C Consiglio Nazionale delle Ricerche #tweeTag: a web‐based annotation tool for Twitter data S. Cresci, M. N. La Polla, S. Tardelli, M. Tesconi IIT TR-07/2016 Technical Report Aprile 2016 Iit Istituto di Informatica e Telematica
Transcript
C
Consiglio Nazionale delle Ricerche
#tweeTag: a web‐based annotation tool for Twitter data
S. Cresci, M. N. La Polla, S. Tardelli, M. Tesconi
IIT TR-07/2016
Technical Report
Aprile 2016
Iit
Istituto di Informatica e Telematica
#tweeTag: a web‐based annotation tool for Twitter data
Autori: Stefano Cresci, Mariantonietta Noemi La Polla, Serena Tardelli e Maurizio Tesconi
Indice Abstract Introduction #tweeTag
Global annotation Figure 1. Global annotation interface Figure 2. Users’ profile page
Global annotation functionality Results Related work Conclusions and future works References
Abstract The manual annotation of tweets is an essential task for the training of new algorithms based on those data. Unfortunately, conventional and consolidated automatic annotation systems that already exists are based and trained on documents where text is longer than 140 characters (the maximum length of a tweet) and the grammar is correct. Besides the length, tweets must be treated differently because they have peculiar characteristics, such as the presence of links, abbreviations, hashtags and mentions. To face the challenge of the linguistic annotation of tweets, we have created #tweeTag, a webtool designed for a specific approach on tweets. The tool is able to annotate tweets in three different ways: (i) global annotation to bring out macro characteristics of the tweet, given context (e.g., if it is related to a certain phenomenon, if it is positive or negative etc.); (ii) textual annotation to annotate the text of a tweet in order to identify information about the topic or content (e.g., whether describes various types of damage to property and/or people, etc); (iii) timeline annotation to evaluate the credibility of a specific user through the analysis of its timeline.
1
#tweeTag has been developed in order to make it possible to run multiple annotation campaigns with different purposes in order to meet every need. Results show a usable and effective tool, with great potential for the near future. As this is a web application, #tweeTag could also be implemented as a crowdsourcing system.
1. Introduction Every day millions of people around the world post messages via social media in order to share thoughts, ideas, strategies, resources. These technologies generate an enormous amount of data, from which we can obtain valuable information for different purposes, from the emergency management to the intelligence [13]. Our analysis focuses on Twitter, one of the main popular social media: around 500 million tweets are posted per day [Twitter, Inc Common Stock, 9 June 2014.]. Our choice originates from the fact that this social media is mainly used to share realtime information on current events and that the limitation on the length of tweets (maximum 140 characters) allows us to concentrate on relevant information. The idea to develop this tool comes from the need to annotate uptodate information on a critical event, for example with the goal of training machine learning classifiers. The tool is designed for creating annotated datasets of tweets and users that will be used in the training phase, and to enable a more performing approach on tweets manual annotation compared to already existing approaches. The initial idea was to have as output annotated datasets of tweets regarding emergency and danger situations (natural disasters, earthquakes, floods, etc.), but in a second phase the tool has been extended to allow for the creation of annotated datasets according to different needs (eg. sentiment analysis, tweets credibility, etc.). #tweeTag is part of SoS Social Sensing , a project at the Institute of Informatics and 1
Telematics at CNR in Pisa. The project aims to leverage social media users as "social sensors" and, by analyzing contents shared on the most popular social media, to identify and understand events raising social concern such as earthquakes, floods, civil unrest or other emergency situations. This technical report describes the concept, design, development, and implementation of #tweeTag, compares it with similar existing web tools, explains why our tool is different and what its characteristics are, and describes the experiments that have been carried out on it to test its usability. The report is organized as follows: section 2 describes #tweeTag and the different types of annotations. Section 3 describes how the tool was implemented and developed. Sections 4 and 5 reports our attempts to evaluate the system and the results obtained. Section 6 reviews related work in the area of web annotation tools. Section 7 concludes the paper and describes some future directions for the work.
