Analisi d’immagine e pattern recognition in matlab Introduzione Matlab Sistemi CAD per la Medicina Esercizi generali Ricette: Generazione di numeri interi compresi tra a e b, con distribuzione uniforme, senza usare randi: a = 5, b = 12, n = 10000, z = floor(rand(1,n) * (b+1-a) + a); hist(z, a:b) Notare che l’uso di round (e conseguentemente con b anziché b+1 nella parentesi tonda al fattore moltiplicativo) non sarebbe corretto perché darebbe una distribuzione non uniforme ma con primo e ultimo bin riempiti a metà. Stessa cosa per numeri double! Esercizi di analisi d’immagine e pattern recognition ESERCIZI GENERALI IN MATLAB 1
Transcript
Analisi d’immagine e pattern recognition in matlab
Introduzione
Matlab
Sistemi CAD per la Medicina
Esercizi generali
Ricette:
Generazione di numeri interi compresi tra a e b, con distribuzione uniforme, senza
usare randi:
a = 5, b = 12, n = 10000, z = floor(rand(1,n) * (b+1-a) + a); hist(z, a:b)
Notare che l’uso di round (e conseguentemente con b anziché b+1 nella parentesi
tonda al fattore moltiplicativo) non sarebbe corretto perché darebbe una distribuzione non
uniforme ma con primo e ultimo bin riempiti a metà.
Stessa cosa per numeri double!
Esercizi di analisi d’immagine e pattern recognition
ESERCIZI GENERALI IN MATLAB
1. Scrivere un programma che chieda all’utente di inserire un numero N, e poi calcoli la somma dei numeri naturali da 1 a N sia “normalmente” (ciclo for? sum di un vettore?) sia con la formula di Gauss:
M = N(N+1)/2.
2. Data una matrice A, verificare che essa sia quadrata3. In una gara a staffetta, i valori seguenti sono le distanze percorse in metri e i tempi
impiegati in secondi:dist 560 440 490 530 370
tempo 10.3 8.2 9.1 10.1 7.5
1
(a) calcolare la velocità media di ogni percorso, (b) individuare quello con velocità media più alta (max), (c) individuare i percorsi con velocità media maggiore della media di tutte le velocità medie dei vari percorsi (find…).
find(x == max(x)) (più di un punto di massimo)
x(logical([0 0 0 1 1]))
x(find(x>0.6))
x(x>0.6)
4. Scrivere una funzione che, dati n, a, b, generi un vettore riga di n numeri casuali con distribuzione uniforme (non interi, o sarebbe risolto dalla sintassi della randi; usare rand) compresi tra a e b esclusi, poi calcoli la media che sarà scritta a video, e infine restituisca gli indici dei numeri che superano (>=) la media.
5. Scrivere una funzione che, dati n, a, b, generi n numeri casuali interi tra a e b inclusi, poi calcoli la media, e infine restituisca gli indici dei numeri che superano (>=) la media.
6. scrivere una funzione che, dati i cateti di un triangolo rettangolo, calcoli l’ipotenusa.7. Scrivere un programma per il calcolo delle radici reali di un’equazione algebrica di
secondo grado.8. Scrivere un programma per il calcolo delle radici reali distinte / reali coincidenti /
complesse coniugate di un’equazione algebrica di secondo grado.9. Data una matrice quadrata A in ingresso realizzare una funzione Matlab chiamata
traccia(A) che restituisce la traccia della matrice, ossia la somma degli elementi sulla diagonale principale.
10. Si scriva una funzione denominata “doppio_per” che accetti in ingresso due matrici A e B qualunque, e restituisca due matrici C= A*B e D = B*A; ove le matrici non fossero quadrate, il programma deve comunicarlo all’utente senza fermarsi per errore.
11. Scrivere una funzione MATLAB che accetti come input un vettore (e.g. di interi) V, e due scalari a e b, e restituisca tre valori: uno scalare che dica quanti sono i numeri compresi tra a e b (limiti inclusi), un vettore che dica quali sono questi elementi, e un altro che dica in quale posizione si trovano nel vettore V. length(find(V>=a & V <= b)), V(find(V>=a & V <= b)), find(V>=a & V <= b) (oppure usare due find separate e poi intersect(). E se fosse stato <a oppure > b?
12. Scrivere una funzione Matlab che effettui la somma di tutti i numeri memorizzati nel vettore V, di lunghezza arbitraria, passatole come parametro, che occupano le posizioni pari (ossia, calcolare V (2)+V (4)+V (6)+· · ·). Riscrivere il codice in modo che effettui la somma di tutti i numeri in posizione dispari.
function s = sommaDispari(v)
% lunghezza
% genero indici dispari
% indicizzo v con gli indici generati
% sommo gli elementi rimasti
end
2
13. La distribuzione triangolare è una distribuzione di probabilità continua la cui funzione di densità di probabilità descrive un triangolo, ovvero è nulla all’esterno di due valori estremi ed è lineare tra questi ed un valore intermedio (la moda) arbitrariamente situato tra a e b. Scrivere una funzione triangle.m per il calcolo della densità di probabilità triangle(t), e si disegnino i grafici di triangle(t), triangle(t/2), triangle(t – 0:5), in un opportuno range di valori di t. Suggerimento: la funzione dev’essere normalizzata, per cui il valore nel punto di massimo è 2/(b-a).
14. Scrivere una funzione che genera una matrice 2x2 di 2 se si passa come argomento 2, una matrice 3x3 di 3 se si passa come argomento 3 e così via fino a 5 compreso. In tutti gli altri casi deve restituire 1.
15. Generare una matrice quadrata di ordine n (ove n è un dato introdotto dall'esterno) con elementi generati a caso da una distribuzione uniforme nell'intervallo [0,1] e calcolare
a. un vettore che contiene la somma degli elementi di ciascuna colonna;b. un vettore che contiene la somma degli elementi di ciascuna riga;c. un vettore che contiene la somma degli elementi di ciascuna riga elevati al
quadrato;d. il massimo degli elementi della matrice;e. la somma di tutti gli elementi della matrice.
16. Date le matrici A=[1 2 3; 4 5 6; 7 8 9]; B=[2 -1 0; -1 2 -1; 0 -1 2]; spiegare cosa producono le seguenti istruzioni:
a. A(:,[1,3])=B(:, 1:2);b. C=A./B;c. C=A.^B;d. A([1:2],:)=[];e. D=B([3,2],1:2:3);
17. Sia b un vettore di 10 componenti con elementi pseudocasuali, si crei il vettore d che abbia come elementi solo gli elementi di b maggiori di 0:5;
18. Scrivere una funzione MATLAB che accetti come input un vettore (e.g. di interi) V, e due scalari a e b, e restituisca tre valori: uno scalare che dica quanti sono gli elementi di V compresi tra a e b, un vettore che riporti questi elementi, e un altro vettore che riporti le posizioni di questi elementi in V.
X = 0:5;
Y = X + 0.05*(rand(1,6)-0.5)
3
scatter(X,Y) o plot(X,Y,’o’)
p = polyfit(X,Y,1); % p(1) e’ la pendenza, p(2) l’intercetta
FX= polyval(p,X);
hold on
plot(X,FX)
function provatictoc
disp('per partire premi un tasto)
pause
tic
disp('ora aspetta quanto vuoi e poi premi nuovamente invio')
pause
t = toc
19. scrivere tre funzioni; la prima, denominata euclDist, calcoli la distanza euclidea tra due punti nel piano, usando il teorema di Pitagora (in seguito, controllare cosa fa la funzione di Matlab pdist); la seconda, denominata meanPoint, date le coordinate di due punti calcoli e restituisca le coordinate del punto medio del segmento avente i due punti per estremi; la terza, denominata triangles, date le coordinate di tre punti nel piano:
a. tracci tali punti con plot usando come marker un cerchietto (plot), b. scriva nei pressi di ogni punto tracciato le lettere A, B, C per indicare i vertici
(text); non ci si preoccupi eccessivamente di posizionare precisamente le lettere A, B, C rispetto ai punti e alle linee tracciate al seguente punto (c).
c. congiunga i punti, precedentemente tracciati, con segmenti di retta (plot o line), generando così un triangolo; nei pressi dei punti medi dei lati dei triangoli (calcolati tramite la funzione meanPoint) scriva a, b, c, dove a indica il lato opposto al vertice A, etc
d. calcoli la lunghezza dei lati tramite la funzione euclDist scritta in precedenza, e scriva sulla command window qual è la lunghezza di ogni lato
e. calcoli l’area A del triangolo tramite la formula (det):
area=12|xA y A 1xB yB 1xC yC 1|
e la scriva nella command window (“Area del triangolo: …”).
Note:
Usare, come tipo di variabile per esprimere le coordinate di un punto nel piano, un vettore (riga o colonna) a due componenti.
4
Teorema di Pitagora: sqrt(sum((A-B).^2))
Riflessometro
Scrivere un programma che effettui un test dei riflessi dell’utente. Il programma ripete un
numero prestabilito di volte le seguenti operazioni:
a. genera un numero casuale x compreso tra un valore minimo e un valore massimo;
tale numero sarà usato come ritardo casuale; è naturalmente possibile e consigliato
generare in un’unica operazione (vettorialmente) tutti i numeri casuali xi da
adoperare come tempi di ritardo, e ciclare poi su di essi;
b. scrive a video “attenzione!” e attende x secondi;
c. scrive a video “premi un tasto” e si dispone ad attendere la pressione di un tasto da
parte dell’utente;
d. quando il tasto è premuto, il programma misura il tempo trascorso tra il messaggio
“premi un tasto” e la pressione effettiva del tasto, e memorizza tale tempo (di
reazione, legato alla rapidità dei riflessi dell’utente).
