricerca per le CA subordinate di
cui si è ottenuto un certificato.
Data la struttura strettamente gerarchica il processo terminerà
correttamente o con il ritrovamento del certificato di Bob oppure con fallimento
quando non ci sono più CA subordinate da esplorare.
��������*HVWLRQH�GHOOLQVXFFHVVR
Per comunicare il fallimento della ricerca è necessario che, quando un
agente di ricerca conclude la sua esplorazione senza trovare il certificato di Bob o
certificati relativi ad altre CA, comunichi il suo stato negativo di non trovato
all’agente che lo ha generato. Analogamente un agente di ricerca che non ha
trovato il certificato di Bob, ma ha recuperato dei certificati relativi ad altre CA
generando per ognuno di essi dei nuovi agenti e ricevuto da ognuno di loro
risposta negativa, dovrà comunicare il suo stato di non trovato all’agente
genitore.
L’ultimo agente a terminare l’esecuzione sarà l’agente di ricerca partito
dal place di Alice che lo comunicherà all’applicazione utente iniziale.
������ 3.,�FRQ�VWUXWWXUD�GLVWULEXLWD
Una struttura distribuita non ha una topologia ben definita che individui
univocamente un cammino di certificazione tra due utenti.
Utilizzando una procedura di ricerca simile al caso dell’organizzazione
gerarchica c’è il rischio di controllare più volte una stessa CA, ed alcuni agenti di
ricerca potrebbero entrare in pericolosi loop. Nel caso la ricerca si conclude con
successo questi loop generati comportano solo uno spreco di risorse, ma nel caso
Page 108
di insuccesso questi loop non faranno terminare il processo di ricerca. Da qui
l’impossibilità di usare un algoritmo simile al caso gerarchico.
Per ovviare al problema della generazione di pericolosi loop si può
pensare di mantenere una lista delle CA già controllate in modo che un agente
prima di effettuare una ricerca su una data CA vede se non sia già stata
controllata.
A tale scopo può essere utile l’utilizzo di un agente repository dove
depositare gli identificativi (p.e. il nome o un certificato) delle CA che si
andranno a controllare.
Vediamo ora come avviene il processo di ricerca e convalida del cammino
di certificazione.
Alice ha a disposizione sicuramente la chiave pubblica della autorità di
certificazione di cui si fida. L'applicazione principale inserisce nel repository un
identificativo per questa CA, genera un agente di ricerca inviandolo nel place
dove risiede la directory della CA fidata di Alice ed aspetta il ritorno da parte
dello stesso agente o di un suo discendente.
L'agente di ricerca una volta arrivato nel place di destinazione, controlla se
tra i certificati contenuti nella directory c'è quello di Bob; se lo trova richiede al
rispettivo server OCSP lo stato corrente del certificato, ricevuta una risposta
firmata l'agente ritorna con successo al place d'origine di Alice riportando con sé
il certificato di Bob e la risposta firmata che ne attesta lo stato di revoca.
Nel caso il certificato di Bob non è presente nella directory, per avere
disponibile un cammino di certificazione che garantisca l'autenticità del
certificato di Bob, l'agente recupera tutti i certificati relative a CA cross-
certificate, selezionando solo quelli non presenti nel repository. Per ognuno dei
selezionati richiede lo stato di revoca al server OCSP, per ciascun certificato
valido inserisce nel repository un identificativo per la CA cui è riferito, genera un
nuovo agente di ricerca che invia nel place dove è situata la directory della CA
(in realtà viene creato un agente in meno, perché in un place si porterà lo stesso
agente genitore).
Ad ogni agente è associato il rispettivo certificato pubblicato dalla CA di
Alice e la relativa risposta OCSP firmata, in modo da aver disponibile alla fine
tutta la catena di certificazione.
Page 109
101
Questi agenti controllano nelle rispettive directory di destinazione la
presenza del certificato di Bob se uno di essi lo trova allora verifica la sua
validità attraverso una richiesta OCSP al server competente, lo ingloba al suo
interno (insieme alla risposta firmata) e ritorna al place di Alice dove porterà con
se l’intero cammino di certificazione e le risposte firmate che ne assicurano la
validità. Inoltre comunica a tutti gli altri agenti di ricerca collegati di concludere
la loro esecuzione.
Nel caso in cui il certificato di Bob non viene trovato, si procede
similmente con la generazione di nuovi agenti di ricerca per le CA di cui si è
ottenuto un certificato valido e non sono presenti nel repository.
Grazie proprio all'utilizzo del repository il processo terminerà
correttamente o con il ritrovamento del certificato di Bob oppure con insuccesso
quando non ci sono più CA da esplorare. Per gestire quest'ultima eventualità
vengono adottate le stesse tecniche del caso di struttura gerarchica.
������ &RQYDOLGD�GHO�FDPPLQR�LQ�DVVHQ]D�GHO�VHUYL]LR�2&63
La verifica della validità dei certificati dovrà passare attraverso il controllo
delle relative CRL.
Quando un agente si porta in un place e preleva un certificato che ritiene
utile può controllare subito la sua validità verificando che non sia presente nella
relativa CRL; per far questo l’agente deve avere con sé la chiave pubblica della
CA in cui sta cercando i certificati. Tale chiave è fornita dall’agente genitore, in
quanto è ottenuta nel passo precedente (dalla CA di provenienza sotto forma di
certificato) oppure fornita direttamente da Alice (la chiave della sua CA di
fiducia).