1 www.socialsensing.eu
2
2. #tweeTag This tool is a web application accessible via a web browser. In this way, #tweeTag can be potentially used as as crowdsourcing system. The interface is intuitive and userfriendly, to make the annotation easier and less time demanding. There are two types of users in #tweeTag:
Annotators, which can annotate one or more campaigns and review their own annotations.
Super annotators, which, in addition to annotators permission, have the opportunity to control campaigns, review annotations, visualize additional details, such as the tweets on which the annotators disagree. They also can modify the labels chosen by annotators.
The tool allows users to annotate one or more campaigns. A campaign is a collection of tweets which will be annotated by one or more annotators according to a predefined task (e.g. sentiment analysis, tweets credibility, etc.). The tweets annotated are retrieved from the database and showed to the user from the latest to the oldest and he can modify them. It’s also possible to chose to view only the tweets annotated with a certain label, or those which have a certain comment or even search tweets by keywords. #tweeTag allows three different types of annotations, described in following sections, opening up new possibilities for analysis of the observed phenomenon. After the login, users can select an annotation campaign among those who have been assigned; the user then accesses the dataset and starts the annotation. When the assignment of a label to a tweet is ambiguous, users can skip the tweet and go on annotating another tweet. Each annotation can be commented thanks to a textarea with a maximum of 100 characters; comments will be visualized and, possibly, modified in the user’s profile. Most annotation campaigns involve a small group of trained annotators who may not always agree on their judgements. The reliability of the annotation is typically assessed by quantifying the level of interannotator agreement, which is the degree of agreement among annotators. It gives a score of how much homogeneity, or consensus, there is in the annotations given by users. There are a number of statistics which can be used to determine interannotator (or interrater) reliability. In #tweeTag we used the Cohen’s kappa (κ), which is a more robust measure than simple percent agreement calculation since it takes into account the agreement occurring by chance. If the raters are in complete agreement then κ = 1. If there is no agreement among the raters other than what would be expected by chance, κ = 0. To describe the degree of concordance we used the scale proposed by Landis & Koch [9].
3
The interannotator agreement is available for those campaigns which have been concluded and it is currently available only for the global annotations. We’re planning to implement it for the other types of annotations too.
Global annotation The first type of annotation is the global annotation. As suggested by its name, it is the annotation of the whole tweet: it is possible to flag each tweet composing a dataset as related or not related with the specific context of analysis. This first type of annotation is ideal to obtain the topic of discussion or other generalizations (e.g., if it is or not related to a certain phenomenon, if it is positive or negative, etc.). The purpose of the campaign is detailed in the main page, where five tweets per time are embedded in order to be annotated with related labels (Figure 1). When a user completes the annotation of a tweet, the annotation is stored in a database, the tweet disappears from the user interface, and a new tweet is appended at the end the list. To facilitate the annotation, the interface offers a global view of the tweet as it appears on Twitter. In addition to the text, other contextual information such as date and time of publication, geolocation, number of retweets and replies, are provided. In this way an annotator is able to provide a more accurate and precise annotation according to the required task.