Alla fine dell’esecuzione, sarà disponibile un vettore di misure di tempi di riflesso e un
vettore di tempi di ritardo iniziale dato dal programma; sarà possibile studiare:
se vi è una tendenza all’aumento o alla diminuzione dei tempi di reazione con
l’aumentare del numero di prove (l’utente si stanca, oppure diventa più abile, o la sua
performance non degrada né migliora con il trascorrere del tempo);
se vi è correlazione tra i tempi di risposta e i tempi di ritardo (l’utente è più bravo se il
ritardo è breve o se invece è più lungo, o la sua abilità non dipende dal ritardo
iniziale).
la distribuzione dei tempi di reazione, confrontandola visualmente (o con un test di
gaussianità) con una distribuzione normale; avendo a disposizione un gran numero
di misure (almeno 100 o 200!) è possibile confrontare le distribuzioni dei tempi di
risposta dei primi run con quelli degli ultimi run, verificando se i campioni
appartengono alla medesima popolazione, oppure l’utente si è stancato o ha
migliorato le proprie prestazioni, e quindi le popolazioni differiscono
Naturalmente, sotto le mentite spoglie di un semplice test di psicologia sperimentale, si
nasconde un modo ludico per imparare qualcosa sulla programmazione e su Matlab, e
magari rispolverare qualche nozione di statistica elementare. In particolare:
l’uso delle istruzioni pause, tic, toc; come salvare e caricare dati da file;
graficare una serie temporale, e dedurne delle informazioni;
come calcolare un fit lineare di una serie di punti sperimentali;
5
come graficare un istogramma, come normalizzarlo, come tracciare una funzione
gaussiana con cui confrontare detto istogramma normalizzato;
come calcolare un coefficiente di correlazione (corrcoef);
come eliminare da un vettore dei dati evidentemente spuri; rimpiazzando
eventualmente questi dati con NaN, si può imparare cosa rappresenti questo
termine, e come trattare dati in cui esso è presente (nanmean, nanstd).
Prerequisiti: pause, tic, toc, pause, rand…
Aggiungere plot
Eliminazione dei dati spuri
E’ possibile che l’utente prema il tasto prima che il computer abbia emesso il segnale “premi
un tasto”. In questo caso i tempi registrati saranno molto brevi, dell’ordine di 0.10 o 0.15
secondi. Come fare per eliminare questi dati dal vettore dei risultati?
(Svuotare il buffer di tastiera prima del tic? NON E’ NECESSARIO, in matlab, perché se si
preme un tasto prima della pause tale pressione è eliminata dalla pause stessa!)
y(y < 0.15) = NaN;
poi si può usare nanmean e nanstd per avere la media e la deviazione standard.
Provare che cosa succede se non si mette il pause: qual è il tempo da sottrarre per evitare
un errore sistematico? (?) (eseguendo senza la pause, l’utente non deve premere nulla e il
programma va avanti da solo registrando non i tempi di risposta bensì i tempi di ritardo
dovuti all’esecuzione dell’istruzione tic (o della disp se questa è fatta dopo). Si tratta di tempi
sensibili?
Confronto con gaussiana
G ( x )= 1√2π σ
e−( x−x )2
2σ 2
Normalizzazione dell’istogramma
Considerare che occorre dividere l’istogramma Ni per l’area sottesa:
6
A=∑iN i∆ xi=∆ x∑
iN i=∆ x N
dove la somma è calcolata sui bin usati per l’istogramma, e N è il numero di run, ossia di dati
disponibili. Quindi:
N i'=N i /A
Calcolando, infatti, l’area dell’istogramma N i':
A'=∆ x∑iN i'=∆ x∑
i
N iN ∆ x
=1.
Plot tendenza, plot correlazione, corrcoef
L'indice o coefficiente di correlazione di Pearson tra due variabili statistiche x e y esprime
un’eventuale relazione di linearità tra di esse. L’indice di Pearson è definito in termini di
covarianza e deviazioni standard:
ρ=σ xyσx σ y
con:
Il coefficiente assume valori compresi tra -1 e 1: −1≤ρ≤1. Se ρ è positivo, la correlazione è
diretta, se è nullo, le variabili si dicono incorrelate o scorrelate, se ρ è negativo la
correlazione è inversa. Inoltre, la correlazione si considera debole se 0<|ρ|≤0.3, moderata
se 0.3<|ρ|≤0.7, forte se 0.7<|ρ|≤1, però tale distinzione è molto grossolana e insufficiente,
in quanto per valutare il risultato del calcolo del coefficiente di Pearson occorre anche tenere
conto della significatività statistica (il p-value) e della numerosità del campione. Per una
trattazione completa si rimanda a un trattato di statistica, quale per esempio []. Per gli scopi
di questo testo, basterà verificare se, visualmente, lo scatterplot dei dati di ritardo dello
stimolo e dei tempi di risposta dell’utente mostrano una certa correlazione: in caso di
correlazione positiva, si potrà dedurre che il particolare soggetto ha prestazioni migliori per
piccoli tempi di ritardo di presentazione dello stimolo; nella correlazione inversa, il soggetto
sarà più “bravo” per tempi di ritardo maggiori; infine, nel caso non vi sia una correlazione
7
importante, per il soggetto non vi sarà particolare dipendenza dal tempo di presentazione
polyfit NON funziona con NaN! Eliminare con idx = isnan(…)
Usare la funzione randn per generare i numeri casuali
function testGaussiana(n,bin,m,st) % testGaussiana(10000, 100, 0, 1)
8
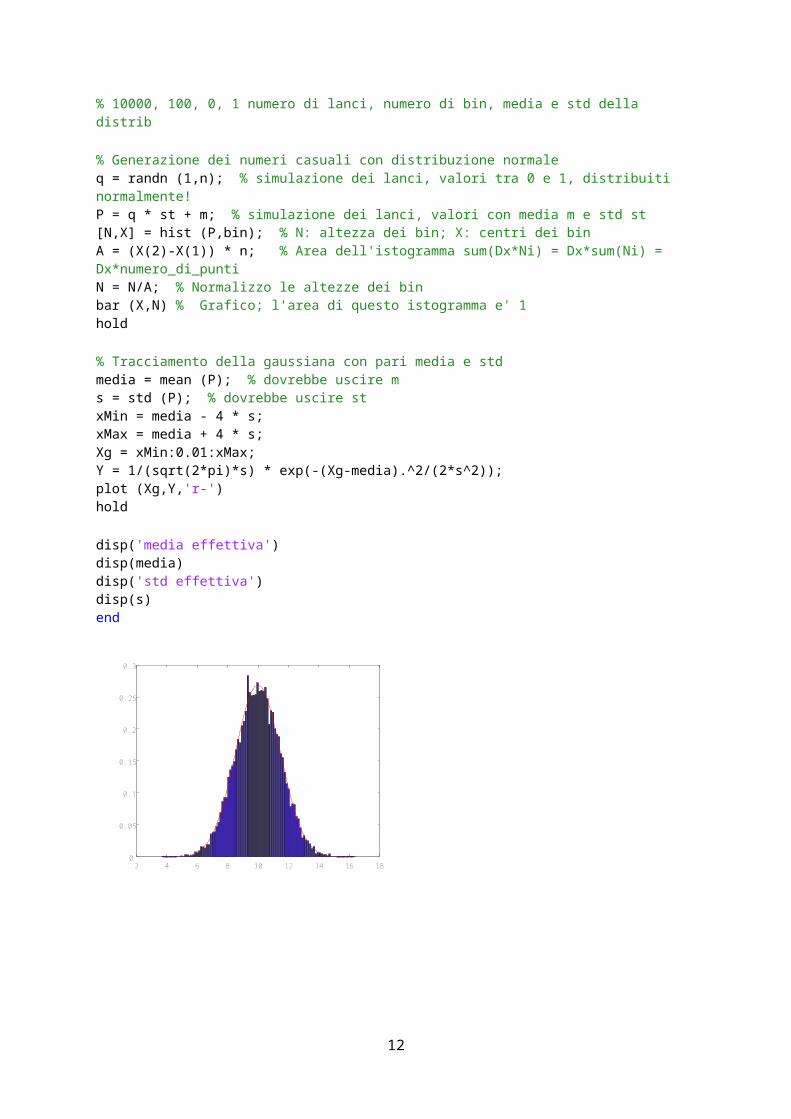
% 10000, 100, 0, 1 numero di lanci, numero di bin, media e std della distrib % Generazione dei numeri casuali con distribuzione normaleq = randn (1,n); % simulazione dei lanci, valori tra 0 e 1, distribuiti normalmente!P = q * st + m; % simulazione dei lanci, valori con media m e std st[N,X] = hist (P,bin); % N: altezza dei bin; X: centri dei binA = (X(2)-X(1)) * n; % Area dell'istogramma sum(Dx*Ni) = Dx*sum(Ni) = Dx*numero_di_puntiN = N/A; % Normalizzo le altezze dei binbar (X,N) % Grafico; l'area di questo istogramma e' 1 hold % Tracciamento della gaussiana con pari media e stdmedia = mean (P); % dovrebbe uscire ms = std (P); % dovrebbe uscire stxMin = media - 4 * s;xMax = media + 4 * s;Xg = xMin:0.01:xMax;Y = 1/(sqrt(2*pi)*s) * exp(-(Xg-media).^2/(2*s^2));plot (Xg,Y,'r-')hold disp('media effettiva')disp(media)disp('std effettiva')disp(s)end
2 4 6 8 10 12 14 16 180
0.05
0.1
0.15
0.2
0.25
0.3
9
Il gioco della vita
Il “gioco della vita” (“game of life”, o semplicemente “life”) è un automa cellulare
ideato dal matematico John Conway (Princeton University) negli anni sessanta. Esso
comparve in pubblico per la prima volta in Scientific American (ottobre 1970), nella rubrica
“Giochi matematici” di Martin Gardner [gar1970]. Non si tratta di un gioco nel senso classico
del termine, poiché non vi sono giocatori, non si vince e non si perde. Lo scopo è mostrare
come da regole semplici e da interazioni a molti corpi possano emergere comportamenti
complessi simili a quelli che si potrebbero riscontrare nella vita di una colonia di organismi
unicellulari. Una volta che i pezzi (le cellule) siano stati collocati nella loro posizione di
partenza su una “scacchiera” (usualmente una griglia idealmente infinita di caselle
quadrate), le regole determinano ciò che accade in seguito. L’andamento del gioco dipende
dunque esclusivamente dal numero e dalla posizione iniziale dei pezzi, dati che possono
essere variati a piacere, e dalle regole del gioco.
