UNIVERSITÀ DEGLI STUDI DI CATANIA FACOLTA’ DI INGEGNERIA DIPARTIMENTO ELETTRICO, ELETTRONICO E SISTEMISTICO CRISTIAN RANDIERI TECNICHE DI SOFT COMPUTING PER LA MODELLISTICA DI DATI DI TIPO AMBIENTALE TESI DI LAUREA Relatore: Ch.mo Prof. G. NUNNARI Correlatore: Ing. A. NUCIFORA ANNO ACCADEMICO 1998-99
Transcript
UNIVERSITÀ DEGLI STUDI DI CATANIA
FACOLTA’ DI INGEGNERIA
DIPARTIMENTO ELETTRICO, ELETTRONICO E SISTEMISTICO
CRISTIAN RANDIERI
TECNICHE DI SOFT COMPUTING PER LA
MODELLISTICA DI DATI DI TIPO AMBIENTALE
TESI DI LAUREA
Relatore:
Ch.mo Prof. G. NUNNARI
Correlatore:
Ing. A. NUCIFORA
ANNO ACCADEMICO 1998-99
Ai miei cari genitori Clelia e
Salvatore, che con immensi sacrifici
hanno permesso tutto ciò.
Al Prof. Giuseppe Nunnari, che mi
ha sempre incoraggiato verso
l’affascinante mondo della ricerca.
Nel ricordo del Prof. Victor Rizza,
modello di vita, elemento unico e
geniale.
i
INDICE
1 INTRODUZIONE 1
2 TECNICHE DI TIPO SOFT COMPUTING 4
INTRODUZIONE 4
2.1 LE RETI NEURALI 6
2.1.1 Struttura delle reti neurali 8
2.1.2 Tipi di apprendimento delle reti neurali 10
2.1.3 Reti a separazione lineare 11
2.1.4 Algoritmo di apprendimento di Widrow-Hoff 14
2.1.5 Reti a separazione non lineare 17
2.1.6 Apprendimento delle reti MLP 19
2.1.7 Apprendimento non supervisionato 22
2.2 LA LOGICA FUZZY 24
2.2.1 La teoria dei fuzzy set 25
2.2.2 Variabili linguistiche 27
2.2.3 Funzione di appartenenza 28
2.2.4 Regole fuzzy 29
2.2.5 Sistemi fuzzy 32
2.2.6 Associazione fuzzy input-output 37
2.2.7 Metodi di defuzzificazione 40
2.3 GLI ALGORITMI GENETICI 42
2.4 LE RETI NEURALI CELLULARI 48
2.4.1 Architettura delle reti neurali cellulari (CNN) : Il modello elettrico 48
2.4.2 Stabilità di una rete neurale cellulare 56
2.4.3 Equilibrio stabile di una cella di una CNN 61
2.4.4 Funzionamento circuitale di una CNN 63
2.5 I SISTEMI IBRIDI 66
2.5.1 Fuzzy neural networks (FNNs) 67
3 MODELLISTICA DELL’INQUINAMENTO
ATMOSFERICO TRAMITE TECNICHE DI
SOFT COMPUTING 72
3.1 INTRODUZIONE 72
ii
3.2 PREDIZIONE DELLE CONCENTRAZIONI DEGLI INQUINANTI