Figure 1. Global annotation interface
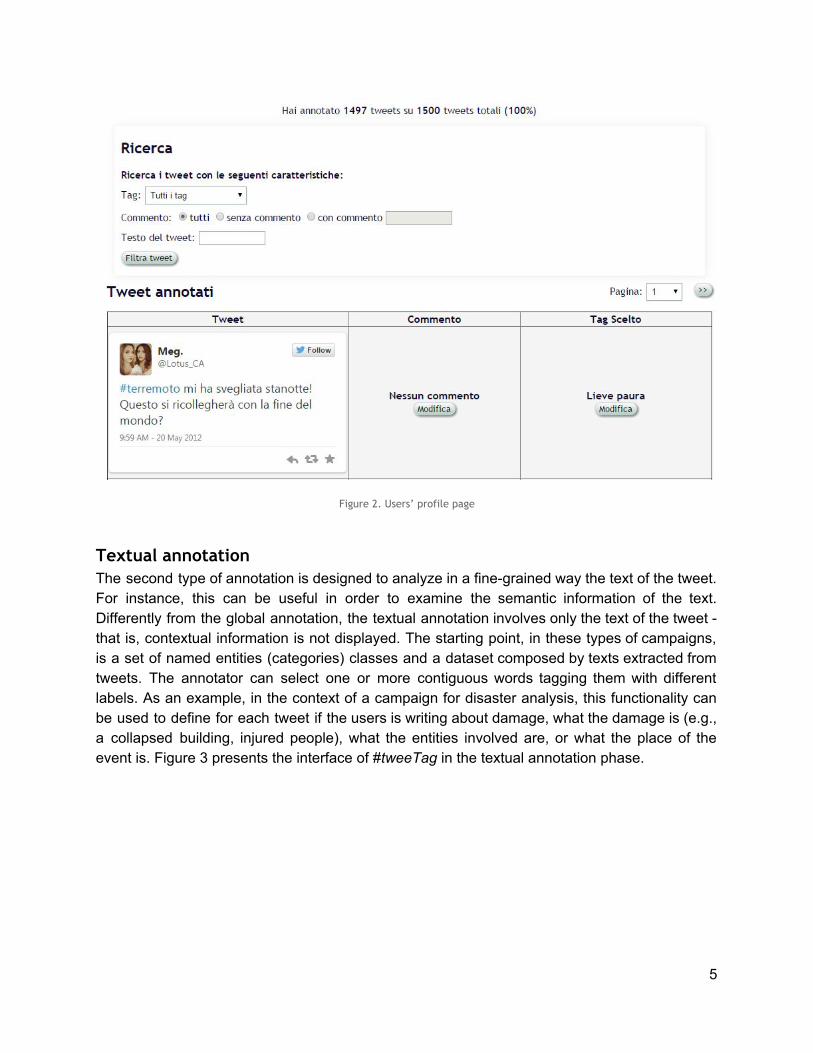
As presented in Figure 2, the profile page is used to allow annotators to search, review, edit and correct the annotations of a given campaign. It also provides a percentage of annotated tweets of the campaign.
4
Figure 2. Users’ profile page
Textual annotation The second type of annotation is designed to analyze in a finegrained way the text of the tweet. For instance, this can be useful in order to examine the semantic information of the text. Differently from the global annotation, the textual annotation involves only the text of the tweet that is, contextual information is not displayed. The starting point, in these types of campaigns, is a set of named entities (categories) classes and a dataset composed by texts extracted from tweets. The annotator can select one or more contiguous words tagging them with different labels. As an example, in the context of a campaign for disaster analysis, this functionality can be used to define for each tweet if the users is writing about damage, what the damage is (e.g., a collapsed building, injured people), what the entities involved are, or what the place of the event is. Figure 3 presents the interface of #tweeTag in the textual annotation phase.
5
Figure 3. Textual annotation interface
In case of textual annotation, the page displays the text of the tweet divided into its sentences and the annotator can select individual tokens or groups of adjacent tokens. Then, the choice of the label is made possible by a series of buttons. The user interface also features a profile page that shows the tweets annotated in an embedded view, and the annotations made on the tokens, with the possibility to modify them thanks to a button which links to the main page.