Le regole sono le seguenti:
1. Le cellule possono “essere vive” (e quindi occupano un posto sulla
scacchiera), o possono “morire” (e scompaiono dalla griglia).
2. Ogni casella ha otto caselle vicine, per cui una cellula può avere fino a otto
cellule vicine (i “primi vicini”).
3. Una casella vuota, che abbia esattamente tre cellule vicine (non due, non
quattro…), dà origine a un nuovo individuo (“nascita” di una nuova cellula,
Fig 1)
4. Una cellula vivente (casella piena) con due o tre vicini, è in buona compagnia
(sufficiente, e non eccessiva) e continua a vivere (“sopravvivenza”, Fig 2)
5. Una cellula vivente circondata da meno di due vicini (nessuno o uno solo) o
da più di tre vicini (da quattro a otto) muore, rispettivamente per “isolamento”
o per “sovraffollamento” (Fig 3).
Figura 1. Due casi di "nascita" di una cellula.
10
Figura 2. Tre casi di sopravvivenza di una cellula: le cellule segnate da un punto colorato sopravvivono perché accompagnate da due o tre vicini.
Figura 3. Morte di cellule, per sovraffollamento (secondo diagramma da sinistra) e per isolamento (gli altri diagrammi, in cui tutte le cellule presenti muoiono).
Il gioco progredisce a step temporali: ogni iterazione applica le regole e dà un output
grafico con il quale lo “spettatore” assiste all’evoluzione della colonia di cellule. Il gioco
finisce quando subentra una situazione di equilibrio (o “stallo”), ossia se tutte le cellule sono
morte, oppure se si è stabilita una condizione di oscillazione tra diversi schemi di
disposizione delle cellule sopravvissute.
Nota importante: a ogni ciclo del gioco, il numero di vicini da considerare
nell’applicazione delle regole è sempre basato sulle cellule presenti prima dell’applicazione
delle regole stesse. In altre parole, l’aggiornamento della scacchiera avviene solo alla fine
dell’applicazione delle regole.
Le configurazioni che le cellule possono via via assumere sono spesso interessanti e
graficamente gradevoli. Esse assumono spesso dei nomi caratteristici, e sono costituite da
gruppi di cellule che oscillano tra configurazioni, oppure gruppi di cellule che si muovono
insieme, e così via. Alcuni esempi sono:
Figura 4. Alcune configurazioni tipiche (da https://it.wikipedia.org/wiki/Gioco_della_vita).
Da un punto di vista informatico, il gioco comporta:
11
1. una matrice di caselle che possono essere occupate da una cellula oppure
vuote (quindi, una matrice sostanzialmente booleana, che costituisce il
“mondo” in cui vivono le cellule)
2. una distribuzione spaziale iniziale delle cellule, decisa a caso oppure per
intervento manuale del “giocatore”, da inserire nel “mondo”
3. una funzione che calcoli il numero di vicini di ciascuna cella, considerando la
scacchiera infinita, oppure limitandosi a trascurare il bordo della scacchiera
stessa (in cui non si porranno cellule)
4. una funzione che applichi le regole a ciascuna casella della matrice “mondo”
e decida se una cellula vive, muore, o “nasce”
5. una seconda matrice di caselle, identica al “mondo”, che contenga le
variazioni via via apportate alla configurazione di cellule in base alle regole, e
che alla fine di ciascun ciclo sia copiata sulla matrice “mondo” visibile da
L1 = zeros(size(L)); % buffer per i calcoli, inizialm. caselle vuote (metto fuori?) for x = 2 : sx - 1 for y = 2 : sy - 1 n = L(x-1,y-1)+L(x,y-1)+L(x+1,y-1)+L(x-1,y)+... L(x+1,y)+L(x-1,y+1)+L(x,y+1)+L(x+1,y+1); if L(x,y) == 0 && n == 3 L1(x,y) = 1; elseif L(x,y) == 1 && (n == 2 || n == 3) L1(x,y) = 1; % sopravvivenza else % L1(x,y) = 0; % morte per solitudine o sovrappopolazione end end % for y end % for x L = L1; % copia il buffer sullo "schermo" da mostrare (il mondo)% L(:,:) = 0; % In questo caso, l’istruzione L1 = zeros(size… va messa fuori!
% salva immagine %fname = ['life_', num2str(time,'%05d')];%fid = fopen(fname, 'wb');%fwrite(fid, L*255, 'int8');%fclose(fid); end % for time
Notare che, avendo deciso di utilizzare un mondo booleano che contenga solo i
valori 0 e 1, è possibile capire quanti primi vicini viventi abbia una cellula semplicemente
sommando il contenuto delle caselle della matrice. Inoltre, nel caso di morte per solitudine o
sovrappopolazione, è superfluo scrivere 0 in L1, in quanto L1 nasce completamente
azzerata (l’istruzione L1(x,y) = 0 è stata inserita comunque, per chiarezza, ma è
commentata perché inutile).
Per riempire inizialmente il “mondo” è possibile impiegare la funzione ginput.
Quest’istruzione, se usata nella sintassi [u, v] = ginput(m), permette di cliccare m
volte sull’immagine corrente (quella visualizzata per ultima) restituendo le coordinate degli m
punti. Se, anziché cliccare, si preme il tasto <invio>, la funzione torna prematuramente, e sia
u che v sono matrici vuote. Notare che il significato di u e v è invertito rispetto alle righe e
alle colonne delle matrici: in questo contesto, u è riferito all’asse delle ascisse (quindi le
colonne) mentre v è riferito alle ordinate (quindi le righe). Occorre quindi poi invertire u con v
prima di usarle per indicizzare la matrice L.
Dopo:
L = zeros(sx, sy);
13
Inserire:
while(1) spy(L) [u, v] = ginput(1); % acquisisco un solo click if isempty(u) || u < 1 || u > sy || v < 1 || v > sx break end u = round(u); v = round(v); L(v, u) = 1 - L(v, u); % “toggle” della cellaend
in cui si è anche considerate l’eventualità che si clicchi al di fuori della matrice delle caselle
(vedere la condizione dell’if) e si è provveduto ad arrotondare a numeri interi i valori delle
coordinate, che l’istruzione ginput restituisce come numeri con virgola, non necessariamente
interi.
Risultato finale.
sr = 100; sc = 100;L = zeros(sr, sc);%L(1,:) = -1;%L(sc,:) = -1;%L(:,1) = -1;%L(:,sr) = -1; L(80,80) = 1;L(81,80) = 1;L(80,81) = 1;L(81,82) = 1;L(80,83) = 1;L(80,83) = 1;L(81,83) = 1;L(82,83) = 1;L(83,80) = 1;L(83,80) = 1;L(83,81) = 1;L(84,82) = 1;L(85,83) = 1;L(84,83) = 1;L(83,83) = 1;L(86,83) = 1; L(74,83) = 1;L(73,87) = 1;L(76,83) = 1; while(1) spy(L) [u, v] = ginput(1); % acquisisco un solo click if isempty(u) || u < 1 || u > sc || v < 1 || v > sr break
14
end u = round(u); v = round(v); L(v, u) = 1 - L(v, u); % toggle della cellaend for time = 1:1000 pause(0.1) % imshow(L, []) spy(L), drawnow L1 = zeros(size(L)); % buffer per i calcoli for r = 2 : sr - 1 for c = 2 : sc - 1 n = L(r-1,c-1)+L(r,c-1)+L(r+1,c-1)+L(r-1,c)+L(r+1,c)+L(r-1,c+1)+L(r,c+1)+L(r+1,c+1); if L(r,c) == 0 && n == 3 L1(r,c) = 1; elseif L(r,c) == 1 && (n == 2 || n == 3) L1(r,c) = 1; % sopravvivenza else % L1(r,c) = 0; % altrimenti morte per solitudine o sovrappopolazione end end % for end % for L = L1; % porta il buffer sullo "schermo" da mostrare % salva immagine %fname = ['life_', num2str(time,'%05d')];%fid = fopen(fname, 'wb');%fwrite(fid, L*255, 'int8');%fclose(fid); end % for time
[gar1970] “The fantastic combinations of John Conway's new solitaire game "life" di
Martin Gardner”, …….
Assorbimento di fotoni e coefficiente di attenuazione lineare
Sia N il numero di bersagli (atomi) per unità di volume nel mezzo. Il coefficiente di
attenuazione μ rappresenta la probabilità di interazione per unità di percorso, ha come
dimensioni l’inverso di una lunghezza e si misura in cm -1. Quando un fascio di fotoni penetra
in un mezzo, a causa delle interazioni con il mezzo stesso l’intensità del fascio decresce
esponenzialmente.
15
Sia infatti NI il numero di fotoni che interagiscono nel tratto di materiale dx e che
quindi vengono sottratti al fascio originario.
dN = -N μ dx
N(x) = No e−μx
N(x) è il numero di fotoni ancora presenti alla profondità x, essendo No il numero di
fotoni iniziale.