ATMOSFERICI IN UNA ZONA AD ALTA DENSITA’ DI
INSEDIAMENTI INDUSTRIALI 79
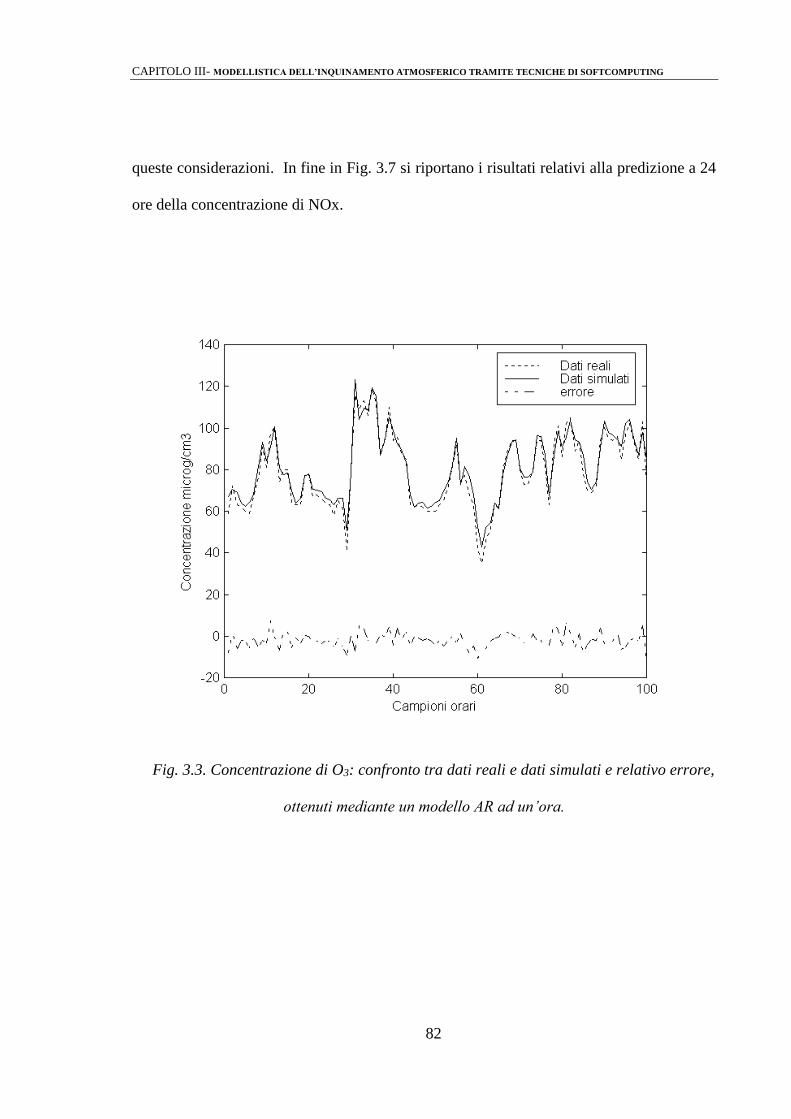
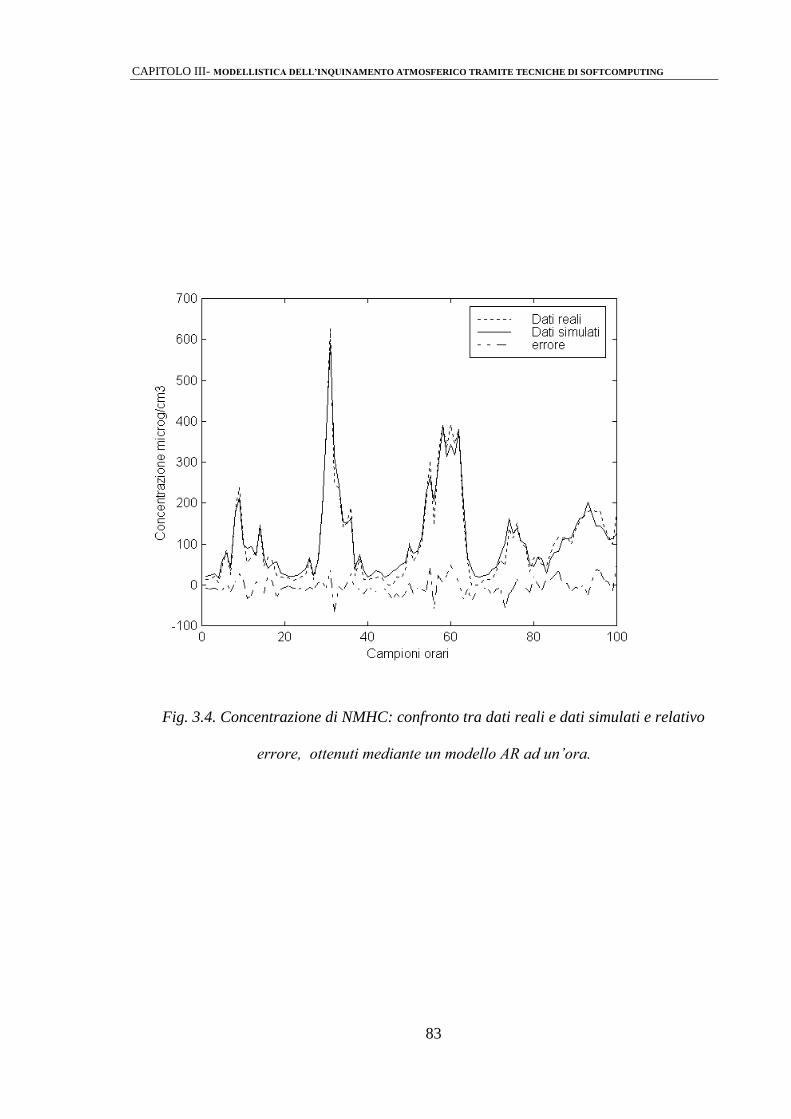
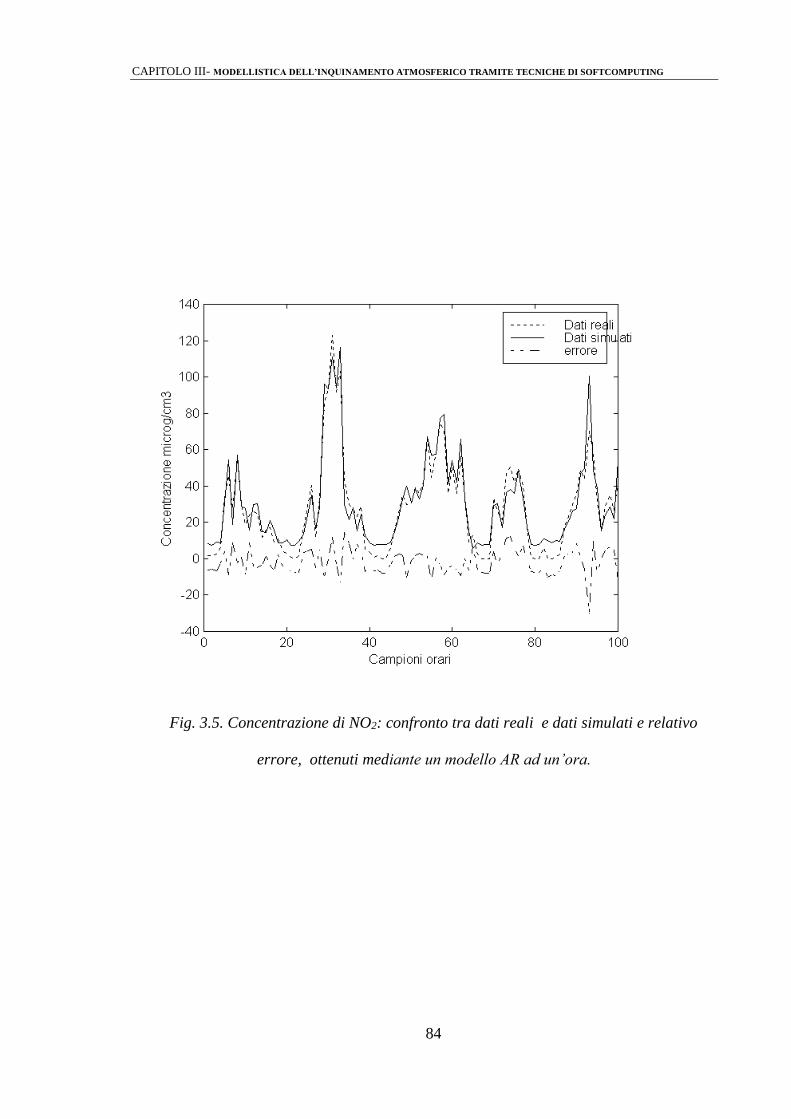
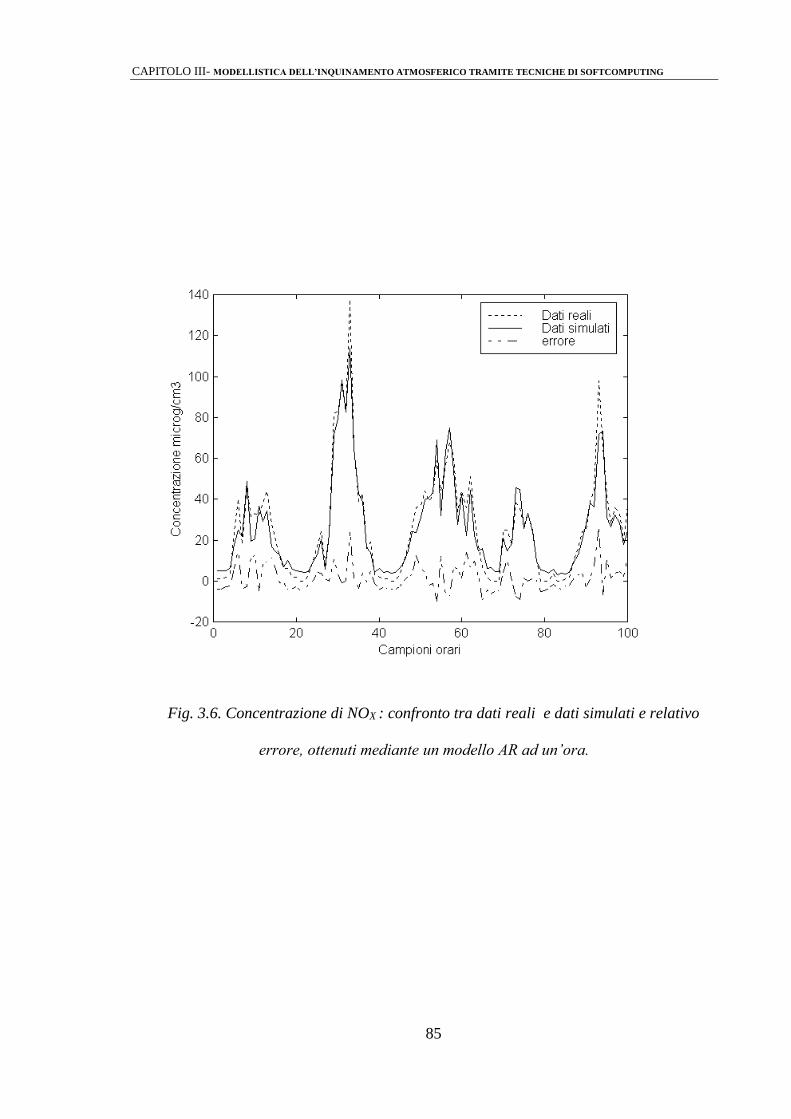
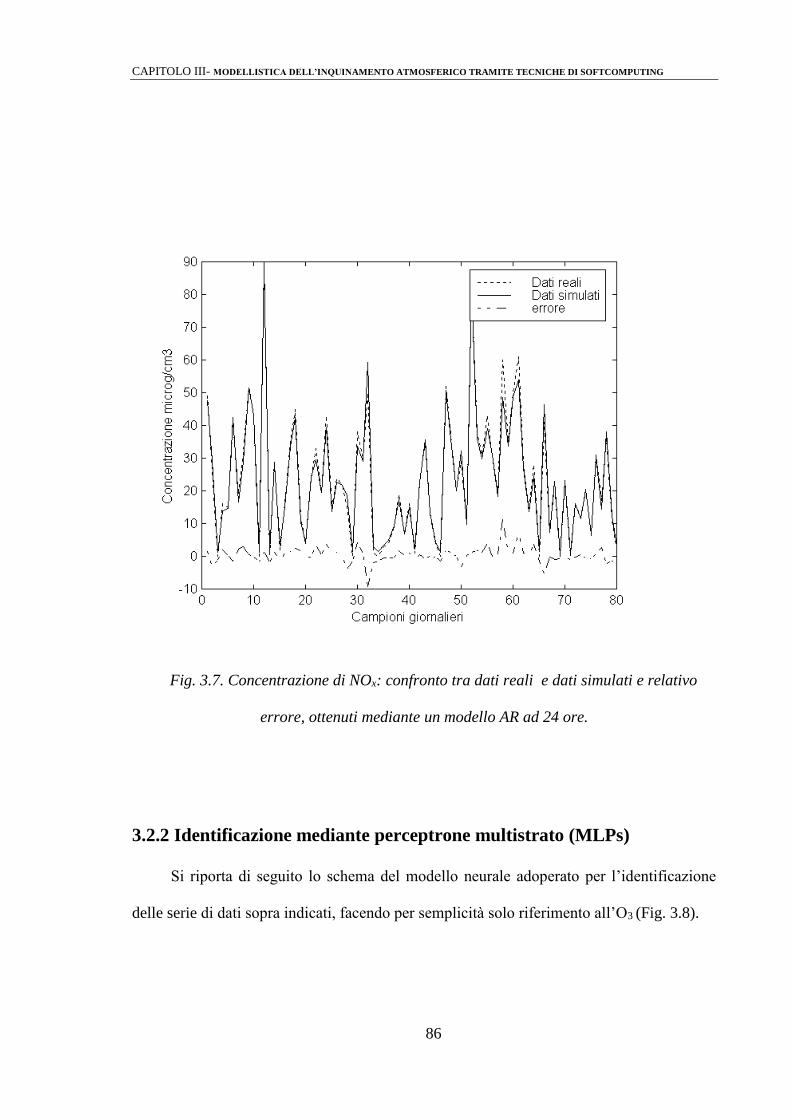
3.2.1 Modelli di predizione mediante strutture di tipo ARMAX 81
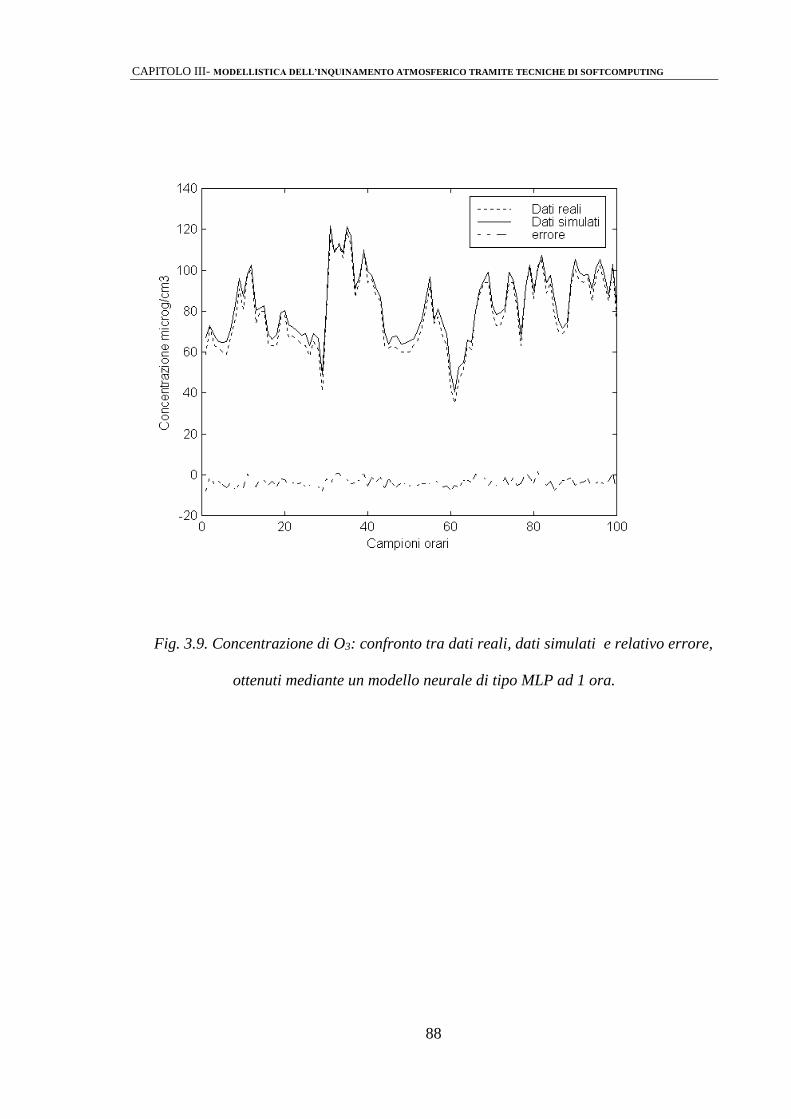
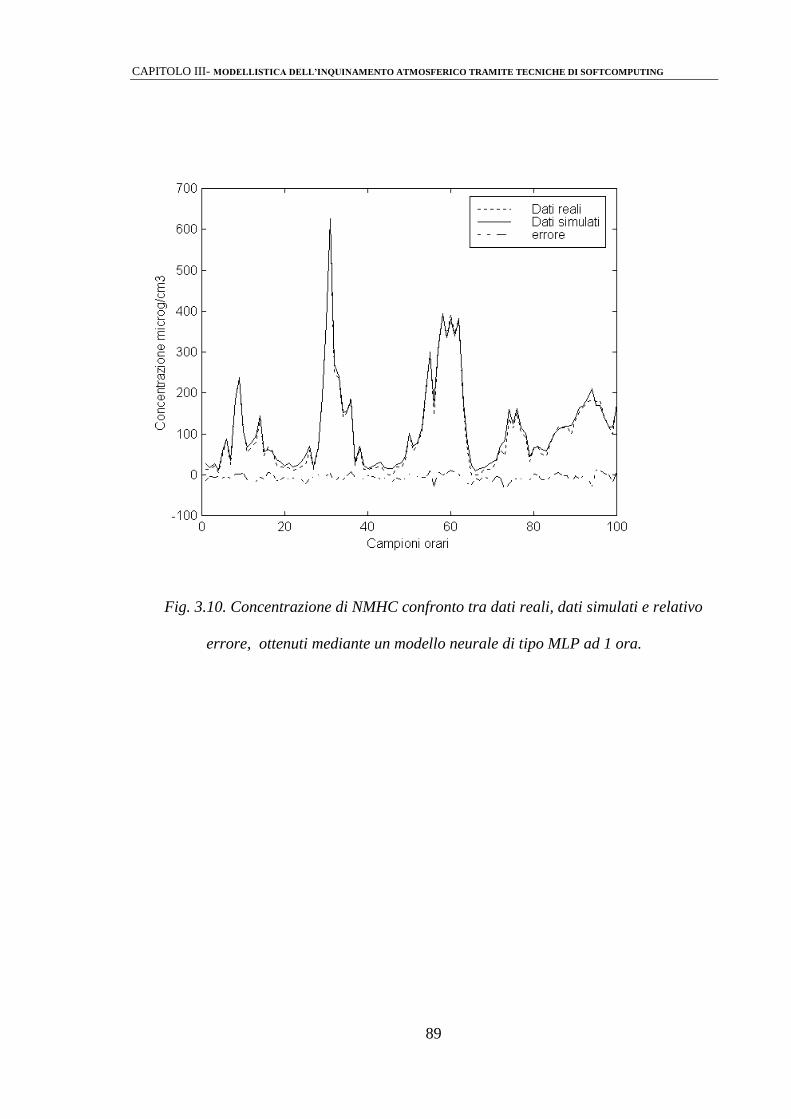
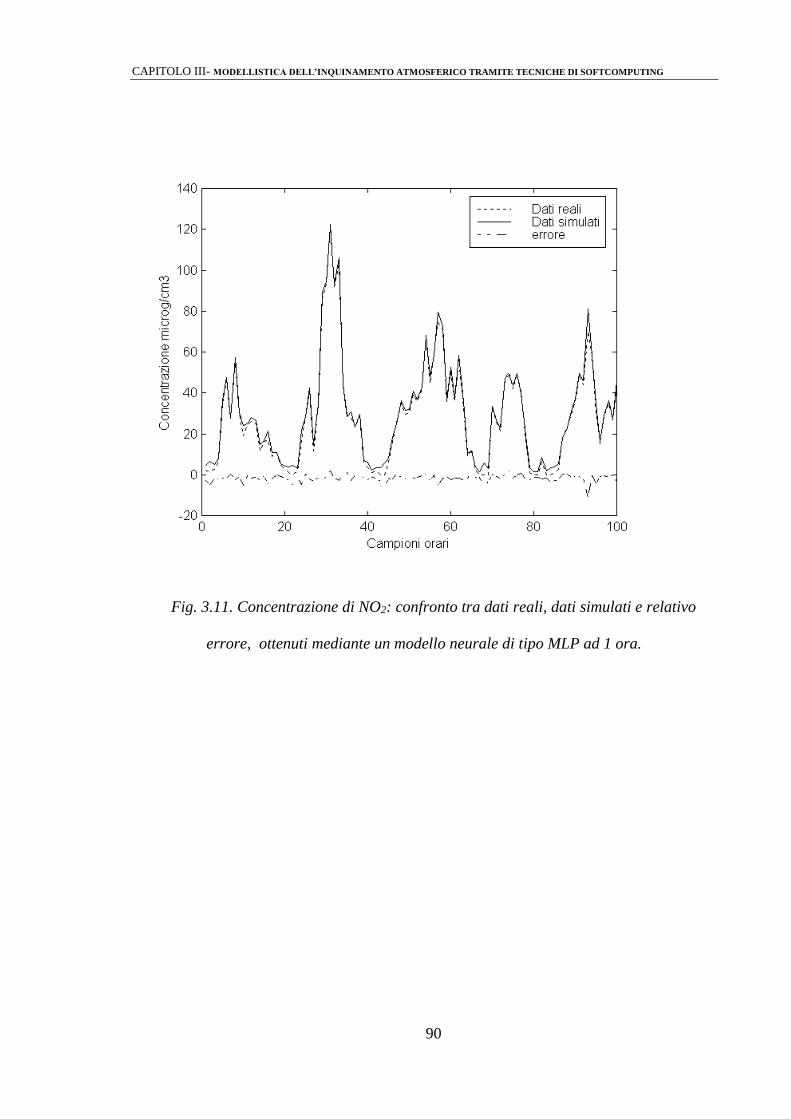
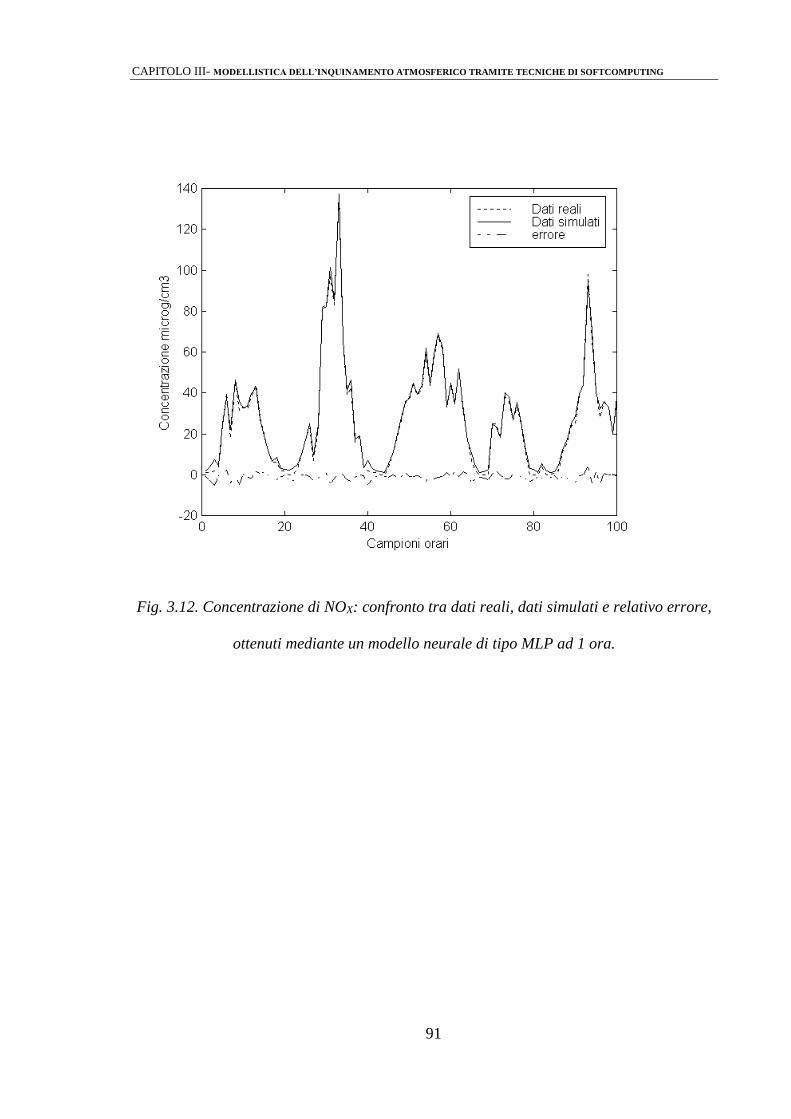
3.2.2 Identificazione mediante perceptrone multistrato (MLPs) 86
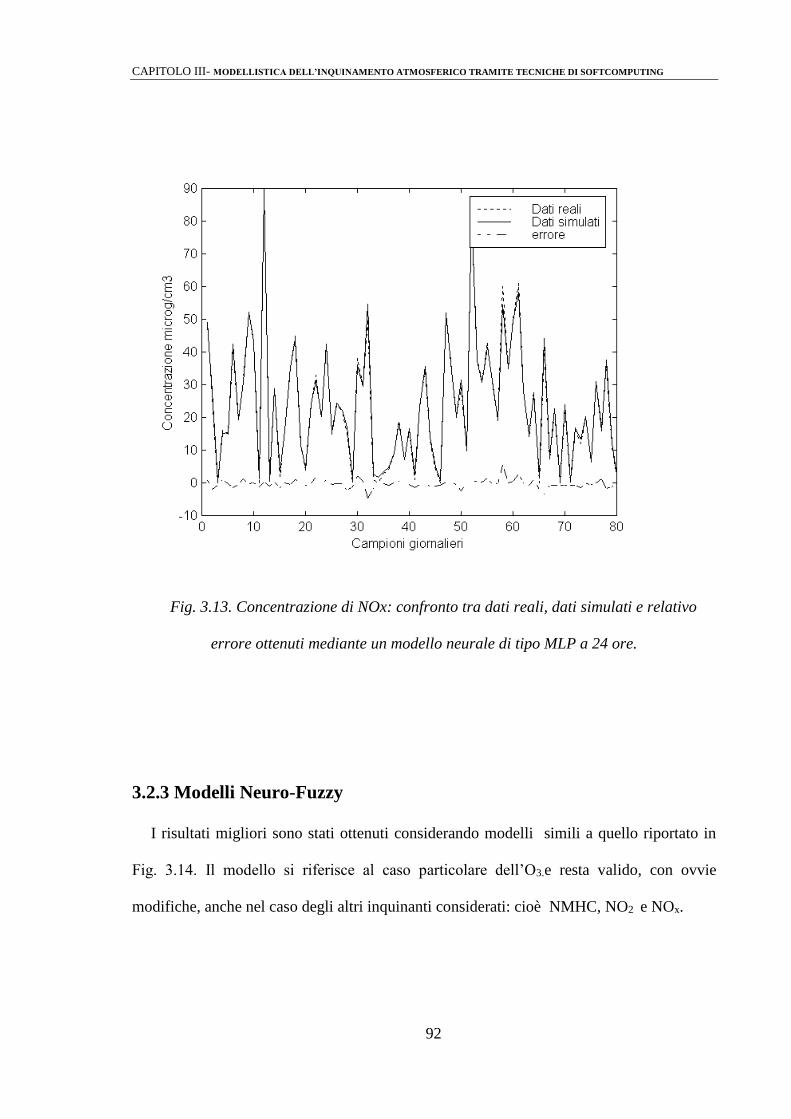
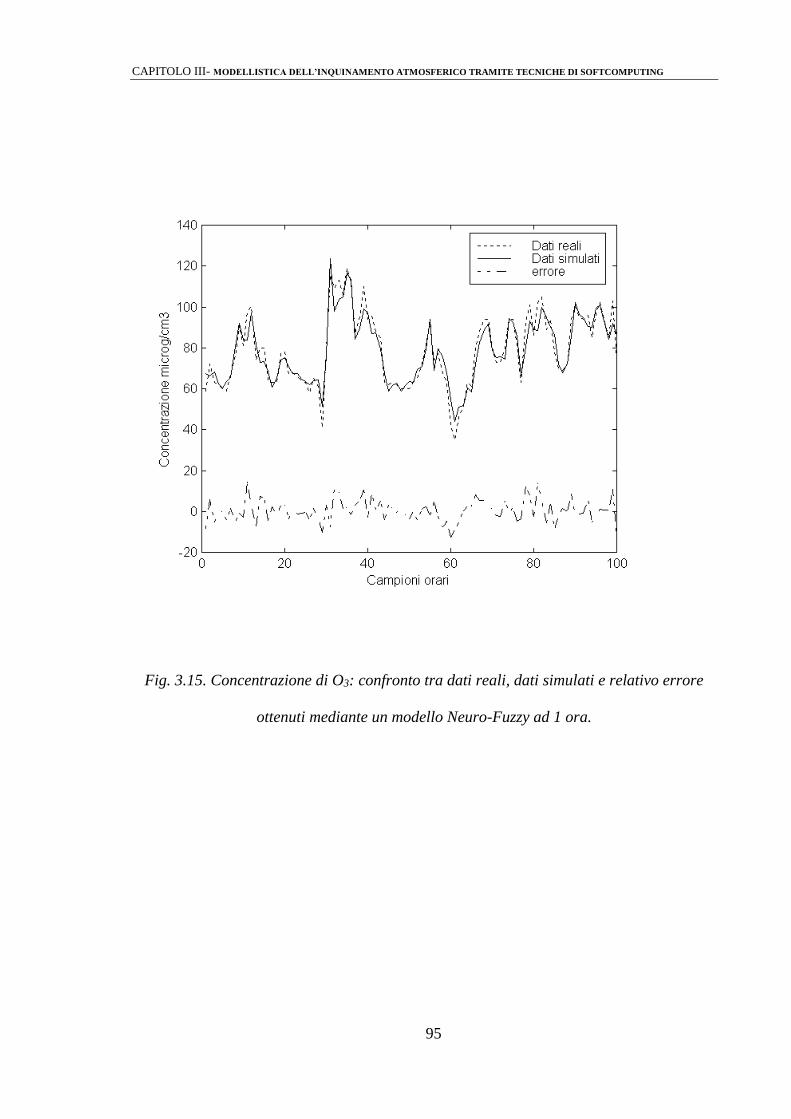
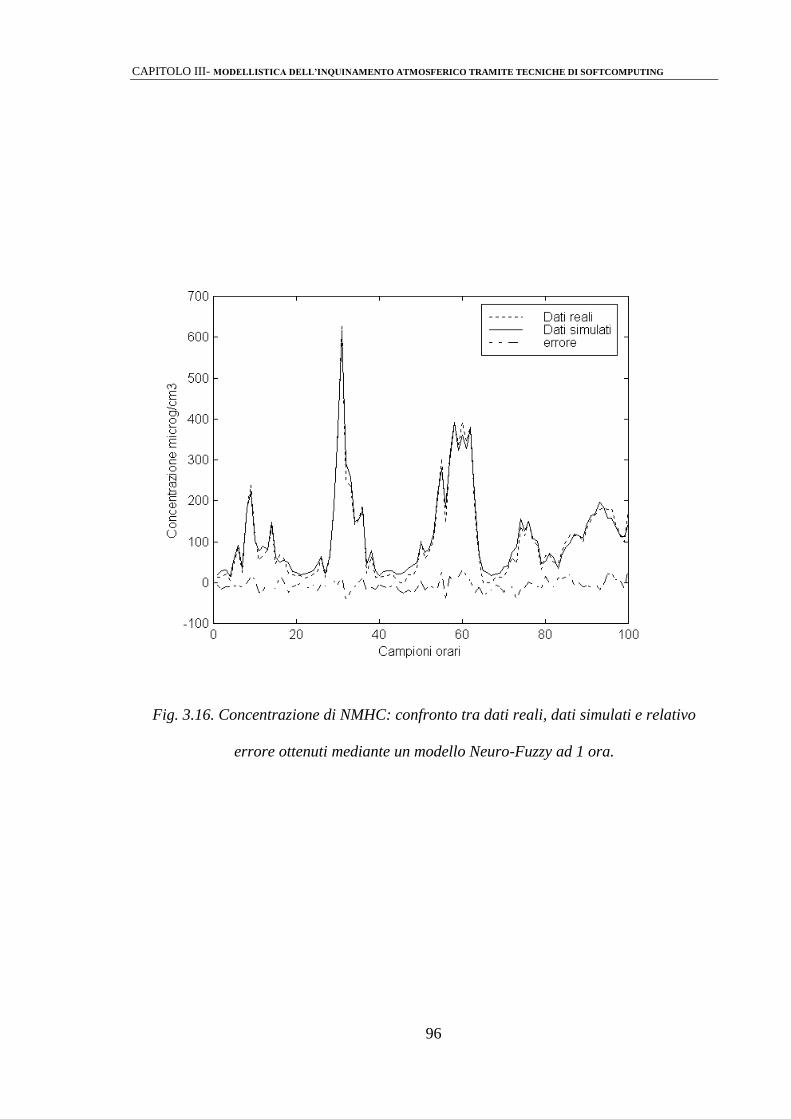
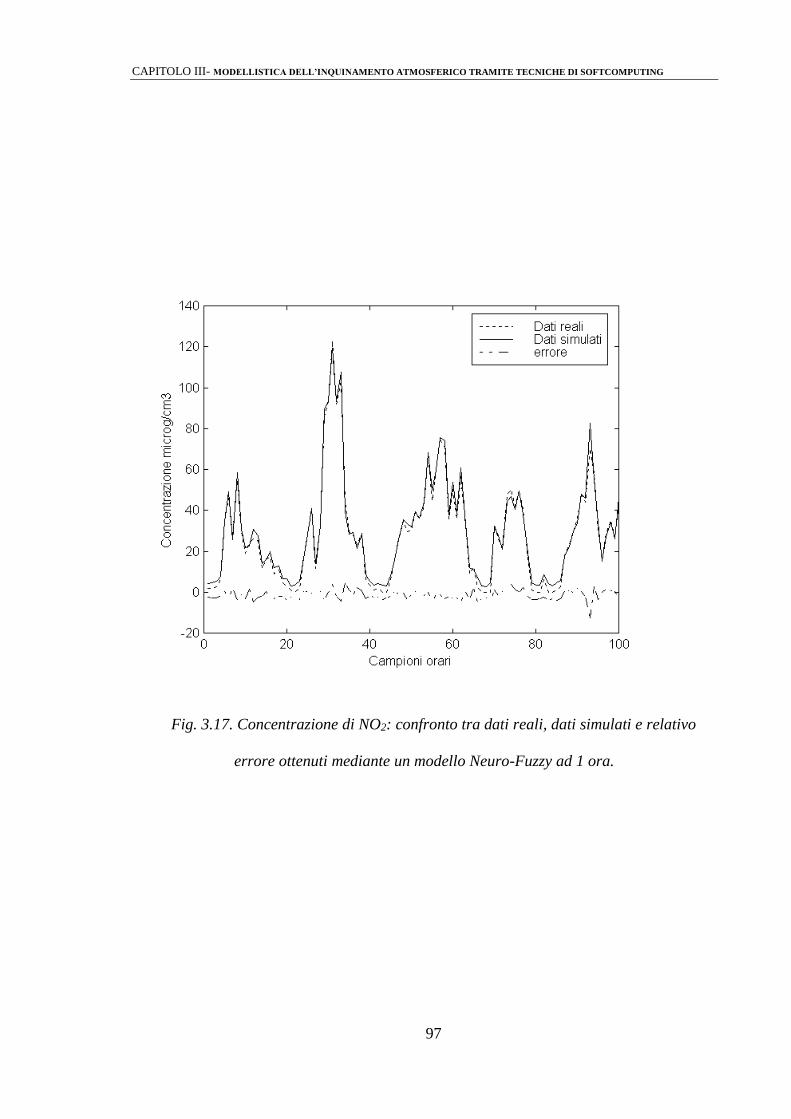
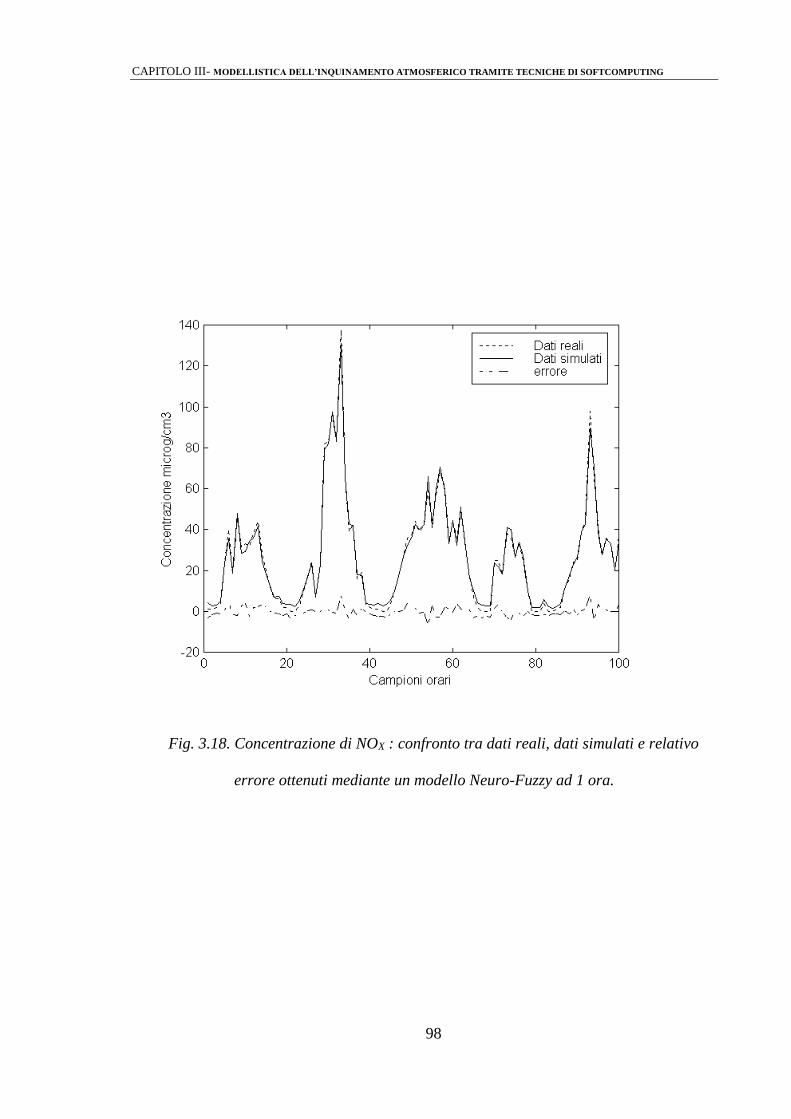
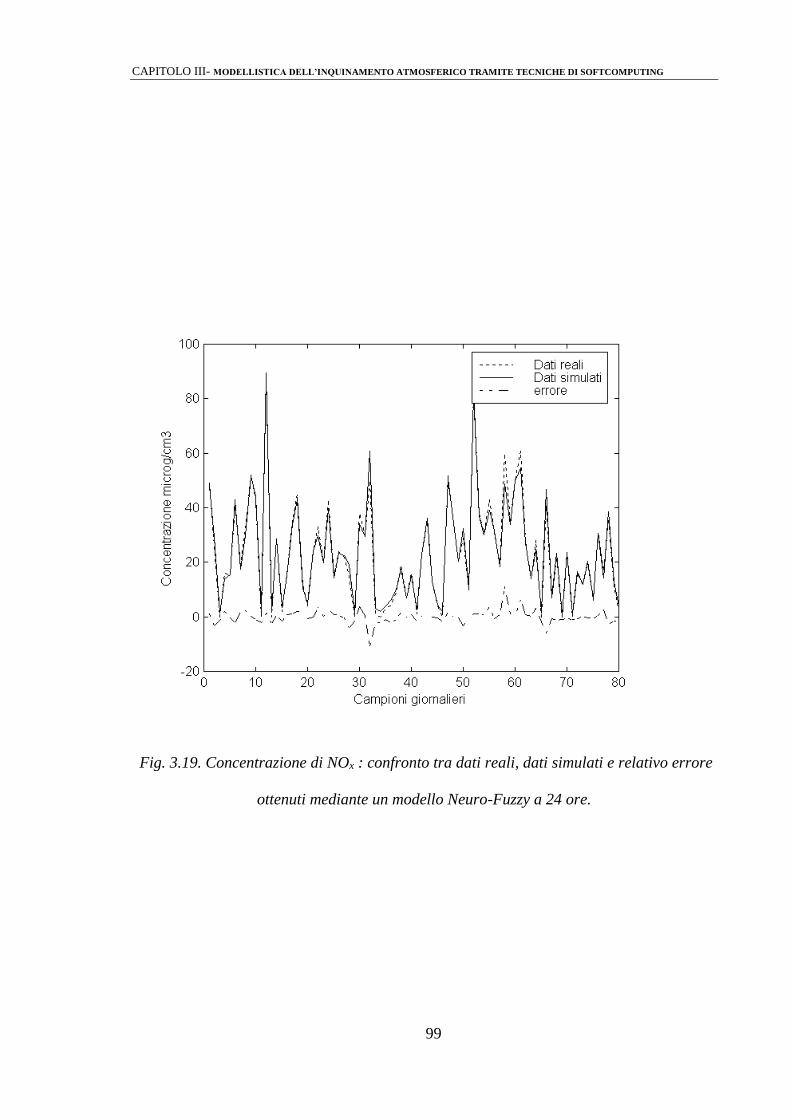
3.2.3 Modelli Neuro-Fuzzy 92
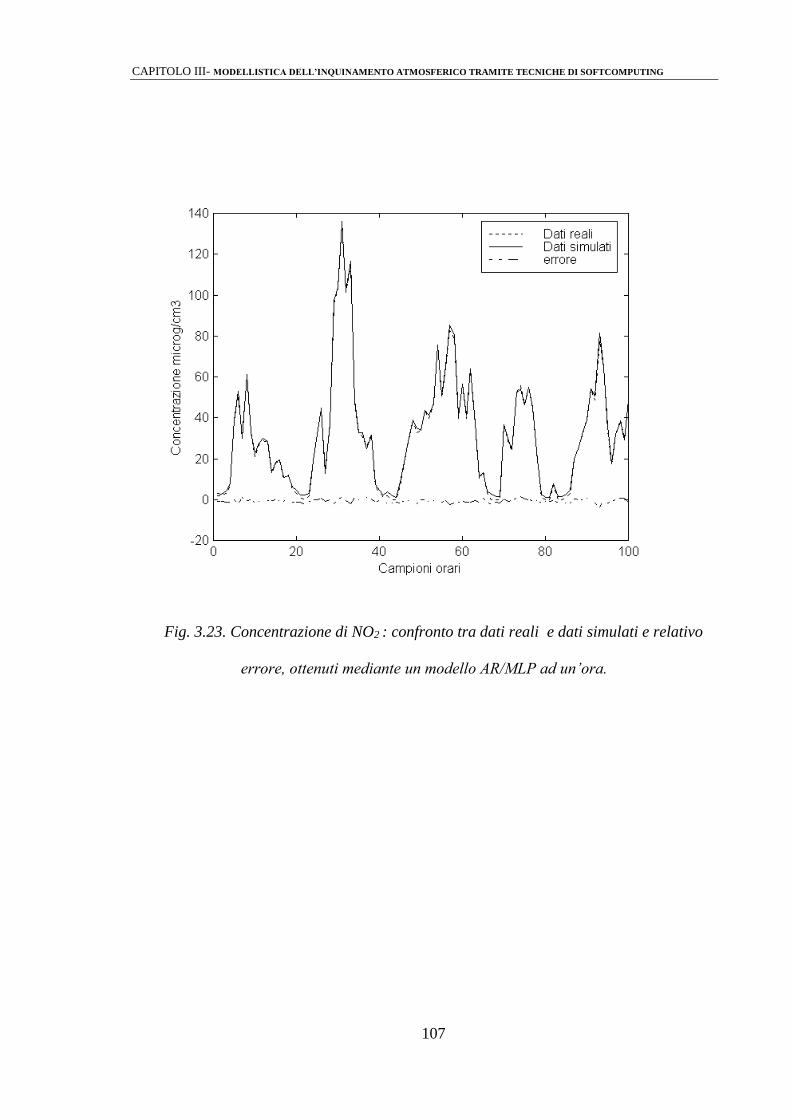
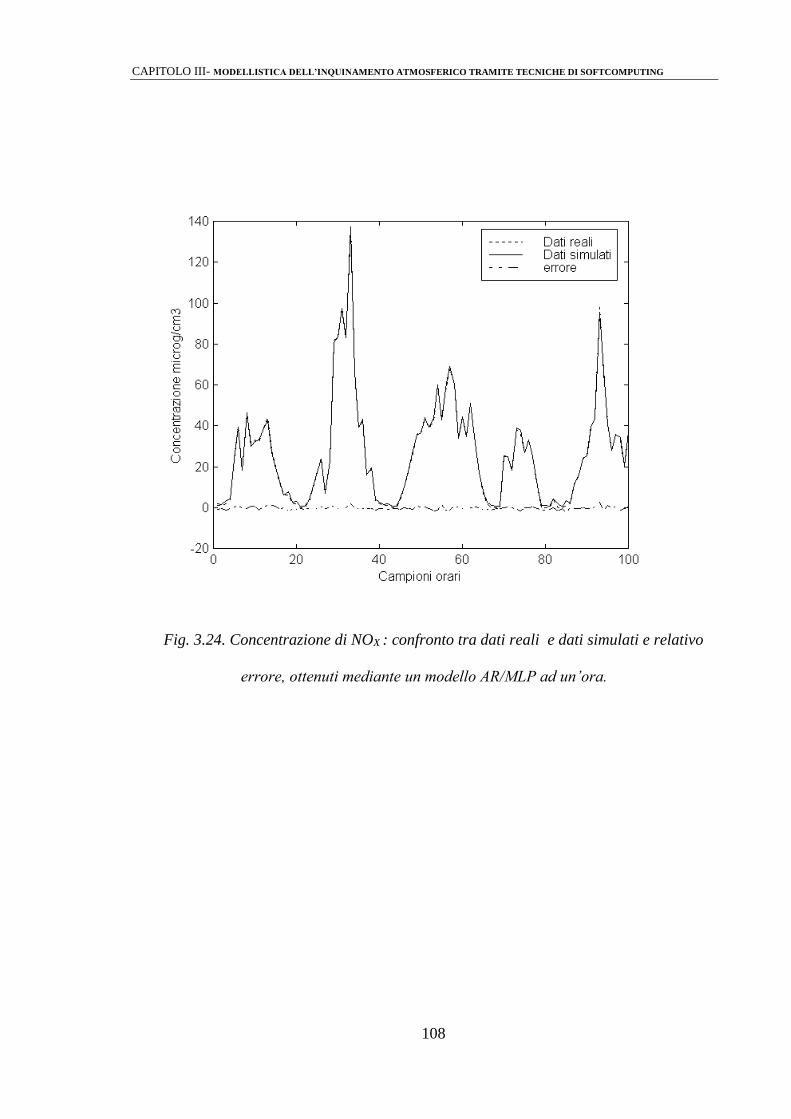
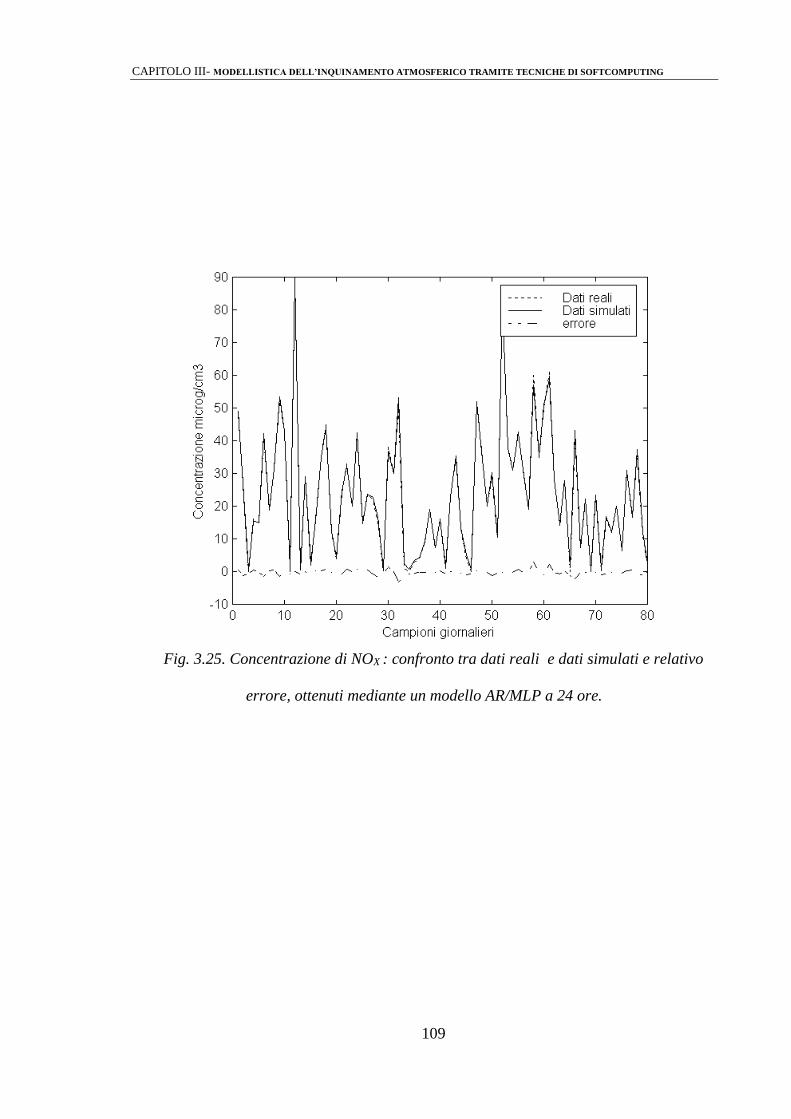
3.2.4 Modelli AR/MLP 103
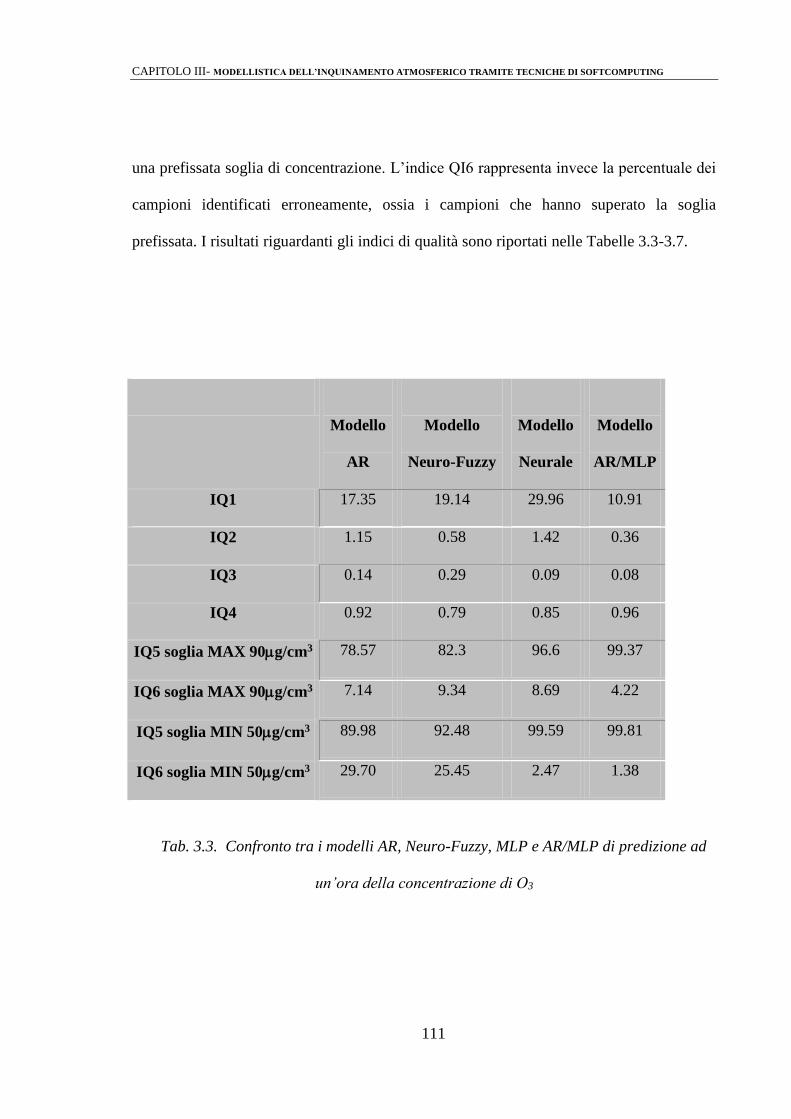
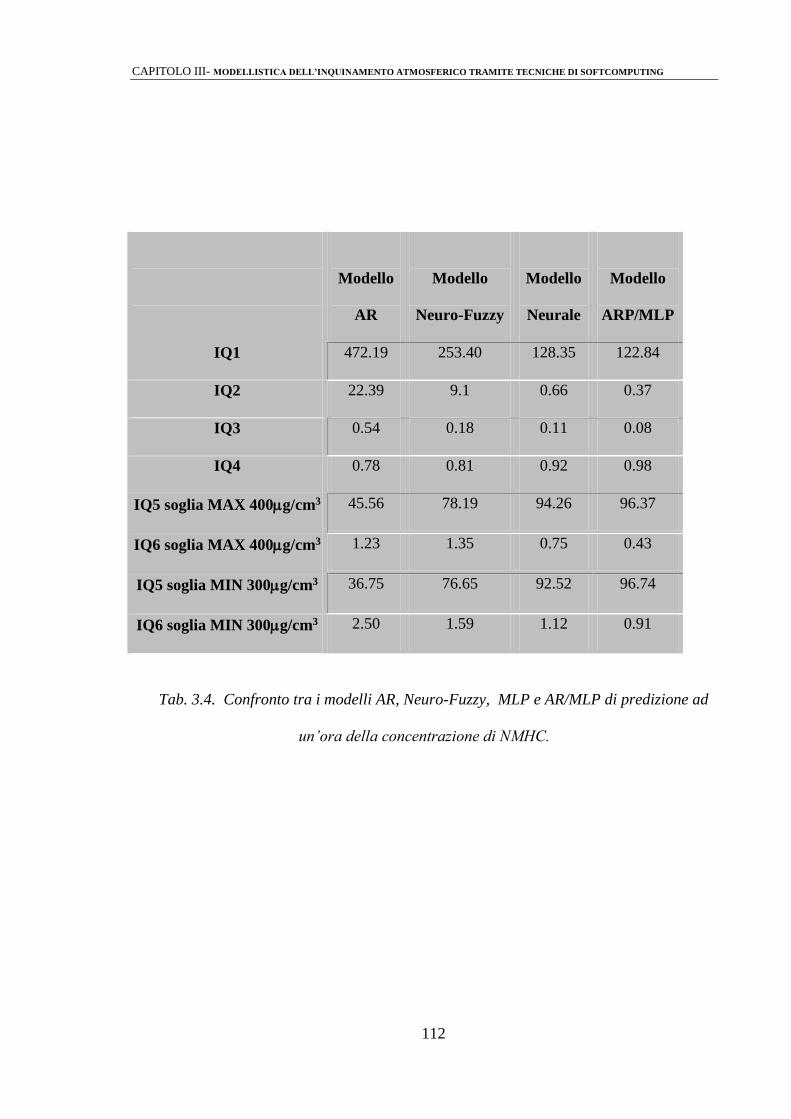
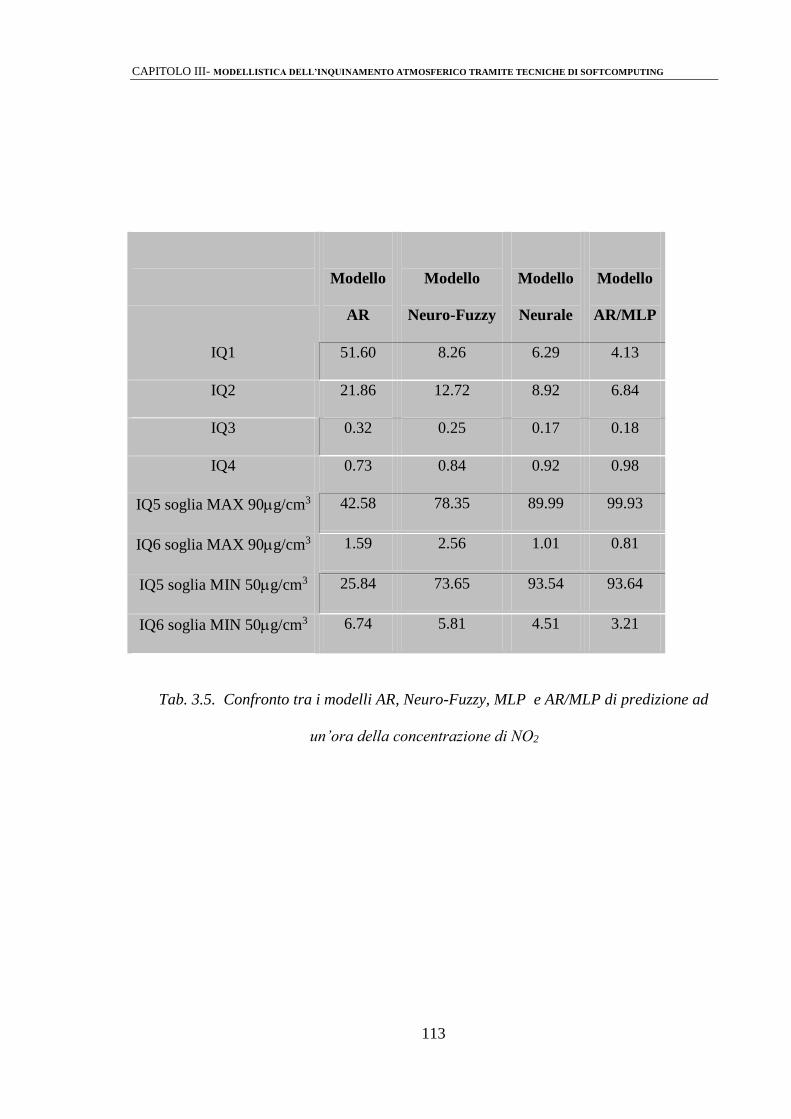
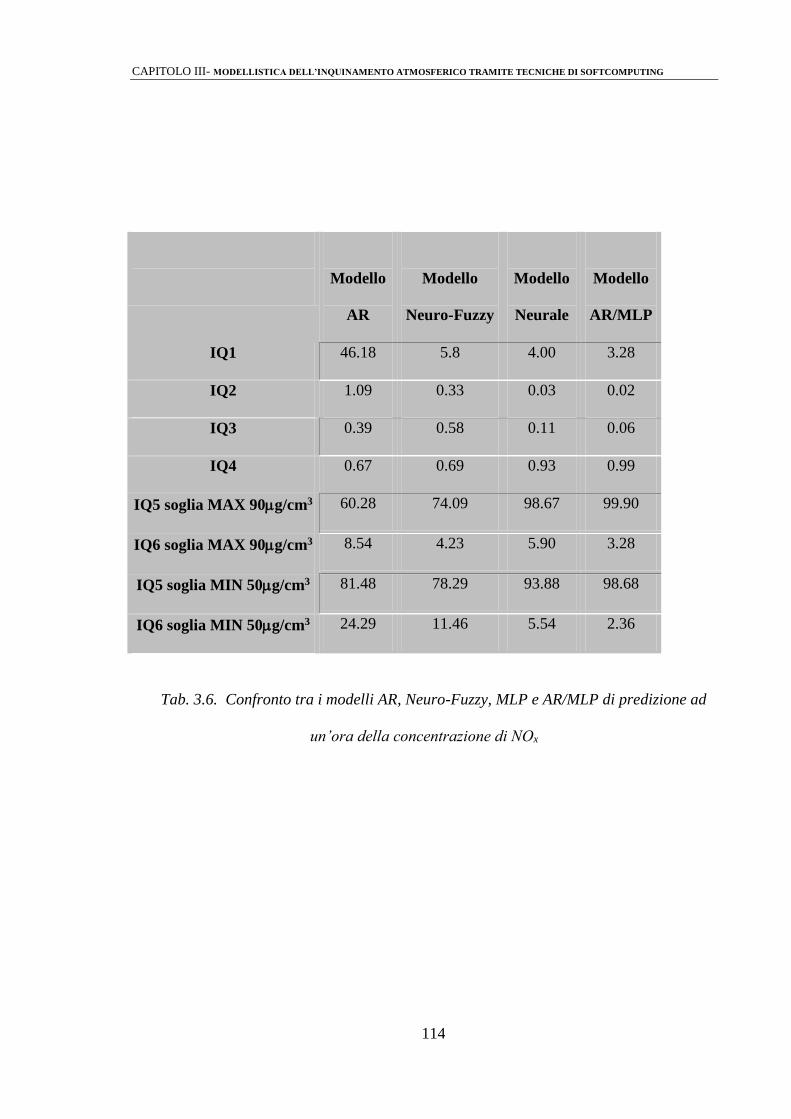
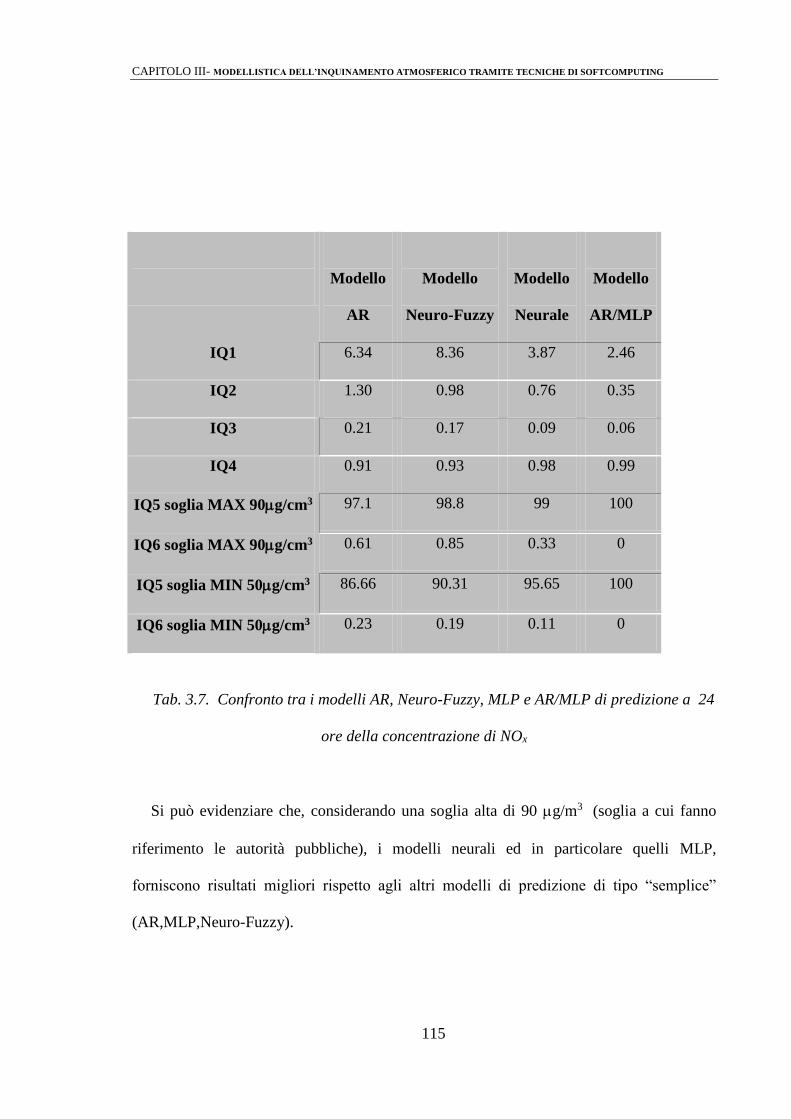
3.3 ANALISI DEI RISULTATI 110
4 SISTEMA PER LA DETERMINAZIONE DELLA
CARICA BATTERICA TRAMITE RETI NEURALI
CELLULARI 117
4.1 INTRODUZIONE 117
4.2 DETERMINAZIONE QUANTITATIVA TRAMITE METODI
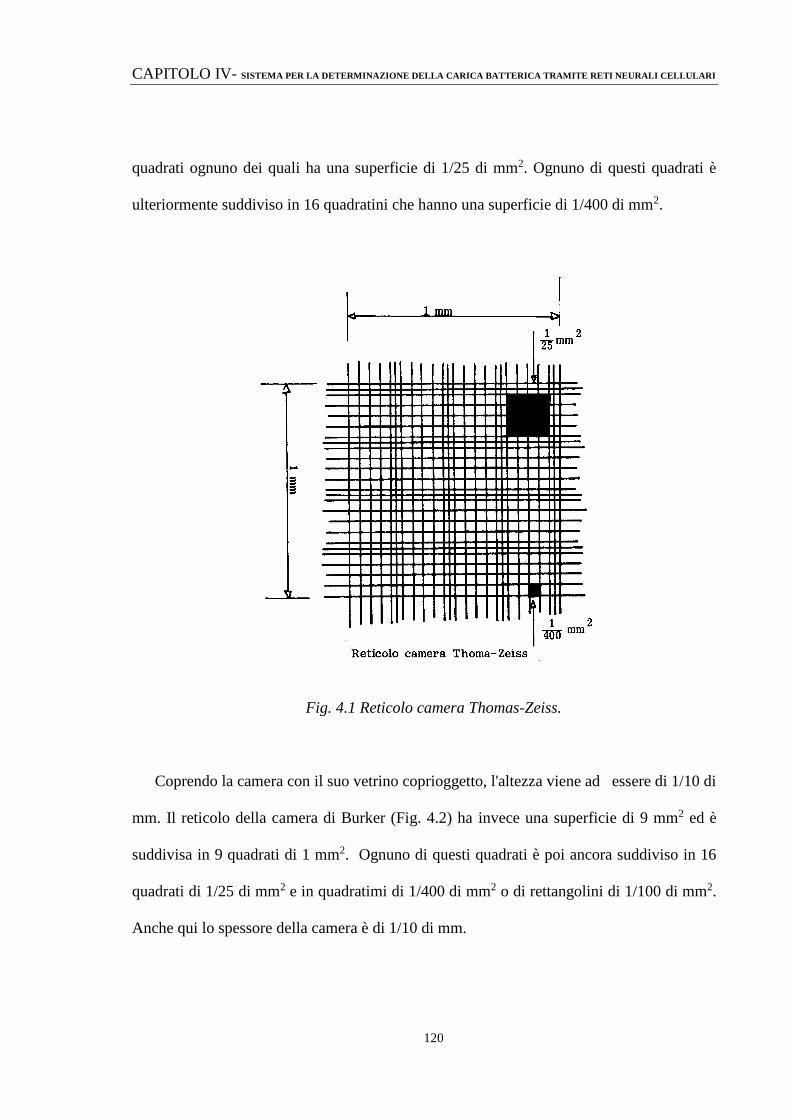
TRADIZIONALI 119
4.3 APPLICAZIONI DELLE RETI NEURALI CELLULARI PER
L’ELABORAZIONE DELLE IMMAGINI 132
4.4 DETERMINAZIONE QUANTITATIVA TRAMITE RETI
NEURALI CELLULARI 135
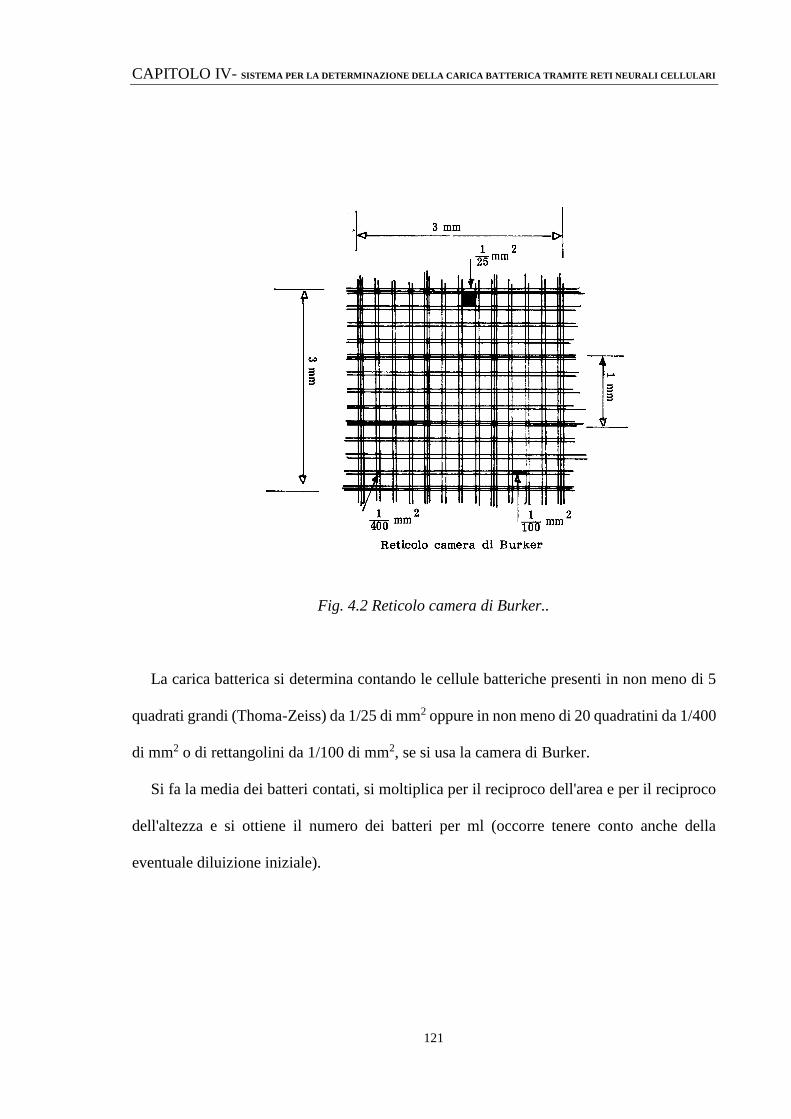
4.5 DETERMINAZIONE QUANTITATIVA: UN CASO REALE
148
ALGORITMO PER LA DISCRIMINAZIONE DELLE CELLULE CON
DIMENSIONE FISSATA 153
5 CONCLUSIONI 155
6 BIBLIOGRAFIA 160
PREFAZIONE
L’approccio classico nella modellizzazione matematica della realtà fisica si basa
sull’utilizzo di leggi che descrivono il comportamento del sistema in studio. Tali leggi si
esprimono generalmente nella imposizione di condizioni di equilibrio di forze agenti su