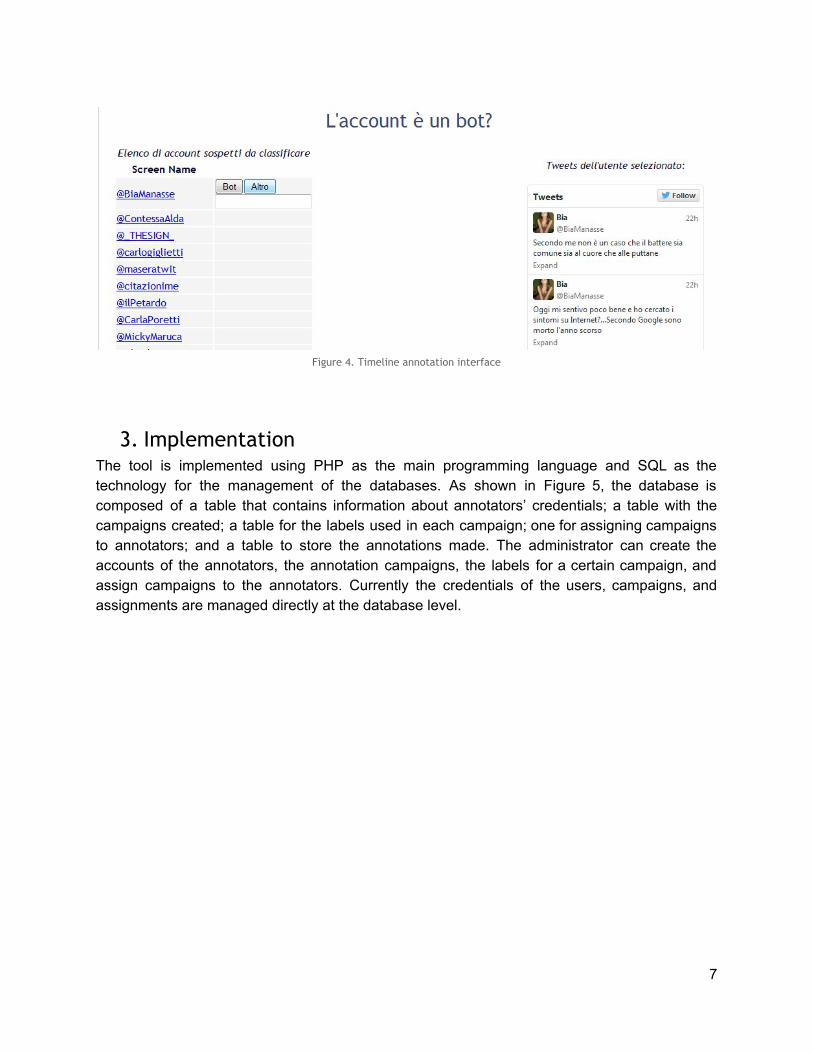
Timeline annotation The third type of annotation allows to evaluate Twitter users through the annotation of their timeline. This type of annotation allows to identify trends, practices or anomalies in the use of Twitter, such as the presence of fake or inactive users and bots (accounts used to produce automated posts and spam). The annotation user considers the last few 20 tweets of a user shown through an embedded view. The timeline annotation page appears split into two main columns topped by the question to be answered for the annotation (see Figure 4). The left column is the list of all screen names of the users that need to be annotated. In the second column is displayed the timeline of the selected user. When a user is selected, the timeline, the available options for the annotation, and a textarea for comments will appear. When the annotation is completed, the user together with its timeline will disappear from the list. If the annotator needs additional information to complete the annotation task, clicking on the screen name of the user allows a redirection to its Twitter page. Annotations are summarized in the annotator’s profile page with the possibility to change them. This type of annotation can be seen in Figure 4.
6
Figure 4. Timeline annotation interface
3. Implementation The tool is implemented using PHP as the main programming language and SQL as the technology for the management of the databases. As shown in Figure 5, the database is composed of a table that contains information about annotators’ credentials; a table with the campaigns created; a table for the labels used in each campaign; one for assigning campaigns to annotators; and a table to store the annotations made. The administrator can create the accounts of the annotators, the annotation campaigns, the labels for a certain campaign, and assign campaigns to the annotators. Currently the credentials of the users, campaigns, and assignments are managed directly at the database level.
7
Figure 5. E/R model of the database
The annotation process starts from a dataset that has to be annotated. This dataset is assigned to one or more annotators. The data not yet annotated will be shown in the main page and once labeled will be saved in the database and will disappear from the user interface. We adopted different approaches to develop the three types of annotations. In the global annotation section, the tool retrieves with a query the tweets that the annotator has not annotated yet for the selected campaign. Twitter makes it possible to integrate embedded Tweets applications through APIs. The tweets are shown in chronological order and there is the possibility of moving over time periods thanks to an interactive calendar (implemented with a Datepicker widget). For the textual annotation of tweets, the text is retrieved with a query from the database. For each tweet in the dataset, the text of that tweet is split at server level in its sentences and then in tokens. This is made possible thanks to a technology that was created using an analysis tool developed by the Italian linguistic NLP Lab [10]. The tweet retrieved is sent to the server that hosts the linguistic annotation tool; then the tool splits the text of the tweet in sentences and then splits each sentence into small units called tokens (typically words). The result is stored in a JSON object which is sent back to #tweeTag and shown in the page where it is possible to select individual tokens or groups of adjacent tokens and annotate them with the available labels.
8
In the timeline annotation user timelines are retrieved with a query to the database. The buttons for the annotation are dynamically created for each user selected. The timeline appears after selecting a user. Again, this functionality is provided by a Twitter widget.
4. Possible uses of #tweeTag In order to test different functionalities offered by #tweeTag we ran several annotation campaigns, targeted to different objectives. In particular, we conducted:
six different campaigns to test the global annotation, detailed in this report; two campaigns for the timeline annotation; one campaign for the textual annotation.
Global annotation functionality To test the global annotation functionality we conducted six distinct campaigns targeted to different objectives. In this way we want to demonstrate that #tweeTag can be used for different purposes and in different domains. In the first global annotation campaign we used #tweeTag to annotate a dataset of tweets and determine which are related or not to a specific event. In this context #tweeTag can be useful for the preparation of training and test sets composed by tweets. We asked three annotators to annotate a dataset composed by 2,414 tweets in English posted during the earthquake occurred January 15, 2014 in California. The question asked was whether a tweet was referred to an ongoing earthquake or not. According to this question, two possible labels were defined:
Related for tweets that refer to an ongoing earthquake (e.g., “Now that was a big #quake. Woke me from a sound sleep in San Francisco.”);
Not related to annotate tweets that refer to a past earthquake (e.g., “after the 1906 quake, a lot of the city was rebuilt to withstand this and since it wasn't right under the city, it was minor!”).
As shown in Figure 6, 1.034 tweets labeled by the annotators as related to the event, 860 not related and 520 skipped.
Figure 6. Results of first campaign global annotations
We then used the global annotation to help the analysis of upcoming natural disasters. In particular, the main objective of three annotations was to build a dataset containing tweets related three natural disasters occurred in Italy in order to study their consequences: the earthquakes occurred in Emilia Romagna in 2012, the flood in Sardinia in 2013 and the flood of Senigallia in 2014. Starting from an initial dataset collected using Twitter API and composed by 4,595 tweets, we posed to three annotators this question: “Is the tweet related to an ongoing event? If so, are there any damages?". Three different labels was available:
Not related, for tweets that don’t refer to an ongoing event (e.g., “It means shaking my head guys”);
without damage to annotate tweets related to an ongoing event but without information about damages (e.g., “First time an earthquake woke me up ”);
with damage to annotate tweets related to an ongoing event and containing information about damages (e.g., “Quake Rocks California Wine Country, Dozens Injured”).
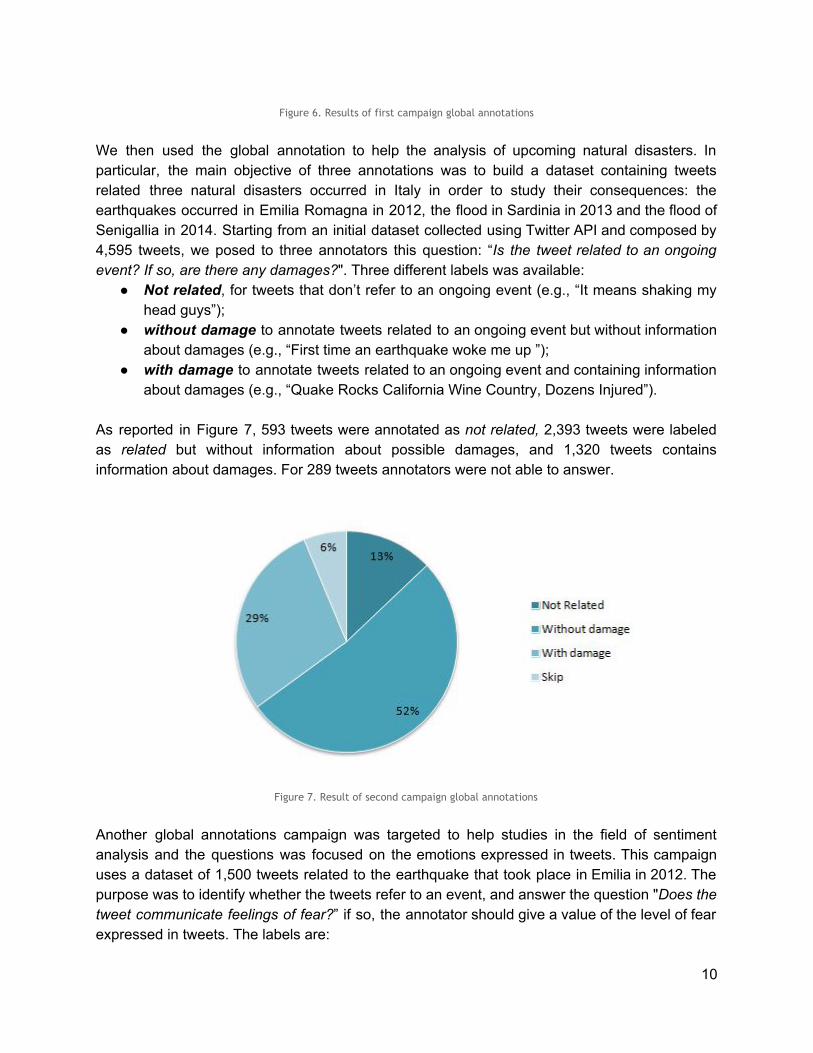
As reported in Figure 7, 593 tweets were annotated as not related, 2,393 tweets were labeled as related but without information about possible damages, and 1,320 tweets contains information about damages. For 289 tweets annotators were not able to answer.
Figure 7. Result of second campaign global annotations
Another global annotations campaign was targeted to help studies in the field of sentiment analysis and the questions was focused on the emotions expressed in tweets. This campaign uses a dataset of 1,500 tweets related to the earthquake that took place in Emilia in 2012. The purpose was to identify whether the tweets refer to an event, and answer the question "Does the tweet communicate feelings of fear?” if so, the annotator should give a value of the level of fear expressed in tweets. The labels are:
10
Not related to annotate tweets that don’t refer to a particular event (e.g., "I wonder what it would feel like going over the bridge during an earthquake”);
No fear tweets that refers to an event but don’t express any feelings of fear (e.g., “Last night in California and we have a nice little earthquake that wakes me up at 3:20 in the morning”);
Slight fear referring to a particular tweet that makes a barely perceptible feeling of fear (e.g., “Damn. Late night earthquake in SF...”);
Moderate fear to annotate tweets that communicate a feeling of moderate fear (e.g., “thanks to the earthquake I'm gonna be scared for the rest of the night”);
Intense fear tweets that express a strong feeling of fear (e.g., “OH GOD! We just had a mini earthquake I'm scared I'm scared I'm scared I'm scared I'm scared I'm scared I'm scared I'm scared”).
This dataset had 1,500 tweets annotated like this: 4 not annotated, 64 skipped, 289 tweets with strong fear, 212 with moderate fear, 131 with a slight fear, 788 tweets do not communicate fear and 11 unrelated. The results of this campaign are graphed through this graph.
Figure 8. Result of third campaign global annotations
5. Results Tests have been useful in order to measure the application degree of adequacy to the task proposed. The results showed a functional tool; the intensive use of the code during the development phase helped identifying and resolving bugs. The data collected can be used for statistical analysis or to train supervised models. Thanks to the experiments conducted we've been able to improve the tool and remove some bugs, especially in the profile page.In fact the annotators were useful in showing us their practical needs when retrieving old annotations, giving us the opportunity to develop a very sophisticated research section.
11
6. Related work Annotated datasets of tweets are difficult to obtain. There are automatic annotation tools that already exist which have been trained on formal documents, such as journal articles, but their performance on texts from Twitter is poor, due to the informal nature of tweets. In fact “Systems analyzing correctly about 90% of the sequences from a journalistic corpus can have a decrease of performance of up to 50% on more informal texts” [1]. Tweets are unlike formal text. They are limited to a maximum of 140 characters, so the use of acronyms and abbreviations (e.g., w/ for with, ur for your, etc.) are very common and grammar rules are often ignored. Moreover, users have adopted some conventions such as hashtags (e.g., #quake), user mentions (e.g., @obama), and retweet (e.g., RT @KatyinIndy). Informal domains, such as Facebook, Twitter, YouTube or Flickr are starting to receive more attention, therefore the study of these social networks requires at least a minimal amount of labeled data for evaluation purposes. That’s why there have been developed tools for manual annotation of this type of data in the past few years. The web offers a wide variety of tools to annotate data from social networks, but #tweeTag has been created to suit the characteristics of Twitter. We found some webbased annotation tools for social media data, but they didn’t fit our need of a customizable instrument that enables to make different type of annotations. A lot of research work related to Twitter analysis is mainly focused on Sentiment Analysis. Kouloumpis et al. [2] have discovered that the features of microblogging are very useful in sentiment analysis classification thanks to the presence of emoticons in the text. Saif et al. [3] have conducted a work of Sentiment Analysis using a training set of manually annotated tweets. To simplify and speed up the annotation efforts, they built Tweenator [4], a webbased sentiment annotation tool that allows users to assign a sentiment label to tweet messages (i.e. assign a negative, positive or neutral label to a certain tweet with regards to its contextual polarity). However, their tool is set only for a purpose of sentiment analysis. In addition to sentiment analysis, #tweeTag allows to label tweets for different detections, e.g. fear detection or state of danger. Furthermore, our tool has the practical view of embedded tweets, which is really useful in helping provide background information. We noticed that in addition to facilitating the task of annotators, the tweets embedded view makes very pleasant the tedious and mechanical work of manual annotation. Another annotation tool has been created by Sravan Kumar G [5] to assess tweets credibility. This tool allows to annotate tweets regarding various events, but the labels used are always the same: “Credible” “Incredible” and “Not relevant”. With #tweeTag the labels are customizable according to the purpose of the annotation. Moreover, our interface is more intuitive. Similar to #tweeTag annotation text is the work conducted by Tim Finin et al. [6] at low cost using Amazon Mechanical Turk (MTurk) to identify three basic types of named entities: person, organisation and location. The words of the tweet are displayed vertically and for each word the labels are showed with radio buttons, therefore the interface is very redundant. #tweeTag allows to select one or more words and then select the label in a simple and intuitive way.
12
Although a tool like MTurk is reliable and welltested, it does not allow the complete management of datasets. If a more specific annotation is required it may not be the ideal tool to be taken into account. Furthermore, it can be expensive to efficiently annotate large volumes of data. #tweeTag has several characteristics which make it innovative and advantageous for the sector. In particular, the benefit of preparing several campaigns with different tasks; the presence of three different types of way to annotate data (global, textual, user); and the fact that the tool is supported by a very versatile database that meets all the requirements to become a database for crowdsourcing. #tweeTag has already been employed for the annotation of tweets related to several published studies, such as [11, 12].
7. Conclusions and future works This report present #tweeTag, an intuitive and userfriendly Webbased online annotation tool and evaluate its effectiveness from a usability perspective. The main characteristic of #tweeTag is the ability to concentrate in a single tool two different approaches to annotate the tweet, globally and textually, and an additional section to annotate timelines. In addition, Embedded Tweets make it possible to make annotation process more coherent and more intuitive and provides an intuitive way to present annotations, enabling annotators to view the information they need to evaluate the tweet (date, time, user, geolocation, etc.) all at once. Thanks to the structure of the database, which has the ability to adapt to any type of task, possible future projects may include the extension of the application to a crowdsourcing annotation tool and the setup of a full opensource annotation platform which allows registration for both people willing to annotate tweets and people in need to have some annotations done. Future works will be focused in improving annotations functionalities and the design of the interface.
8. References 1. Poibeau, T., & Kosseim, L. (2001). Proper name extraction from nonjournalistic texts. Language
and computers, 37(1), 144157. 2. Kouloumpis, E., Wilson, T., & Moore, J. D. (2011). Twitter sentiment analysis: The good the bad and
the omg!. Proceedings of ICWSM’11, 538541. 3. Saif, H., He, Y., & Alani, H. (2012). Alleviating Data Sparsity for Twitter Sentiment Analysis.Making
Sense of Microposts (# MSM2012). 4. http://www.tweenator.com/ 5. Kumar, S. Ranking Assessment of Event Tweets for Credibility. 6. Finin, T., Murnane, W., Karandikar, A., Keller, N., Martineau, J., & Dredze, M. (2010, June).
Annotating named entities in Twitter data with crowdsourcing. InProceedings of the NAACL HLT
2010 Workshop on Creating Speech and Language Data with Amazon's Mechanical Turk (pp. 8088). Association for Computational Linguistics.
7. Sakaki, T., Okazaki, M., & Matsuo, Y. (2010, April). Earthquake shakes Twitter users: realtime event detection by social sensors. In Proceedings of the 19th international conference on World wide web (pp. 851860). ACM.
8. Crooks, A., Croitoru, A., Stefanidis, A., & Radzikowski, J. (2013). # Earthquake: Twitter as a distributed sensor system. Transactions in GIS, 17(1), 124147.
9. Landis, J. R., & Koch, G. G. (1977). The measurement of observer agreement for categorical data. Biometrics, 159174.
10. http://linguisticannotationtool.italianlp.it 11. Cresci, S., Cimino, A., Dell’Orletta, F., & Tesconi, M. (2015). Crisis mapping during natural disasters
via text analysis of social media messages. InWeb Information Systems Engineering–WISE 2015 (pp. 250258). Springer International Publishing.
12. Cresci, S., Tesconi, M., Cimino, A., & Dell'Orletta, F. (2015, May). A linguisticallydriven approach to crossevent damage assessment of natural disasters from social media messages. InProceedings of the 24th international conference on world wide web companion (pp. 11951200). International World Wide Web Conferences Steering Committee.
13. Aliprandi, C., De Luca, A. E., Di Pietro, G., Raffaelli, M., Gazzè, D., La Polla, M. N., ... & Tesconi, M. (2014, August). CAPER: Crawling and analysing Facebook for intelligence purposes. In Advances in Social Networks Analysis and Mining (ASONAM), 2014 IEEE/ACM International Conference on (pp. 665669). IEEE.












![[Profilo Ospiti 2009] MUSEO PIAGGIO Viale Rinaldo Piaggio ... · Romagna, Japan Tobacco, MV Agusta… As the President of Greenpeace in Italy, he has organised several social campaigns](https://static.documenti.site/doc/80x56/5f3ceb8c403206049d243b9d/profilo-ospiti-2009-museo-piaggio-viale-rinaldo-piaggio-romagna-japan-tobacco.jpg)
