Rappresentando N(x) in funzione di x su grafico semilogaritmico (oppure calcolando
il logaritmo di ambo i membri dell’equazione e rappresentando log (N(x) / No) in funzione di
x) si ottiene un andamento lineare:
N(x) / No = e−μx
da cui, calcolando il logaritmo di ambo i membri e applicando la definizione di logaritmo, si
ottiene:
log (N(x) / No) = – μ x
dove la pendenza della retta è –μ.
function p = assorbimento(h, w, d, rho)%h = 10; % dimensioni della matrice, altezza, ...%w = 10; % ...larghezza e...%d = 100; % spessore%rho = 0.005; % probabilita' di occupazionespazio = zeros(h,w,d);spazio2 = zeros(h,w);N = floor(rho*h*w*d);x = ceil (h * rand (N,1));y = ceil (w * rand (N,1));z = ceil (d * rand (N,1));for i = 1 : N % oppure potrei inserire in tutto il campione dei numeri casuali tra 0 e 1 e applicare una soglia che e' la densita' spazio (x(i),y(i),z(i)) = 1; spazio2 (x(i),y(i)) = 1;endspazio2;%pcolor (spazio2)nfot0 = 1000;nfot = 0;for j = 1 : nfot0 rf = ceil (h * rand); cf = ceil (w * rand); if spazio2 (rf,cf) == 0 nfot = nfot + 1; endendp = nfot/nfot0
16
assorbmain.m
h = 10; % dimensioni della matrice, altezza, ...w = 10; % ...larghezza e...rho = 0.007; % probabilita' di occupazione k=0spessori = 10:10:1000for d = spessori k = k + 1; v(k) = assorbimento(h, w, d, rho);end % Siccome devo fare poi il logaritmo, devo fermarmi a risultati di% assorbimento diversi da 0!!! Trovo il primo uguale a 0 e prendo i dati% precedenti; e’ un esercizio utile di per se’!% Alternativa, sommare eps al vettore v. In questo caso pero’ il fatto di % avere pochi fotoni porta a un salto nel grafico dei log! ind = find (v==0);ind1 = ind (1);v = v (1:ind1-1);spessori = spessori (1:ind1-1); figure('color', 'w')subplot(1,3,1)f = fit(spessori', v', 'exp1'); % fit vuole vettori colonna!plot (f, spessori, v, 'o')xlabel('d'), ylabel('N/N_o') subplot(1,3,2)semilogy (spessori, v, 'o')xlabel('d'), ylabel('N/N_o') p = polyfit (spessori,log(v),1)f = polyval(p,spessori);subplot(1,3,3)plot (spessori,log(v), 'o', spessori, f, '-')xlabel('d'), ylabel('log(N/N_o)') disp(['Il coefficiente di assorbimento e'' ' num2str(-p(1))])
SI PUO’ fare break dal loop che calcola a diversi spessori cosi’ appena si trova il
primo zero non si continua piu’ a calcolare; inoltre poi indicizzo solo la parte della matrice
utile
Relazione tra mu e rho
17
Miscele con mu differente, non si puo’ fare se non si fa dipendere mu da una sigma!
f = fit(…, exp1)
fit.a e fit.b per graficare nel semilog dove non posso inserire direttamente f
PARLARE DI WAITBAR
Ancora numeri casuali!
Scrivere un programma (in forma di script) che generi una sequenza di numeri casuali X
(compresi tra 0 e 1 e tratti da una distribuzione uniforme, istruzione rand()), di cui a priori
non si conosca la lunghezza, e individui:
1. quanti numeri della sequenza occorra sommare per superare il valore 5 (il risultato
sia n1, e quindi sum(X) >= 5 per la prima volta quando length(X) sia pari a n1);
2. quanti numeri della sequenza siano estratti affinché ne venga estratto uno compreso
tra 0.80 e 0.85 limiti inclusi (il risultato sia n2, ossia il numero casuale al posto n2 è il
primo della sequenza ad essere compreso tra i limiti assegnati: 0.80 <= X(n2) <=
0.85);
3. quanti numeri della sequenza occorra estrarre prima che la media sia situata tra 0.01
e 0.50 limiti inclusi (sia n3, ovvero 0.01 <= mean(X) <= 0.50 con length(X) = n3).
Si noti che il programma deve segnalare solo la prima volta che tali condizioni si verifichino
(per esempio, dato n1, è chiaro che anche per n1+1 la prima condizione sarà soddisfatta,
ma ciò non dev’essere segnalato!).
Essendo la sequenza a priori di lunghezza non nota, conviene generare i numeri uno alla
volta e accodarli al vettore che contiene la sequenza, ossia X. Ad ogni generazione di
numero casuale, si testerà ciascuna condizione, segnalandone l’effettiva soddisfazione, e –
per evitare che la medesima condizione sia segnalata anche in seguito – si attiverà un flag
18
opportuno (una variabile booleana, che da falsa diventerà vera) che indicherà l’effettivo
raggiungimento di un goal del programma, e sarà a sua volta testata per evitare che tale
goal sia segnalato più volte. Quando tutte e tre le “bandierine” saranno alzate, il programma
avrà finito il proprio compito e potrà terminare.
Conviene far girare il programma più volte per vedere come n1, n2 e n3 varino. E’ anche
interessante chiedersi se e quali dei risultati indicati possano essere in qualche modo
previsti, in base a considerazioni elementari di teoria della probabilità.
A chiarimento di quanto suggerito, se la sequenza di numeri casuali è:
si verifica che sum(X(1:7)) = 4.6542 mentre sum(X(1:8)) = 5.0464, quindi n1 = 8
si constata immediatamente che n2 = 3
si verifica che mean(X(1:2)) = 0.3457, quindi n3 = 2.
Naturalmente, il programma smetterà di generare numeri casuali dopo averne estratti 8,
perché tutte le condizioni saranno state soddisfatte.
Conversione di scale di temperatura
Print a table that converts °C (from 0°C to 100°C with intervals of 10°C) to °F. Hint: c
= 5* (f − 32) / 9;
Radice quadrata: metodo di Newton
Il metodo di Newton per il calcolo della radice quadrata di un numero è un approccio
iterativo, ad approssimazioni successive. Dato un numero positivo A, la prima
approssimazione per la radice quadrata di A è xo = 1, e le iterazioni successive sono pari a:
xn+1=xn2
+ A2 xn
L’iterazione termina quando il valore xn elevato al quadrato differisce da A meno di
una quantità definita a priori (errore). La differenza massima accettabile può essere imposta
come valore assoluto o come valore relativo (o percentuale), ovvero:
19
|(x¿¿n2−A)|<∆¿
oppure:
|( xn2−A )|A <ε
Scrivere una funzione, chiamata mysqrt, che abbia due parametri, il valore A di cui
calcolare la radice quadrata, e l’errore desiderato. La funzione restituisca la radice quadrata
di A. Inserire anche l’help, in modo che la funzione risponda correttamente alla richiesta
help mysqrt.
function x=mysqrt(A) % My square root function. % % x = mysqrt(A) % % x is the square root of A. x=1; %First guess err=1; %Set error to something to get started while(err>0.0001) x = myfunction(A,x); % call to local function below end err = abs(A -x.^2); % calculate the errorend
function y = myfunction(A,x) % Local function to calculate the % Newton Raphson Iteration equation y = (x.^2+A)/(2*x);end
Sinusoidi
20
Tracciare il grafico della funzione seguente, con t compreso tra 0 e 10, e passo 0.1.
(s2 indica secondi al quadrato)
Si tratta di un’onda sinusoidale con frequenza che aumenta linearmente (in
particolare da 0 Hz a 5 Hz, tra 0s e 10 s). [Matlab-answers.pdf]
Trovare i punti nei quali la funzione attraversa lo 0 (zero crossing). Purtroppo un
semplice confronto dei valori con lo 0 non è sempre soddisfacente, perché la funzione è
campionata a intervalli regolari che non necessariamente includono i punti in cui essa passa
“esattamente” per lo zero. Questo è un problema generale: per una variabile che assume
valori reali (nel senso di non interi) è rischioso effettuare confronti con quantità precise (cioè
21
x == 0): è sempre meglio individuare metodi basati su una soglia di tolleranza, quali abs(x) <
delta, con delta opportunamente scelto in base al problema.
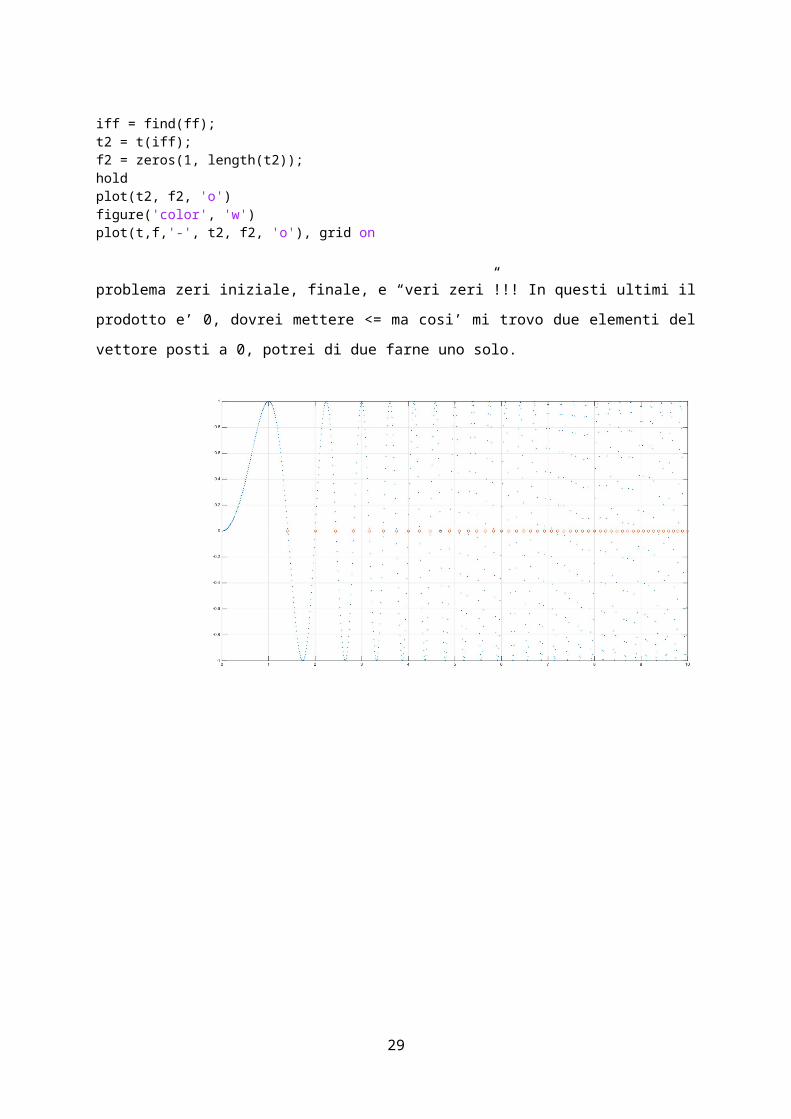
clcclose allcleart = 0:0.01:10;f = sin(pi*t.^2/2);figure('color', 'w')plot(t,f,'.'), grid on z = t == 0; % non va benez = abs(f) < 0.05 % non va bene fA = f(2:end);fB = f(1:end-1);ff = fA.*fB;ff = ff < 0; iff = find(ff);t2 = t(iff);f2 = zeros(1, length(t2));holdplot(t2, f2, 'o')figure('color', 'w')plot(t,f,'-', t2, f2, 'o'), grid on
problema zeri iniziale, finale, e “veri zeri”!!! In questi ultimi il prodotto e’ 0, dovrei mettere <=
ma cosi’ mi trovo due elementi del vettore posti a 0, potrei di due farne uno solo.