parti infinitesime del sistema in esame. Le equazioni che così si ricavano sono tipicamente
equazioni differenziali alle derivate parziali. Tali modelli però risultano molto complessi e
di difficile applicazione quale ad esempio nella previsione degli inquinanti atmosferici.
Pertanto molte delle volte non riescono a dare dei risultati in piccola scala ma si riferiscono
ad osservazioni macroscopiche del sistema in esame.
Nell’ultimo decennio sono nate alcune tecniche diverse da quelle convenzionali di tipo
analitico, per la modellizzazione di sistemi fisici. Ci si riferisce alle tecniche di relative alla
fuzzy logic, alle reti neurali artificiali, alle tecniche di ottimizzazione globale (ad esempio
algoritmi di ottimizzazione globale ed evoluzionistici) e ai sistemi distribuiti non lineari
(ad esempio le CNN) che messe assieme originano una metodologia denominata Soft
Computing. Esso mira a fondere in modo sinergico i differenti aspetti delle varie discipline
al fine di implementare sistemi ibridi che riescono a fornire soluzioni innovative nei settori
più svariati della scienza.
PREFAZIONE
iv
Nel presente lavoro si portano due applicazioni di uso scientifico che fanno uso di
tecniche di Soft Computing. La prima si riferisce alla previsione della concentrazione di
particolari inquinanti atmosferici quali O3, NMHC, NO2 e NOx . La seconda, mira invece a
risolvere un problema pratico di conteggio di oggetti a partire da immagini, nella
fattispecie verrà descritta l’implementazione si un sistema per la conta di cellule e batteri
mediante l’uso delle reti neurali cellulari (CNN).
I problemi presentati in questa sede sono già stati affrontato da alcuni autori con risultati
incoraggianti [1][2] [3] [4]. In questo lavoro l’argomento viene riprese ed esteso.
CAPITOLO I
INTRODUZIONE
1.1 INTRODUZIONE ALLA PRIMA PARTE
In una società industrializzata come la nostra, oggi più che mai si pone il problema
dell’inquinamento atmosferico dovuto agli scarichi industriali. Normalmente il nostro