Utilizzando questo metodo di verifica istantanea dei certificati quando
l’agente avrà determinato un cammino di certificazione e lo ritornerà ad Alice si
è sicuri anche della sua validità.
Il problema è che il controllo della firma avviene in un place sconosciuto e
in assenza di garanzie sull’ambiente di esecuzione non si può essere sicuri del
risultato ottenuto e il processo di convalida del cammino di certificazione dovrà
recuperare le CRL associate ai certificati componenti il cammino e portarle nel
Page 110
place sicuro di Alice, dove potranno essere controllate correttamente al fine di
convalidare il cammino di certificazione trovato.
Le CRL possono essere recuperate dagli agenti direttamente nel processo
di ricerca del cammino copiando al loro interno le CRL associate ad ogni
certificato reperito nei place delle varie CA. In questo modo quando l’agente
troverà il cammino di certificazione avrà con sé anche le CRL corrispondenti e
potrà verificare la validità del cammino una volta ritornato nel place di Alice.
Questo metodo, abbastanza semplice e veloce, ha però il difetto di
appesantire troppo l’agente date le dimensioni non troppo piccole delle CRL.
Un'altra soluzione è di recuperare le CRL solo dopo aver ottenuto un
cammino di certificazione, mandando un agente ad ogni CA che ha pubblicato
almeno un certificato del cammino, a recuperare le rispettive CRL in modo da
poterli verificare. In questo modo si evita che la dimensione dell’agente sia
troppo grande.
������2VVHUYD]LRQL�H�SRVVLELOL�HVWHQVLRQL
In presenza di informazioni aggiuntive su Bob si può semplificare la
ricerca, evitando a priori di visitare le directory associate a CA che non possono
pubblicare certificati per Bob. Per esempio, se conosciamo la nazionalità di Bob,
basterà controllare solo i certificati emessi da CA di quel paese; oppure se
conosciamo a quale organizzazione o gruppo di organizzazioni appartiene Bob
allora si consulteranno solo le directory con i certificati pubblicati da CA che
possono gestire queste organizzazioni, od ancora se conosciamo la CA di Bob
una volta recuperato un certificato per tale autorità non si genereranno altri
agenti, ma ci si porterà direttamente nel relativo place a prelevare il certificato di
Bob. Nel caso più favorevole in cui già si conosce il cammino di certificazione e
bisogna solo recuperare i certificati di cui è composto (p.e. in una struttura
gerarchica Bob può averlo comunicato ad Alice con un messaggio precedente), si
possono mandare degli agenti direttamente nelle directory delle CA interessate a
prelevare i certificati richiesti. L’algoritmo proposto per un’organizzazione
distribuita di PKI è il più generale e può essere applicato anche nel caso di
struttura gerarchica, con una perdita in termini di efficienza rispetto all’algoritmo
specifico, garantendo comunque la completezza e la correttezza della soluzione.
Page 111
103
&DSLWROR����,03/(0(17$=,21(�(�5,68/7$7,
���� ,QWURGX]LRQH
Nel capitolo precedente abbiamo visto come possa essere realizzato un
sistema per il recupero dei certificati, in particolare abbiamo proposto
un’architettura basata sul modello di comunicazione ad agenti mobili. In questo
capitolo descriveremo l’implementazione del sistema e analizzeremo le sue
prestazioni.
Il processo di costruzione del sistema ad agenti per il recupero e la
convalida dei certificati elettronici si è svolto in diverse fasi distinte. In prima
fase abbiamo individuato un supporto ad Agenti Mobili sul quale realizzare il
sistema. Poi, in seconda fase, ci siamo occupati dell'interfaccia tra il sistema e i
server di Directory, decidendo di utilizzare le JNDI (Java Naming and Directory
Interface) API (Application Programming Interface). Infine, si è passati alla
programmazione dell'applicazione e degli agenti necessari. Una volta realizzato il
sistema si è svolta un'adeguata fase di testing e di analisi delle prestazioni.
���� /D�VFHOWD�GHO�VXSSRUWR
Il supporto ad Agenti Mobili sul quale abbiamo realizzato il nostro sistema
è l'ambiente SOMA descritto nel sesto capitolo. I motivi di tale scelta sono
molteplici: SOMA fornisce tutte le funzionalità di un sistema ad agenti, il codice
è distribuito liberamente [SOMA], è realizzato all'interno del DEIS il
dipartimento dove si è svolta questa tesi e questo ha permesso un continuo
scambio di informazioni con i progettisti di SOMA.
Inoltre SOMA è realizzato interamente tramite il linguaggio JAVA
introdotto nel paragrafo 5.9, gli agenti SOMA possono così utilizzare anche tutte
le funzionalità offerte da Java.
Page 112
���� /LQWHUIDFFLD�WUD�LO�VLVWHPD�H�L�VHUYL]L�GL�'LUHFWRU\
Il linguaggio JAVA rende disponibile un API per l’accesso ai servizi di
Directory che prende il nome di JNDI (Java Naming and Directory Interface)
[JNDI].
Questa interfaccia è di basso livello e costituisce la base per la costruzione
di semplici applicazioni o interfacce di livello superiore che realizzano una
maggiore astrazione.
Le JNDI API sono indipendenti dal particolar tipo di servizio di directory
usato come LDAP, NDS o NIS. L'utilizzatore accede alle diverse directory in
maniera trasparente, sarà compito dell'interfaccia, attraverso appositi driver,
tradurre le chiamate JNDI standard nelle chiamate specifiche richieste per il
particolare server di directory.
Un'applicazione che usa le JNDI API potrà essere utilizzata per accedere a
diversi directory server, secondo la filosofia JAVA "write once, run anywhere";
l'applicazione rimane sempre la stessa e sono i driver a cambiare.
E' importante notare che un applicazione realizzata con JNDI potrà essere
utilizzata non solo con i servizi di directory attualmente disponibili, ma anche
con i futuri; basterà, infatti, che il produttore del nuovo directory server renda
disponibile un driver JNDI.
Le case produttrici di servizi di directory possono realizzare facilmente
questi driver JNDI attraverso l'utilizzo delle JNDI SPI (Service Provider
Interface).
L'importanza di avere un'interfaccia comune di accesso è stata recepita dai
maggiori produttori di directory server, come Netscape, Novell e Sun, che
forniscono i driver JNDI per tutti i loro sistemi.
���� ,O�VLVWHPD�SHU�LO�UHFXSHUR�H�OD�FRQYDOLGD�GHL�FHUWLILFDWL�DG$JHQWL�0RELOL
Il sistema si basa sull'architettura di fig. 7.1 descritta nel paragrafo 7.5. Il
recupero e la convalida dei certificati elettronici avviene attraverso la tecnica
proposta nel paragrafo 7.6.
Page 113
105
Riportiamo di seguito i diagrammi di flusso del comportamento
dell’applicazione e dell’agente ricerca, distinguendo tra i due modelli
organizzativi di PKI e assumendo la presenza del servizio OCSP.
������ 3.,�FRQ�VWUXWWXUD�JHUDUFKLFD
L’applicazione utente principale genera il primo DJHQWH�ULFHUFD che inizia
il processo di recupero a partire dalla directory della root, come indicato in figura
8.1.
)LJ�����: Diagramma di flusso dell’applicazione nel caso di organizzazione gerarchica delle PKI
L'applicazione resterà in attesa del ritorno di un agente, l'utente però in
questa fase si può scollegare dalla rete risparmiando sui costi di connessione;
quando si ricollegherà, raccoglierà e verificherà il risultato ottenuto dall'agente
ricerca. Questo è un altro dei vantaggi dell'utilizzo degli agenti mobili.
Le variabili 1),*/, e $*(17(,'3$'5( sono interne all'agente ricerca
ed indicano rispettivamente il numero di agenti figli creati e l'identificativo
dell'agente ricerca genitore, quest'ultima variabile per l'agente ricerca generato
direttamente dall'applicazione assume il valore di zero.
L'agente di ricerca una volta arrivato nel place di destinazione, controlla se
tra i certificati contenuti nella directory c'è quello di Bob; se lo trova richiede al
rispettivo server OCSP lo stato corrente del certificato. Ricevuta una risposta
firmata l'agente ritorna con successo al place d'origine di Alice riportando con sé
il certificato di Bob e la risposta firmata che ne indichi lo stato di revoca.
Page 114
)LJ�����: Diagramma di flusso del comportamento dell’agente ricerca una volta arrivato nel place di destinazione nel caso organizzazione gerarchica delle PKI
Page 115
107
Nel caso il certificato di Bob non è presente nella directory l'agente dovrà
continuerà la ricerca nelle subordinate CA per ottenere il certificato elettronico di
Bob. Per avere disponibile un cammino di certificazione che garantisca
l'autenticità del certificato di Bob, l'agente recupera, sempre dalla stessa
directory, tutti i certificati relativi a subordinate CA. Per ognuno di questi
richiede lo stato di revoca al server OCSP e per ciascun certificato valido genera
un nuovo agente di ricerca che invia nel place dove è situata la directory della
CA cui il certificato è riferito; nell'ultimo place individuato si porterà lo stesso
agente genitore. Lo schema di principio è indicato nelle figure 8.2 e 8.3.
Per gestire correttamente il processo di recupero dei certificati elettronici
l'agente ricerca deve memorizzarsi gli identificativi degli agenti ricerca da lui
generati.
Page 116
)LJ�����: Diagrammi di flusso di procedure necessarie al corretto funzionamento dell’agente ricerca
������ 3.,�FRQ�VWUXWWXUD�GLVWULEXLWD
Nel caso di organizzazione distribuita delle PKI vengono utilizzati gli
DJHQWL�UHSRVLWRU\, nei quali come indicato nel paragrafo 7.6.2 si inseriscono gli
identificativi delle CA che man mano si esplorano.
L’applicazione utente principale, come indicata in figura 8.4, inserisce
nell’DJHQWH�UHSRVLWRU\ un identificativo per la prima CA che si andrà a visitare e
genera il primo DJHQWH�ULFHUFD che inizia il processo di recupero a partire dalla
directory di questa CA. L'applicazione resterà in attesa del ritorno di un agente.
Le variabili 1),*/, e $*(17(,'3$'5( hanno lo stesso significato del caso di
organizzazione gerarchica delle PKI.
Come indicato in figura 8.5, l'agente di ricerca una volta arrivato nel place
di destinazione, controlla se tra i certificati contenuti nella directory c'è quello di
Bob; se lo trova richiede al rispettivo server OCSP lo stato corrente del
certificato, ricevuta una risposta firmata l'agente ritorna con successo al place
d'origine di Alice riportando con sé il certificato di Bob e la risposta firmata che
ne attesta lo stato di revoca.
Page 117
109
)LJ�����: Diagramma di flusso dell’applicazione nel caso di organizzazione distribuita delle PKI
Nel caso il certificato di Bob non è presente nella directory, per avere
disponibile un cammino di certificazione che garantisca l'autenticità del
certificato di Bob, l'agente recupera tutti i certificati relative a CA cross-
certificate, selezionando solo quelli non presenti nel repository. Per ognuno dei
selezionati richiede lo stato di revoca al server OCSP, per ciascun certificato
valido inserisce nel repository un identificativo per la CA cui è riferito, genera un
nuovo agente di ricerca che invia nel place dove è situata la directory della CA;
nell'ultimo place individuato si porterà lo stesso agente genitore. Lo schema di
funzionamento è indicato in figura 8.5.
Le procedure RITROVATO, FINISCI ESECUZIONE e RISULTATO
RICERCA sono le stesse del caso di organizzazione gerarchica delle PKI,
indicate in figura 8.3.
Page 118
)LJ�����: Diagramma di flusso del comportamento dell’agente ricerca una voltaarrivato nel place di destinazione nel caso organizzazione distribuita delle PKI
Page 119
111
Nella realizzazione del sistema si è assunto che tutte le Autorità di
Certificazione coinvolte pubblicano i certificati elettronici secondo lo standard
X.509 v3. In particolare, come indicato in [RFC2459 pag.40 e pag32], per ogni
certificato elettronico riportano nell'estensione Private Internet Extensions
l'indirizo IP del server OCSP dove richiedere lo stato di revoca; inoltre per i
certificati elettronici relativi a CA riportano nell'estensione Subject Alternative
Name l'indirizzo LDAP della directory dove la CA pubblica i suoi certificati.
���� /D�VLFXUH]]D�GHJOL�DJHQWL�ULFHUFD
Gli agenti ricerca possono essere sottoposti ad attacchi passivi ed attivi6
nella rete di comunicazione e nei place di esecuzione.
Le informazioni trasportate dall'agente (certificati elettronici e stati di
revoca) sono pubbliche e quindi la protezione da attacchi passivi, può essere
trascurata.
La protezione dagli attacchi attivi deve, invece, essere considerata;
analizziamo separatamente i rischi possibili a seconda in cui il pericolo proviene
dalla rete di trasmissione o dai place di esecuzione.
������ 3URWH]LRQH�VXOOD�UHWH�GL�FRPXQLFD]LRQH
Tutte le informazioni reperite nei vari place (certificati elettronici e stati di
revoca) sono firmate dalla CA responsabile e quindi ogni possibile alterazione
viene individuata all'atto del controllo della firma. Inoltre in SOMA è garantita
l'integrità dell'agente nello spostamento.
������ 3URWH]LRQH�QHL�SODFH�GL�HVHFX]LRQH
Qualora le informazioni reperite nei vari place vengono alterate dopo che
la relativa CA li ha firmati allora il problema viene individuato in fase di verifica
della firma.
6 Si definisce attacco passivo un attacco con cui un intrusore intercetta semplicemente un flusso diinformazioni, senza apportare alcun genere di modifiche; con un attacco attivo, invece, l’intrusoreintroduce alterazioni al flusso di dati che possono comprendere modifica del contenuto informativo,eliminazione di tutto o solo di alcune parti del messaggio o trattenimento del messaggio per poi replicarloin tempi successivi.
Page 120
Allorché l'alterazione viene effettuata prima della firma della CA o la
stessa CA fornisce delle informazioni sbagliate è impossibile accorgersi del
problema, bisogna comunque notare che è la CA firmataria a prendersi la
responsabilità di quest'errore.
������ /H�YDULDELOL�LQWHUQH
Le variabili NFIGLI, AGENTEIDPADRE e AGENTEIDFIGLIO sono
necessarie al corretto funzionamento del processo di ricerca ed una loro possibile
alterazione o cancellazione può non far terminare correttamente il processo di
ricerca.
E' importante osservare che se il processo di ricerca termina con
insuccesso questo potrebbe essere dovuto ad un decremento o cancellazione
fraudolenta della variabile NFIGLI, viceversa se il processo di ricerca termina
con successo siamo sicuri del risultato anche in presenza di manomissioni delle
variabili interne.
Una modifica delle variabili interne può portare, in caso di successo, ad
una mancata eliminazione di agenti ricerca non più utili, ma non influenza il
risultato della ricerca.
Garantire l'integrità delle variabili interne è, comunque, auspicabile.
Attualmente non è previsto nessun tipo di protezione per queste variabili e ci si
affida completamente ai meccanismi di sicurezza di SOMA.
���� ,�WHVW�GHOODSSOLFD]LRQH�H�ODQDOLVL�GHOOH�SUHVWD]LRQL
Per verificare la bontà del nostro progetto abbiamo effettuato alcune
sessioni di test, per comprendere le reali prestazioni del sistema realizzato.
Per prima cosa ci siamo dovuti costruire un ambiente per le prove.
All'interno del Centro di Calcolo (CCIB) e del LAB2 della Facoltà di Ingegneria
si sono installate diverse e distinte Infrastrutture a chiave pubblica (PKI) per
simulare un'organizzazione multipla di PKI.
L'organizzazione di PKI costruita può essere vista come una struttura
gerarchica di PKI con radice la PKI1 e le altre subordinate in sequenza.
Page 121
113
L'applicazione test scelta è stata quindi quella per organizzazioni gerarchiche di
PKI.
Il servizio OCSP non era disponibile ed è stato per questo simulato
attraverso un server che ad ogni richiesta fornisce una risposta secondo il formato
nel draft OCSP [RFC2560].
)LJ�����: Organizzazione delle PKI, realizzata per la fase di test
Per valutare meglio l'efficienza del sistema progettato abbiamo realizzato
altre tre applicazioni di confronto:
• Un sistema client-server che effettua le stesse operazioni della nostra
applicazione, ma invece di richiedere le informazioni alle PKI tramite
Agenti Mobili, effettua delle richieste remote LDAP o OCSP.
• Un sistema ad Agenti Mobili che non effettua delle richieste OCSP,
ma recupera la relativa lista di revoca CRL di ogni certificato utile.
• Un sistema client-server che recupera le liste di revoca CRL e non
effettua richieste OCSP.
L'ambiente di prova descritto in figura 8.6 è così configurato:
♦ la postazione di Alice, da dove partirà l'esecuzione dell'applicazione, è
su un PC Pentium 133 Mhz dotato di 32 Mb di RAM;
♦ la PKI1 è installata su un PC Pentium II 233 Mhz dotato di 128 Mb di
RAM;
♦ la PKI2 è installata su un PC Pentium II 233 Mhz con 64 Mb di RAM;
PKI1 PKI2 PKI3 PKI4
Page 122
♦ la PKI3 è installata su un PC Pentium II 233 Mhz dotato di 128 Mb di
RAM;
♦ la PKI4 è installata su un PC Pentium II 233 Mhz con 64 Mb di RAM;
Tutti i PC sono connessi mediante una LAN di tipo Ethernet a 10
Mbit/sec. Il supporto ad agenti mobili SOMA è stato configurato su tutti i PC
definendo per ognuno un place di esecuzione.
Il certificato di Bob è stato inserito inizialmente nella PKI1 si sono
effettuati i test delle quattro applicazioni e raccolti i risultati; poi si è eliminato il
certificato di Bob dalla PKI1 ed inserito nella PKI2 misurando le prestazioni
delle diverse applicazioni in questa situazione; successivamente si è spostato il
certificato di Bob nella PKI3 testando nuovamente le quattro applicazioni; infine
si è spostato il certificato di Bob nella PKI4 misurando le nuove prestazioni delle
diverse applicazioni. Come ultima situazione di test per le quattro applicazioni
non si è inserito il certificato di Bob in nessuna PKI simulando il caso in cui il
certificato di Bob non è presente e quindi non può essere recuperato.
Si è voluto in questo modo verificare le prestazioni dell'applicazione al
variare delle PKI visitate.
I risultati ottenuti dalle diverse applicazioni test sono riportati in tabella
8.1. Le misure indicano i tempi medi di recupero del certificato di Bob per
ciascuna delle quattro applicazioni al variare delle PKI visitate.
Da una prima analisi dei risultati osserviamo che tutti i tempi di recupero
per qualunque applicazione sono dell'ordine delle decine di secondi, quindi tempi
accettabilissimi per un utente umano. Questo dimostra l'effettiva bontà degli
algoritmi di ricerca utilizzati indipendentemente dal modello di comunicazione
adottato o dai servizi disponibili.
Riportando i risultati su di un grafico, possiamo osservare l'andamento dei
tempi di recupero al variare del numero di PKI visitate, per ciascuna applicazione
test.
Page 123
115
Tempi di risposta in secondi
Certificato di BobPresente nella:
Applicazionead AgentiMobili conserver OCSP
ApplicazioneClient Servercon serverOCSP
AgentiMobili inassenza delserver OCSP
Client Serverin assenza delserver OCSP
PKI1 1,532 7,111 1,663 7,581
PKI2 2,674 9,183 2,874 9,664
PKI3 3,665 11,496 4,176 12,67
PKI4 4,696 13,798 5,496 15,824Non presentein nessuna PKI 4,607 12,234 4,987 13,966
7DE�����: Risultati delle prove effettuate
)LJ�����: Grafici dei tempi di esecuzione in funzione del numero di PKI coinvolte nella ricerca
Tali grafici mostrano come le soluzioni di tipo client-server abbia sempre
prestazioni nettamente inferiori rispetto a quella ad agenti mobili. Si può notare
come la pendenza delle rette nei casi client-server sia molto più accentuata
rispetto alle applicazioni ad Agenti Mobili. Ciò significa che le soluzioni client-
�
�
��
�
��
����
��
��
� � � �
1XPHUR�3.,�YLVLWDWH
7HP
SR��VH
F�
$JHQWL�0RELOLFRQ�2&63
&OLHQW�6HUYHUFRQ�2&63
$JHQWL�0RELOLVHQ]D�2&63
&OLHQW�6HUYHUVHQ]D�2&63
Page 124
server sono molto dipendenti dal numero di PKI visitate, mentre quelle ad Agenti
Mobili ne dipendono in maniera più limitata.
In generale la presenza del server OCSP migliora le prestazioni del
sistema ed è quindi auspicabile un suo utilizzo, rispetto alle tradizionali CRL.
In conclusione l'applicazione che ha le migliori prestazioni è quella ad
Agenti Mobili che sfrutta i server OCSP.
Page 125
117
&DSLWROR����&21&/86,21,
Il recupero e la convalida dei certificati elettronici rappresenta una delle
procedure più complesse nella progettazione e gestione di una infrastruttura a
chiave pubblica (PKI) su larga scala. Il problema è particolarmente evidente
quando gli interlocutori appartengono a domini di sicurezza differenti collegati
da un ampio cammino di certificazione. Occorre, quindi, disporre di un
meccanismo efficace per costruire e verificare cammini di certificazione in tempi
accettabili.
L’obiettivo principale di questa tesi è stato, pertanto quello di studiare,
progettare e realizzare delle soluzioni efficienti per costruire e convalidare
cammini di certificazione. In particolare, si è evidenziata l'utilità del modello di
esecuzione ad Agenti Mobili per il recupero e la verifica dei certificati elettronici
in ambienti distribuiti su scala globale. Le capacità degli agenti di interagire ed
elaborare le informazioni localmente alle risorse stesse riduce l'utilizzo della rete
rispetto alla soluzione classica basata sul modello client/server comportando una
diminuzione dei tempi di trasferimento e quindi di recupero e verifica dei
certificati.
Si è pertanto realizzato un’applicazione basata sugli agenti mobili per il
recupero di certificati e la si è confrontata in termini di efficienza con un’analoga
applicazione progettata sulla base del classico modello client/server per
confrontare. La realizzazione di entrambe le applicazioni, ad agenti e basata sul
modello client/server, ha esplorato la possibilità di utilizzare per la verifica dello
stato di revoca dei certificati sia le tradizionali liste di revoca (CRL) sia il
servizio di verifica on-line (OCSP).
I risultati sperimentali hanno mostrato che il modello ad agenti mobili è il
più efficiente ed hanno confermato l’utilità degli agenti per la ricerca e la
convalida dei cammini di certificazione. Inoltre i risultati hanno evidenziato che
l’utilizzo del servizio on-line di verifica comporta un incremento delle
prestazioni dell’applicazione ad agenti mobili. I vantaggi sono dovuti alle
Page 126
dimensioni ridotte delle risposte OCSP rispetto alle CRL che determinano una
diminuzione dei tempi di trasferimento.
Il lavoro iniziato con questa tesi può essere esteso in varie direzioni. Un
primo possibile e importante sviluppo del nostro sistema potrebbe essere
rappresentato dall'introduzione della verifica della firma sui certificati all'atto del
loro reperimento e non più solo dall'utente finale. Questa estensione, tuttavia,
richiederebbe all'agente mobile di portare con sé le chiavi pubbliche di verifica e
gli algoritmi di controllo e questo sarebbe possibile solo se l'ambiente di
esecuzione dove avviene la verifica della firma fosse sicuro e fidato. Altre
eventuali estensioni derivano dalla possibilità di definire politiche di recupero dei
certificati a livello utente e dall'introduzione di un servizio di cache dove
memorizzare i cammini di certificazione più richiesti o parte di essi.
Page 127
119
$SSHQGLFH��$&&(662�$�',5(&725<�(/,1*8$**,2�-$9$���-1',�
I servizi di directory vengono sempre di più usati in ambienti come
Internet e Intranet per accedere a informazioni di varia natura come utenti,
applicazioni, hardware, servizi ed altro.
Un linguaggio moderno che intenda proporsi come standard per la
programmazione di rete e la realizzazione di applicazioni per il Web deve quindi
consentire l'accesso ai sistemi di directory.
Il linguaggio Java risponde a questa esigenza e aggiunge alla gerarchia di
classi base una Application Programming Interface (API) per l'accesso ai sistemi
di directory che prende il nome di Java Naming and Directory Interface (JNDI).
L'API ha l'obiettivo di costituire un'interfaccia comune, uniforme e
trasparente per tutti i sistemi di Directory, secondo la ben nota filosofia del
linguaggio Java "write once, run anywhere".
Molti sviluppatori di applicazioni Java potranno beneficiare di JNDI API
che non solo è indipendente dal particolare Directory Server, ma fornisce gli
strumenti necessari per la gestione degli oggetti memorizzati.
L'interfaccia è di basso livello e costituisce la base per la costruzione di
semplici applicazioni o interfacce di livello superiore che realizzano una
maggiore astrazione.
L'indipendenza delle API dal particolare tipo di servizio di directory usato
(come LDAP, NDS o NIS) è dovuta a un gruppo di interfacce Java che vengono
implementate da un driver; questo driver si prende cura di tradurre le chiamate
JNDI standard in chiamate specifiche richieste dal Directory Server che supporta.
L'applicazione viene scritta una sola volta e poi viene inviata ai vari
driver; questo significa che l'applicazione rimane sempre la stessa, mentre sono i
driver a cambiare.
Page 128
L'architettura base di JNDI è quella mostrata nella figura seguente.
L'indipendenza delle API dal particolare tipo di servizio di directory usato
(come LDAP, NDS o NIS) è dovuta a un gruppo di interfacce Java che vengono
implementate da un driver; questo driver si prende cura di tradurre le chiamate
JNDI standard in chiamate specifiche richieste dal Directory Server che supporta.
L'applicazione viene scritta una sola volta e poi viene inviata ai vari
driver; questo significa che l'applicazione rimane sempre la stessa, mentre sono i
driver a cambiare.
L'implementazione concreta dell'interfaccia si basa proprio su questi
driver specifici per i singoli sistemi di directory che vengono registrati presso il
JNDI Implementation Manager.
E' importante notare che un applicazione realizzata con JNDI potrà essere
utilizzata non solo con i servizi di directory attualmente disponibili, ma anche
con i futuri. Basterà infatti che il produttore del nuovo directory server renda
disponibile un driver JNDI che può realizzare facilmente attraverso le JNDI SPI
(Service Provider Interface).
Page 129
121
Le JNDI API sono composte da due package:
• MDYD[�QDPLQJ
• MDYD[�QDPLQJ�GLUHFWRU\
Il JNDI Service Provider (SPI) è contenuto nel package:
• MDYD[�QDPLQJ�VSL
Il package MDYD[�QDPLQJ fornisce tutte le funzioni di naming e multiple
naming che consentono di guardare un oggetto a partire dal suo nome. Questo
package è fondamentale in quanto un sistema di directory deve includere al suo
interno delle funzioni di naming per permettere agli utenti di identificare le varie
entità disponibili.
Il package MDYD[�QDPLQJ�VSL fornisce tutti gli strumenti attraverso i quali i
diversi produttori di Naming/Directory Service possono sviluppare e rendere
disponibile i rispettivi driver JNDI. Questo permette ai loro servizi di essere
accessibili dalle applicazioni che usano JNDI, in maniera trasparente.
Il package MDYD[�QDPLQJ�GLUHFWRU\ permette di accedere ai diversi
Directory Service in maniera uniforme. Estende il package MDYD[�QDPLQJ
fornendo tutte le funzioni necessarie per interagire con le directory in aggiunta ai
servizi di naming. Permette alle applicazioni che lo utilizzano di recuperare gli
oggetti memorizzati nelle directory, esaminare e modificare i suoi attributi.
Fornisce funzioni per aggiungere o eliminare oggetti dalla directory e filtri per
ricerche su specifici attributi.
Attraverso l'interfaccia 'LU&RQWH[W si definisce il contesto della directory
necessario all'implementazione concreta.� 'LU&RQWH[W fornisce i metodi per
recuperare, aggiornare, cancellare e aggiungere attributi associati agli oggetti
memorizzati nella directory. In particolare il metodo JHW$WWULEXWHV�� restituisce gli
attributi associati con un oggetto contenuto nella directory.
La ricerca degli oggetti memorizzati è molto semplificata dall'utilizzo del
metodo VHDUFK�� che permette di elaborare da semplici e comuni ricerche base a
sofisticate e multiple ricerche complesse, attraverso l'indicazione di un filtro di
ricerca dove si specificano le caratteristiche che gli oggetti e i loro attributi
devono soddisfare.
L'integrazione tra JNDI e LDAP è totale, gli sviluppatori possono
produrre tutte le query disponibili da LDAP v3 attraverso l'interfaccia JNDI.
Page 130
Tutte le operazioni LDAP sono mappate in funzioni JNDI, esiste inoltre una
corrispondenza tra le JNDI Exceptions e gli LDAP Status Code.
JNDI fornisce tutti gli strumenti di sicurezza richiesti da LDAP come ad
esempio i metodi di autenticazione.
Page 131
123
%,%%/,2*5$),$
[AMO93] R.K. Ahuja, T.L. Magnanti, J.B. Orlin, "Network Flows",
Prentice-Hall, Englewood Cliffs, New Jersey, 1993
[AZ98] C. Adams & R. Zuccherato, "A General, Flexible
Approach to Certificate Revocation", Entrust
Technologies, Luglio 1998.
[CDK94] G.Coulouris, J.Dollimore, T.KindBerg, “Distribuited
Systems: Concepts and Design”, Addison-Wesley, 1994.
[CG89] N. Carriego, D. Gelernter: “Linda in Context”,
Comunication of ACM, vol. 32, n°4, April 1989.
[CGPV97] G. Cugola, C. Ghezzi, G.P. Picco, G. Vigna, “Analyzing
Mobile Code Languages”, 1997.
[CHA96] D.W. Chadwick, “Understanding X.500 - The
Directory”,
http://www.salford.ac.uk/its024/VersionWeb/Contents.htm,
1996.
[CHK95] D. Chees, C. Harrison, A. Kershenbaum, “Mobile
Agents: Are They a Good Idea?”, 1995
[Cav99]
[Coc98]
[Chi98]
[CMT79] N. Christofides, A. Mingazzi, P. Toth, C. Sandi, eds.,
"Combinatorial Optimization", Wiley, New York, 1979
[CORBA] R. Orfali and D. Harkey: “Client/Server Programming
Page 132
with JAVA and CORBA” WileyComputer Publishing,
1997
[CPV97] A. Carzaniga, G.P. Picco, G. Vigna, “Designing
Distributed Applications with Mobile Code Paradigms”,
in Proc. of the 19th Int. Conf. on Software Engineerine
(ICSE’97), R. Taylor, Ed. 1997, pp. 22–32, ACM Press.
[CUR95] I. Curry, "The concept of trust in network security",
Entrust Technologies White Paper, Dicembre 1995.
[DH76] W.Diffie, M. Hellman, "New directions in
cryptography", in IEEE Transactions on Information
Theory, vol. 22 (1976), pp. 644-654, 1976.
[DIR] THE DIRECTORY. CCITT RECOMMENDATION
X.500-X.521 | ISO/IEC STANDARD 9594
X.500 | 9594.Part 1 Overview of Concepts, Models
and Services
X.501 | 9594.Part 2 Models
X.511 | 9594.Part 3 Abstract Service Definition
X.518 | 9594.Part 4 Procedures for Distributed
Operations
X.519 | 9594.Part 5 Protocol Specifications
X.520 | 9594.Part 6 Selected Attribute Types
X.521 | 9594.Part 7 Selected Object Classes
X.509 | 9594.Part 8 Authentication Framework
X.525 | 9594.Part 9 Replication.
Page 133
125
[F94] W. Ford, "The need for separete key pairs for symmetric
key transfer and digital signature", Febbraio 1994.
[FAQC98] "Frequently asked questions about today’s cryptography",
RSA Laboratories, 1998.
[FPV98] A. Fuggetta, G.P. Picco and G. Vigna “Understanding
Code Mobility”, IEEE Transactions on Software
Engineering, 1998.
[Gong97] Li Gong, M. Mueller, H. Prafullchandra, R. Schemers:
“Going Beyond the Sandbox: An Overview of the New
Security Architecture in the Java Development Kit 1.2”,
in Proceedings of the USENIX Symposium on Internet
Technologies and Systems, Monterey, California,
Dicembre. 1997
[Gong98] Li Gong: “Java Security Architecture (jdk1.2)”, Ottobre
1998
[IBM96] D.B. Lange and Daniel T. Chang, “Programming Mobile
Agents in Java, A White Paper”, Settembre 1996
[KPS95] C. Kaufman, R. Perlman, M. Speciner, “Network
Security, Private Comunication in a Public World”, 1995
[KT98] N.M. Karnik, A.R. Tripathi: “Design Issues in Mobile-
Agent Programming Systems”, IEEE Concurrency, 1998
[LA97] D.B. Lange, Y. Aridor: “Agent Transfer Protocol –
ATP/0.1”, Draft 4, IBM Tokyo Research Laboratory,
Marzo 1997
Page 134
[LC96] D.B. Lange, D.T. Chang: “IBM Aglets Workbench”,
Draft , IBM Corporation, Settembre 1996
[LDAPv3] D.W.Chadwick, "Internet X.509 Public Key
Infrastructure Operational Protocols - LDAPv3", PKIX
Working Group 'UDIW, Agosto 1999.
[JAVA]
[JNDI]
[MKO98] M. Oshima, G. Karjoth, K. Ono: “Aglets Specification
1.1”, Draft 0.65 , Settembre 1998
[Nie98] O. Nierstrasz, “An Introduction to Java”, Software
Composition Group Institut fur Informatik (IAM)
Universitat Bern, 1998
[OBJ97] “ObjectSpace Voyager Core Package Technical
Overwiew”, ObjectSpace press, Dicembre 1997
[OBJ97a] “Voyager Core Package Thecnical Overwiew”,
ObjectSpace press, Marzo 1997
[OBJ97b] “ObjectSpace Voyager, General Magic Odyssey, IBM
Aglets: a Comparison”, ObjectSpace press, Giugno 1997
[OBJ98] “ObjectSpace Voyager Core Technology 2.0”,
http://www.objectspace.com, 1998
[Odi98] “Introduction to the Odyssey API”, General Magic, 1998.
Page 135
127
[Pro99]
[RFC1424] B. Kaliski, “ Privacy Enhancement for Internet Electronic
Mail - Part IV: Key Certification and Related Services”,
Request for Comments 1424, Febbraio 1993.
[RFC1777] W. Yeong, T. Howes, S. Kille, "Lightweight Directory
Access Protocol", Request for Comments 1777, Marzo
1995.
[RFC2459] R.Housley, W. Ford, W. Polk, D. Solo, "Internet X.509
Public Key Infrastructure - Certificate and CRL Profile",
Request for Comments 2459, Gennaio 1993.
[RFC2559] S. Boeyen, T. Howes, P. Richard, "Internet X.509 Public
Key Infrastructure Operational Protocols - LDAPv2",
Request for Comments 2559, April 1999.
[RFC2560] M. Myers, R. Ankney, A. Malpani, S. Galperin,
C.Adams, " X.509 Internet Public Key Infrastructure
Online Certificate Status Protocol - OCSP", Request for
Comments 2560, Marzo 1999.
[RFC954] K. Harrestein, M. Stahl, E. Feinler,
"NICNAME/WHOIS", Request for Comments 954,
Ottobre 1985.
[RMI98] “Remote Method Invocation for Java”, Javasoft
Corporation,
http://chatsubo.javasoft.com/current/rmi/index.html, 1998
[RSA78] R. L. Rivest, A. Shamir, L. Adleman, "A method for
Page 136
obtaining Digital Signature and Public-Key
Cryptosystems", in Communications of the ACM, vol.
21, n.2, pp. 120-126, 1978.
[S96] B. Schneier, "Applied cryptography", John Wiley &
Sons, 1996.
[SOMA] Secure And Open Mobile Agent, Sito web:http://www-lia.deis.unibo.it/Software/SOMA/
[Tar98] F. Tarantino, Tesi di Laurea presso l’Università diBologna, Facoltà di Ingegneria, 1998.
[Ten98] L. Tenti, Tesi di Laurea presso l’Università di
Bologna, Facoltà di Ingegneria, 1998.
[T94] A. S. Tanenbaum “I moderni sistemi operativi”, Prentice
Hall International, Jackson Libri.
[Teles94] Jim White: “Telescript Tecnology: The Fondation for
Electronic Marketplace”, General Magic Inc. Mountain
View (CA), USA, 1994
[WSB98] U.G. Wilhelm, S. Staamann, L. Buttyan: “On the
Problem of Trust in Mobile Agent Systems”,1998
[YCC96] A. Young, N. K. Cicovic, D. Chadwick, “Trust Models in
ICE-TEL”, 1996