22
t = 0:0.01:10;f = sin(pi*t.^2/2); plot(t,f)
Il calcolo di
Il valore di può essere calcolato a partire da serie numeriche come le seguenti:
23
π 2−816
=∑n=1
∞ 1(4 n2−1 )2
oppure tramite metodi iterativi come il seguente:
Algoritmo di Gauss-Legendre o di Brent-Salamin
1. Valori iniziali; a = 1; b = 1 / sqrt(2); t = ¼; x = 1
2. Repeat the following statements until the difference of a and b is within the desired accuracy; y = a a = (a+b) / 2 b = sqrt(b*y) t = t − x * (y−a)² x = 2 * x
Ripetere le seguenti istruzioni finché la differenza fra e è della precisione voluta:
3. Il valore di p è approssimato dalla formula:
π = ((a+b)²) / (4*t)
Le prime tre iterazioni danno:
How many terms are needed to obtain an accuracy of 1e-12? How accurate is the sum of 100 terms of this series?
How many repeats are needed to estimate pi to an accuracy of 1e-8? 1e-12?
24
Compare the performance of this algorithm to the result from Exercise 1, above.
INVECE DI USARE (A+B)/2, vedere che un pigreco disti dal precedente meno di una
9. Compute and plot the path(s) of a set of random walkers which are confined by a pair of barriers at +B units and -B units from the origin (where the walkers all start from). A random walk is computed by repeatedly performing the calculation xj+1 = xj + s where s is a number drawn from the standard normal distribution (randn in MATLAB). For example, a walk of N steps would be handled by the code fragment x(1) = 0; for j = 1:N x(j+1) = x(j) + randn(1,1); end There are three possible ways that the walls can "act": a. Reflecting - In this case, when the new position is outside the walls, the walker is "bounced" back by the amount that it exceeded the barrier. That is, when xj+1 > B, xj+1 = B - |B - xj+1|
If you plot the paths, you should not see any positions that are beyond |B| units from the origin. b. Absorbing - In this case, if a walker hits or exceeds the wall positions, it "dies" or is absorbed and the walk ends. For this case, it is of interest to determine the mean lifetime of a walker (i.e., the mean and distribution of the number of steps the "average" walker will take before being absorbed). c. Partially absorbing - This case is a combination of the previous two cases. When a walker encounters a wall, "a coin is flipped" to see if the walker relfects or is absorbed. Assuming a probability p (0 < p < 1) for reflection, the pseudo-code fragment that follows uses the MATLAB uniform random-number generator to make the reflect/absorb decision: if rand < p reflect else absorb end
What do you do with all the walks that you generate? Compute statistics, of course. Answering questions like What is the average position of the walkers as a function of time? What is the standard deviation of the position of the walkers as a function of time? Does the absorbing or reflecting character influence these summaries? For the absorbing/partial-reflection case, a plot of the number of surviving walkers as a function of step numbers is a very interesting thing. is useful, informative and interesting, particularly if graphically displayed.
[I, map] = imread('blobs.gif');figure, imshow(I, [])I = ind2gray(I,map);figure, imshow(I, []) IM = I < 130;figure, imshow(IM, []) IM = imclearborder(IM); I2 = I .* uint8(IM);figure, imshow(I2, []) L = bwlabel(IM);figure, imshow(L, []) % impixelinfo s = regionprops(L, 'basic'); % area, centroid, bboxlength(s) s(4).Areaareas = [s.Area]; figure, hist(areas, 20) %idx = find(areas > 800);idx = find(areas > 500);L1 = L == idx(1);figure, imshow(L1, []) % conserva l'oggetto "grosso"; potrei cercare l'oggetto di area massima e visualizzarlo figure, imshow(I, [])hold onfor j = 1 : length(idx) c = s(idx(j)).Centroid plot(c(1), c(2), '+g')endhold off% falsi positivi e falsi negativi % dall'help:%centroids = cat(1, s.Centroid);%imshow(BW)%hold on%plot(centroids(:,1), centroids(:,2), 'b*')%hold off cs = [s.Centroid];x = cs(1:2:end);y = cs(2:2:end);holdplot(x, y, 'sg')hold %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
27
s = regionprops(L, 'Area', 'Centroid', 'Eccentricity', 'Perimeter'); % area, centroid, etc% notare: non posso accoppiare basic con altre opzioni!! % CIRCULARITY (shape factor) https://en.wikipedia.org/wiki/Shape_factor_(image_analysis_and_microscopy)% circ = 4*pi*A/p^2 areas = [s.Area];perimeters = [s.Perimeter];circularities = 4*pi*areas./perimeters.^2;eccentricities = [s.Eccentricity]; figure, hist(circularities, 50), title('circularities')figure, hist(eccentricities, 20), title('eccentricities') % quali sono gli oggetti con circolarita' > 1.5 idx = find(circularities > 1.5);figure, imshow(I, [])hold onfor j = 1 : length(idx) c = s(idx(j)).Centroid plot(c(1), c(2), '+g')endhold off % quali sono gli oggetti con circolarita' > 0.9 ma < 1.5 idx = find(circularities > 0.9 & circularities < 1.5);figure, imshow(I, [])hold onfor j = 1 : length(idx) c = s(idx(j)).Centroid plot(c(1), c(2), '+g')endhold off % che area hanno gli oggetti che stiamo conservando areaOggettiBuoni = areas(idx);figure, hist(areaOggettiBuoni, 10)
Esercizio xx: “Media”
SCRIVERE UN PROGRAMMA CHE:
28
1) Sia composto da due function, di cui una svolga il ruolo di main program e l’altra di
function esecutrice
2) Il main chiede all’utente su quanti numeri deve lavorare (valore intero N), e i due
estremi di un intervallo (A e B)
3) Il main chiama poi la function passandole N, A, B
4) La function crea un vettore di N numeri casuali compresi tra A e B…
5) …ne calcola la media e la restituisce al programma principale
6) Il programma principale stampa il vettore e la media, chiedendo all’utente di inserire
un numero. In base al numero inserito scrive se il numero è maggiore o minore della
media trovata prima
ANALISI D’IMMAGINE
Esercizio 1: “Diatomee”
SCRIVERE UN PROGRAMMA CHE:
1) carichi l'immagine Diatoms.jpg; il path dell'immagine è passato come parametro; si
noti dal workspace che l'oggetto caricato è una matrice 3D (colori RGB, anche se
l’immagine appare a vista monocromatica) per cui è necessario trasformarla in
immagine a toni di grigio
2) la visualizzi (figura 1)
3) crei una maschera che comprenda tutti gli oggetti, e sia bianca dove vi sono pixel
appartenenti alle diverse diatomee. Per farlo, occorre
a. applicare all’immagine una soglia ad hoc che sfrutti il bordo nero (figura 2)
b. adoperare l’operazione di closing morfologico per riempire i piccoli gap nel
bordo (figura 3)
c. riempire i buchi (imfill(..., 'holes'))(figura 4)
4) visualizzi la nuova immagine
29
5) escluda le diatomee a contatto con il bordo, in quanto visualizzate solo in parte
(imclearborder) (figura 5)
6) etichetti (bwlabel) gli oggetti e poi ne cerchi le statistiche (regionprops) (figura 6)
7) individui la diatomea di lunghezza massima, scrivendone il valore a video e
segnando il centroide dell’oggetto con una crocetta (figura 7)
8) individui la diatomea di area massima, scrivendone il valore a video e segnando il
centroide dell’oggetto con una crocetta.
1) 2)
3) 4)
30
5) 6) 7)
(Immagine tratta da http://bioweb.uwlax.edu/bio203/2010/ramsby_jord/classification.htm)
Esercizio 2: “Pseudo OCR”
31
SCRIVERE UN PROGRAMMA CHE:
1) carichi un'immagine che mostra alcune lettere dell'alfabeto (optik.jpg); il path
dell'immagine è passato come parametro; si noti dal workspace che l'oggetto
caricato è una matrice 3D, cioè a colori RGB (righe x colonne x 3)
2) la visualizzi (figura 1);
3) conservi dell'immagine solo i pixel grigi molto scuri, cioè quelli che hanno tutte le
componenti RGB minori di (per esempio) 50
4) visualizzi la nuova immagine (figura 2);
5) Ingrandendo l'immagine, se si nota che le lettere hanno dei difetti al loro interno
(buchi), li si eliminino con un'operazione di closing morfologico con un piccolo
elemento strutturante (un disco di raggio 1). Si verifichi che così non vi sono buchi
nelle lettere (figura 3);
6) si etichettino (bwlabel) gli oggetti e poi si cerchino le statistiche (regionprops).
Vogliamo individuare la lettera D, l'unica provvista di un buco. Statistica consigliata:
EulerNumber; il numero di eulero è dato dal numero di oggetti in ciascuna regione (in
questo caso sempre 1) meno il numero di buchi (1 per la D, 2 per la B, 0 per la A,
etc)
7) si individui la lettera D cercando, ad esempio con un ciclo for, l'oggetto che ha
numero di eulero opportuno, e si crei una figura in cui essa sola risulta visibile (una
volta conosciuto l'indice dell'oggetto, nell'immagine di etichette bisogna accendere
solo i pixel che hanno quel valore); (figura 4);
32
1) 2)
3) 4)
(Immagine tratta con modifiche da http://www.ocr-systeme.de/images/optik.jpg)
Esercizio 3: “Linea mediana”
33
Individuare la linea mediana di un’immagine CT cerebrale
Scopo….. Immagine: CT-head.jpg (tratta dal software ImageJ (https://imagej.net/).
1) posso partire dalla maschera del cervello (quindi non dall'immagine originale)
2) il cervello occupa una parte dell'immagine: trovo due valori di riga, minima e
massima, entro i quali sicuramente il cervello c'e' tutto; Individuo riga massima e riga
minima manualmente (eg tra 210 e 440) ma provo anche a individuare
automaticamente, ossia calcolando un profilo integrato dell'immagine (proietto,
sommando, sull'asse verticale, e studio l'istogramma; banalmente, prendo i valori
estremi non nulli)
3) faccio un loop sulla riga, per ogni riga row tra 210 e 440 prendo il profilo: p =
improfile(I, [1 512], [row row])
4) faccio la "derivata", o meglio il rapporto incrementale, del profilo dp = diff(p)
5) trovo i punti in cui dp e' diverso da 0: ci sono due punti, uno di gradiente positivo e
uno negativo, che corrispondono al fronte di salita e al fronte di discesa del profilo (i
punti in cui si entra e poi si esce dalla maschera). I punti potrebbero essere piu' di
due solo verso i bordi dell'immagine: se succede magari si butta via il profilo, per
evitare problemi (dopo aver visto che succede).
6) si fa la media delle x (le colonne) dei due fronti di ingresso nel tessuto cerebrale
(discesa e salita rispettivamente): questo da' la posizione, su quella particolare riga,
della linea mediana, m(row)
7) invece di plottare (row, m(row)) per tutte le row tra 210 e 440, si fa un fit lineare, per
trovare la riga che meglio approssima quei punti (che non saranno realmente
allineati): pol = polyfit(X,Y,N) dove le X sono le colonne trovate, le Y sono le
righe (210:440), N = 1. Poi si disegna sull'immagine con Y2 = polyval(pol,X); e poi il
plot (X,Y2).
34
Esercizio 4: “Monete”
Sul bancone di un negozio, lasciamo alcune monete come pagamento di un
acquisto. Il negoziante, molto pigro, vuole un programma che riconosca le monete (dandone
il valore in euro), e ne calcoli automaticamente il totale.
Il programma che scriveremo, sfrutterà il fatto che le diverse monete hanno tutte diametro diverso tra loro, secondo la tabella riportata nel seguito (tratta da
http://euro.raddos.de/italiano/monete.php).
35
Un programma versatile, dovrebbe far fronte a qualunque combinazione di monete,
anche tra loro in contatto o parzialmente sovrapposte, e probabilmente sfrutterebbe anche il
colore, per distinguere i diversi pezzi.
Per semplificare, noi assumeremo (in maniera molto arbitraria!!!) che:
a) tutti i pezzi possano essere presenti, ma vi sia necessariamente la moneta da 1
cent (la più piccola!)
b) le monete siano ben separate tra loro.
SCRIVERE UN PROGRAMMA CHE:
1) abbia forma di function, supponiamo sia la funzione “main”
2) carichi l'immagine eire-euros.jpg (tratta da http://www.katsandogz.com/ireland/)
il nome dell'immagine sia passato come parametro alla funzione “main”
3) la visualizzi (figura 1)
4) si noti dal workspace che l'oggetto caricato è una matrice 3D (colori RGB) per cui
(volendo usare il diametro come feature discriminante, e non i colori) il programma
trasformi l’immagine in toni di grigio (rgb2gray), e la visualizzi (figura 2)
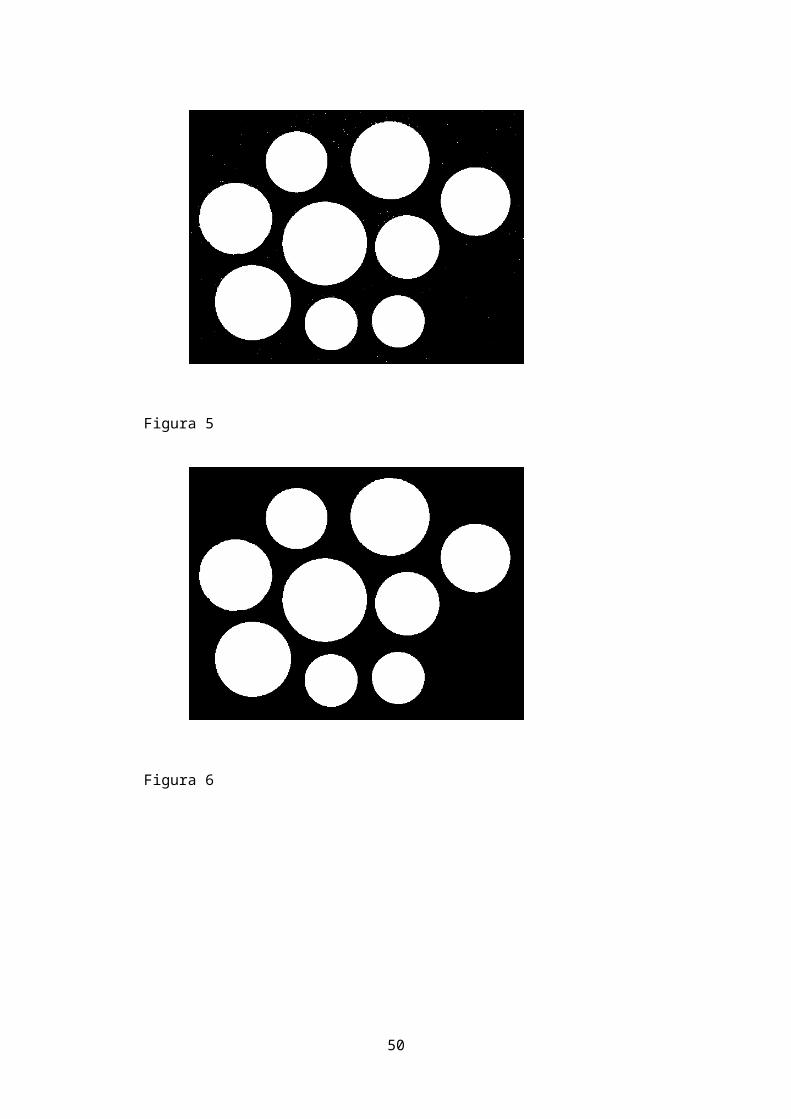
5) visualizzi l’istogramma, allo scopo di trovare una soglia opportuna per la
segmentazione delle monete rispetto allo sfondo (figura 3); si usi anche
eventualmente impixelinfo per il medesimo scopo (e si commenti nel programma il
valore trovato)
6) crei una maschera che comprenda tutti gli oggetti, e sia bianca dove vi sono pixel
appartenenti alle diverse monete. Per farlo, occorre
i. applicare all’immagine la soglia ad hoc in precedenza definita (figura 4)
ii. riempire i buchi nelle maschere delle monete (figura 5)
iii. eliminare il rumore tipo “sale” con operazioni morfologiche (che non
modifichino le dimensioni degli oggetti) (figura 6)
7) etichetti (bwlabel) gli oggetti e poi ne cerchi le proprietà (regionprops), in
particolare il diametro e la posizione dei centroidi
8) ora, la parte di elaborazione d’immagine è terminata: sapendo che nell’immagine vi è
certamente la moneta più piccola (1 cent), come scritto nella prima delle assunzioni
36
alla base del programma, si calcoli il rapporto tra le dimensioni in pixel dell’oggetto
più piccolo, e il diametro in mm di tale moneta (sia per esempio la variabile “ratio”, le
cui unità di misura sono pixel/mm). Questo rapporto di scala permetterà di calcolare
le dimensioni in mm di tutti gli oggetti presenti nell’immagine, allo scopo di
confrontare queste dimensioni con quelle conosciute delle monete;
9) per effettuare il confronto, conviene mettere in un vettore i valori delle monete (in
euro: euro = [0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1, 2]); in un altro vettore i rispettivi
diametri in mm (diametri = [16.25, 18.75, 21.25 etc]). In questo modo si potrà cercare
nel secondo vettore la dimensione di una moneta individuata, e poi dedurre (dalla
medesima posizione nel primo vettore) di che moneta si tratti.
10) Siccome c’è sempre un certo errore nel calcolo delle dimensioni di una moneta
dall’immagine, per cercare un particolare valore di diametro (“valore_cercato”)
ottenuto dal diametro in pixel e dalla variabile “ratio”, conviene non usare l’operatore
==, ma scrivere una funzione che trovi nel vettore “diametri” il valore più vicino a
Con un po’ di fantasia, l’immagine potrebbe rappresentare un insieme di cellule
(bianche) viste al microscopio, così vicine tra loro da toccarsi, alcune delle quali
internamente corredate di due corpuscoli (“nuclei”, rappresentati dalle macchiette ellittiche
grigie), altre da uno solo.
Si richiede di:
a) trovare il raggio (in pixel) delle “cellule”, supposte circolari e tutte uguali
b) individuare e segnalare (tramite una crocetta nel rispettivo centroide) le cellule che
hanno al loro interno due nuclei anziché uno.
Se le cellule non fossero a contatto, il compito sarebbe semplice: consisterebbe in:
applicare una soglia opportuna per binarizzare l’immagine, in modo che
nell’immagine bianco/nero risultassero visibili le maschere delle varie “cellule” come
cerchi bianchi su sfondo nero (senza differenziazione dei nuclei);
trovare in essa gli oggetti connessi (i cerchi) chiedendone la misura del raggio e la
posizione dei centroidi;
per ciascun oggetto dell’immagine binaria, isolare dall’immagine originale la cellula
corrispondente (tramite prodotto per la singola maschera), applicare una soglia per
evidenziare solo i nuclei, e trovare gli oggetti connessi individuati da ciascuna
maschera.
43
Invece, essendo le cellule a contatto, il lavoro da fare è maggiore!
Suggerimenti:
Per separare le cellule, si può ricorrere ad operazioni di morfologia matematica (dopo
aver trasformato l’immagine in bianco/nero). In seguito, si potrà individuare il
centroide di ciascuna cellula. Le operazioni morfologiche per il distacco, però,
ridurranno la dimensione delle cellule, per cui la misura del raggio sarà alterata.
Per trovare il raggio effettivo (originale) delle cellule, si suggerisce di ricostruire, a
partire dal centroide, una delle cellule tramite (ad esempio) una function di disegno di
cerchi (già vista in altri esercizi fatti durante il Corso). Si farà variare il raggio della
cellula ricostruita iterativamente, da un valore minimo ad uno massimo, confrontando
– ad ogni ricostruzione – l’immagine ottenuta con quella originale (trasformata in
bianco/nero). Il confronto potrà essere ottenuto con l’AND tra l’immagine ricostruita e
l’originale binarizzata: tale AND sarà identico all’immagine ricostruita, fintantoché il
raggio usato per la ricostruzione sarà più piccolo o uguale a quello reale (i cerchi
disegnati cadono dentro quelli originali); appena il raggio supererà quello effettivo, i
cerchi ricostruiti conterranno anche alcune parti che nell’immagine iniziale binarizzata
sono neri, e quindi l’AND tra le due immagini sarà più piccolo dell’immagine
ricostruita. Calcolando il rapporto tra la aree accese nelle due immagini, questo sarà
dunque pari all’unità all’inizio, per poi decrescere quando il raggio usato per la
ricostruzione supererà quello effettivo dei cerchi.
Trovato R, occorrerà usare i centroidi delle singole cellule, e il raggio R, per
ricostruire le maschere delle singole cellule; con queste maschere si isoleranno
nell’immagine iniziale (opportunamente binarizzata) i nuclei che ad esse competono
(oggetti connessi), che saranno contati per decidere se sono uno o due. Si
metteranno infine le crocette in base a quest’ultima misura.
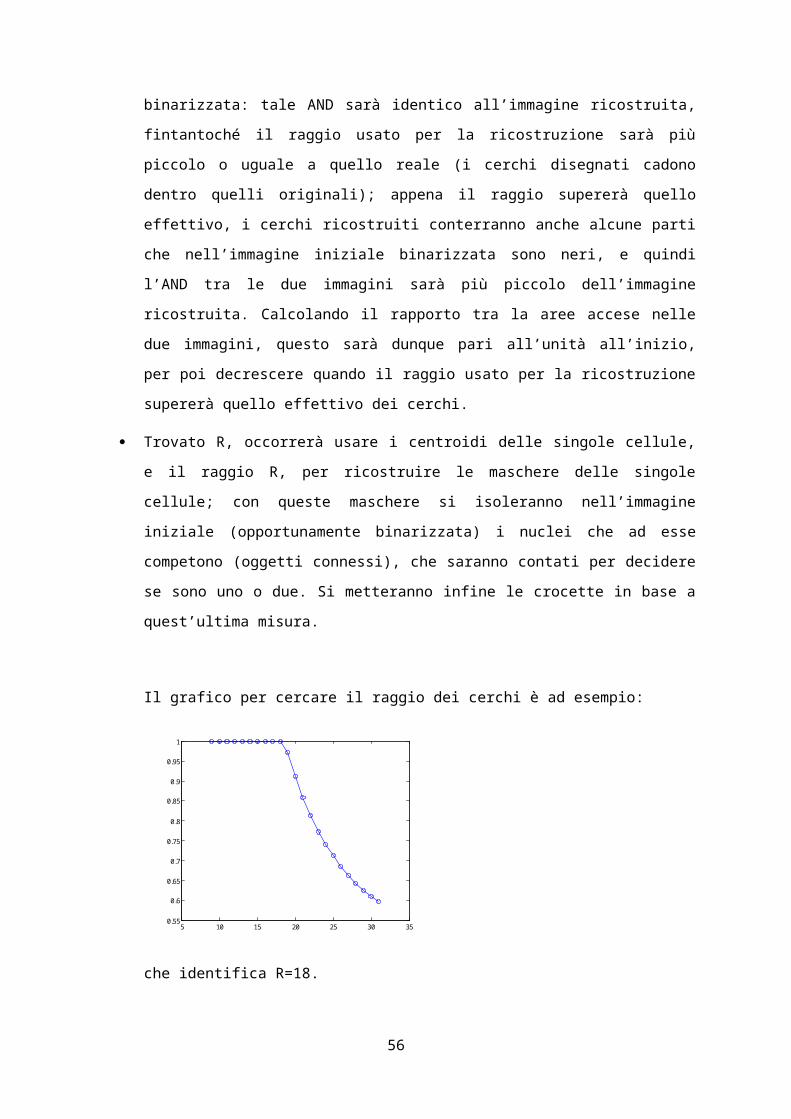
Il grafico per cercare il raggio dei cerchi è ad esempio:
44
5 10 15 20 25 30 350.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
che identifica R=18.
Il risultato dell’esecuzione del programma dev’essere:
Esercizio 6: “Pentagoni e triangoli: distinguere figure geometriche”
45
Preliminarmente, consideriamo l'immagine pentagoni_e_triangoli.ppm; essa raffigura
i contorni di due figure geometriche diverse (pentagoni e triangoli, appunto), e di varie
dimensioni.
Effettuiamo dapprima le operazioni necessarie per preparare l'immagine ad essere
trattata con bwlabel: ossia trasformiamo la figura data in un'immagine in bianco e nero in
cui in bianco vi sono gli oggetti, e poi riempiamo l'interno degli oggetti. Ci accorgiamo che,
per fare ciò, la soglia usata nell'istruzione im2bw è critica, in quanto c'è il rischio che i lati
degli oggetti risultino spezzati e quindi le operazioni di riempimento non vadano a buon fine.
Con un'opportuna scelta del livello di soglia, il problema si risolve e l'immagine finale
presenta le figure piene, in bianco su sfondo nero.
Ora passiamo all'immagine effettivamente da trattare per risolvere il problema.
Ripetendo le operazioni già effettuate, ci accorgiamo che le cose non funzionano
correttamente sulla pentagoni_e_triangoli_difettosi.ppm! La ragione è che i bordi di molte
figure geometriche, in questa seconda immagine, sono frammentati in uno o più punti:
caricare l'immagine e verificare che, ad esempio, il primo pentagono in alto a sinistra ha il
bordo difettoso.
Inseriamo nello script un'istruzione che permetta di ricostruire i bordi rovinati. Si tratta
di un'operazione morfologica che ricongiunge i bordi con un elemento strutturante e, così,
chiude le figure.
A questo punto l'output sarà ciò di cui abbiamo bisogno: oggetti bianchi chiusi, su
sfondo nero.
Vogliamo ora distinguere i pentagoni dai triangoli (si tratta di figure regolari).
Suggerimento: i pentagoni appaiono molto più "compatti", ossia simili ad un cerchio,
dei triangoli. Una diffusa misura di compattezza di una figura geometrica è il rapporto tra
l'area della figura, e l'area di un cerchio di uguale perimetro (circularity ratio):
R=4 πAp2
Usare il rapporto di circolarità per distinguere le figure: disegnare un istogramma di
R, verificare se nell'istogramma compare una soglia naturale, usarla per distinguere triangoli
46
da pentagoni, porre una crocetta al centro dei triangoli, e nulla, o un altro simbolo, al centro
dei pentagoni (nella figura originale).
Esercizio 7: “Segmentazione di una slice CT polmonare, e individuazione di un
nodulo subpleurico”
E’ data una slice di CT polmonare (lungs.png), appartenente a un paziente con
manifestazioni neoplastiche di natura nodulare. In particolare, si osserva un nodulo
subpleurico nel polmone destro (convenzione radiologica), in alto (Fig. 1):
Figura 1
Vogliamo scrivere un programma Matlab che produca due risultati:
a. segmentare il tessuto polmonare, in modo da eliminare tutte le strutture esterne al
parenchima visualizzando solo quest’ultimo
47
b. evidenziare (eventualmente con la presenza di falsi positivi) il nodulo pleurico,
dandone posizione e dimensioni approssimative in mm, considerando che le
dimensioni del pixel dell’immagine sono 0.8 mm x 0.8 mm.
Allo scopo, ecco la sequenza di operazioni consigliata, da eseguire da programma:
1) Caricare e visualizzare l’immagine (file cdPi110-sl249.png).
2) Calcolare e visualizzare l’istogramma dei grigi (scegliendo un numero di bin
opportuno, e facendo attenzione al fatto che l’immagine è formalmente a colori,
quindi va convertita), Fig. 2. L’istogramma è manifestamente bimodale; il picco di
bassa intensità di grigi rappresenta tutte le regioni scure, compreso il parenchima
polmonare che desideriamo evidenziare, mentre il picco di intensità maggiore
comprende muscoli, vasi, osso. Dall’istogramma, si individui un valore corretto di
soglia, per la separazione tra parenchima polmonare e le strutture dense di contorno
(ma anche in esso contenute, come i vasi!). La soglia sarà circa a metà tra le due
regioni modali;
-50 0 50 100 150 200 250 3000
1
2
3
4
5
6x 10
4
Figura 2
3) Applicare la soglia; dopo la segmentazione, il tessuto polmonare dovrà essere
bianco (“oggetto”), mentre i tessuti densi dovranno essere posti a 0 (Fig. 3). Notiamo
però la presenza di “oggetti” spuri, dovuti allo sfondo dell’immagine originale,
ovviamente sotto soglia. Occorrerà quindi eliminare opportunamente gli “oggetti” a
contatto con i bordi dell’immagine. Essendo poi il parenchima attraversato dai vasi,
avremo piccole zone vuote nei polmoni, anch’esse da riempire opportunamente.
Eventualmente si potrà eliminare rumore di tipo “sale” (che comunque andrà via nelle
operazioni seguenti).
48
Figura 3
4) Individuare gli oggetti rimasti nella maschera (bwlabel etc): saranno i polmoni, ma
non solo (è presente la trachea); con una soglia sull’area, si conserverà solo la
maschera dei polmoni, da visualizzare.