pianeta è soggetto a determinati cicli chimici che hanno originato la vita degli esseri che
popolano la terra. Un’alterazione di questi ultimi può provocare seri danni alla natura
distruggendo tutto ciò che essa è riuscita a fare in milioni di anni. L’uomo purtroppo non si
rende conto di ciò e non pensa alle conseguenze delle sue azioni. Una delle prime
conseguenze a cui si va incontro è l’aumento della temperatura terrestre, che fino a qualche
anno fa sembrava solo un’ipotesi astratta, si sta rilevando oggi come possibilità concreta.
Le sostanze inquinanti che abbiamo immesso in questi ultimi decenni di era industriale
sono ben poca cosa in confronto a ciò che ora stiamo immettendo e che immetteremo nei
prossimi decenni.
La predizione della concentrazione degli inquinanti atmosferici, sia essi urbani che
industriali, rappresenta oggi un mezzo molto potente per la scelta delle strategie da
CAPITOLO I - INTRODUZIONE
2
applicare per evitare il superamento delle soglie di concentrazioni ammesse dalla
legislazione.
Lo scopo della prima parte di questo lavoro consiste nel considerare la possibilità di
usare tecniche moderne quali quelle basate sul Soft Computing per l’identificazione di
modelli per la predizione degli inquinanti atmosferici. Verranno prese in considerazione
predizioni a piccolo e medio raggio delle concentrazioni di O3, NMHC, NO2 e NOx, che
sono inquinanti tipici del ciclo fotolitico dell’azoto. I risultati ottenuti dimostrano la grande
capacità delle reti neurali per la modellizzazione del fenomeno in questione rispetto ai
modelli autoregressivi di identificazione tradizionali.
Inoltre la possibilità di usare reti neuro-fuzzy, che sfruttano le capacità delle reti neurali
combinate con la logica fuzzy, permetterà l’estrazione automatica della base di regole nella
forma “if ... then …”; ciò rappresenta un modo trasparente di modellizzazione che
aggiunge indicazioni utili per l’analisi del fenomeno in questione e l’eventuale
integrazione con altre basi di conoscenza acquisite da un esperto umano.
In fine si introduce la possibilità di utilizzare un modello di predizione “misto” che
prevede l’uso in cascata di un modello AR con un modello basato sul perceptrone
multistrato (MLP).
CAPITOLO I - INTRODUZIONE
3
1.2 INTRODUZIONE ALLA SECONDA PARTE
I metodi di conteggio delle cellule trovano largo impiego sia nella biologia molecolare
che nella medicina clinica con particolare riferimento ai cicli di crescita e fissione delle
cellule animali. Non è sempre tecnicamente possibile misurare quantitativamente gli eventi
riguardanti la crescita e la fissione cellulare. Quando ciò può essere fatto, le procedure
impiegate non sono molto semplici e non riescono ad analizzare un gran numero di cellule
contemporaneamente. In questo lavoro, si descrive un sistema basato su reti neurali
cellulari (CNN) che facendo uso di un simulatore CNN è capace di conteggiare, in modo
automatico, le cellule animali anche durante le loro fasi di crescita e replicazione. La
capacità del sistema proposto saranno illustrate mediante un semplice esperimento di
conteggio che si basa sul contatore Petroff-Hauser o Helber, normalmente impiegato in
biologia per la conta dei batteri.
Lo studio presentato è suddiviso in due parti. La prima parte riguarda i metodi di
conteggio tradizionalmente impiegati nella cultura di cellule batteriche. La seconda
riguarda invece l’implementazione del sistema automatico di conteggio basato su reti
neurali cellulari. In fine si dimostrerà la possibilità di implementare un sistema per lo
screening del numero delle cellule in funzione della loro grandezza.
CAPITOLO II
TECNICHE DI TIPO SOFT COMPUTING
INTRODUZIONE
Da sempre una delle cose che più ha affascinato l’essere umano è stato il processo di
formazione della conoscenza umana ed animale. Da argomento principe della filosofia di
tutti i tempi è arrivata fino ad oggi senza per questo perdere quel fascino che la
contraddistingueva. Nel campo del sapere più propriamente scientifico è nata di recente
una disciplina denominata Soft Computing che si pone come metodologia che fonde in
modo sinergico gli aspetti caratteristici della fuzzy logic, delle reti neurali, degli algoritmi
evoluzionistici e dei sistemi distribuiti non lineari al fine di progettare sistemi il cui
comportamento sia ibrido. Esso fornisce algoritmi sempre più potenti capaci di
discriminare, ragionare, valutare, prevedere piuttosto che semplicemente eseguire dei
“calcoli”, queste nuove strutture di calcolo si ispirano a processi naturali e biologici quali
l’adattamento, l’aggregazione, la cooperazione e la selezione.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
5
Si cerca cioè di ricercare soluzioni fortemente innovative nel settore della
classificazione, nella modellizzazione e nella simulazioni di sistemi dinamici molto
complessi. Il loro pregio maggiore è quello di essere capaci di modellare l’incertezza che è
tipica del mondo reale. Essi sono “soft” nel senso che la loro precisione è sfumata e che la
logica su cui si basano non è rigida ma elastica. Il Soft Compunting assieme alla tecnologia
sempre più spinta dei nostri giorni, ci consente di progettare sistemi sempre più complessi
e sofisticati, incrementando così la qualità della nostra vita e del benessere comune.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
6
2.1 LE RETI NEURALI
I primi studi su questi sistemi risalgono agli anni sessanta ma vennero presto
abbandonati in quanto non parevano offrire possibilità di sviluppi futuri. Da pochi anni,
anche grazie a nuovi algoritmi di apprendimento e alle possibilità della odierna tecnologia,
sono invece tornate prepotentemente alla ribalta.
La caratteristica principale delle reti neurali è quella di poter risolvere un determinato
problema apprendendolo anziché mediante una specifica programmazione. Le reti neurali
artificiali si ispirano dichiaratamente al sistema nervoso degli animali. Tale sistema è
costituito da un grande numero di cellule nervose (una decina di miliardi nell’uomo)
collegate tra di loro in una fitta rete. Nell’uomo, ogni neurone è collegato mediamente con
decine di migliaia di altri neuroni [5]. Si hanno quindi centinaia di miliardi di connessioni.
Il comportamento intelligente emerge dalle numerose interazioni tra le unità interconnesse
(perciò si parla di paradigma connessionista). Ogni neurone è costituito da un corpo
cellulare (soma) dal quale si diparte un filamento (assone) che si ramifica poi in tanti
filamenti secondari (dendriti). Ogni filamento secondario istituisce un contatto chimico con
un altro neurone. Tale contatto (sinapsi o peso sinattico) si estrinseca nel rilascio
controllato di una sostanza chimica di tipo ormonale (neurotrasmettitore) che consente la
trasmissione del segnale da un neurone ad un altro. I pesi sinattici possono essere eccitatori
o inibitori, quindi l’input di un neurone è la media di segnali di segno opposto, oltre che di
intensità diversa. Quando tale media supera una determinata soglia il neurone genera un
segnale bio-elettrico che si propaga lungo l’assone sino alle dendriti e, attraverso i pesi
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
7
sinattici, ad altri neuroni. La soglia del neurone può variare nel tempo, con effetto
“calmante” o “eccitante”, a seconda che il suo valore si alzi o si abbassi.
Una caratteristica fondamentale delle reti neurali è la loro precisione sfumata; in altre
parole esse sono costituzionalmente “fuzzy”. Questo potrebbe sembrare un elemento
negativo, ma è in realtà un punto di forza che le accomuna al cervello. Anche il cervello
umano non brilla per precisione (le sue capacità aritmetiche sono inferiori a quelle di
qualunque calcolatrice). Tuttavia nessuna macchina, per quanto sofisticata, sa riconoscere
un gatto o un albero da una loro figura approssimativa oppure la presenza non visibile di
una persona conosciuta dalla sua voce, magari alterata da rumore ambientale. La precisione
sfumata delle reti neurali le rende inadatte alla contabilità o al calcolo tecnico-scientifico,
ma si rivela preziosa nel riconoscimento e nella classificazione di oggetti, nel supporto
decisionale a scelte complesse, nella robotica, in un mondo reale che è “grigio“ e analogico
e non “bianco o nero” cioè discreto. In particolare, quanto sopra conferisce alle reti neurali
una notevole capacità di generalizzazione. Dopo un apprendimento basato su un adeguato
campione di dati (training set) la rete non solo risolverà correttamente (anche se con
precisione sfumata) ognuno di questi esempi, ma fornirà una soluzione adeguata anche per
nuovi input, non compresi in quegli esempi.
Altre caratteristiche importanti delle reti neurali sono la loro robustezza o non
fragilità (forniscono infatti soluzioni accettabili anche con dati parziali o rumorosi) ed il
funzionamento “fail safe” (degradazione dolce delle prestazioni). Queste proprietà
dipendono dal loro essere fuzzy e dal coinvolgimento di un grande numero di neuroni nella
soluzione di un problema: la conoscenza necessaria è distribuita e condivisa da molti
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
8
neuroni e non concentrata in uno o in pochi di essi. Inoltre le reti neurali possono fornire
buoni risultati anche se gli input sono parzialmente mancanti o ambigui o addirittura
contrastanti oppure se un certo numero di neuroni non sono operativi.
2.1.1 Struttura delle reti neurali
Pur essendo un neurone reale molto complesso, una sua schematizzazione che si è
rivelata di grande utilità (neurone artificiale) è la seguente. Ogni neurone riceve in ingresso
segnali x1,x2,...,xi,...,xn da n altri neuroni, tramite connessioni di intensità wi (pesi sinattici)
fornendo in uscita un solo segnale y. I segnali di ingresso vengono consolidati in un
potenziale post-sinattico
P w xi ii
n
1
(2.1)
media pesata degli ingressi, mentre l’uscita è fornita da una opportuna funzione di
attivazione y f P dove è una soglia caratteristica del neurone in questione.
Le funzioni di attivazione più usate sono:
Funzione a gradino: y=f(x)=sign(x), cioè f(x)=1, per x 0 ( P ) e f(X)=0
altrimenti [6].
Funzione sigmoide o curva logistica:
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
9
y f xe Ax
1
1 (2.2)
Le caratteristiche della funzione sigmoide sono:
- vale 1/2 per x=0 ( P );
- tende a zero per x ;
- tende a uno per x ;
- può essere più o meno ripida in funzione del parametro A ed in particolare tende a
diventare la funzione a gradino per A molto grande e la funzione lineare per A molto
piccolo.
In alcuni casi si usa la grandezza T=1/A che viene denominata temperatura per analogia
con la termodinamica in quanto che, in alcuni casi viene diminuita gradualmente in una
sorta di processo di raffreddamento. Una proprietà interessante della sigmoide, che sarà
sfruttata in fase di apprendimento, è che la sua derivata è data da
ydy
dxAy y' 1 (2.3)
In alternativa alla sigmoide si usa in alcuni casi la tangente iperbolica che ha la
caratteristica di fornire valori compresi tra -1 e 1. La sua espressione è
ye e
e e
x x
x x
(2.4)
L’uscita y di ogni neurone, in una rete, è a sua volta uno degli input di molti altri
neuroni. In generale una rete neurale artificiale è costituita da n neuroni di ingresso
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
10
(corrispondenti ai neuroni sensori come quelli della retina nell’occhio), da m neuroni di
uscita (corrispondenti ai neuroni motori come quelli che attivano i muscoli) e da k neuroni
intermedi (interneuroni o neuroni nascosti). Questi ultimi sono collegati con altri neuroni
intermedi e/o con neuroni sensori a monte e/o con neuroni motori a valle. Se in un
determinato momento, gli input della rete sono x1,x2,...,xi,...,xn allora si otterranno gli
output y1,y2,...,ym con
y f x x xj j n 1, ,...,2 (2.5)
In sostanza una rete può essere concepita come una scatola nera che trasforma
determinati ingressi in corrispondenti uscite. Se gli input sono i dati di un problema e gli
output le relative soluzioni, la rete risolve quel problema.
2.1.2 Tipi di apprendimento delle reti neurali
La capacità di apprendere di una rete neurale è contenuta intrinsecamente nella sua
struttura. Più precisamente, nel corso delle sue interazioni con l’ambiente esterno,
tipicamente nel processo di apprendimento, i pesi sinattici tra ogni coppia di neuroni
vengono modificati in funzione delle prestazioni. Nelle reti artificiali si hanno due tipi
principali di apprendimento detti supervisionato e non supervisionato. Nel primo caso
vengono presentati alla rete, in ogni istante t, opportuni campioni degli ingressi xi e dei
corrispondenti output desiderati dj. Le variazioni dei pesi sinattici necessarie per
l’aggiornamento
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
11
w t w t w 1 (2.6)
sono un’opportuna funzione di una metrica dell’errore e quindi delle differenze (yj-dj) tra
output ottenuti yj e output desiderati dj. In generale gli algoritmi di apprendimento
assumono come metrica l’errore quadratico medio che viene minimizzato.
L’apprendimento supervisionato richiede quindi la conoscenza preliminare non solo degli
input xi ma anche dei corrispondenti output voluti dj. Ogni campione
x x xn1 2, ,..., d d dm1 2, ,...,
è un elemento di un insieme di p campioni denominato “training set”.
Nel caso invece dell’apprendimento non supervisionato, il training set è tipicamente
costituito da numerosi campioni di ingresso X x x xi i i in 1 2, ,..., che si vogliono
classificare in un numero limitato m di classi C1,C2,...,Cm . Nel presentare i campioni non
viene però dichiarata la classe di appartenenza. E’ la stessa rete ad auto organizzarsi,
cambiando progressivamente i suoi pesi sinattici, in modo tale da eseguire, dopo
l’apprendimento, classificazioni corrette.
2.1.3 Reti a separazione lineare
La rete neurale più semplice che possiamo costruire è quella formata da un solo neurone
con n ingressi ed una sola uscita y. Adottiamo, per fissare le idee, una funzione di
trasferimento a gradino e studiamone le prestazioni.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
12
Una tale rete, che viene indicata come perceptrone, può riconoscere tutti gli esemplari di
una determinata forma F , distinguendoli da quelli relativi a forme non-F. Nel caso
bidimensionale basterà che una retta separi i punti (x1,x2) corrispondenti ad una forma F da
quelli relativi a forme non F. La situazione descritta è mostrata in Fig. 2.1.
Fig 2.1 Esempio di classi separabili linearmente.
Se w1 e w2 sono i pesi sinattici e è la soglia del neurone, l’equazione della retta deve
essere
w x w x1 1 2 2 0 (2.7)
In tal caso la retta divide il piano in due semipiani per i quali si ha rispettivamente
w x w x1 1 2 2 0 , cioè w x Pi ii
n
1
, quindi y=1 (2.8)
w x w x1 1 2 2 0 , cioè w x Pi ii
n
1
, quindi y=0 (2.9)
dove P è già stato definito potenziale postsinattico. Fornendo come ingressi le
coordinate di un punto che giace nel semipiano di F la rete darà uscita unitaria, altrimenti
x2
x1
F
non
F
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
13
l’uscita sarà nulla. Nel caso di tre coordinate possiamo parlare di piano di separazione fra
due semispazi e, nel caso più generale di n dimensioni, si parlerà di iperpiani di
separazione. Una variazione dei valori dei pesi sinattici wi determina una variazione
dell’inclinazione dell’iperpiano, mentre una variazione della soglia determina uno
spostamento dell’iperpiano parallelamente a se stesso. L’apprendimento dei pesi e della
soglia si risolve allora in una serie di piccoli movimenti dell’iperpiano sino a realizzare la
separazione lineare, partendo da un iperpiano iniziale generico che non la realizza. In
generale si usa parlare di apprendimento dei pesi e si suole considerare la soglia come il
peso di un ingresso sempre unitario. Questo è possibile ridefinendo P come
P w xi ii
n
1
(2.10)
Il modo più semplice per addestrare una rete di questo tipo è quello di far variare i
pesi (aumentarli o diminuirli) in modo proporzionale agli ingressi cioè secondo la formula
w x dove è un coefficiente detto “learning rate”.
E’ ovvio che la rete descritta funziona solo se esiste un iperpiano che divide le due
classi e che ciò non sempre avviene. Supponiamo adesso di considerare lo spazio
bidimensionale binario. Gli elementi dello spazio sono le quattro coppie 00,01,10 e 11. E’
facile separare, ad esempio, la forma logica AND = 11 dalle altre, o la forma logica OR =
10,01,11 da 00 ed anzi è facile verificare, graficamente o analiticamente, che esistono
infinite rette che operano questa separazione. Se però consideriamo la forma XOR = 01,10
i suoi due elementi non sono separabili dagli altri due punti con una retta. In tal caso la
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
14
separazione è effettuabile mediante linee curve cioè mediante l’introduzione di reti più
complicate con almeno un livello di neuroni nascosti.
2.1.4 Algoritmo di apprendimento di Widrow-Hoff
Estendiamo i discorsi precedenti ad una rete con m neuroni. Se esistono m forme
diverse Fj, ciascuna delle quali costituisce una configurazione di n punti x ed è separabile
linearmente dalle altre, allora ogni neurone può riconoscere una configurazione particolare
e la rete, globalmente, può riconoscere m configurazioni. Per ottenere questo occorre
assegnare agli m n pesi sinattici. L’algoritmo di Widrow-Hoff calcola i pesi necessari,
partendo da pesi casuali e apportando ad essi piccole variazione, graduali e progressive, in
un processo che converge alla soluzione finale.
La rete abbia quindi n ingressi x, ed m neuroni (uscite). Gli m neuroni abbiano tutti la
stessa funzione di trasferimento associata f e che tale funzione sia differenziabile. Sia
inoltre disponibile un training set di p esempi. Ciò premesso l’algoritmo consiste nel
ripetersi ciclico di alcuni passi fino al raggiungimento dei risultati desiderati. Tali passi
sono:
1) Presentazione di un input generico X x x x xi n 1 2, ,..., ,... (2.11)
2) Calcolo degli output corrispondenti y f Pj j con P w xj ji ii
n
1
(2.12)
3) Calcolo dell’errore quadratico medio E y dj jj
m
1
2
2
1
(2.13)
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
15
4) Calcolo delle variazioni w t w t wdE
dwji ji ji
ji
1 (2.14)
dove è un coefficiente compreso tra zero ed uno detto “learning rate”.
Il processo si interrompe quando E raggiunge un valore piccolo prefissato. Per
giustificare la formula dell’aggiornamento dei pesi sinattici rileviamo che occorre
minimizzare E quindi se E aumenta con w (dE/dw>0) i pesi devono diminuire (w 0 )
mentre se E diminuisce all’aumentare di w (dE/dw<0) i pesi devono essere aumentati
(w 0).
Vediamo come si possono scrivere le formule di aggiornamento scritte al punto quattro.
Essendo
dE
dwy d
dy
dwy d
dy
dP
dP
dwji
i j
j
ji
i j
j
j
j
ji
(2.15)
dove
dy
dPf P
j
j
j ' e dP
dwx
j
ji
i (2.16)
si ha allora
w y d f P x D xji j j j i j i ' (2.17)
avendo posto D y d f Pj j j j ' . (2.18)
Se la funzione di trasferimento considerata è la sigmoide si ha f P y yj j j' 1 e
dunque
w y d y y xji j j j j i 1 (2.18)
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
16
L’inconveniente della sigmoide è allora che per y vicino a zero le variazioni dei pesi
tendono a zero e dunque il sistema non apprende più.
Se la funzione di trasferimento è lineare la sua derivata è costante e dunque
w y d xji j j i (2.19)
Dopo la presentazione di un congruo numero di esempi in altrettanti cicli consecutivi
l’errore diventerà più piccolo di un minimo prefissato ed il processo di apprendimento sarà
così concluso. Se invece, dopo una prima presentazione di tutti gli esempi del training set
(prima epoca) l’errore non è ancora accettabile si procede a una seconda epoca a così via.
Solo nel caso di funzione di trasferimento lineare l’errore avrà un minimo assoluto mentre
negli altri casi esistono dei minimi locali. E’ opportuno allora in alcuni momenti inserire
delle perturbazioni casuali sui pesi in modo da evitare lo stallo in uno di questi minimi.
Negli sviluppi matematici precedenti si è considerata la versione on-line dell’algoritmo
cioè quella che prevede l’aggiornamento dei pesi alla presentazione di ogni singolo
esempio. La versione batch dell’algoritmo prevede invece che l’aggiornamento sia
effettuato ad ogni epoca. L’errore da minimizzare in questo caso risulta
E y dkj kjj
m
k
p
1
2
2
11
(2.20)
In generale la versione on-line è preferita alla versione batch in quanto fornisce
normalmente risultati migliori cioè convergenza più veloce e minori oscillazioni.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
17
2.1.5 Reti a separazione non lineare
Ritorniamo al problema dello XOR per dimostrare che esso può essere risolto mediante
una rete più complessa cioè con un maggior numero di gradi di libertà. Un modo per
risolverlo è quello di aumentare fittiziamente il numero di ingressi del sistema
aggiungendo a x1 e x2 un terzo input x3=x1x2. Gli esempi del training set sono allora quelli
della seguente tabella:
x1 x2 x3 Y
0 0 0 0
0 1 0 1
1 0 0 1
1 1 1 0
Il problema è stato trasformato in un problema a separazione lineare e dunque può
essere risolto con un perceptrone. Tuttavia già con tre ingressi avremmo dovuto inserire
quattro ingressi fittizi. Possiamo allora concludere che questo metodo è scarsamente
applicabile con un numero realistico di ingressi.
Un altro modo di aumentare i gradi di libertà del sistema è quello di aggiungere uno
strato di neuroni intermedi. Per il problema da noi considerato la soluzione può essere
ricavata dalla formula del calcolo combinatorio
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
18
x1 XOR x2 = (x1 AND x2) OR (x1 OR x2) (2.21)
che suggerisce di adottare la seguente rete:
Fig 2.2 Rete neurale a due strati dove i neuroni intermedi realizzano uno la funzione
OR e uno la funzione AND ed il neurone di uscita realizza la funzione OR.