Figura 4
5) Ottenere quindi il risultato (a), adoperando l’immagine prodotta come maschera su
quella originale (si può usare l’istruzione roifilt2, oppure altro metodo di
filtraggio). Si conservi e visualizzi dunque solo il parenchima polmonare (Fig. 5).
49
Figura 5
6) Ci si occupi ora del nodulo polmonare subpleurico: si effettui un’opportuna
operazione morfologica per lo smussamento del bordo della maschera, che diverrà
più dolce contenendo ora all’interno della maschera anche il nodulo, e poi si
sottragga dalla maschera così ottenuta quella pre-morfologia: i noduli pleurici
eventuali risalteranno. Per l’operazione morfologica si scelga un disco di diametro
opportuno: se è troppo piccolo, la forma del nodulo così estratto non sarà aderente
alla realtà.
7) A questo punto, si verifichi che effettuare l’operazione morfologica sui due polmoni
contemporaneamente porta a problemi nella regione tra essi compresa (i polmoni
rischiano di essere collegati da un “ponte” di pixel, che poi resta nella sottrazione,
Fig.6, dando sia il nodulo effettivamente presente che una struttura spuria nella zona
centrale dell’immagine). Si organizzi quindi il programma in modo che lavori su un
polmone alla volta.
50
Figura 6
8) Si calcoli la statistica dei candidati noduli eventualmente trovati (bwlabel etc), con
le loro caratteristiche distintive (e.g. feature come area, perimetro, circolarità =
4A/p2) e si deduca una regola, se possibile, per individuare il nodulo; la dimensione
minima dei noduli identificabili è dell’ordine di qualche mm, per cui si può assumere
(dato che la dimensione di un voxel nell’immagine fornita è 0.8 mm x 0.8 mm) che
oggetti più piccoli di 3 o 4 voxel possono essere eliminati a priori. Si costruisca una
matrice di feature, in cui ogni riga compete a uno dei candidati, e le colonne sono:
etichetta (0 se non nodulo, 1 se nodulo), area, perimetro, circolarità.
9) Evidenziare il nodulo nell’immagine di figura 5, con una circonferenza che lo circondi.
Per generare una circ onferenza, si usi un metodo a piacere, come l’istruzione strel o
altro, creando due cerchi di raggio diverso e sottraendo le due immagini una
dall’altra. La corona circolare così costruita, sarà poi sovrapposta alla figura 5, dando
la figura 7. Sarà così raggiunto il risultato (b).
51
Figura 7
Note: uso di roifilt2 per l’applicazione di una maschera.
E’ possibile adoperare l’istruzione roifilt2 per applicare una maschera all’immagine. La
sintassi è:
Im = roifilt2(0, I, MASKc);
dove I è l’immagine originale, MASKc è la maschera da applicare, complementata, ossia
con pixel a 0 in corrispondenza della parte dell’immagine da conservare, e a 1 nella parte da
azzerare. Il primo parametro vale 0 e rappresenta un filtro “nullo”, che restituisce appunto il
valore 0 per tutti i pixel dell’immagine che hanno, in MASKc, valore 1. Laddove MASKc sia
0, invece, il valore restituito è quello originale, non filtrato. Il risultato è la filtratura
dell’immagine come desiderata, equivalente a I .* MASK.
Note: uso di medfilt2 per l’eliminazione di rumore di tipo “sale” (o “pepe”).
E’ possibile adoperare medfilt2 per eliminare rumore del tipo sale o pepe, ossia con netti
picchi bianchi al di sopra di uno sfondo scuro, o viceversa. La sintassi è:
BW = medfilt2(BW,[3 3])
Si applica cioè un filtro mediano che ha, come noto, la proprietà di eliminare outlier, in
questo caso costituiti dai picchi o dai pozzi netti rispetto allo sfondo mediamente uniforme.
52
Esercizio 7: “Cellule a X”
Sia data l’immagine FigP1036-DIP.tif, tratta da “Digital Image Processing” (Gonzalez, Woods, & Eddins, 3rd ed) e rappresentante delle cellule. Vogliamo evidenziare quelle a forma di X, sia nell’immagine stessa (figura 1, a sx), che nella medesima immagine ruotata di 90° (Figura 1, a dx). Gli step da realizzare sono indicati tra parentesi nel testo.
Figura 1
Dopo aver visualizzato l’immagine (step 1) innanzitutto occorre (step 2) applicare all’immagine una soglia opportuna che evidenzi le cellule rispetto allo sfondo (applicazione di una maschera, che mostri le cellule in bianco su sfondo nero), poi (step 3) si riempiano i buchi visibili in ciascuna cellula, infine (step 4) si elimini il rumore tramite un’operazione morfologica con opportuno (piccolo) elemento strutturante (figura 2, da sinistra a destra e poi dall’alto in basso, prime quattro immagini). A questo punto (step 5) si etichettino gli oggetti (bwlabel), si trasformi il risultato in immagine a colori (label2rgb), si visualizzi, e sull’immagine a colori si visualizzino nella posizione giusta anche le etichette (con l’istruzione text coadiuvata da num2str, basandosi su regionprops con attributo centroid).
1
2
3
4 5
6
7
8
9
1011
12
13
14
15
16
17
1819
20
21
22 23
2425
26
27
28
29
30
31
32
33
3435
36
3738
3940
41
42
43
44
45
46
47
48
49
50
51
0.2 0.4 0.6 0.8 1Solidity
0
10
20
30
40
50
60
Equ
ivD
iam
eter
1
2
3
4
5
6 7 8 9
1011
12
13
14
15
16
17
18
1920
2122
23
24
25
26
27
2829
30
31
32
33
3435
36
37
38
39
404142
43 4445
46
47
48
49
50
51
Figura 2
53
Sempre con regionprops, si calcolino le grandezze: Solidity, Eccentricity, EquivDiameter; si visualizzino a coppie (6) su uno scatterplot, e si decida quale coppia di queste grandezze è in grado di identificare bene e con facilità gli oggetti 1 e 30, che sono quelli di nostro interesse (ultima immagine della fig. 1, che mostra già la giusta coppia di feature, sebbene con le etichette mascherate). Si sfrutti tale conoscenza per decidere che soglie usare, e poi mettere, sull’immagine originale, un marker sulle due cellule a forma di X. A questo punto si faccia ruotare l’immagine di 90° (rot90) e si veda se le soglie sono ancora adatte alla necessità, ossia evidenzino ancora i due oggetti a X, sebbene ruotati. Per verificare completamente l’invarianza per rotazioni occorrerebbe provare ovviamente anche con angoli qualunque. Usare l’istruzione imrotate per ruotare l’immagine di un angolo arbitrario e verificare se l’intera procedura continua a funzionare (effettuare il test per qualche angolo a piacere).
Ricorsione
function f = fattorialeR(n)if n == 1 f = 1;else f = n * fattorialeR(n-1)endend
function f = fattorialeI(n)f = 1;for j = 1 : n f = f * j;endend
function n = fibonacci2(k)disp('Eccomi')if k == 1 n = 1;else if k == 2 n = 1; else n = fibonacci2(k-2) + fibonacci2(k-1); endendend
MANCA CRABS e BRATS; inserire un esempio sulla mammografia; inserire i vulcani
di venere.
54
SOLUZIONI
Riflessometro
function [z,y]=riflessi(m, t1, t2)y = zeros(m,1); % conterra' i tempi di rispostaz = rand(m,1) * (t2-t1) + t1; % tempi di ritardo
55
for i = 1 : m disp('attenzione...') fflush(stdout) % Solo in OCTAVE! https://stackoverflow.com/questions/2633019/how-can-i-flush-the-output-of-disp-in-matlab-or-octave pause(z(i)); disp('premi un tasto') tic pause y(i)=toc;enddata = [y z];save('data.txt', 'data', '-ascii')
function [z,y]=riflessi(m,t1,t2)y=zeros(1,m); % conterra' i tempi di rispostaz=zeros(1,m); % tempi di ritardofor i=1:m r=rand(1,1); t=r*(t2-t1)+t1; disp('attenzione') pause(t); disp('premi un tasto') tic pause y(i)=toc; z(i)=t;enddata = [y z];save('data.txt', 'data', '-ascii')
SEGMENTAZIONE
% NON TERMINATO: CALCOLA LA CIRCOLARITA' MA NON LA USA close allclear I1 = imread('cdPi110-sl249.png'); figure('color', 'w'), imshow(I1, []) % calculate the histogramI1 = rgb2gray(I1);[c,b] = imhist(I1,50);%figure, stem(b,c)figure('color', 'w'), bar(b,c)
56
% imhist(I1,1000); % commentare il plot, cambiare assi % individuare la soglia, a occhio!!! Il vero algoritmo la fa automaticamente th = 100; BW = I1 < th; % only consider "dark" objectsfigure('color', 'w'),imshow(BW); BW = imclearborder(BW); % drop objects in contact with the image border (they cannot be the lungs)figure('color', 'w'),imshow(BW); BW = imfill(BW, 'holes'); % imfill will eliminate background regions within the (foreground) lungsfigure('color', 'w'),imshow(BW); %BW = medfilt2(BW,[3 3]); % now we have to eliminate foreground (white) "salt" noise from the background (black), alternative? %BW = imopen(BW, strel('disk',1));%figure('color', 'w'),imshow(BW); L = bwlabel(BW, 8); % put 1, 2, .. in connected objects (8 is connectivity)figure('color', 'w'); imshow(L, []); RGB = label2rgb(L, 'jet', 'k'); % colora secondo la mappa "jet" di colorifigure('color', 'w'); imshow(RGB, []); % get statistics... stats = regionprops(L, 'Area', 'Centroid'); stats.AreaallAreas = [stats.Area]idx_area = find(allAreas > 10000)stats=stats(idx_area) MASK = ismember(L, idx_area);MASKc = imcomplement(MASK);figure('color', 'w'), imshow(MASKc,[]) I = roifilt2(0, I1, MASKc);figure('color', 'w'), imshow(I,[]) %----- figure('color', 'w'), imshow(MASK,[]) closedMASK = imclose(MASK, strel('disk', 10));figure('color', 'w'), imshow(closedMASK,[]) delta = closedMASK - MASK;