Una rete neurale con uno stadio di ingresso, uno o più strati intermedi ed uno stadio di
uscita è denominato Multi-Layers Perceptron (perceptrone multistadio MLP). Tale rete è
anche definita di tipo feed-forward perchè i segnali si propagano dagli ingressi alle uscite,
attraverso i neuroni intermedi, non avendosi connessioni trasversali o connessioni feed-
back.
In conclusione una rete neurale MLP può, in teoria, eseguire qualunque separazione
risolvendo così qualsiasi problema di classificazione, di riconoscimento, di scelta. Tuttavia,
nel caso di problemi complessi, la realizzabilità teorica di una rete MLP che risolva il
x1 x2
y
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
19
problema, può non essere di grande aiuto. Infatti il grande numero richiesto di neuroni
intermedi, la notevole lunghezza del processo di addestramento e la non disponibilità di un
training set adeguato potrebbero diventare ostacoli insormontabili per una realizzazione
effettiva.
2.1.6 Apprendimento delle reti MLP
Purtroppo l’algoritmo di Widrow-Hoff (WH) non può essere applicato al caso di reti
MLP. Sappiamo infatti calcolare l’errore E y dj j j per ogni neurone di uscita ma non
sappiamo calcolarlo per i neuroni intermedi k non conoscendo i valori voluti dk. Questo
fatto ha impedito per molto tempo lo sfruttamento pratico delle notevoli possibilità delle
reti MLP. Solo nel decennio scorso è stato proposto l’algoritmo back-propagation (BP) che
supera tale problema. Sostanzialmente l’algoritmo BP è un estensione del WH. Il punto
chiave è l’opportuna ripartizione dell’errore, noto al livello di uscita, tra i neuroni dello
strato e quelli degli strati intermedi. In ogni ciclo dell’algoritmo si hanno due fasi: una
(forward) per il calcolo degli errori che è virtualmente identica al caso del perceptrone e
l’altra per la ripartizione degli errori negli strati intermedi.
Per fissare le idee, consideriamo una rete di tre strati; il primo con attività neurali xi, il
secondo (intermedio) con attività yj e pesi sinattici wji, il terzo con attività zk e pesi sinattici
wkj. L’aggiornamento dei pesi wkj è identico a quello già visto per l’algoritmo WH
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
20
wdE
dwz d f P ykj
kj
k k k j ' (2.22)
cioè anche ponendo D z d f Pk k k k '
w D ykj k j (2.23)
Per quanto riguarda l’aggiornamento dei pesi sinattici wji si ha, similmente a quanto
visto per l’algoritmo Widrow-Hoff
wdE
dwji
ji
dE
dw
dE
dy
dy
dP
dP
dwji j
j
j
j
ji
dy
dPf P
j
j
j ' e dP
dwx
j
ji
i
dE
dw
dE
dyf P x
ji j
j i ' (2.24)
Per ottenere dE/dwji occorre ora conoscere dE/dyi , ma gli errori noti sono (zk-dk),
differenza tra gli output ottenuti zk e quelli desiderati dk. Dovremmo quindi esprimere
dE/dyi in funzione di questi errori
dE
dy
dE
dz
dz
dP
dP
dyy d f P w D w
j k
k
k
k
jkk k k kj
kk kj
k
' (2.25)
Ne deriva finalmente che è
dE
dwf P x D w
ji
j i k kjk
' (2.26)
cioè anche, ponendo D f P D wj j k kjk
'
wdE
dwD xji
ji
j i (2.27)
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
21
Quanto sopra può essere generalizzato dicendo che, dati due strati successivi con attività
neurali xi e pesi wji, l’aggiornamento w ji deve essere effettuato con la formula
w D xji j i (2.28)
dove però
D y d f Pj j j j ' se j è un neurone di uscita
D f P D wj j k kjk
' se j è un neurone intermedio.
Generalmente l’aggiornamento dei pesi viene eseguito con una formula modificata
nel seguente modo
w t D x w tji j i ji 1 (2.29)
dove è un coefficiente positivo minore di uno denominato “momentum”. In questo
caso l’aggiornamento nel ciclo t tende a non differenziarsi molto da quello nel precedente
ciclo t-1 per una sorta di effetto di inerzia. Si può anche affermare che il termine di
momentum ha l’effetto di filtrare le variazioni ad alta frequenza della superficie di errore
E, nello spazio dei pesi w. In sostanza l’adozione di tale termine (tipicamente =0.9)
consente di assumere un coefficiente più elevato (tipicamente =0.7) senza incorrere in
oscillazioni.
Rileviamo infine che non esiste a tutt’oggi una teoria che suggerisca, per risolvere un
determinato problema, il numero di strati intermedi o il numero di neuroni necessari per
ognuno di questi strati. Occorre quindi procedere per tentativi applicando criteri empirici.
La scelta oculata del numero di neuroni intermedi è molto importante perché da essa deriva
la più o meno buona capacità di generalizzazione della rete. Se ci sono troppi neuroni
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
22
intermedi la rete impara troppo il training set, non generalizza e richiede anche un processo
di apprendimento più lungo. D’altra parte, se ci sono pochi neuroni intermedi la rete non
riesce ad apprendere nemmeno il training set. La capacità di generalizzazione della rete
dipende anche da altri fattori quali la lunghezza del processo di apprendimento o la
presentazione degli esempi.
2.1.7 Apprendimento non supervisionato
Consideriamo adesso l’apprendimento senza supervisione dove, come già è stato detto,
il training set è costituito da numerosi campioni X x x xi i i in 1 2, ,..., che si vogliono
classificare in un numero limitato p di classi C C Cp1 2, ,..., . Nel presentare i campioni, non
viene ora dichiarata la loro classe di appartenenza (a priori ignota), al contrario di quanto
avviene nell’apprendimento supervisionato. E’ la stessa rete ad auto-organizzarsi,
cambiando progressivamente i suoi pesi sinattici, in modo tale da eseguire classificazioni
corrette ad apprendimento completato.
La rete in questione ha n ingressi e m (m>p) neuroni di uscita collegati con pesi sinattici
wji. Ad ogni neurone j è associato quindi un vettore W w w wj j j jn 1 2, ,..., cioè anche un
punto nello spazio ad n dimensioni. Anche i vettori X x x xi i i in 1 2, ,..., rappresentano
dei punti nello stesso spazio. Se gli ingressi X i sono raggruppati in p classi distinte si
avranno p “nuvole” distinte di punti. L’apprendimento consiste nella migrazione dei punti
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
23
Wj verso i centroidi di queste nuvole partendo da una generica configurazione iniziale.
Presentando dunque un certo input X i tutti i neuroni competono per essere attivati ma
vince uno solo di essi cioè quello per cui Wj è più vicino a X i . Il premio di tale vittoria
consiste in un ulteriore piccolo avvicinamento a X i secondo la formula
w X Wj i j (1.30)
dove è il solito coefficiente di apprendimento detto learning rate e compreso tra zero
ed uno. Presentando in successione tutti i punti del training set si avrà come risultato
l’avvicinamento progressivo dei punti Wj ai centroidi delle classi. Alla fine
dell’apprendimento gli input che si riferiscono ad una certa classe attiveranno solo il
neurone i cui pesi nello spazio rappresentano tale classe. Se questo avviene la rete ha
imparato il problema di classificazione.
L’apprendimento che abbiamo ora descritto è denominato “competitive learning” per il
fatto che i neuroni si competono la vittoria ad ogni presentazione di un ingresso. Tale
strategia è denominata “Winner Takes All” (WTA)[7].
Esistono altri e diversi tipi di apprendimento ed altre importanti topologie di reti neurali
quali l’apprendimento Hebbiano o le reti di Hopfield per le quali si rimanda alla
bibliografia [8] [9] [10].
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
24
2.2 LA LOGICA FUZZY
In molti campi di applicazione la metodologia fuzzy si è resa utile per la progettazione
di dispositivi che richiedono una certa intelligenza nel loro modo di operare. Essa,
contrariamente all' "Hard Computing", si prefigge di tollerare l'incertezza e l'imprecisione
in fase di calcolo, di elaborazione e di decisione, risultando così meno accurata, ma nello
stesso tempo più robusta e soprattutto capace di ridurre complessità e quindi costi.
La Fuzzy Logic, in particolare, è una disciplina scientifica che imita l'abilità della mente
umana di impiegare metodi di ragionamento approssimati anziché esatti; essa si rende
molto utile per ridurre la complessità di sistemi intelligenti che possono tollerare
l'imprecisione e l'incertezza, apprendere dall'esperienza ed adattarsi ai cambiamenti delle
condizioni di lavoro.
Nata intorno al 1965 [11], con l'introduzione della teoria degli insiemi fuzzy (Fuzzy
Set), a partire dagli anni '80 comincia ad essere usata nelle applicazioni industriali e poi,
dagli anni '90, ha interessato sempre più vari prodotti di largo consumo, anche in
combinazione con le tecniche delle reti neurali, per renderli capaci di adattarsi e di
apprendere dall'esperienza. A tal proposito si può dire che i principali costituenti del Soft
Computing, ovvero la logica fuzzy (FL), la teoria delle reti neurali (NN) ed il ragionamento
probabilistico che include gli algoritmi genetici (GA), pur avendo aree che si
sovrappongono, sono complementari piuttosto che competitivi, quindi è conveniente
impiegarli insieme anziché da soli. Di essi, il primo tratta fondamentalmente con
l'imprecisione, il secondo con l'apprendimento e il terzo con l'incertezza.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
25
Recentemente la logica fuzzy ha raggiunto enorme popolarità, tanto nel mondo
accademico che in quello industriale, vincendo la naturale resistenza al cambiamento. Il
suo successo ha spinto le industrie di microelettronica a creare una nuova classe di
macchine (i circuiti integrati denominati fuzzy machine) in grado di superare i limiti che si
incontrano con i sistemi di calcolo tradizionali quando sono usati in ambito fuzzy.
Il termine Fuzzy Logic in senso letterale indica un sistema logico che mira ad una
formalizzazione del modo di ragionare approssimato; oggi, invece, va inteso in senso più
ampio come sinonimo di teoria degli insiemi fuzzy, ovvero teoria di classi con confini non
netti.
2.2.1 La teoria dei fuzzy set
Nella teoria degli insiemi tradizionale un elemento dell'universo può appartenere ad un
dato insieme oppure no. Ad esempio tra tutte le persone di una famiglia, elementi u di U,
l'elemento persona "a" appartiene all'insieme A delle persone con età inferiore ai 30 anni e
non appartiene all'insieme B delle persone con più di 70 anni (si veda la Fig 2.3). Quindi, il
grado di appartenenza di un elemento nei confronti di un dato insieme può assumere solo i
valori logici "vero" o "falso" cioè, come si suol dire, valori "crisp".
Nelle situazioni più comuni, tuttavia, si incontrano casi nei quali non conviene delineare
un confine netto per gli insiemi; ad esempio, volendo considerare la classe delle persone
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
26
giovani, sembra una forzatura fissare dei valori numerici in anni per delimitarne l'intervallo
di appartenenza.
Fig 2.3 Esempio di insiemi tradizionali.
In un caso del genere è più interessante invece conoscere quanto una data persona può
definirsi giovane, cioè in che misura può considerarsi tale. E’ proprio da questa semplice
constatazione che prende spunto la teoria dei fuzzy set.
Un fuzzy set è una generalizzazione di un insieme tradizionale, ottenuta assegnando ad
ogni suo elemento un grado di appartenenza compreso tra 0 ed 1. In questo modo si può
capire quanto più una data persona "a" soddisfa la caratteristica del concetto "giovane",
continuando ad indicare con i valori estremi 1 e 0 la perfetta appartenenza o meno al dato
insieme. In questo modo l'insieme A delle persone giovani sarà costituito da tutti elementi
persone di U, ognuno con il suo grado di appartenenza ad A, il quale, potendo assumere
valori con continuità e non in modo brusco, fornisce un'idea più vicina alla realtà del
concetto di giovane riferito a quella persona. Si evince quindi che, con tale definizione,
nessun elemento dell’universo U risulta essere non appartenente (nel senso
U A
B
a
b
c
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
27
dell’insiemistica ordinaria) ad un fuzzy set, e ciò in virtù del concetto di grado di
appartenenza. Pertanto un elemento che nell’insiemistica ordinaria verrebbe considerato
come non appartenente ad un dato insieme, in un contesto fuzzy gli verrebbe invece
associato un grado di appartenenza basso, o, al limite, nullo.
In sintonia con quanto detto, la teoria dei fuzzy set rappresenta il superamento della
concezione secondo la quale una data asserzione può essere o solo vera o solo falsa.
2.2.2 Variabili linguistiche
La logica fuzzy permette di approdare alle soluzioni attraverso un metodo
deterministico che, mascherato da una struttura di tipo “linguistico”, consente di avere una
struttura versatile e adattabile ad ogni tipo di sistema. E’ noto infatti che il linguaggio
verbale è ridondante, ovvero lascia abbastanza spazio all’ambiguità e all’incertezza. La
logica fuzzy quindi rappresenta una sorta di fusione tra due approcci basilarmente
antitetici.
Una variabile linguistica è una variabile i cui valori sono parole o frasi anziché numeri.
Tornando all'esempio precedente, asserendo che una data persona è giovane, si fa
riferimento alla variabile linguistica "età", i cui valori linguistici potrebbero appunto essere
"giovane", "di mezza età" ed "anziano". Quindi, fissata una variabile linguistica, la
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
28
specificazione dei suoi valori comporta allo stesso tempo la specificazione degli insiemi
fuzzy prima discussi.
Analiticamente una variabile linguistica x nell'universo del discorso U è caratterizzata
da un insieme W(x) = (W1x , ... , Wnx) e da un insieme M(x) = (M1x , ... , Mnx).
W(x) è l’insieme contenente tutti i valori linguistici che può assumere x,
M(x) contiene invece un set di funzioni Mix specificanti, ciascuna, il grado di
appartenenza di ogni elemento dell’universo U a Wix, cioè all’i-esimo fuzzy set individuato
dalla variabile linguistica x.
2.2.3 Funzione di appartenenza
Considerando una variabile linguistica, ad ogni suo valore linguistico, per quanto detto
in precedenza, si può associare un sottoinsieme fuzzy, i cui elementi saranno caratterizzati
da un grado di appartenenza. Si può così identificare una funzione di appartenenza ad un
sottoinsieme fuzzy, che associa ad ogni elemento u dell'Universo del Discorso U il
corrispondente grado di appartenenza a quel sottoinsieme. Nella insiemistica ordinaria tale
funzione può assumere solo i valori logici "vero" o "falso", è cioè "crisp"; invece, nella
teoria dei sistemi fuzzy ha un ruolo molto importante, potendo assumere valori reali che
variano con continuità da 0 ad 1.
In un sistema di assi cartesiani si può rappresentare, ad esempio, il sottoinsieme fuzzy
giovane con il grafico della funzione di appartenenza come in figura 2.4 .
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
29
Fig 2.4 Fuzzy set.
Analiticamente si può dire che nell' Universo del Discorso U un fuzzy set F è
caratterizzato da una funzione di appartenenza mf ( ) definita in U, che assume valori reali
nell'intervallo 0 1, ; è quindi rappresentato da un insieme di coppie ordinate, ognuna
composta da un generico elemento appartenente ad U e dal suo grado di appartenenza mf
(u), cioè
F = ( u, mf (u)) u U . (2.31)
ETA’ IN ANNI
GRADO DI
APPARTENENZA
GIOVANE MEZZA ETA’
VECCHIO
1
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
30
2.2.4 Regole fuzzy
I fuzzy set possono essere considerati un'estensione degli insiemi ordinari, d'altra parte
la fuzzy logic costituisce un'estensione della logica ordinaria. Quindi, così come avviene
tra l'insiemistica e la logica ordinarie, si possono ricavare delle corrispondenze anche tra la
teoria dei fuzzy set e la fuzzy logic. Ad esempio agli operatori unione, intersezione e
complemento agenti sui sistemi fuzzy corrispondono rispettivamente gli operatori logici
OR, AND e NOT, al grado di appartenenza di un elemento in un fuzzy set può
corrispondere il valore vero di una proposizione nella fuzzy logic.
Infine anche le implicazioni tra sottosistemi fuzzy possono essere rappresentate
mediante regole. Le regole che governano un sistema fuzzy vengono spesso scritte usando
espressioni linguistiche che formalizzano le regole empiriche per mezzo delle quali un
operatore umano è capace di descrivere un processo usando la sua esperienza.
Tali regole fanno uso di relazioni logiche tra argomenti chiamate predicati. Si parla in
particolare di predicati fuzzy i quali si contrappongono su certi aspetti ai predicati normali.
Ad esempio gli esempi seguenti costituiscono rispettivamente un predicato normale e
fuzzy.
Prezzo = 28
Prezzo = alto
Nel primo caso, il predicato può essere vero o falso, nel secondo caso, alto è un insieme
fuzzy, definito in un dominio Pmin- Pmax, e il prezzo può essere “alto” con gradi di verità
compresi tra zero e uno.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
31
In generale, quindi, un predicato fuzzy ha la forma X = F, dove X è una variabile
definita in un dominio Xmin- Xmax e F, denotato da un termine linguistico, come “alto”,
“veloce”, “caldo”, è un insieme fuzzy nello stesso dominio.
In generale una regola condizionale fuzzy è del tipo:
if premessa then conclusione.
La premessa è costituita da un asserzione in cui i predicati fuzzy Pi (che chiameremo
antecedenti) della forma generale (xi is Ai) possono essere combinati da diversi operatori
quali gli operatori logici AND e OR; in questo caso xi è una variabile linguistica definita
nell'universo del discorso U ed Ai è uno dei nomi del term set di xi .
La conclusione indica le azioni da intraprendere quando vengono soddisfatte le
condizioni della premessa.
Un esempio di regole condizionali fuzzy che usano tali operatori è dato da:
if (P1 and P2 or P3) then P4
dove
P1 = (x1 is A1), P2 = (x2 is A2),
P3 = (x3 is A3), P4 = (y4 is B4), (2.32)
Il predicato ( xi is Ai) restituisce come risultato il grado di appartenenza i della
variabile linguistica xi relativamente all'insieme fuzzy Ai. L'applicazione degli operatori
fuzzy ai predicati della premessa fornisce ancora un valore compreso tra 0 ed 1, ricavato
mediante le corrispondenze riportate nella tabella seguente.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
32
Operatore Significato
i AND j MIN( i , j )
i OR j MAX( i , j )
NOT i 1- i
Considerando un universo del discorso finito, cioè con un numero finito di elementi,
una funzione di appartenenza ad un sottosistema può essere identificata da un array, i cui
valori sono dati dal grado di appartenenza a quel sistema di ogni elemento dell'universo.
2.2.5 Sistemi Fuzzy
Un sistema fuzzy trasforma determinati input (per esempio, la temperatura T di una
stanza, rilevata da un sensore) in opportuni output (per esempio, la velocità V di un
ventilatore che deve raffreddare la stanza) : C = f(V).
In generale, si hanno però n input Ii e m output Oj, per cui :
O1 = f1 (I1 , I2 , ... , In)
O2 = f2 (I1 , I2 , ... , In)
O3 = f3 (I1 , I2 , ... , In) (2.33)
Il comportamento dei sistemi fuzzy è definito da una specie di base di conoscenza : essa
comprende la descrizione degli insiemi fuzzy, input e output, e le regole che associano gli
uni agli altri. Le regole dei sistemi fuzzy sono principi generali piuttosto che regole
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
33
precise : ad esempio non ci sono regole come “se la velocità supera 100 Km/h, allora
occorre girare la valvola di 30 gradi”, ma piuttosto regole come “se la velocità è media,
allora occorre girare la valvola di un angolo medio”.
Infine le regole fuzzy vengono eseguite tutte contemporaneamente, in parallelo
conferendo al sistema la possibilità di comprendere le relazioni tra input e output.
Esaminiamo ora il funzionamento generale di un sistema fuzzy.
Si abbiano r regole del tipo (x = Ai and y = Bj z = Ck), con due input, un output, N
insiemi Ai (nel dominio x1 , ... , xn) M insiemi Bj (nel dominio y1 , ... , ym), e P insiemi Ci
(nel dominio z1 , ... , zp).
Il funzionamento comprende le seguenti tre fasi :
1) Fuzzificazione. Vengono opportunamente attivati gli insiemi input (fuzzy), in
funzione dei valori attuali delle variabili input (non fuzzy).
Nel caso di due variabili x, y e dei relativi insiemi input :
A1 , A2 , ... , AN
B1 , B2 , ... , BM
si otterranno, come vedremo tra poco, per i valori attuali x = xo, y = yo, i sottoinsiemi
input :
A’1 , A’2 , ... , A’N,
B’1 , B’2 , ... , B’M .
2) Associazione input-output. E’ la trasformazione dei precedenti insiemi input
(con apice) negli insiemi output fuzzy :
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
34
(C’1 , C’2 , ... , C’P),
applicando le regole :
A’i and B’j C’k,
3) Defuzzificazione. In questa fase i precedenti insiemi output C’k vengono
consolidati in un solo insieme output C’ che, a sua volta, deve essere convertito in un ben
determinato valore attuale zo della variabile output z (viene cioè “defuzzificato”).
L’architettura di un sistema fuzzy (Fig. 2.5), ha quindi come componenti : una base di
dati che descrive gli insiemi fuzzy (funzioni di appartenenza), una base di regole fuzzy, un
fuzzificatore dell’input, un associatore input-output (valutazione regole) e un
defuzzificatore dell’output.
Fig 2.5 Architettura di un sistema fuzzy.
FUZZIFICAZIONE
INPUT
FUZZY
INPUT
VALUTAZIONE
REGOLE
FUZZY
OUTPUT
DEFUZZIFICAZIONE
OUTPUT
FUNZIONI
MEMBERSHIP
REGOLE
BASE DATI E REGOLE
INPUT
OUTPUT
OUTPUT
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
35
La prima operazione di un sistema fuzzy consiste nell’attivare gli insiemi input, in
funzione del valore attuale delle sue variabili input. Abbiamo visto che un insieme fuzzy A
si può rappresentare nel dominio discreto n-dimensionale x1 , x2 , ... , xn, tramite il vettore :
A = (a1 , a2 , ... , an)
dove :
ai = m (A, xi) 1 (2.34)
è il grado di appartenenza di xi ad A.
Il valore attuale di x coincide con un ben determinato x1 xi xn (poniamo con x4), al
quale corrisponde una determinata funzione di appartenenza a4 = m (A, x4), grado di verità
dell’appartenenza di x4 ad A. Questo valore x4 attiva, come giustificheremo tra poco, un
sottoinsieme A’ di A.
Si hanno due modalità di attivazione : Correlation-Minimum Encoding e
Correlation-Product Encoding.
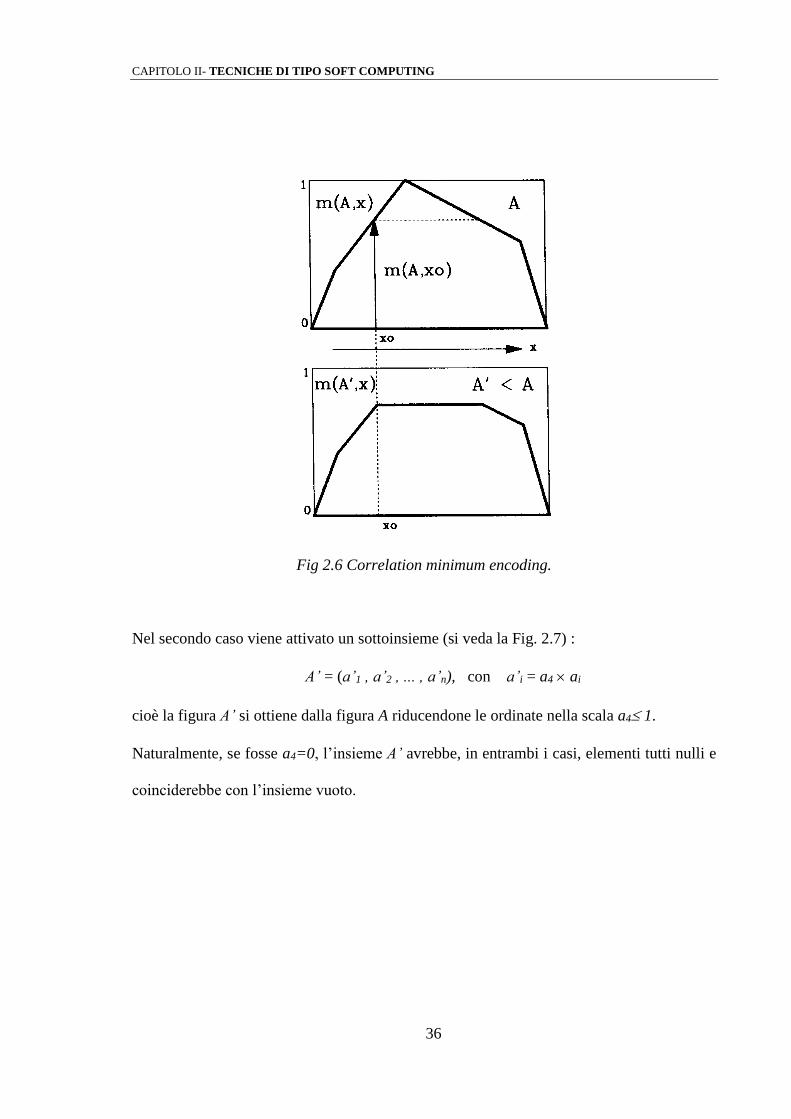
Nel primo caso viene attivato un sottoinsieme (si veda la Fig. 2.6) :
A’ = (a’1 , a’2 , ... , a’n), con a’i = min (a4 , ai)
cioè la figura A’ si ottiene dalla figura A tagliandone la parte superiore ad a4.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
36
Fig 2.6 Correlation minimum encoding.
Nel secondo caso viene attivato un sottoinsieme (si veda la Fig. 2.7) :
A’ = (a’1 , a’2 , ... , a’n), con a’i = a4 ai
cioè la figura A’ si ottiene dalla figura A riducendone le ordinate nella scala a4 1.
Naturalmente, se fosse a4=0, l’insieme A’ avrebbe, in entrambi i casi, elementi tutti nulli e
coinciderebbe con l’insieme vuoto.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
37
Fig 2.7 Correlation product encoding.
2.2.6 Associazione fuzzy input-output
La seconda operazione di un sistema fuzzy consiste nell’attivare gli insiemi output, in
funzione delle regole applicabili e degli insiemi già attivati in input. Nel nostro esempio di
riferimento, avendo già attivato gli insiemi A’i, B’i, occorrerà ora determinare in che misura
attivare gli insiemi Ck nel dominio (z1 , z2 , ... , zp) della variabile z.
Incominciamo a considerare il caso di una sola associazione input-output, espressa da
una sola regola con un solo antecedente : A B, per esempio “Temperatura alta
Velocità ventilatore alta”.
Sappiamo che A e B sono due vettori non binari :
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
38
A = (a1 , a2 , ... , an)
B = (b1 , b2 , ... , bm)
di dimensioni rispettive n, m.
Per ottenere l’output B dall’input A occorrerebbe allora, da un punto di vista
matematico, moltiplicare il vettore A per una opportuna matrice M di dimensioni n m e
con determinati elementi mij :
B = A M , con bj = i ai mij , per 0 i n, 0 j m. (2.35)
Le operazioni fuzzy su vettori e matrici vengono eseguite nel modo seguente : alla somma
di elementi si sostituisce l’operatore max e al prodotto di elementi l’operatore min.
Questa operazione fondamentale è denominata Composizione Min-Max :
i ai diventa max (ai)
ai aj diventa min (ai, aj)
(ai aj) diventa max(min(ai , aj))
Pertanto avremo, al posto della moltiplicazione B = A M la Composizione Min-Max (“o”
è il relativo operatore) :
B = (A o M), con bi = max min (ai, mij) (2.36)
Vi sono due modi per ottenere gli elementi di mij di M :
Correlation-Minimum Encoding : mij = min (ai, bj)
Correlation-product Encoding : mij = ai bj
Nei due casi, mij è il prodotto, fuzzy o normale, degli elementi ai, bj e la matrice M è
fornita rispettivamente da :
M = AT o B (2.37)
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
39
oppure
M = AT B (2.38)
dove AT è il vettore trasposto di A (verticale se A è orizzontale).
In pratica, però, non si ha mai una sola regola, bensì un repertorio di r regole :
A1 B1 A’1 B’1
A2 B2 cioè anche A’2 B’2
Ar Br A’r B’r
Non tutte le regole saranno generalmente applicabili, perché al valore attuale della
variabile x corrisponderanno solo pochi insiemi A’i non nulli, come abbiamo già rivelato.
Otterremo quindi solo pochi insiemi output B’i , che sarà opportuno consolidare in un solo
insieme B’ .
Il modo più semplice per farlo è il ricorso ad una loro combinazione lineare :
B’ = i (Wi B’j) (2.39)
dove i pesi Wi dovrebbero riflettere la credibilità, la frequenza o la forza della regola
Ai Bi .
Comunemente però si adotta Wi = 1, per cui B’ si riduce a una semplice somma :
B’ = i B’i (2.40)
Esaminiamo, infine il caso più realistico costituito da regole con più antecedenti nella
premessa.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
40
Basterebbe considerare due antecedenti A, B connessi da “and”, poiché i risultati possono
essere generalizzati facilmente a qualunque numero di antecedenti, comunque connessi.
Si abbia dunque la regola :
A and B C
che potremo scindere nelle due seguenti :
A C1
B C2
C = C1 and C2
I valori attuali delle variabili x, y attivano i sottoinsiemi A’ e B’, quindi l’applicazione in
parallelo delle due regole produrrà, nel caso di correlation-Minimum Encoding, i
corrispondenti C’1 e C’2 .
Nel caso invece di due antecedenti con connettivo “or” :
A or B C ,
al posto dell’intersezione occorrerebbe operare la congiunzione tra C’1 e C’2 .
2.2.7 Metodi di defuzzificazione
Il processo di defuzzificazione consiste nell'estrapolazione del valore più
rappresentativo dall’universo del discorso.
Dato un sottoinsieme fuzzy F sullo spazio d’uscita Y, il processo di defuzzificazione ha
il compito di selezionare un opportuno elemento y. I metodi utilizzati per realizzare tale
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
41
operazione sono diversi; i più noti sono il metodo del massimo ed il metodo del centro di
gravità.
Il primo metodo assume come punto rappresentativo di C’ il suo valore massimo
max ',m C zk con 1 k p . Si ottiene così un determinato valore di k in corrispondenza
del quale si ha il valore cercato. Il metodo però fallisce nel caso di più massimi e ignora la
maggior parte dell’informazione contenuta nella funzione m C zk' , . Il secondo metodo,
quello più usato, consiste nel determinare l’ascissa del centroide dell’area sottesa alla
funzione m C zk' , , cioè del suo baricentro
z
m C z z
m C z
k kk
kk
0
' ,
' , (2.41)
Naturalmente nel caso di dominio continuo della variabile z occorre sostituire alle
sommatorie gli integrali. Posto m C z f z' , si ha
z
f z zdz
f z dz
f z zdz
A0
(2.42)
dove A è l’area sottesa alla funzione f(z). Una proprietà importante, e di interesse pratico, è
la seguente: tagliando l’area globale in n strisce verticali di area Ai e centroide zi si ha
zA z
A
A z
A
i i
i
i i
0
(2.43)
Questa proprietà semplifica i calcoli in quanto l’area A è generalmente la somma di figure
semplici (triangoli, rettangoli o trapezi) il cui centroide si calcola facilmente.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
42
2.3 GLI ALGORITMI GENETICI
Gli algoritmi genetici (GA = Genetic Algorithms) furono proposti inizialmente da J.H.
Holland [12] nel 1975. Da allora sono stati oggetto di molti studi e recentemente si è
iniziato ad utilizzarli anche per applicazioni pratiche. Essi costituiscono un modello
computazionale idealizzato dell'evoluzione darwiniana, basata sui due principi della
variazione genetica e della selezione naturale. Gli individui di una popolazione hanno
patrimoni genetici più o meno differenti (variazione genetica). Ad ogni generazione,
coppie di individui si uniscono per generare altri individui, che saranno dotati di un
patrimonio genetico risultante dalla combinazione dei patrimoni dei genitori.
L'adattamento degli individui all'ambiente ("fitness") dipende dal loro patrimonio genetico.
Gli individui con maggiore fitness sono mediamente favoriti (selezione naturale) rispetto
agli altri: essi tendono a vivere di più, a riprodursi di più, trasmettendo alla discendenza
parte del loro patrimonio genetico, già rivelatosi competitivo.
Negli algoritmi genetici il patrimonio genetico di un individuo è rappresentato
generalmente da una stringa di n simboli o geni. Ogni gene è un simbolo tratto da un
alfabeto di p simboli; in particolare, i simboli possono essere 0, 1 (p = 2), avendosi allora
stringhe binarie. Si possono pertanto avere pn individui diversi che, nel caso binario, sono
vertici di un iper-cubo di n dimensioni. Una popolazione è costituita da m stringhe, aventi
tutte la stessa lunghezza n. Nella soluzione di un problema, mediante un algoritmo
genetico, le stringhe di una popolazione rappresentano altrettante ipotesi di soluzione di
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
43
quel problema. La bontà delle soluzioni è misurata dalla fitness delle stringhe. Inizialmente
le fitness sono piuttosto scadenti e si cerca allora di fare evolvere la popolazione in modo
da fare emergere, dopo un numero ragionevole di generazioni, almeno una soluzione
"molto buona", con fitness elevata. Per ottenere tale evoluzione, gli algoritmi si valgono di
operazioni genetiche, ciascuna eseguita su uno o più individui, scelti con criteri
probabilistici. Le operazioni genetiche più comuni sono:
1) Riproduzione. In una popolazione di M individui (generazione attuale) se ne
scelgono, con probabilità proporzionale alla loro fitness solo m<M, che costituiscono
la generazione successiva.
2) Cross-over. Questa operazione coinvolge due stringhe genitrici
A A A
B B B
n
n
1 2
1 2
, ,...,
, ,...,
Dopo aver scelto in modo random un indice k (1 k n) si effettua uno scambio di
geni tale da produrre le stringhe figlie
A A A A B B B
B B B B A A A
k k k k n
k k k k n
1 2 1 1 2
1 2 1 1 2
, ,..., , , , ,...,
, ,..., , , , ,...,
Una variante di questa operazione sceglie in modo random due indici k ed l ed
effettua lo scambio
A A A B B A A
B B B A A B B
k k l l n
k k l l n
1 2 1 1
1 2 1 1
, ,..., , ,..., , ,...,
, ,..., , ,..., , ,...,
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
44
3) Mutazione. Opera su una sola stringa A nel modo seguente: dopo aver scelto, in
modo casuale, un indice k si sostituisce al simbolo Ak un nuovo simbolo Ak
' tratto
in modo random dall’alfabeto dei geni. Si ottiene così la trasformazione
A A A A A Ak n k n1 1,..., ,..., ,..., ,...,'
L’algoritmo genetico di base (dal quale derivano molte versioni) è il seguente
Si ha una popolazione U di m stringhe, ordinate in funzione della loro fitness.
Si sceglie con probabilità Pmut (molto piccola) un gene di una stringa e si opera la
mutazione.
Si scelgono con probabilità P Pcross mut due stringhe e si opera il cross-over.
Si riordinano le stringhe in funzione della loro fitness e se ne scelgono m, con
probabilità proporzionale alla fitness, costituendo così la nuova popolazione U.
Si ritorna al punto 1 fino a che non è stato soddisfatto un predefinito criterio di stop
(per esempio un numero massimo di iterazioni).
Il problema sarà risolto se almeno una delle stringhe della popolazione finale costituisce
una soluzione vicina all’ottimo assoluto. Sostanzialmente l’algoritmo genetico è un metodo
di ricerca di soluzioni ottimali nel “paesaggio” multidimensionale della fitness. Tale
metodo è considerato più efficiente di quello denominato “hill climbing” che presenta
l’inconveniente di offrire soluzioni che sono minimi relativi e non assoluti. Per l’algoritmo
genetico la mutazione introduce, così come il coefficiente di momentum per le reti neurali,
un disturbo che tende ad evitare la convergenza prematura su un ottimo relativo.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
45
E’ importante anche rilevare che, nell’ambito di una stringa, possono emergere, in un
certo momento, determinate sequenze di geni che le conferiscono una fitness superiore alla
media. Un esempio di schema, in una stringa binaria con n=13 è
01###100#1101
dove # indica un qualunque simbolo legale. Si definisce “ordine” di uno schema il
numero di simboli definiti in esso (9 nel precedente esempio). Si ritiene che l’operazione di
cross-over faciliti la combinazione di schemi buoni di ordine basso (“building blocks”) in
schemi migliori di ordine elevato. Un teorema dovuto ad Holland assicura, sotto
determinate condizioni, la convergenza dell’algoritmo. Gli schemi con fitness superiore
alla media tendono a diffondersi esponenzialmente nella popolazione.
Tuttavia, se esistono soluzioni diverse, ugualmente buone ma con schemi
contrastanti, l’operazione di cross-over può produrre, da genitori buoni, ibridi cattivi.
Generalmente nel passaggio da una generazione all’altra che, come abbiamo visto, tende a
riprodurre gli m individui migliori, si preferisce comunque copiare l’individuo migliore
della generazione precedente, per non rischiare la perdita del suo prezioso patrimonio
genetico.
Per risolvere un problema mediante l’algoritmo genetico è necessario formalizzare le
ipotetiche soluzioni con stringhe di simboli aventi la stessa lunghezza . Come primo
esempio consideriamo il semplice problema di trovare la regola che sintetizza i casi
accettabili della tabella:
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
46
Caso Prezzo Qualità Accettabilità
1 450 3 si
2 500 3 si
3 600 3 no
4 450 2 si
5 500 2 si
6 600 2 no
7 450 1 no
8 500 1 no
9 600 1 no
La regola cercata sarà del tipo
(Op1 VP) Op2 (Op1 VQ)
con la seguente codifica binaria
Op1 = operatore 1 (0 = maggiore o uguale, 1 = minore o uguale)
VP = valore prezzo (01 = 450, 10 = 500, 11 = 600, 00 non usato)
Op2 = operatore 2 (0 = AND, 1 = OR)
VQ = valore qualità (01 = 1, 10 = 2, 11 = 3, 00 non usato)
Per esempio la regola 0111101, una stringa di 7 bit equivale a
(Prezzo 600) OR (Qualità 1)
La fitness di una regola è uguale al rapporto tra il numero di casi accettabili che esso
soddisfa e il numero totale di tali casi (la regola precedente ha fitness nulla). Partendo
allora da una popolazione sufficientemente grande di stringhe (nel nostro caso ne sono
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
47
possibile 128), applicando l’algoritmo genetico, si giunge, in un ragionevole numero di
generazioni, alla migliore soluzione che ha fitness 1 ed è
1100010=(Prezzo 500) OR (Qualità 2).
Per completare la breve trattazione sugli algoritmi genetici occorre sottolineare che
esistono una serie di operatori genetici non standard che permettono di migliorare le
prestazioni dell’algoritmo genetico sia in termini di velocità di convergenza che in termini
di accuratezza della soluzione [13] [14].
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
48
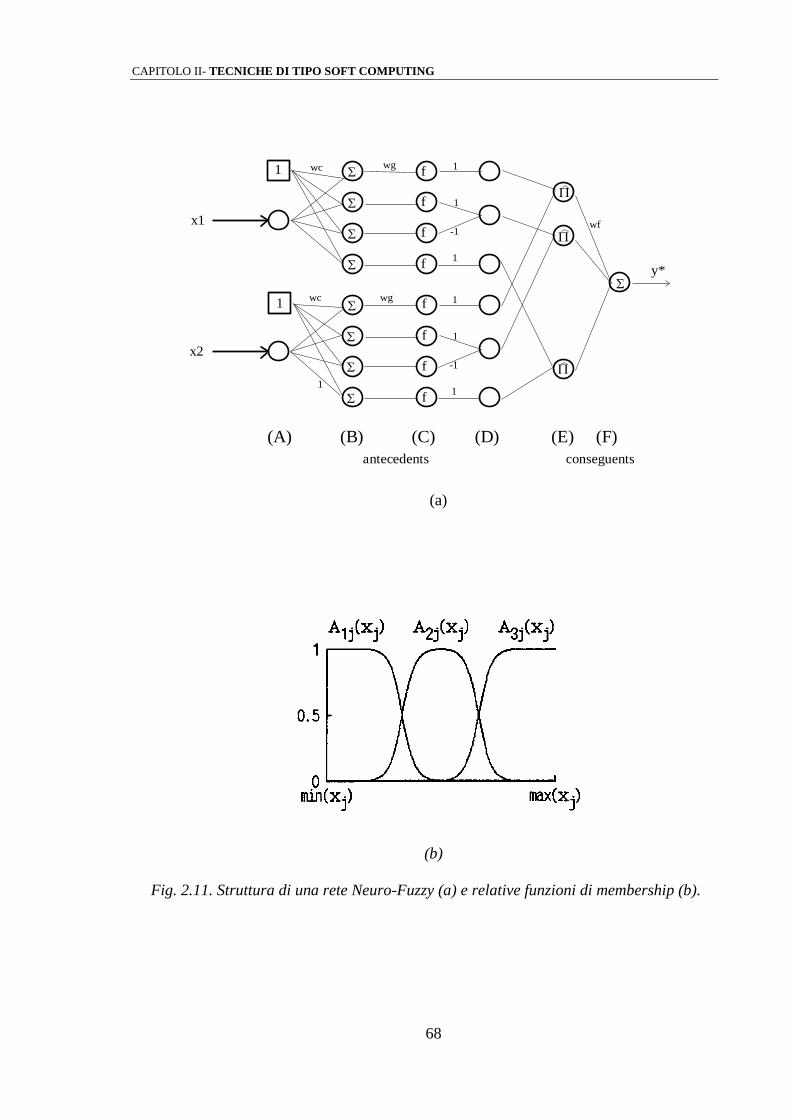
2.4 LE RETI NEURALI CELLULARI
Le reti neurali cellulari (CNN), la cui prima formulazione si deve a L.O.Chua, fanno
la loro prima apparizione nell’ottobre 1988 [15]. Le CNN, costituiscono un particolare tipo
di reti neurali artificiali, da cui traggono alcuni aspetti innovativi tra cui il processamento
asincrono parallelo, tempo continuo (circuiti analogici), derivante dalle interazioni degli
elementi della rete: esse trovano un ottimo campo di impiego nell’elaborazione delle
immagini. Oggi il campo di applicazione di tali sistemi si è ampliato enormemente tanto da
trovare impiego in ambiti totalmente differenti da quello originale. Sono state proposte
applicazioni nella elaborazione dei dati di tipo biomedicale, nella robotica, nelle memorie
associative, nella simulazione di sistemi complessi sia fisici che biologici [16],[17].
2.4.1 Architettura delle reti neurali cellulari (CNN): il modello elettrico
L’unità di base di una CNN è detta cella ed è implementata mediante un circuito
elettrico elementare costituito da elementi lineari come condensatori, resistenze, generatori
indipendenti e generatori pilotati, e non lineari implementati anch’essi con generatori
pilotati non lineari.
Ogni singola cella è in grado di interagire in modo diretto con le celle ad essa adiacenti
ed indirettamente con tutte le altre, sfruttando l’effetto di propagazione degli stimoli
[15],[17].
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
49
Una CNN computazionalmente, può essere considerata come una matrice di celle n-
dimensionale: nel nostro caso ci limiteremo a CNN bidimensionali ovvero considereremo
matrici MxN, tenendo conto del fatto che quanto diremo potrà essere facilmente esteso ai
casi a più dimensioni.
Un esempio di CNN bidimensionale 3x3 in cui vengono indicate le connessioni tra le
celle, è mostrato in Fig. 2.8.
C(1,1) C(1,2) C(1,3)
C(2,1) C(2,2) C(2,3)
C(3,1) C(3,3)C(3,2)
Fig. 2.8 Schema di CNN 3x.3
Detta C(i,j) la cella della matrice/CNN, appartenente alla i-esima riga e alla j-esima
colonna, si definisce intorno Nr(i,j) di raggio r della cella, il seguente:
N i j C k l k i l j r k M l Nr( , ) ( , )|max | |,| | , , 1 1 (2.44)
con r 0 .
La figura 1.9 mostra due esempi di intorni di una cella C(i,j), indicata in nero,
rispettivamente di raggio r=1 ed r=2.
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
50
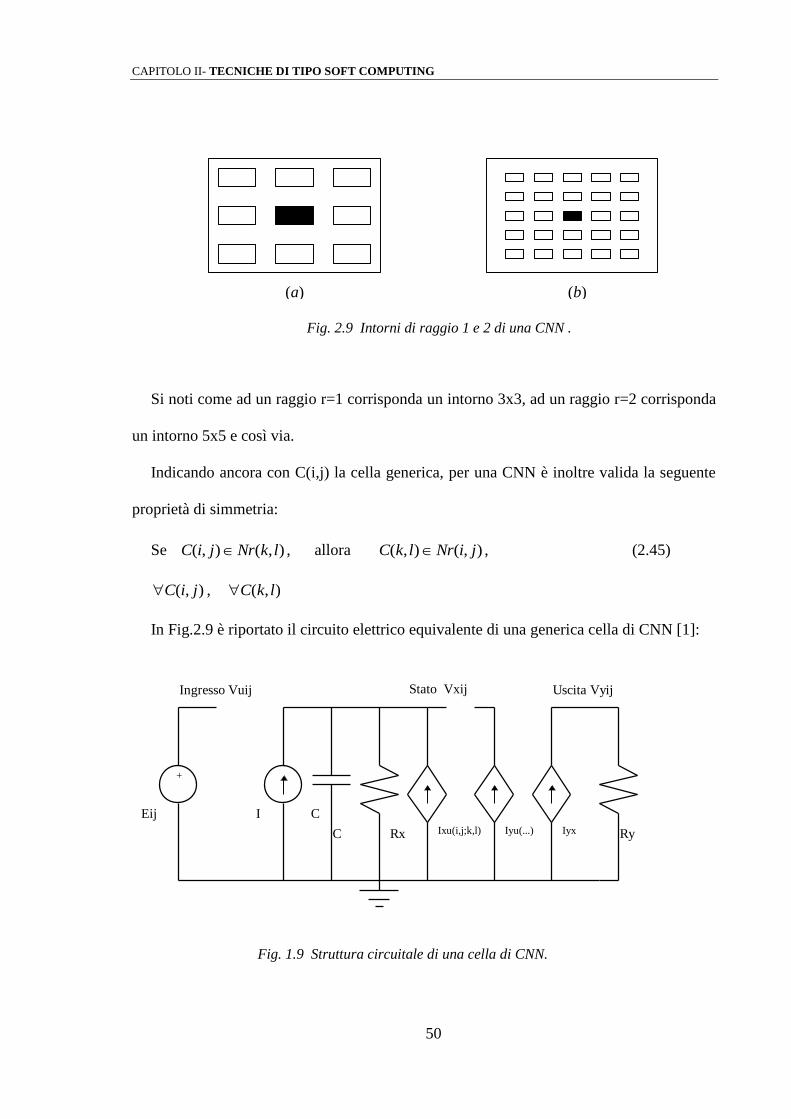
(a) (b)
Fig. 2.9 Intorni di raggio 1 e 2 di una CNN .
Si noti come ad un raggio r=1 corrisponda un intorno 3x3, ad un raggio r=2 corrisponda
un intorno 5x5 e così via.
Indicando ancora con C(i,j) la cella generica, per una CNN è inoltre valida la seguente
proprietà di simmetria:
Se C i j Nr k l( , ) ( , ) , allora C k l Nr i j( , ) ( , ) , (2.45)
C i j( , ) , C k l( , )
In Fig.2.9 è riportato il circuito elettrico equivalente di una generica cella di CNN [1]:
+
Eij I C
Ixu(i,j;k,l) Iyu(...) Iyx
Stato VxijIngresso Vuij Uscita Vyij
C Rx Ry
Fig. 1.9 Struttura circuitale di una cella di CNN.
fig
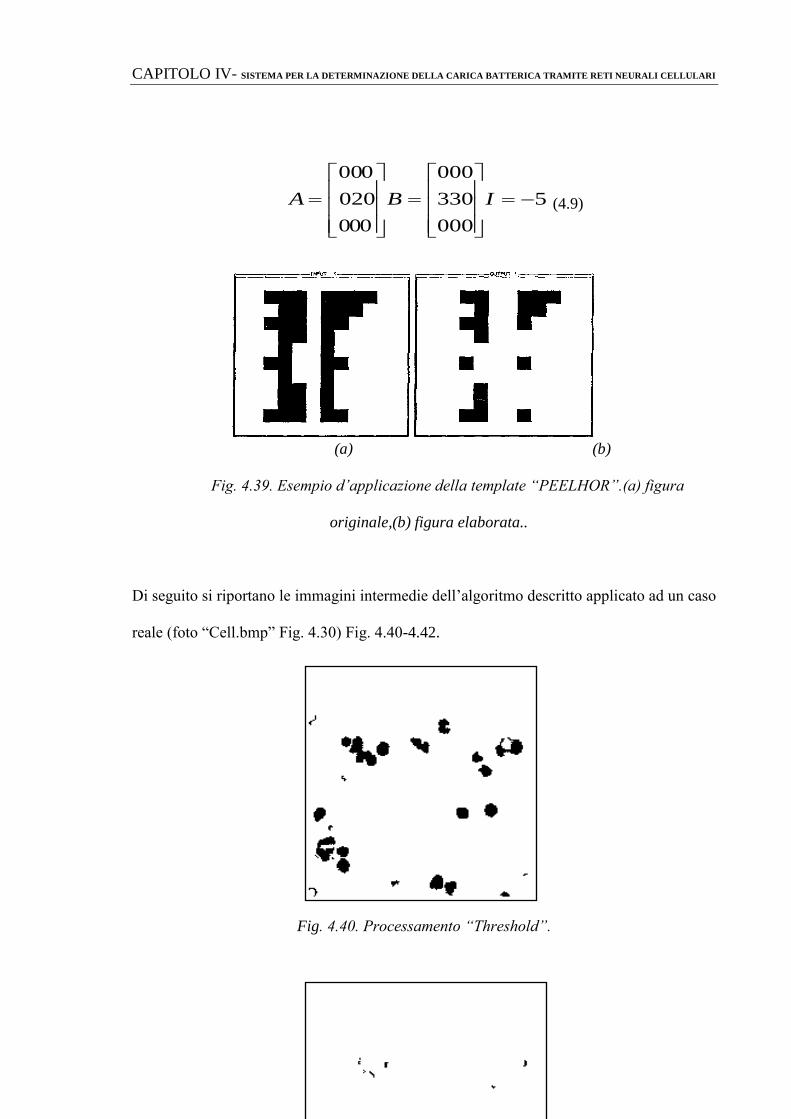
.3
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
51
I suffissi u, x e j, indicano rispettivamente l’ingresso, lo stato e l’uscita del circuito.
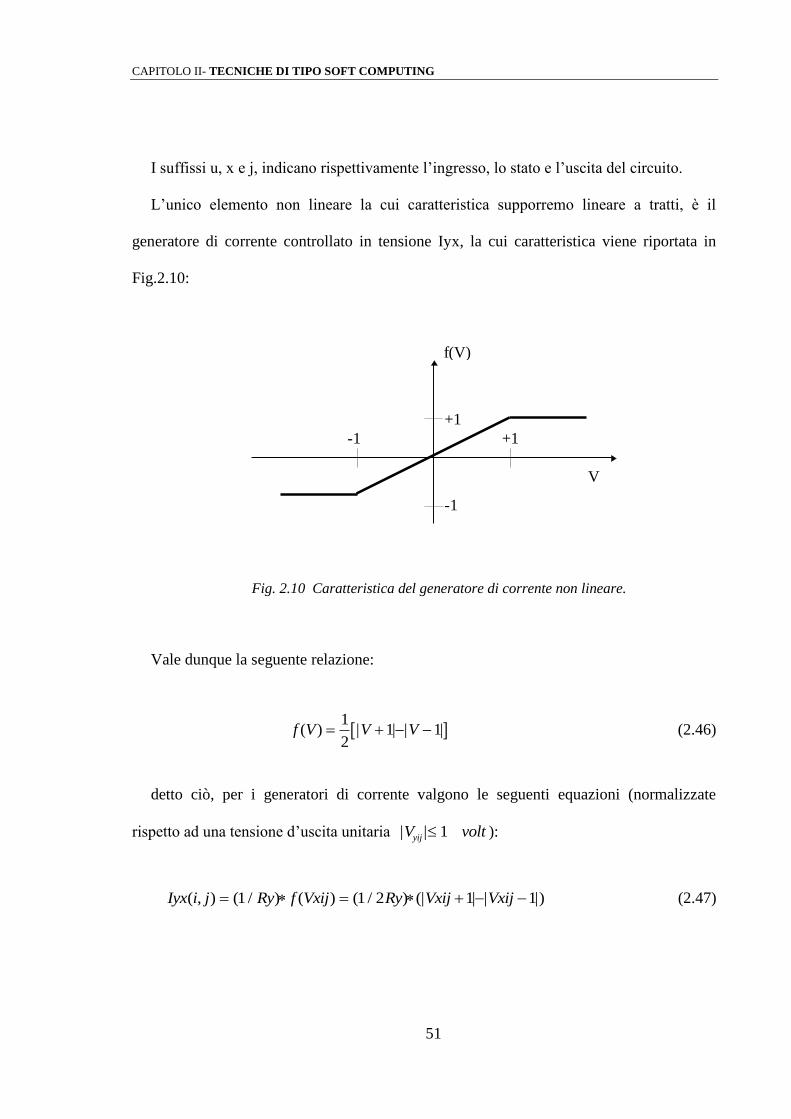
L’unico elemento non lineare la cui caratteristica supporremo lineare a tratti, è il
generatore di corrente controllato in tensione Iyx, la cui caratteristica viene riportata in
Fig.2.10:
f(V)
V
+1
-1
-1 +1
Fig. 2.10 Caratteristica del generatore di corrente non lineare.
Vale dunque la seguente relazione:
f V V V( ) | | | | 1
21 1 (2.46)
detto ciò, per i generatori di corrente valgono le seguenti equazioni (normalizzate
rispetto ad una tensione d’uscita unitaria | |V voltyij 1 ):
Iyx i j Ry f Vxij Ry Vxij Vxij( , ) ( / ) ( ) ( / ) (| | | |) 1 1 2 1 1 (2.47)
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
52
Ixy i j k l A i j k l VyklRy
A i j k l Iyx k l( , ; , ) ( , ; , ) ( , ; , ) ( , ) 1
(2.48)
Ixu i j k l B i j k l Vukl( , ; , ) ( , ; , ) (2.49)
Si noti come l’interazione tra la cella C(i,j) e la cella C(k,l) avvenga mediante generatori
di corrente controllati in tensione.
Le grandezze A e B vengono dette maschere di convoluzione o “templates”: esse,
unitamente alla corrente I, influenzano il comportamento dell’intera CNN.
Una condizione necessaria per la convergenza verso uno stato stabile della CNN, è che
A sia una matrice simmetrica, ovvero:
k l Nr, , sia: A k l A l k( , ) ( , ) (2.50)
inoltre, se A(0,0) > 1, ogni uscita dello stato stabile sarà compresa tra i valori 1 e -1.
La template A viene denominata “feedback template”, essendo legata alle uscite
circuitali e svolgendo una vera e propria azione di retroazione sullo stato.
Per quel che riguarda la matrice B, essa può interpretarsi come un operatore di controllo
e pertanto viene denominata “control template”, essendo peraltro legata agli ingressi
circuitali [18] [19].
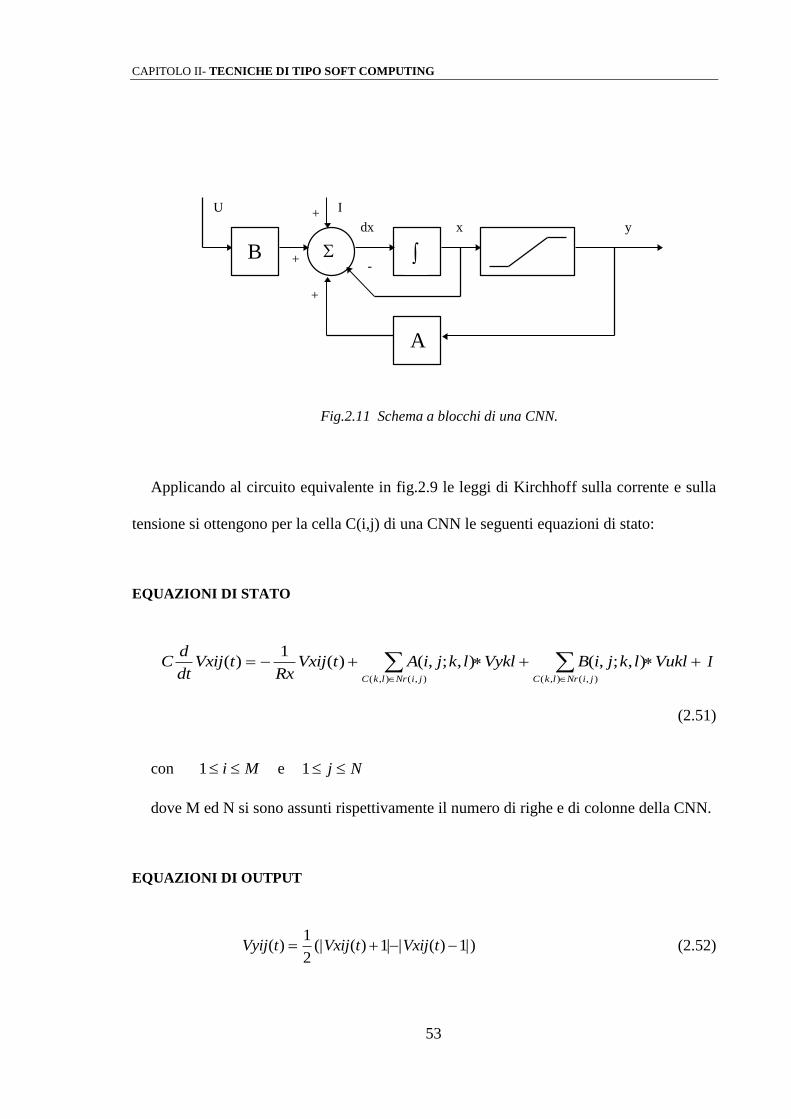
Lo schema a blocchi di una CNN standard viene rappresentato in Fig. 2.11 [16]:
CAPITOLO II- TECNICHE DI TIPO SOFT COMPUTING
53
B
A
U I
x dx y
+
-
+
+
Fig.2.11 Schema a blocchi di una CNN.
Applicando al circuito equivalente in fig.2.9 le leggi di Kirchhoff sulla corrente e sulla
tensione si ottengono per la cella C(i,j) di una CNN le seguenti equazioni di stato: