Progetto VICE Definizione dell’architettura della piattaforma 1 Progetto VICE DOC. CU03.00004 : “Definizione dell’architettura della piattaforma - Documento di specifica e design per la piattaforma” Data: Lunedì 5 Aprile 2004
Transcript
Progetto VICE
Definizione dell’architettura della piattaforma 1
Progetto VICE
DOC. CU03.00004 : “Definizione dell’architettura della piattaforma -
Documento di specifica e design per la piattaforma”
2 Il Framework ......................................................................................................................................... 5
2.1 Struttura e ruoli ................................................................................................................................... 5 2.2 Metodi di accesso................................................................................................................................ 9 2.3 Architettura del framework ............................................................................................................... 10 2.4 Scenari di utilizzo ............................................................................................................................. 17
3 Il repository classico ............................................................................................................................ 26
4 Accesso navigazionale al repository ..................................................................................................... 35
4.1 Hyperbase......................................................................................................................................... 35 4.2 Le associazioni semantiche ............................................................................................................... 39 4.3 Il livello di accesso............................................................................................................................ 41 4.4 Hyperbase nel localizzatore............................................................................................................... 46
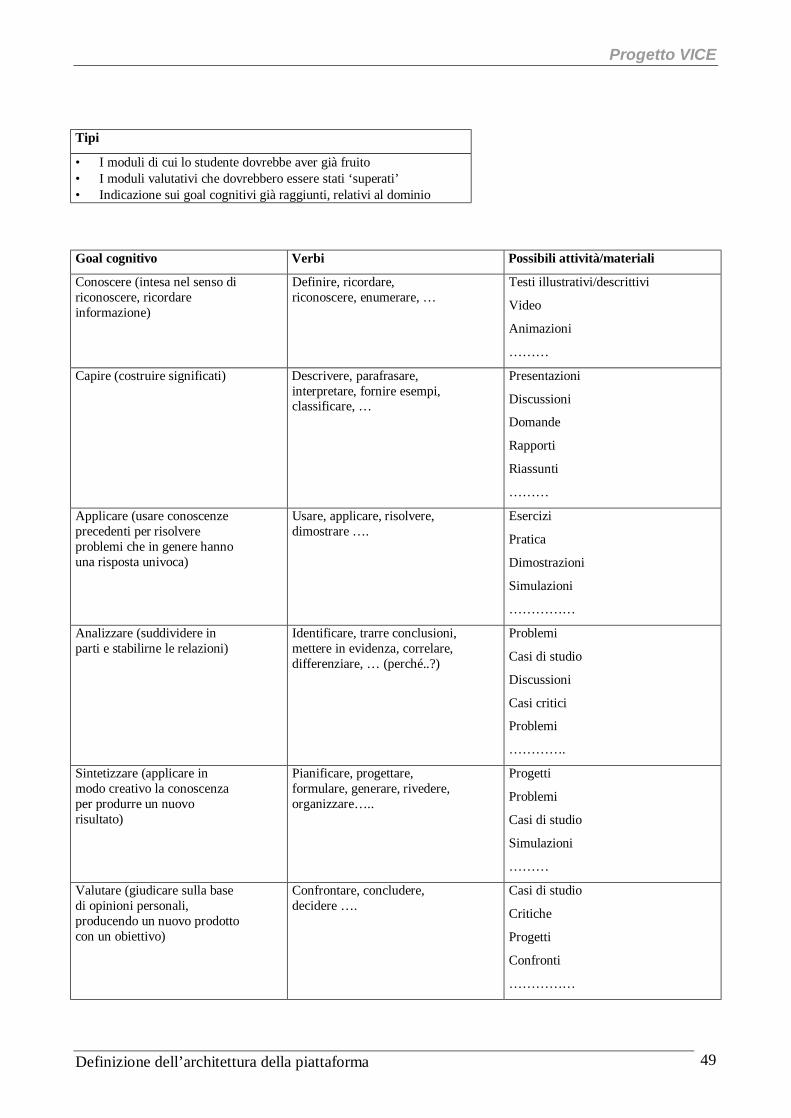
5 Il wizard pedagogico............................................................................................................................ 48
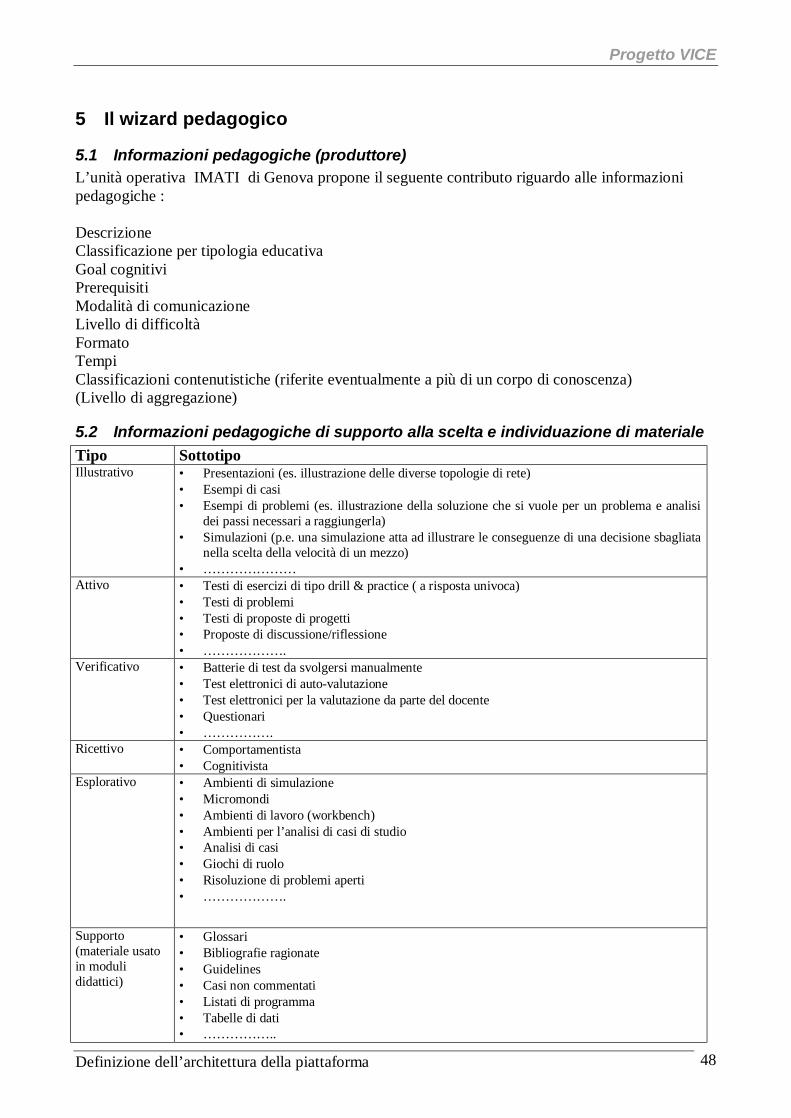
5.1 Informazioni pedagogiche (produttore).............................................................................................. 48 5.2 Informazioni pedagogiche di supporto alla scelta e individuazione di materiale ................................. 48 5.3 Osservazioni sugli aiuti per costruire un percorso in base ad un approccio educativo ......................... 50 5.4 Osservazioni su altri tipi di aiuto ....................................................................................................... 50
6 Il modulo ontologico............................................................................................................................ 52
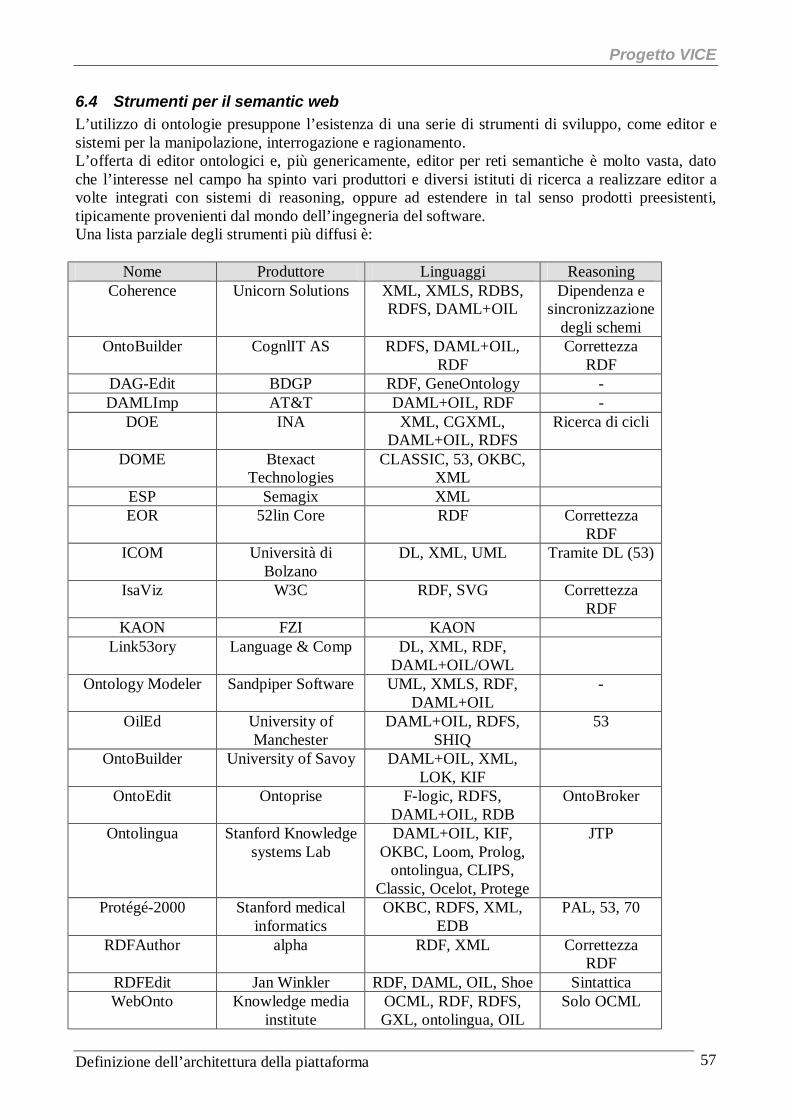
6.1 Le ontologie ed il semantic web ........................................................................................................ 52 6.2 Una struttura per il semantic web ...................................................................................................... 52 6.3 I linguaggi del semantic web ............................................................................................................. 54 6.4 Strumenti per il semantic web ........................................................................................................... 57 6.5 Le ontologie per l’e-learning ............................................................................................................. 58 6.6 I servizi basati sulle ontologie ........................................................................................................... 62 6.7 Implementazione............................................................................................................................... 68
7 Profilazione utente e adattività ............................................................................................................. 71
7.4 Aspetti cognitivi................................................................................................................................ 76 7.5 Aspetti tecnologici ............................................................................................................................ 77 7.6 Stato del contributo ........................................................................................................................... 79
8 Valutazione e validazione dell’usabilità ............................................................................................... 80
8.1 Learner-Centred Design vs User-Centred Design............................................................................... 81 8.2 Progettazione Learner- Centred ......................................................................................................... 83 8.3 Usabilità del software LC.................................................................................................................. 84 8.4 Interazione con i sistemi di e-Learning: uno studio pilota .................................................................. 88 8.5 Studio di linee guida per la valutazione di usabilità di piattaforme di e-Learning ............................... 89
1 Summary Il progetto VICE (Virtual Continuing Education) mira allo sviluppo di strumenti e metodi per la costruzione di learning object (LO) efficaci e riusabili, e di un repository che supporti la progettazione e la costruzione di moduli didattici, riutilizzando i learning objects disponibili. Gli obbiettivi del progetto si possono pertanto riassumere così:
• Costruzione di una piattaforma innovativa per la realizzazione di un repository, orientato a massimizzare la ricusabilità di Learning Objects.
• Sviluppare una metodologia che consenta di realizzare LO’s efficaci e di elevata ricusabilità. • Sviluppare metodi innovativi per accedere al repository. • Sviluppare metodi per la misurazione della usabilità e validità dei LO’s
I ruoli più importanti identificati per l’ambiente VICE sono quelli di amministratore di sistema, gestore della didattica (per creare l’impianto logico e dei metadati), organizzatore della didattica (che crea specifici moduli didattici utilizzando LOs), autore (che crea i singoli LOs).
Il repository che si intende sviluppare ha, alla base, una moderna architettura “classica”, basata sulla memorizzazione dei contenuti separata dai metadati; i contenuti possono anche essere “large objects” multimediali. I metadati hanno una struttura compatibile con i principali standard (SCROM in particolare). Il repository contiene descrittori dei metadati, e può anche contenere descrittori di LO’s “tradizionali” (lezioni, esercitazioni, test in aula, ..) o comunque senza un contenuto memorizzabile. L’accesso “classico” al repository avviene mediante search (per ora basate sui metadati ed in seguito estese a considerare il contenuto). Un altro meccanismo di accesso al repository si basa su di una “ipertestualizzazione” del suo contenuto: un impianto di navigazione consente di fare un browsing dei contenuti del repository, navigando, per esempio, da una “tecnologia”, ai “prodotti SW” che la realizzano o agli “esempi” della sua applicazione. Un terzo meccanismo di accesso, più sperimentale ed innovativo, si basa su di un “wizard pedagogico”, vale a dire su di un agente intelligente capace di individuare (a fronte dei requisiti di contenuto e degli obbiettivi didattici da raggiungere) i LOs più adatti e di costruire con essi un percorso didattico valido. Il wizard pedagogico presuppone la disponibilità di una “ontologia didattica” capace di rappresentare gli elementi più significativi di un approccio didattico, e di un meccanismo di “profilazione utente”, vale a dire di un meccanismo per individuare le caratteristiche salienti degli utenti del repository.
L’ultimo tema affrontato è la individuazione di uan metodologia sistematica per la valutazione della usabilità sia del repository, che dei LO’s in esso contenuti.
Progetto VICE
Definizione dell’architettura della piattaforma 5
2 Il Framework Obiettivo del seguente capitolo è descrivere, in modo dettagliato, il framework su cui si basa il repository. Se ne descrivono in particolare le strutture e le modalità d’accesso, i metodi di accesso ai dati e le metodologie utilizzate. Da ultimo si descriveranno alcuni possibili scenari di utilizzo.
2.1 Struttura e ruoli Nel seguente paragrafo si descrive la struttura logica del framework (dati e sottosistemi), si identificheranno i differenti ruoli che un utente può ricoprire e saranno descritti alcuni macro-scenari di utilizzo.
2.1.1 Dati
L’unità atomica di informazione che può essere acceduta utilizzando il repository sono i Learning Object (LO). Ogni LO è costituito da due parti fondamentali; i dati veri e propri, che possono essere informazioni di qualsiasi genere e in qualsiasi formato (raw-data), e le meta-informazioni sui dati stessi (metadata) che li caratterizzano; il repository è utilizzato per memorizzare entrambi i tipi di informazione. L’utilizzo dei metadata garantisce il riuso dei LO in diversi contesti. Esistono tuttavia particolari LO a cui non è associato alcun raw-data (si consideri per esempio il caso di un seminario o di un libro di testo) e il cui unico tipo di informazione che c’è nel repository sono i metadata. Associato al concetto di LO vi sono anche i concetti di versione e variante di un LO. In particolare, solo l’autore di un LO può crearne una nuova versione mentre le varianti di un LO possono essere create da tutti gli autori. In entrambi i casi è come se si creasse un nuovo LO anche se nei metadata viene tenuta traccia del LO da cui derivano. Ogni LO potrà inoltre appartenere a più tipologie (es. teorema, algoritmo, esempio grafica 3D) che lo caratterizzano a livello didattico: lo stesso LO può essere usato con scopi didattici od in ambiti differenti. Più LO possono essere, a loro volta, organizzati in Percorsi Didattici che ne definiscono una “sequenza” di fruizione in un processo di apprendimento. Analogamente ai LO anche ai Percorsi Didattici sono associati i metadata. Un insieme di Percorsi Didattici definiscono infine un Modulo didattico ovvero una sequenza ordinata di Percorsi Didattici. Tutta l’architettura del Framework è pensata in funzione sia dei dati sia della struttura logica e fisica in cui sono contenuti: il repository.
2.1.2 Sottosistemi Il framework è costituito da alcuni sottosistemi che, interagendo tra loro, contribuiscono a creare l’ambiente complessivo su cui poi sarà basato il funzionamento del repository. Queste parti possono essere considerate dei sottosistemi a tutti gli effetti e, definendo le opportune interfacce, possono essere implementate anche con linguaggi differenti trovando quindi la tecnologia che meglio si adatta alla realizzazione di ognuna di esse. Dal punto di vista logico si possono identificare sei sottosistemi:
• area pubblica: accessibile liberamente da un qualsiasi utente esterno che abbia accesso ai
canali di comunicazione previsti. Dall’area pubblica è possibile sia accedere ai LO e ai Percorsi Didattici contenuti nel repository sia effettuare alcune semplici operazioni. In particolare è possibile sfogliare e navigare i LO e i Percorsi Didattici, esportarli nella propria area privata. Non è invece consentito modificare i contenuti in alcun modo.
Progetto VICE
Definizione dell’architettura della piattaforma 6
• area privata: area riservata ai soli utenti registrati, mette a disposizione alcuni servizi
(metadata modeler, metadata editor) riservati a particolari categorie di utenza che necessitano di autorizzazione. Anche da questa zona è ovviamente possibile accedere al repository e ai dati in esso contenuti.
• localizzatore: dal punto di vista logico il localizzatore altro non è che un repository locale in tutto e per tutto simile al repository pubblico. Il localizzatore, di cui esiste un’istanza per ogni utente registrato, permettere agli utenti di avere in locale i LO e i Percorsi didattici su cui sta lavorando. Essi possono essere già presenti nel repository pubblico e copiati in locale per eventuali modifiche oppure possono essere creati ex-novo ed esportati nel repository pubblico, rendendoli disponibili a tutti.
• metadata modeler: accessibile solo dal gestore della didattica (descritto in seguito nel documento) permette di definire sia le classi di meta-informazioni (classi di metadata) che potranno essere associate ai LO e ai Percorsi Didattici, sia i vari tipi di associazioni utilizzate per collegare due LO.
• metadata editor: accessibile agli autori (descritti in seguito nel documento) permette l’istanziazione dei metadata e la loro associazione ad un raw-data o ad un Percorso Didattico. Il metadata editor permette inoltre sia la definizione della “sequenza” di fruizione dei LO in un Percorso Didattico sia la creazione e modifica di un Modulo Didattico.
• interfaccia di coordinamento: accanto ai sottosistemi precedentemente descritti si trova il sistema di coordinamento che costituisce il nucleo fondamentale del framework. Questo ne rappresenta il fulcro vero e proprio su cui si basano tutti gli altri sottosistemi che contribuiscono ad offrire le funzionalità e i servizi per il collegamento al repository.
Così configurato il framework è in grado di fornire le funzionalità cui è preposto, e di cui si parlerà più in dettaglio in seguito, mantenendo comunque un alto livello di modularità. Si rende in questo modo anche più semplice l’eventuale sviluppo futuro di ulteriori moduli che possono essere definiti, indipendentemente dalla tecnologia utilizzata, semplicemente analizzando accuratamente le interfacce messe a disposizione
2.1.3 Ruoli Si descrivono ora in dettaglio i ruoli degli attori che hanno accesso al repository. In particolare sono previsti tre ruoli. Ognuno di questi è caratterizzato da un differente tipo di accesso al repository. Non tutti i ruoli d’utenza possono accedere in scrittura ai dati contenuti del repository pubblico. In particolare, esiste il ruolo di amministratore di sistema che ha accesso a servizi particolari come gestione della correttezza dei dati e il management degli utenti del sistema (creazione utenti, cancellazione,utilizzo dei files di log, etc... ). Diversificando i servizi messi a disposizione per i vari ruoli di utenze si può schematizzare l’accesso all’applicazione nel seguente modo (Figura 1):
• amministratore di sistema: ha accesso al repository con funzioni di controllo e amministrazione. Ha la possibilità di gestire gli utenti e il loro profilo, può controllare la correttezza dei dati nel repository. Ha accesso inoltre alle informazioni relative ai profili utente. Gestisce l’abilitazione degli organizzatori della didattica.
Progetto VICE
Definizione dell’architettura della piattaforma 7
• gestore della didattica: definisce e gestisce le classi di metadata e di associazione.
• organizzatore della didattica: accede al repository per creare i moduli didattici utilizzando i
percorsi didattici e i LO creati dai vari autori. Può inoltre creare nuove associazioni tra LO.
• autore: crea e gestisce i LO e i Percorsi Didattici nel repository. Può inserire nuovi raw-data nel repository (facendone l’upload dal proprio PC), può verificare la consistenza con le informazioni già presenti nel repository, può importare i LO dal repository centrale al proprio localizzatore o li può esportare all’esterno del repoitory. Durante il processo di importazione dei LO dal repository centralizzato verso quello locale, l’autore può decidere di importarne solo i descrittori oppure anche i raw data annessi. Può anche decidere di importare un singolo LO o tutti i LO collegati. Il localizzatore conterrà quindi una replica parziale del repository pubblico oltre alle informazioni private (non ancora rese pubbliche) di ogni utente.
Figura 1 – I ruoli degli utenti
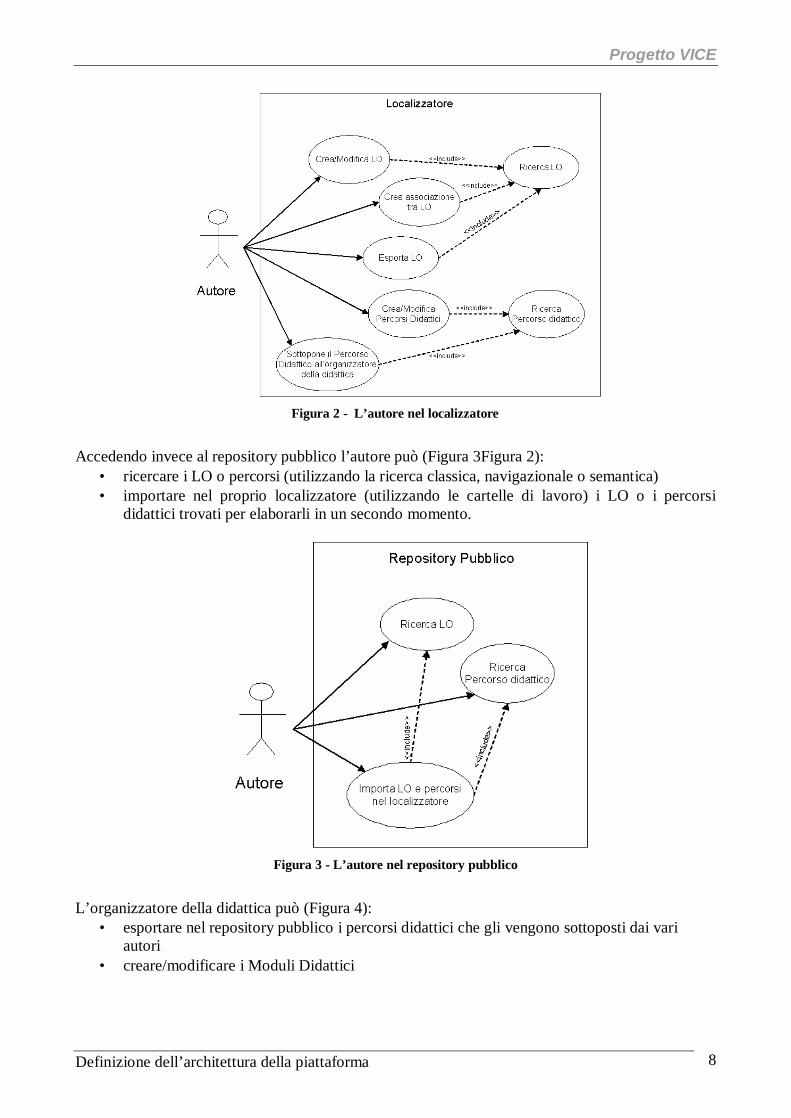
2.1.4 Macro-scenari di utilizzo Nel seguente paragrafo sono descritte le funzionalità che il sistema offre ai vari utenti. Come già evidenziato gli utenti principali del sistema sono l’autore e l’organizzatore e il gestore della didattica. L’autore può accedere sia al localizzatore che al repository pubblico; in particolare accedendo al localizzatore egli può (Figura 2):
• creare e/o modificare i LO • creare e/o modificare i percorsi didattici • creare le associazioni semantiche tra LO • esportare nel repository pubblico i LO creati o modificati • sottoporre i percorsi didattici creati all’organizzatore della didattica ne deciderà
l’esportazione nel repository pubblico.
Progetto VICE
Definizione dell’architettura della piattaforma 8
Figura 2 - L’autore nel localizzatore
Accedendo invece al repository pubblico l’autore può (Figura 3Figura 2):
• ricercare i LO o percorsi (utilizzando la ricerca classica, navigazionale o semantica) • importare nel proprio localizzatore (utilizzando le cartelle di lavoro) i LO o i percorsi
didattici trovati per elaborarli in un secondo momento.
Figura 3 - L’autore nel repository pubblico
L’organizzatore della didattica può (Figura 4):
• esportare nel repository pubblico i percorsi didattici che gli vengono sottoposti dai vari autori
• creare/modificare i Moduli Didattici
Progetto VICE
Definizione dell’architettura della piattaforma 9
Figura 4 - L'organizzatore della didattica nel localizzatore
Il gestore della didattica può (Figura 5):
• definire nuovi tipi di metadata • definire nuovi tipi di associazioni semantiche • esportare nel repository pubblico i tipi di metadata e di associazioni semantiche
Figura 5 – Il gestore della didattica nel localizzatore
2.2 Metodi di accesso Accanto al concetto di ruolo di utenza, che consente di definire le modalità per accedere all’applicazione, si definiscono anche tre differenti modalità di accesso alle informazioni contenute nel repository. Questo avviene indipendentemente da come si è acceduto al framework. In particolare le differenti tipologie di accesso ai dati non dipendono dal ruolo che si ricopre ma quanto dalle finalità della ricerca che si vuole effettuare. Ogni ruolo di utenza che abbia a propria disposizione il servizio di ricerca all’interno del repository può, di volta in volta, decidere quale tipologia di accesso sia la più indicata per ottimizzare il proprio lavoro.
Nello specifico le differenti modalità di accesso ai dati si possono schematizzare come segue:
Progetto VICE
Definizione dell’architettura della piattaforma 10
• Accesso ipertestuale/navigazionale: i LO e i percorsi didattici sono organizzati in collezioni. Per esempio è possibile organizzarli in base alla tipologia o all’argomento trattato. Una volta acceduto ad un LO è inoltre possibile navigare verso altri LO utilizzando le associazioni semantiche.
• Accesso di tipo semantico o pedagogico: l’accesso alle informazioni (LO e Percorsi)
avviene tramite una ricerca che tiene conto di varie informazioni quali, per esempio, la profilazione dell’organizzatore, chi fa la ricerca, la profilazione dei destinatari (target) e dei LO. Ad esempio: io (autore x) voglio organizzare un corso di informatica grafica (argomento y) per studenti di disegno industriale (target z). Grazie agli agenti che saranno implementati il risultato proposto è un corso tarato in base alle caratteristiche di chi vuol fare il corso e anche in base al profilo del target. Le basi informatiche e le finalità del corso cambiano in base al tipo di studente.
• Accesso per contenuto con ricerche effettuate utilizzando le informazioni relative ai LO.
Questo tipo di accesso comprende l’accesso classico sugli attributi, come per le basi di dati tradizionali: ad esempio (autore x, data y, lingua it). Il risultato sarà uno o più LO di quell’autore di quella data in italiano. Inoltre questo tipo di accesso permette di fare ricerche anche senza specificare esattamente i campi della struttura interessati (ricerca tipica per dati semi-strutturati): ad esempio, si vuole esaminare i LO in cui si parla, anche come argomento secondario, di “semantic web”. In questo caso la ricerca di tipo testuale su “semantic web” può venire effettuata non solo su campi come Titolo e Descrizione associati al LO, ma, se presenti, anche su campi contenuto del LO, come un trascritto dello speaker, nel caso di audio/video, il contenuto testuale di slide di presentazioni, etc..
I tre tipi di ricerca, dal punto di vista logico, restituiscono come risultato un insieme di LO o Percorsi Didattici. La loro differenziazione non si ha a livello di risultato ma riguarda il metodo di ricerca effettuato sul repository. In ultima analisi, quindi, i tre metodi di ricerca attuano un differente tipo di approccio ai metadata che identificano i LO e producono un risultato che può essere diverso a seconda di quanto queste meta-informazioni siano state analizzate e processate.
2.3 Architettura del framework In questa parte del documento si analizza la struttura fisica del framework. Vengono definite le tecnologie che si utilizzano e si analizzano nel dettaglio i componenti fondamentali di cui è già stata discussa la funzione logica.
2.3.1 Architettura fisica Nell’ambito del progetto, è stato disegnato un framework architetturale con caratteristiche specifiche per supportare adeguatamente gli scenari di utilizzo e i tipi di accesso ai LO, precedentemente descritti.
Il framework si basa sui servizi forniti da MILOS (MultImedia Learning Object Server), un sistema di Repository per la memorizzazione e il recupero dei LO, appositamente disegnato in questo progetto. MILOS è basato su un potente database/repository multimediale, in grado di garantire funzionalità di persistenza, ricerca e recupero di LO descritti secondo lo standard XML del W3C. L’uso dello standard XML come formato di memorizzazione dei metadati dei LO presenta diversi vantaggi, come l’integrazione di più formati di metadati, la possibilità di utilizzare potenti linguaggi di interrogazione come XPATH e XQUERY, la possibilità di mettere in relazione diverse
Progetto VICE
Definizione dell’architettura della piattaforma 11
componenti di metadati, tramite lo standard XLINK, la possibilità di definire schemi su metadati tramite XML Schema, etc . Nel framework complessivo dell’architettura, MILOS realizza il repository pubblico, che fornisce i propri servizi alle atre componenti distribuite del framework come web-services. Il repository MILOS, al suo interno è strutturato a tre livelli:.
• Al livello inferiore, si trovano i due moduli che gestiscono i due database, logicamente e fisicamente differenti, dei metadati dei LO e dei raw-data che compongono i LO. I metadata sono contenuti in un repository per la gestione di oggetti XML (XMLSE) [1]. I raw data sono contenuti invece in un repository che supporta semplici funzioni di accesso diretto, inserzione, eliminazione e update. Le query, effettuate dal livello superiore di MILOS (business logic) sul repository dei metadati di LO, in linguaggi XML, verranno eseguite utilizzando XMLSE come engine di ricerca. I LO vengono restituiti alla business logic dal repository che contiene i raw data utilizzando il formato SCORM (Sharing Content Object Reference Model).
• Nel livello intermedio di MILOS troviamo la sua business logic. A questo livello avviene la gestione degli accessi ai repository. Lo strato operativo prende il nome di ARSL (Adaptable Repository Service Logic). L’interrogazione alla logica di business si effettua utilizzando opportuni XML-schema, mentre il flusso di LO verso il livello superiore avviene sempre tramite il formato SCORM.
• Il livello d’interfaccia di MILOS è realizzato utilizzando dei web-services che sono pubblicati verso l’applicazione e che mettono a disposizione dell’utente di MILOS una API (Application Program Interface) per l’accesso al repository. I vari servizi necessari per interagire con il repository sono realizzati dalle API e a queste si può accedere richiamando il web-service che le invoca.
Un altro ruolo di MILOS nel framework complessivo è di fornire servizi di middleware (realizzati su di un web-server e un application server) per gestire l’interazione tra il repository pubblico/centralizzato e i repository locali, con opportune opzioni di sincronizzazione.
La gestione dei dati utilizzando il formato SCORM rende anche necessaria la presenza, in un livello intermedio, dello SCORM Run Time Environnement che gestisce l’interazione tra i pacchetti SCORM e il client. Per le ricerche di dati correlati che forniscono percorsi ipertestuali di navigazione del repository si utilizza XLINK. In questo modo i metadati risultano legati tra loro in relazione al contenuto del LO ed è possibile creare in maniera naturale percorsi semantici all’interno del repository e realizzare una navigazione e una ricerca per contenuti affini. La fruizione dell’applicazione avviene tramite interfaccia web. Su questa si possono trovare i servizi per l’accesso al repository centralizzato e i servizi per l’accesso alle parti localizzate di repository dove il ruolo d’utenza lo consenta. Su un server web sono anche pubblicati i contenuti per la fruizione.
Progetto VICE
Definizione dell’architettura della piattaforma 12
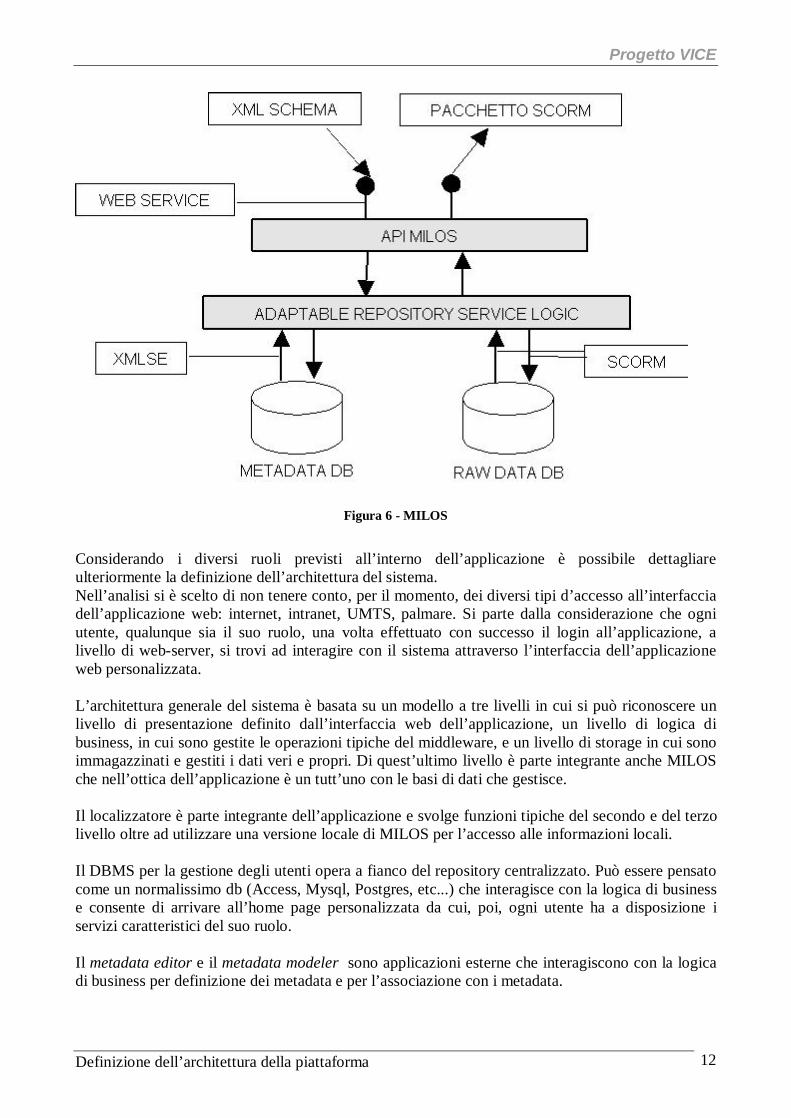
Figura 6 - MILOS
Considerando i diversi ruoli previsti all’interno dell’applicazione è possibile dettagliare ulteriormente la definizione dell’architettura del sistema. Nell’analisi si è scelto di non tenere conto, per il momento, dei diversi tipi d’accesso all’interfaccia dell’applicazione web: internet, intranet, UMTS, palmare. Si parte dalla considerazione che ogni utente, qualunque sia il suo ruolo, una volta effettuato con successo il login all’applicazione, a livello di web-server, si trovi ad interagire con il sistema attraverso l’interfaccia dell’applicazione web personalizzata. L’architettura generale del sistema è basata su un modello a tre livelli in cui si può riconoscere un livello di presentazione definito dall’interfaccia web dell’applicazione, un livello di logica di business, in cui sono gestite le operazioni tipiche del middleware, e un livello di storage in cui sono immagazzinati e gestiti i dati veri e propri. Di quest’ultimo livello è parte integrante anche MILOS che nell’ottica dell’applicazione è un tutt’uno con le basi di dati che gestisce. Il localizzatore è parte integrante dell’applicazione e svolge funzioni tipiche del secondo e del terzo livello oltre ad utilizzare una versione locale di MILOS per l’accesso alle informazioni locali. Il DBMS per la gestione degli utenti opera a fianco del repository centralizzato. Può essere pensato come un normalissimo db (Access, Mysql, Postgres, etc...) che interagisce con la logica di business e consente di arrivare all’home page personalizzata da cui, poi, ogni utente ha a disposizione i servizi caratteristici del suo ruolo. Il metadata editor e il metadata modeler sono applicazioni esterne che interagiscono con la logica di business per definizione dei metadata e per l’associazione con i metadata.
Progetto VICE
Definizione dell’architettura della piattaforma 13
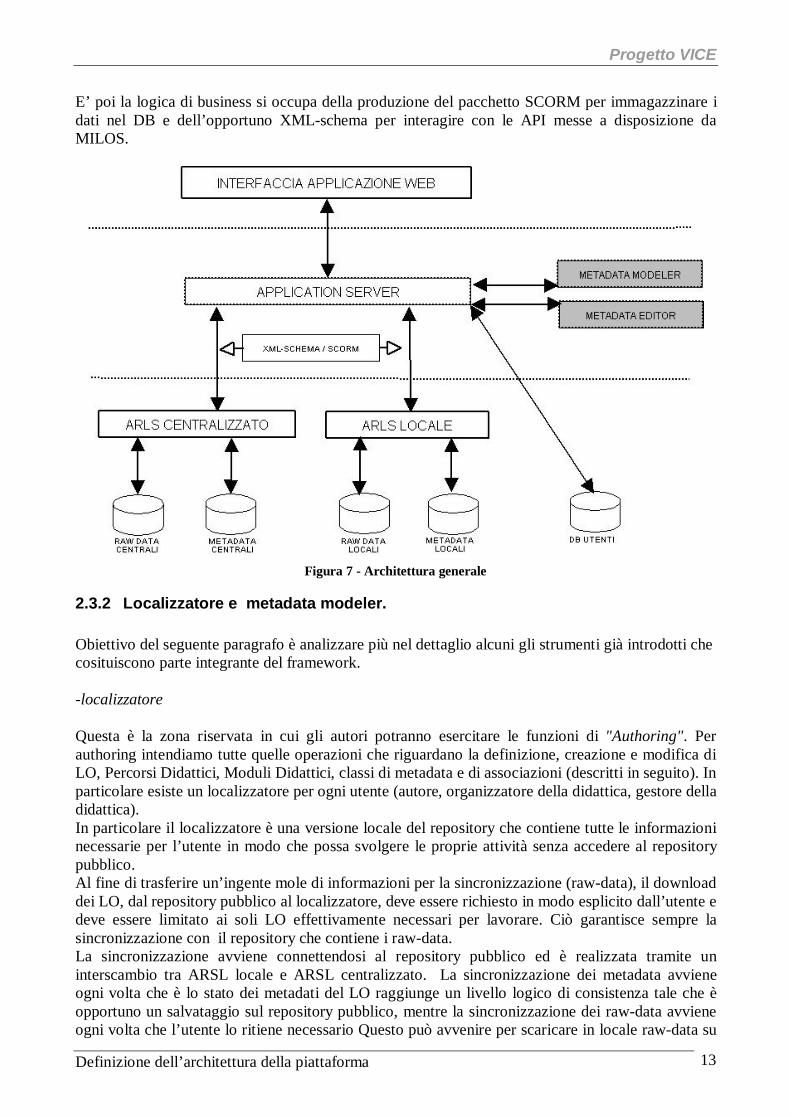
E’ poi la logica di business si occupa della produzione del pacchetto SCORM per immagazzinare i dati nel DB e dell’opportuno XML-schema per interagire con le API messe a disposizione da MILOS.
Figura 7 - Architettura generale
2.3.2 Localizzatore e metadata modeler. Obiettivo del seguente paragrafo è analizzare più nel dettaglio alcuni gli strumenti già introdotti che cosituiscono parte integrante del framework. -localizzatore
Questa è la zona riservata in cui gli autori potranno esercitare le funzioni di "Authoring". Per authoring intendiamo tutte quelle operazioni che riguardano la definizione, creazione e modifica di LO, Percorsi Didattici, Moduli Didattici, classi di metadata e di associazioni (descritti in seguito). In particolare esiste un localizzatore per ogni utente (autore, organizzatore della didattica, gestore della didattica). In particolare il localizzatore è una versione locale del repository che contiene tutte le informazioni necessarie per l’utente in modo che possa svolgere le proprie attività senza accedere al repository pubblico. Al fine di trasferire un’ingente mole di informazioni per la sincronizzazione (raw-data), il download dei LO, dal repository pubblico al localizzatore, deve essere richiesto in modo esplicito dall’utente e deve essere limitato ai soli LO effettivamente necessari per lavorare. Ciò garantisce sempre la sincronizzazione con il repository che contiene i raw-data. La sincronizzazione avviene connettendosi al repository pubblico ed è realizzata tramite un interscambio tra ARSL locale e ARSL centralizzato. La sincronizzazione dei metadata avviene ogni volta che è lo stato dei metadati del LO raggiunge un livello logico di consistenza tale che è opportuno un salvataggio sul repository pubblico, mentre la sincronizzazione dei raw-data avviene ogni volta che l’utente lo ritiene necessario Questo può avvenire per scaricare in locale raw-data su
Progetto VICE
Definizione dell’architettura della piattaforma 14
cui lavorare o per aggiungere al repository pubblico raw-data modificati o raw-data prodotti ex novo in locale. In questo modo è possibile garantire all’utente la possibilità di lavorare off-line senza la continua necessità di avere una connessione permanente con i dati centralizzati. A fronte di questi pro bisogna anche rimarcare l’unico importante contro che nasce da una gestione di questo tipo: la sincronizzazione di raw-data di grosse dimensioni potrebbe imporre vincoli sulla banda necessaria per l’interscambio di dati .
Figura 8 – Localizzatore
La gestione delle versioni avviene seguendo il sistema di miglioramenti progressivi. Ogni LO può essere “cambiato” modificando alcune parti o aggiungendo informazioni che lo rendono più completo. Questo privilegio è però riservato solamente all’autore del LO il quale può scegliere se modificare il LO esistente nel repository pubblico (raw-data e/o metadata) o estenderlo creando una nuova versione o variante. Le relazioni che sono istanziate nel riutilizzo del LO rappresentano un enorme vantaggio al momento della ricerca nel repository. Questi percorsi consentono, partendo da un LO, di risalire a quelli che gli sono collegati come significato e che sono stati sviluppati a partire da esso. In questo modo rimane traccia delle modifiche effettuate da altri autori e si può creare, in maniera naturale, una history di un LO basata sulla frequenza di utilizzo. A livello di metadata questi collegamenti sono realizzati tramite gli XLINK. Quando uno sviluppatore decide di modificare un LO per aggiungere o per modificare contenuti, può anche scegliere di non pubblicare una nuova versione come integrazione del lavoro già svolto ma di istanziare il tutto come un LO diverso, indipendente da quello di partenza. E’ il caso, in particolare, di LO i cui contenuti possono essere condivisi tra più argomenti con scopi didattici differenti. Ad esempio se un LO contiene informazioni sull’utilizzo degli algoritmi di ricerca potrebbe avere impieghi differenti a seconda che serva per la preparazione di un corso di informatica di base o per la preparazione di un corso di ricerca operativa: per completezza semantica non sarebbe corretto aggiungere le informazioni proprie della ricerca operativa al LO dichiarandone una nuova versione ma piuttosto creare ad hoc un nuovo LO con un utilizzo più specifico degli stessi argomenti.
Progetto VICE
Definizione dell’architettura della piattaforma 15
-metadata modeler Il metadata modeler permette al gestore della didattica di creare nuovi tipi di metadata o di associazione che sono poi opportunamente passati all’interfaccia di MILOS. In questo modo il middleware stesso si preoccupa di creare le API necessarie per la ricerca e per l’inserimento dei metadata e dei LO nel repository. Lo standard per i metadata è il 3 [3]. Pur utilizzando uno schema molto simile definiamo l’insieme dei metadati, a livello logico, in maniera dettagliata. È’ previsto un nucleo di metadata indispensabili e fondamentali di cui un LO non può fare a meno e, a corredo, una galassia di metadata facoltativi che, se istanziati, contribuiscono a tipizzare fortemente il LO in questione.
Figura 9 - Schema Metadata
I metadata facenti parte del core sono obbligatori, l’autore decide poi se vuole o meno arricchire il LO istanziando anche i metadata satellite o se preferisce lasciare che questo abbia un carattere più generale. Il metadata modeler si preoccupa di definire quale sia lo schema dei metadata mentre il metadata editor si pone come strumento a servizio dell’autore per editare i metadata già definiti in fase di modellazione. In generale i metadata del core contengono informazioni sulla tipologia di LO e sull’autore di quest’ultimo. In relazione alla tipizzazione, al versioning e alla creazione di varianti del LO vengono riempiti automaticamente i metadata del core che contengono le relative informazioni, compresi anche gli eventuali percorsi XLINK che puntano ai LO legati al corrente, per mezzo delle relazioni predefinite. La galassia di metadata satellite resta a disposizione dell’autore se questi dovesse manifestare l’intenzione di tipizzare fortemente il LO rendendolo meno generale. Per definire i metadata attraverso il modeler bisogna interagire con MILOS fornendo un XML-schema che viene interpretato dal middleware e che crea le API e i web-services necessari per l’interazione. Lo standard 3 offre già di per sè una forte categorizzazione dei metadata in base alle loro funzionalità e ai loro scopi. In particolare i metadata risultano suddivisi in alcune categorie principali.
Progetto VICE
Definizione dell’architettura della piattaforma 16
• general. Informazioni generali riguardanti il LO nella sua visione più generale. In questa categoria troviamo ad esempio un identificatore univoco del LO, un titolo, una tipologia di catalogo con il rispettivo inquadramento, il linguaggio in cui è scritto, alcune parole chiave, una breve descrizione, l’area semantica a cui fa riferimento, indicazioni sulla sua sottostruttura e sul suo livello di aggregazione in riferimento a strutture più semplici e non da ultimo le informazioni sull’autore.
• lyfecycle.
Informazioni generali sulla storia del LO, sul suo stato corrente e sulle eventuali entità che hanno interagito con esso portando ad alcune modifiche. Nel dettaglio troviamo ad esempio il numero di versione, lo stato di completamento e i contributi allo sviluppo.
• meta-metadata.
Informazioni che descrivono il record del metadata stesso. Troviamo informazioni su chi ha creato o modificato i metadata, su quali metadata sono stati istanziati, sul linguaggio in cui metadata stessi sono scritti e un identificatore che identifica univocamente il record di metadata.
• technical.
Informazioni che descrivono i requisiti e le caratteristiche tecniche del LO. Contengono dati che riguardano il formato del LO, la sua dimensione, la sua localizzazione (URI), i prerequisiti tecnici per la fruizione, le note per una corretta visualizzazione e la durata temporale della fruizione prevista in fase di creazione.
• educational.
Questa categoria descrive il LO in termini pedagogici/didattici relativi all’apprendimento. Troviamo ad esempio informazioni relative al tipo di interattività richiesta al fruitore, al tipo di risorsa di apprendimento (lezione, esercitazione, esperimento, etc.), alla densità semantica, all’uso tipico previsto per l’utente finale, al contesto, alla fascia di età di targeting, alla difficoltà, al tempo medio di apprendimento e al linguaggio di esposizione.
• rights.
Vengono descritti i diritti di utilizzo e di proprietà relativi al LO. Esistono, per esempio, metadata che descrivono il costo di utilizzo del LO, le restrizioni imposte sui contenuti dal creatore e i commenti dell’autore sulle condizioni di utilizzo (License).
• relation.
In questa categoria vengono descritte le eventuali relazioni di che un LO ha con altri LO. Il 3, utilizzando 52lin Core, offre già alcuni tipi di relazioni predefinite come ad esempio is part of oppure is instance of. In particolare nei metadata possiamo indicare il tipo di relazione, la risorsa a cui fa riferimento e una descrizione del legame.
• annotation.
Contiene annotazioni sulla creazione del LO e eventuali commenti al LO e allo sviluppo delle funzionalità per cui è preposto.
• classification.
Questa categoria descrive un possibile inquadramento del LO in sistemi di classificazione predefiniti. Contiene ad esempio informazioni sulle finalità di sviluppo del LO e su un eventuale classificazione tassonomica di questo.
Progetto VICE
Definizione dell’architettura della piattaforma 17
L’insieme dei metadata forniti dal 3 è molto diversificata e particolareggiata. Basando il modello di metadata su quello già fornito dalla IEEE possiamo creare un modello che ricalchi fedelmente quello riportato sopra definendo in maniera precisa quali metadata devono, per loro natura, far parte del core e quali appartengono invece alla galassia rimanente. Un percorso di questo tipo ci porterà a definire, in un passo successivo, l’XML-schema che definisce il modello dei metadata e che, interpretato da MILOS, renderà possibile la creazione dei web-services per l’accesso al repository centralizzato. Per loro stessa natura i metadata del core rendono il LO il più generale possibile. In questa categoria troveremo quindi solo quelle informazioni che permettono di identificare univocamente un LO senza entrare nel dettaglio riguardo il suo utilizzo o le sue finalità. In particolare potremmo enumerare i metadata del core nella maniera seguente:
• identificatore univoco • dati dell’autore • data creazione • tipo di supporto • linguaggio dei testi • tipo di risorsa di apprendimento • tipo di relazioni e riferimento fisico
Gli altri metadata dello standard 3 sono comunque utili per aumentare il livello di dettaglio della descrizione del LO, fanno quindi parte della galassia dei metadata satellite e la loro istanziazione è a discrezione dell’autore. Esiste inoltre un insieme di metadata che sviluppano funzionalità utili per l’implementazione di differenti tipologie di accesso all’ applicazione, ad esempio la ricerca con l’utilizzo di agenti. Queste vengono definite in un documento XML-schema a parte e passate all’interfaccia di MILOS che creerà API e web-services su misura per la gestione.
2.4 Scenari di utilizzo Obiettivo del seguente paragrafo è sia descrivere le funzioni principali dell’applicazione sia evidenziare l’interazione tra i diversi moduli del sistema che concorrono alle stesse.
Progetto VICE
Definizione dell’architettura della piattaforma 18
L’autore: Creazione di un nuovo LO.
Figura 10 - Creazione di un nuovo LO
Lo scenario modella la possibilità per l’autore di creare un nuovo LO e di renderlo disponibile nel repository pubblico (Figura 10). Sequenza di operazioni:
1. L’autore esegue l’upload del materiale didattico (raw-data) dal proprio PC al repository locale (localizzatore) .
2. L’autore avvia il metadata editor. 3. L’autore seleziona i raw-data a cui associare i metedata . L’operazione è opzionale e non
viene eseguita nel caso il nuovo LO non preveda raw-data associati. 4. I raw-data vengono caricati nel metadata editor. In particolare vengono caricati sono i
riferimenti ai raw-data. 5. L’autore edita i metadata e li associa ai raw-data creando, di fatto, il nuovo LO 6. Il nuovo LO è salvato nel repository locale 7. L’autore decide di esportare il nuovo LO nel repository pubblico. L’operazione è opzionale
in quanto non è detto che l’autore voglia rendere disponibile il nuovo LO agli altri utenti.
Progetto VICE
Definizione dell’architettura della piattaforma 19
L’autore: Modifica di un LO.
Figura 11 - Modifica di un LO
Lo scenario modella la possibilità per l’autore di modificare un LO, creando una nuova versione o facendone semplicemente l’update (Figura 11). Se l’autore non è il proprietario del LO l’operazione porterà alla creazione di un nuovo LO che sarà una variante del LO originario. Sequenza operazioni:
1. L’autore avvia il metadata editor. 2. L’utente seleziona dal repository locale il LO da modificare. 3. Il LO viene caricato nel metadata editor. 4. L’autore modifica i raw-data associati al LO. L’operazione consisterà nel fare l’upload nel
repository locale di nuovi raw-data e nell’associazione degli stessi al LO. 5. L’autore modifica i metadata associati al LO (ne associa di nuovi, modifica o elimina quelli
esistenti). 6. L’autore salva il nuovo LO decidendo se è una nuova versione, un update o una variante. 7. L’autore decide di esportare il nuovo LO nel repository pubblico. L’operazione è opzionale
in quanto non è detto che l’autore voglia rendere disponibile il nuovo LO agli altri utenti.
Progetto VICE
Definizione dell’architettura della piattaforma 20
L’autore: Creazione di un nuovo percorso didattico
Figura 12 - Creazione nuovo percorso
Lo scenario modella la possibilità per l’autore di creare un nuovo percorso didattico (Figura 12). Un percorso didattico è composto sia da LO sia da altri percorsi didattici organizzati in una struttura che ne definisce la sequenza di fruizione. Sequenza operazioni:
1. L’autore avvia il metadata editor. 2. L’utente seleziona dal repository locale i LO e i percorsi didattici da utilizzare per la
creazione del nuovo percorso. 3. I riferimenti ai LO e ai percorsi didattici selezionati vengono caricati nel metadata editor. 4. L’autore definisce la struttura del nuovo percorso didattico. 5. L’autore edita i metadata e li associa al nuovo percorso didattico. L’operazione presuppone
la selezione dei tipi di metadata da utilizzare per caratterizzare il percorso 6. L’autore salva il nuovo percorso didattico nel repository locale 7. L’autore sottopone il nuovo percorso didattico all’organizzatore della didattica che deciderà
se renderlo pubblico o meno. L’operazione è opzionale in quanto l’autore potrebbe non voler rendere pubblico il proprio percorso didattico.
Progetto VICE
Definizione dell’architettura della piattaforma 21
L’autore: Modifica di un percorso didattico
Figura 13 - Modifica di un percorso didattico
Lo scenario modella la possibilità per l’autore di modificare un proprio percorso didattico. La modifica comprende la modifica sia della struttura che dei metadata associati allo stesso (Figura 13) Sequenza operazioni:
1. L’autore avvia il “Metadata Editor” 2. L’autore seleziona dal repository locale il percorso da modificare. 3. Il riferimento al percorso viene caricato nel Metadata Editor 4. L’autore modifica la struttura del percorso. Ciò equivale a:
a. Riorganizzare la sequenza di fruizione dei LO e dei “sotto-percorsi” b. Inserire/Eliminare un LO c. Inserire/Eliminare un percorso didattico
5. L’autore modifica i metadata associati al percorso (ne associa di nuovi, modifica o elimina quelli esistenti).
6. L’autore salva il percorso didattico nel repository locale. 7. L’autore sottopone il nuovo percorso didattico all’organizzatore della didattica
Progetto VICE
Definizione dell’architettura della piattaforma 22
L’autore: Creazione di un’associazioni tra LO
Figura 14 - Creazione di un’associazione tra LO
Lo scenario modella la possibilità per l’autore di creare un’associazione tra due LO. L’associazione è creata da un autore nel suo localizzatore e può essere esportata nel repository pubblico. (Figura 14). Sequenza operazioni:
1. L’autore selezione il LO source dell’associazione 2. L’autore seleziona il tipo di associazione da istanziare 3. L’autore seleziona il LO target dell’associazione. La nuova associazione è salvata nel
repository locale 4. L’autore decide di esportare l’associazione nel repository pubblico insieme ai LO source e
target
Progetto VICE
Definizione dell’architettura della piattaforma 23
L’Organizzatore della didattica: Esportazione di un percorso didattico
Figura 15 - Esportazione di un percorso didattico
Lo scenario modella la possibilità per l’organizzatore della didattica di rendere pubblici i percorsi didattici da lui creati o che gli sono stati sottoposti per l’approvazione dai vari autori (Figura 15). Sequenza operazioni:
1. L’organizzatore della didattica sfoglia i percorsi presenti nel suo repository locale. 2. L’organizzatore della didattica seleziona i percorsi da rendere pubblici e li esporta nel
repository. L’Organizzatore della didattica: Creazione di un modulo didattico
Figura 16 – Creazione di un modulo didattico
Lo scenario modella la possibilità per l’organizzatore della didattica di creare un nuovo modulo didattico (Figura 15). Sequenza operazioni:
1. L’organizzatore della didattica seleziona i percorsi didattici da inserire nel modulo didattico 2. L’organizzatore della didattica inserisce le informazioni di base associate al modulo
didattico 3. L’organizzatore della didattica salva il modulo didattico nel proprio repository locale. 4. L’organizzatore della didattica rende pubblico il modulo didattico.
Progetto VICE
Definizione dell’architettura della piattaforma 24
Il Gestore della Didattica: Definizione di un nuovo tipo di metadata
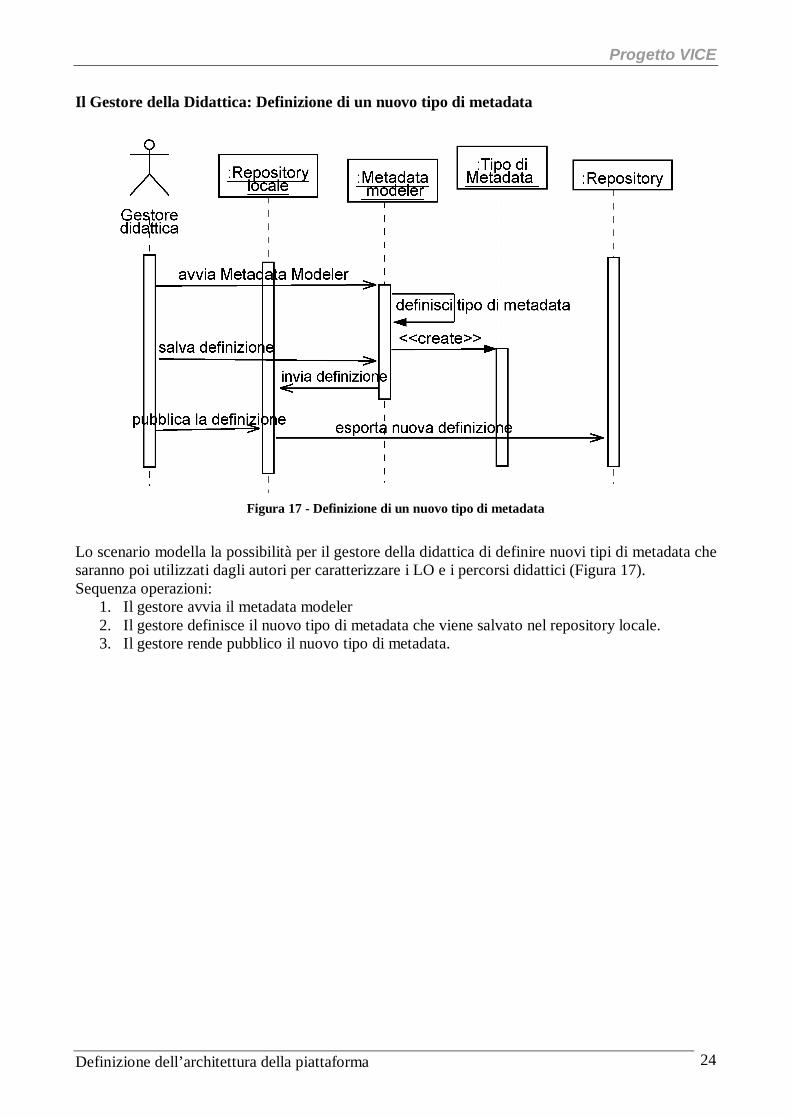
Figura 17 - Definizione di un nuovo tipo di metadata
Lo scenario modella la possibilità per il gestore della didattica di definire nuovi tipi di metadata che saranno poi utilizzati dagli autori per caratterizzare i LO e i percorsi didattici (Figura 17). Sequenza operazioni:
1. Il gestore avvia il metadata modeler 2. Il gestore definisce il nuovo tipo di metadata che viene salvato nel repository locale. 3. Il gestore rende pubblico il nuovo tipo di metadata.
Progetto VICE
Definizione dell’architettura della piattaforma 25
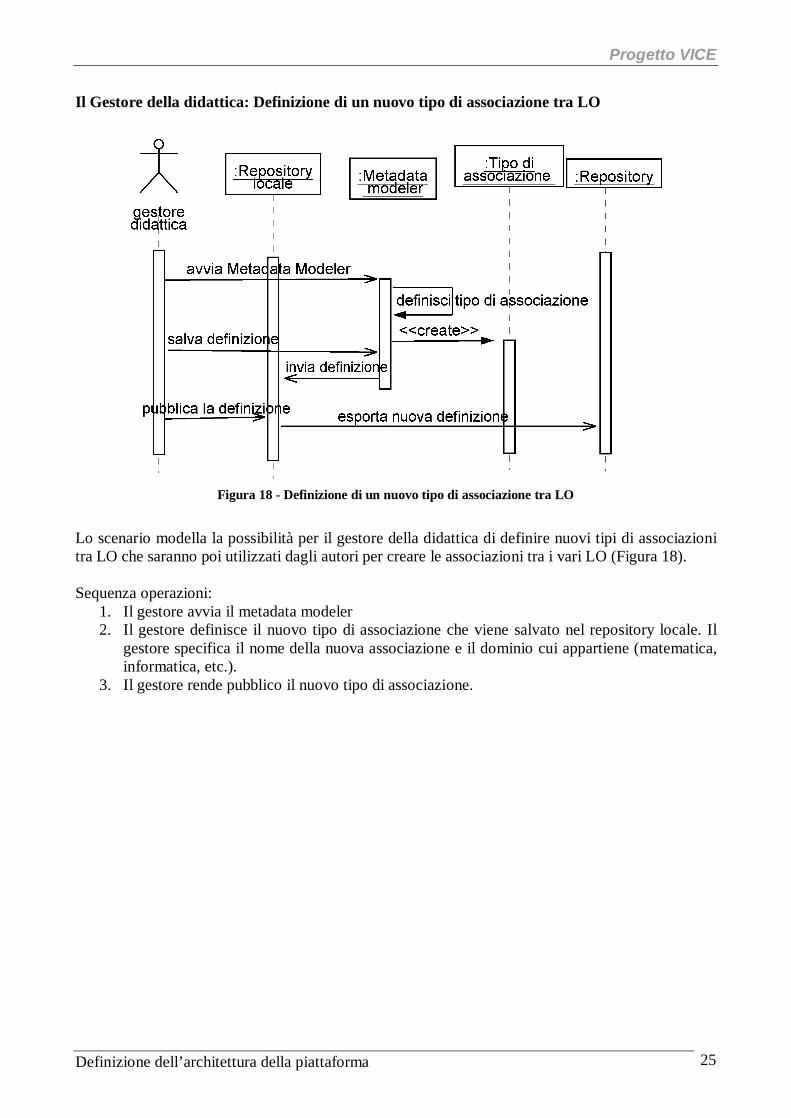
Il Gestore della didattica: Definizione di un nuovo tipo di associazione tra LO
Figura 18 - Definizione di un nuovo tipo di associazione tra LO
Lo scenario modella la possibilità per il gestore della didattica di definire nuovi tipi di associazioni tra LO che saranno poi utilizzati dagli autori per creare le associazioni tra i vari LO (Figura 18). Sequenza operazioni:
1. Il gestore avvia il metadata modeler 2. Il gestore definisce il nuovo tipo di associazione che viene salvato nel repository locale. Il
gestore specifica il nome della nuova associazione e il dominio cui appartiene (matematica, informatica, etc.).
3. Il gestore rende pubblico il nuovo tipo di associazione.
Progetto VICE
Definizione dell’architettura della piattaforma 26
3 Il repository classico Per il Repository di LO, da sviluppare nell’ambito del progetto, si sono individuate i seguenti requisiti essenziali:
• Flessibilità di strutturazione e rappresentazione di oggetti e metadati
• Scalabilità e distribuzione dell’architettura
• Modello operativo adeguato alle funzionalità richieste dalle altre componenti del progetto
La flessibilità è richiesta a due livelli: a livello degli oggetti di base che compongono i LO e a livello dei metadati dei LO. Gli oggetti di base, ad esempio. file PDF, video MPEG2, presentazioni PowerPoint, immagini JPEG, oggetti con sequenze temporali, tipo SMIL o MPEG4, etc. hanno ognuno un suo formato e strutturazione interna, e fanno riferimento ad ambienti/tool specifici di sviluppo e display. I metadati descrivono il contenuto degli oggetti basici, o raw-data, (ad esempio, MPEG7 per gli oggetti multimediali) e la loro valenza e composizione nell’ambito di un LO (metatdati SCORM). E’ chiaro che deve essere possibile rappresentare situazioni in cui un LO (descritto a livello di metadati) contiene diversi oggetti basici, e, viceversa, un oggetto basico è contenuto in diversi LO. La flessibilità richiesta per rappresentare e gestire metadati di LO si ottiene adottando XML come standard di specifica di metadati (come nel caso di MPEG7 e SCORM, descritti nel seguito).
I requisiti di scalabilità e distribuzione sono essenziali in relazione all’ambiente operativo per questo genere di applicazioni. Infatti, non si può realisticamente immaginare un unico Repository centralizzato per i LO,. Piuttosto, è realistica una situazione in cui diverse organizzazioni rendono disponibili, con opportuni controlli, i loro LO, ed in particolare i loro metadati su cui poter effettuare ricerche sul contenuto. Questo approccio permette un riuso dei LO posseduti, generando valore aggiunto. Nel nostro caso, pensiamo di ottenere questi scopi adottando una tecnologia basata su Web Services. Il modello operativo richiesto per un Repository di LO ha requisiti specifici che risultano diversi da quelli di un DBMS classico. Abbiamo identificato i seguenti requisiti specifici:
• Deve essere possibile inserire metadati di LO nuovi e diversi senza l’intervento preventivo di un amministratore, come nel caso dei DBMS;
• Deve essere molto efficiente nell’accesso, in lettura, ai metadati rappresentati in XML, usando linguaggi standard quali XPath [13] e XQuery [14]. Le interfacce XML ai database relazionali sono particolarmente inefficienti per oggetti complessi XML, in quanto richiedono un grande numero di operazioni di Join.
• Non è necessario che il Repository di LO supporti un meccanismo transazionale potente ma rigido come quello dei DBMS, piuttosto un meccanismo più semplice (tipo check-out e check-in) per controllare che sta lavorando sui metadati di un LO.
• Deve essere molto efficiente anche per le operazioni di inserimento di nuovi LO (ad esempio, operazioni di bulk import, nel caso una organizzazione acquisti grandi librerie di LO per iniziare nuovi fronti di attività)
• Deve essere possibile definire più versioni dei metadati di un LO. In questa sezione presentiamo l’architettura e le funzionalità di MILOS (MultImedia Learning Object Server) il sistema di Repository per il supporto alla memorizzazione e recupero dei LO che si basa sui requisiti di progetto precedentemente esposti. Nel primo anno di attività del progetto si è
Progetto VICE
Definizione dell’architettura della piattaforma 27
completato il disegno del sistema MILOS è si è iniziata la sua implementazione, specialmente per alcuni moduli critici di cui si necessità valutare quanto prima le funzionalità. MILOS è basato su un potente database/repository multimediale, in grado di garantire funzionalità di persistenza, ricerca e recupero di LO in XML (descritti usano lo schema del W3C). L’uso dello standard XML come formato di memorizzazione dei documenti ha fra i tanti vantaggi anche quello di permettere l’integrazione di formati preesistenti quali SCORM [15] e MPEG-7 [16] utili per il progetto. In particolare il formato SCORM sarà utilizzato per descrivere LO, mentre MPEG-7, per arricchire le componenti multimediali dei LO stessi. Infatti alcune parti dei LO possono essere oggetti di base vale a dire, immagini, file PDF, video, presentazioni Power Point, oggetti interattivi in MPEG-4, etc.
3.1 MILOS L’infrastruttura di MILOS è basata su un’architettura a tre livelli (Figura 19) composta da cinque componenti logici: metadata Modeler, Interface Logic, Adaptable Repository Service Logic, Storage Layer (composto dal Large Object Database, e dal metadata Database). La Figura mostra anche la relazione fra gli strumenti di creazione dei LO (metadata editors) e il Repository. Il metadata Modeler è uno strumento per la creazione di modelli di metadati per la creazione dei LO. La Interface Logic è formata da un certo numero di componenti in grado fornire varie interfacce di accesso ai LO agli utenti esterni attraverso la rete, utilizzando un semplice browser. Il Repository Service Logic gestisce l’accesso ai dati memorizzati nel Repository dei LO (metadata DB) e dei dati di base (Large Object DB). Di seguito diamo una descrizione più dettagliata di questi componenti. Si noti che tutti i componenti di MILOS comunicano attraverso il protocollo SOAP.
Figura 19 – L’architettura di MILOS
3.2 Metadata modeler È uno strumento utilizzato per definire nuovi modelli di metadati o arricchire modelli già esistenti Come esempio si supponga di voler creare uno schema di LO con nuove funzionalità ed ontologie, il risultato dei questa fase di progettazione sarà un insieme di uno o più schemi XML, che saranno in seguito utilizzati come parametro di ingresso per l’Adaptable Repository Service Logic. Quest’ultimo è in grado di adattare la sua interfaccia di accesso sulla base del nuovo schema di metadati.
Progetto VICE
Definizione dell’architettura della piattaforma 28
3.3 Interface logic La interface Logic comprende tutti i moduli relativi alle attività esportate all’esterno dal sistema. Tipicamente l’accesso sarà fornito attraverso un browser web. In particolare, i metadata Editor Tools permettono agli utenti di editare o modificare manualmente i metadati associati ai LO. In teoria esiste un metadata editor per ogni schema di metadati. In pratica, un editor di metadati può essere programmato in modo da funzionare con più schemi di metadati definiti da un metamodello di metadati. Alcuni dei tipi di metadati possono essere generati automaticamente; è il caso ad esempio dei metadati multimediali, come il trascritto o le scene di un filmato. In questo caso un editor può essere utile per apportare delle correzioni. I Retrieval tools sono usati per cercare i LO. Varie funzionalità sono fornite da questa interfaccia: gli utenti possono ad esempio cercare del testo libero sul trascritto o sulle descrizioni associate ai LO, ricercare specifici campi di metadati, oppure eseguire ricerche per similarità sui contenuti multimediali, etc. Un esempio di metadata editor, sviluppato durante il progetto ECHO, un progetto europeo per la gestione di documenti storici Audio/Video, è mostrato in Figura 20. Un’importante caratteristica di questo editor è che il suo codice non è cablato su di un particolare insieme di attributi dei metadati. Infatti, l’editor di ECHO utilizza l’XML schema del modello dei metadati di ECHO come un file configurazione. Il vantaggio di tale scelta risiede nella possibilità di aggiungere o rimuovere dei campi secondo le esigenze degli utilizzatori del sistema ECHO. Questo è ottenuto dando all’editor la possibilità di riconoscere automaticamente un sottoinsieme di tipi predefiniti dagli schemi XML, come, stringhe, booleani, date, etc.
Figura 20 – L’editor del progetto ECHO
3.4 Adaptable Repository Service Logic (ARSL) Questo componente gestisce l’accesso alle basi di dati sottostanti: il LO database (che fornisce la persistenza dei LO) e il Large Object database (dove sono memorizzati tutti i dati di base dei LO).
Progetto VICE
Definizione dell’architettura della piattaforma 29
In particolare l’ARSL gestisce l’elaborazione delle query integrando e allineando le informazioni nei due database. Inoltre, esso esegue la riconciliazione dei dati recuperati gestendo il loro riordino. Quando un nuovo XML schema è introdotto, il sistema è in grado automaticamente di generare una nuova interfaccia di middlewere in grado di comunicare con l’editore e lo strumento di retrieval della Interface Logic. L’ARSL deve essere quindi in grado di tradurre le chiamate ai servizi esportati in opportune chiamate XQUERY. A questo scopo il progettista dello schema aggiungerà alcune informazioni nello schema XML (attraverso i campi xsd:annotation/appinfo degli schemi XML del W3C) che specificheranno quali campi dei metadati sono utili per la ricerca, se e come devono essere mappati con altri campi, se devono essere indicizzati da un motore di ricerca testuale, etc. Come semplice esempio si guardi il seguente frammento di un di un oggetto 3/SCORM in XML
<?xml version="1.0"?> <3 xmlns="http://www.imsglobal.org/xsd/imsmd_rootv1p2p1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.imsglobal.org/xsd/imsmd_rootv1p2p1 imsmd_rootv1p2p1.xsd"> <general> <title> <langstring>Vessel Aground Lighting</langstring> </title> <description> <langstring>Picture showing lighting requirments for inland vessel less than 50 meters in length in an aground condition.</langstring> </description> <keyword> <langstring>Vessel</langstring> </keyword> <keyword> <langstring>Lighting</langstring> </keyword> <keyword> <langstring>Aground</langstring> </keyword> </general> … </3> Vogliamo istruire l’ARSL sul fatto che il ad esempio il campo title è individuato all’interno dell’oggetto 3 con il seguente XPATH: 3/genaral/title/langstring e che sia identificabile anche come “Titolo” (in italiano quindi) e come “dc.creator.title” (come se fosse un campo doublin core). Vogliamo inoltre che tale campo sia indicizzato dal motore XML, in modo da aumentarne le prestazioni durante la ricerca esatta. Infine, vogliamo che il campo sia indicizzato dal motore di ricerca testuale. Per comunicare queste informazioni all’ARSL possiamo aggiungere un’annotazione di annotation/appinfo all’interno della definizione dello schema del tag title, così come segue: <?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified"> <xs:element name="langstring" type="xs:string"/> <xs:element name="3"> <xs:complexType> <xs:sequence> <xs:element name="general"> <xs:complexType> <xs:sequence> <xs:element name="title"> <xs:complexType> <xs:sequence> <xs:element name="langstring" type="xs:string">
Tutto ciò che è contenuto all’interno del tag <xsd:annotation> viene ignorato dai parser XML, ma può essere utilizzato da altre applicazioni esterne.
Il tag <xsd:documentation> viene utilizzato per introdurre dei commenti, in questo caso viene fornita una spiegazione del campo titolo (che potrebbe essere mostrato come tooltip text su una interfaccia di editing o navigazione). I tag <xsd:appinfo> sono utilizzati in generale da specifiche applicazioni, nel nostro caso vengono valutati dall’ARLS. Ad esempio il primo testo “ARSL: KEYWORDS: Titolo, dc.creator.title” dice all’ARLS che il campo title deve poter essere trovato anche come Titolo, title e dc.creator.title. Mentre il secondo testo “ARSL: FAST_INDEX” dice che il campo title deve essere indicizzato in modo da ottimizzare la ricerca. Ed infine il terzo “ARSL: TEXT_INDEX”, comunica all’ARLS di passare il contenuto del campo title al motore di ricerca testuale. Non tutti i campi, infatti, ha senso indicizzarli. Si noti che lo schema dà la possibilità all’ARSL di identificare il path completo per raggiungere il testo da indicizzare. Nel nostro esempio, infatti, il titolo vero e proprio non si trova esattamente all’interno del tag <title>, ma ad un livello più basso, vale a dire nel tag <langstring>.
L’ARSL fornirà quindi una interfaccia di ricerca in grado di permettere il recupero agevole dei campi così annotati. Nel nostro esempio ci potrà essere un servizio che esporta il seguente metodo:
findText(string MetadaType, string value, string field, string returnField); che permette di cercare all’interno documenti appartenenti al tipo di metadati MetadaType (in pratica istanze dello schema XML di nome MetadaType), il valore value, del campo e restituire returnField. Utilizzando sempre il nostro esempio:
findText(“3”,“Vessel”,“titolo” “titolo”) Verrebbe espanso nella seguente XQuery:
for $a in /3 where $a/general/title/langstring ~ Vessel return $a/general/title/langstring La query così generata restituirebbe il titolo completo “Vessel Aground Lighting”.
3.5 Metadata database Questa parte del sistema gestisce i LO (e i loro metadati) rappresentabili in XML. Il vantaggio di XML è di poter sfruttare un potente motore XML realizzato ex-novo, basato su tecniche per eseguire efficientemente interrogazioni XML secondo gli standard XPath e XQuery, in modo da aumentare le prestazioni durante la ricerca.
Progetto VICE
Definizione dell’architettura della piattaforma 31
Nello specifico, dato che i linguaggi di interrogazione per XML usano path-expressions, contenenti wildcards, ed operatori per navigare la struttura XML, si sono studiati metodi di accesso per supportare la valutazione efficiente di path-expressions e la navigazione nella struttura dei documenti XML. In particolare, si sono sviluppati due metodi di accesso:
• XML path index per supportare la valutazione di path-expressions
• XML tree signature, un metodo di accesso che permette la navigazione efficiente nella struttura XML e la verifica di inclusione di sotto-alberi.
La maggior parte dei linguaggi di interrogazione per XML usano i wildcards nelle path-expression, che tipicamente vengono valutate facendo uso di join di contenimento. Nella maggior parte dei casi, specialmente quando i path sono molto lunghi o gli elementi sono poco selettivi, questo modo di procedere è molto inefficiente. Nel tentativo di eludere l'inefficienza di questo approccio si è sperimentato un metodo alternativo che si basa su una tecnica usata in information retrieval per valutare interrogazioni con termini parzialmente specificati. Con questa tecnica è possibile processare path-expression contenenti wildcards in maniera efficiente, anche in presenza di path lunghi e elementi poco selettivi. Usando questa tecnica del lessico ruotato è possibile eseguire, senza l'uso di join di contenimento, query del tipo ABC, *BC, A*C, AB*, *B*, dove A, B, e C, sono path-expressions senza wildcard. Le query che non hanno uno dei precedenti patterns possono comunque essere processate facendo uso di join di contenimento. L'idea delle tree signature è quella di mantenere una rappresentazione compatta della struttura dei documenti XML in maniera tale da poter effettuare in maniera efficiente la navigazione ed il test di inclusione durante la valutazione delle query. Una signature è una lista di coppie. Ogni coppia mantiene il nome di un nodo e la posizione nell'ordinamento di visita posticipata del nodo stesso. La lista di coppie è invece ordinata secondo l'ordine ottenuto con la visita anticipata. Utilizzando questa codifica si possono facilmente implementare tutti gli assi previsti dal linguaggio XPath: Child, Descendant, Parent, Following, Preceeding, Following-sibling, e Preceeding-sibling.
3.6 Large Object database Questo repository contiene tutti dati (oggetti basici o raw-data) collegati a LO come, video, immagini, presentazioni, file pdf, etc., che sono creati da tool esterni al sistema VICE. Ad esempio una presentazione può essere stata creata utilizzando un programma come Power Point di Microsoft. Nel caso di documenti di tipo Mpeg-4, potranno essere messi a disposizione dei tool di editing specifici, in grado di gestire l’interattività dei documenti. Il Large Object Database può eseguire un’analisi degli oggetti inseriti durante la loro fase di ingestione. In questo modo possono essere generati dei metadati automaticamente senza nessun intervento da parte dell’utente. Ad esempio da un file pdf può essere estratto il testo, come pure un file di Power Point. Dagli oggetti multimediali possono essere estratte features per facilitarne la ricerca o la loro navigazione.
3.7 Descrizione Accesso al repository L’ISTI fornirà i servizi di accesso, ricerca e persistenza di documenti XML che rappresentano i LO di VICE. Il repository è in grado eventualmente di fornire la persistenza degli schemi stessi essendo quest’ultimi scritti in formato XML ossia secondo lo standard XML Schema del W3C. È importante notare che i livelli superiori al repostitory, come le interfacce di ricerca, gli editor, non accedono mai direttamente al XMLSE sottostante (il motore XML di basso livello che usa XXQuery); ma si collegano alla business logic (ARSL). Quest’ultimo, infatti, fornisce un accesso
Progetto VICE
Definizione dell’architettura della piattaforma 32
trasparente al repository XML dei LO e al large Object. Il vantaggio di utilizzare l’ARSL è che i livelli superiori non devono preoccuparsi di eseguire query nel linguaggio XXQuery. A questo scopo saranno disponibili servizi di ricerca più avanzati, realizzati ad-hoc secondo le esigenze dei servizi di interfaccia. XXQuery è un’estensione del linguaggio XQuery che supporta query con l’operatore similarità [12]. Metadate modeler e metadata editor Come detto il metadata modeler ha il compito di generare schemi XML dei LO (XSD) che vengono poi istanziati dal metadata editor. Il metadata editor sarà in grado di adattare la propria interfaccia sulla base dello schema generato dal metadata modeler. Si noti che l’editor non può essere sviluppato in modo da gestire qualsiasi tipo schema (l’editor in questo caso diventerebbe qualcosa tipo XMLSpy), ma da un sottoinsieme degli schemi possibili definiti da un meta-schema. Questa osservazione è valida anche per l’ARLS. Quindi la definizione di questo meta-schema è di fondamentale importanza per la determinazione delle funzionalità sia dell’editor sia dell’ARSL. L’editor di VICE sarà realizzato in modo da essere estendibile (con un meccanismo tipo “plug-in”) in modo che nuove funzionalità (associate per esempio a parti dello schema dei metadati) possano essere aggiunte senza modificare il programma principale. Ad esempio se nello schema dei metadati compaiono dei name space che si riferiscono allo schema MathML, le parti dei documenti XML scritti in MathML verranno generati con un plug-in simile ad equation editor (analogamente a come fa MS-Word). SOAP Per l’integrazione fra l’ARSL e i moduli soprastanti si utilizzeranno Web Services basati su SOAP. Il vantaggio principale di SOAP è sicuramente quello di garantire l’interoperabilità di applicazioni su piattaforme diverse. Tuttavia, vi sono altri vantaggi:
• Sfrutta tecnologie Web già consolidate: o XML: per esprimere le informazioni o HTTP: per trasportare le informazioni
• rimane indipendente dal protocollo di trasporto (ad esempio può funzionare via email, HTTPS, FTP, ecc.).
• Non ha problemi con i Firewall: o Messaggi testuali o semplifica l’analisi ed il monitoraggio del traffico in ingresso (utilizzo di porte
TCP/IP standard) o non sono necessarie configurazioni del firewall “rischiose”.
Integrazione con il Wizard Pedagogico Il Wizard Pedagogico si connette anch’esso all’ARSR per recuperare l’intero repository LO per poi utilizzarlo per creare le reti semantiche. Ingestione dei dati di base L’ingestione dei i dati di base attraverso l’ARLS avverrà utilizzando semplici meccanismi di Upload basati sul protocollo HTTP. Repository distribuiti e gestione delle versioni È importante per l’utente avere la possibilità di lavorare su di un proprio repository “locale”, e di sincronizzare di seguito i propri dati con quelli del repository centrale. In questo modo un utente è in grado di lavorare localmente senza dover essere connesso alla rete. Emerge quindi la necessità di fornire meccanismi di gestione delle versioni dei documenti creati. È importante distinguere due tipi di versioni:
Progetto VICE
Definizione dell’architettura della piattaforma 33
• la versione temporale; lo stesso LO può essere modificato più volte nel tempo, ma rimane concettualmente sempre lo stesso oggetto),
• la versione di tipo uso; lo stesso LO può avere più versioni. Ad esempio versioni in lingue diverse. Essere scritto in diversi formati, come video, o come slide power point, etc.
Per quanto riguarda la gestione delle versioni temporali, sono state prese in considerazione diverse soluzioni; la più realistica sembra essere quella di fornire meccanismi di tipo “check in/check out” tipo CVS. Al contrario, le versioni di tipo uso saranno gestite ad alto livello, definendo opportunamente i gli schemi dei metadati. La gestione delle versioni temporali si semplifica se si assume che esiste una corrispondenza biunivoca fra documenti XML e LO, vale a dire un LO è identificato nella sua interezza da un’istanza di un documento XML nel repository. Ogni LO (e quindi il suo corrispondente documento XML) può trovarsi in uno stato libero o bloccato. Quando è libero, un utente può estrarlo, copiarlo nel proprio repository e modificarlo, per tutto il tempo necessario (in modo connectionless). Gli altri utenti non sono abilitati a modificare i LO bloccati ma possono solo leggerli (accedendo quindi all’ultima versione modificata). Durante la fase di rilascio di un LO l’utente è abilitato ad aggiornarlo, o di rilasciarlo senza modifiche.
Note sul modello SCORM SCORM (Sharable Content Object Reference Model) [15] definisce il modello di aggregazione dei contenuti per la FAD e l'ambiente di run-time per i LO. SCORM è un insieme di specifiche adattate da molte fonti per fornire una suite completa di strumenti di e-Learning che permettono interoperabilità, accessibilità e riusabilità dei contenuti formativi basati su web. Il lavoro portato avanti dall’ADL Iniziative per sviluppare lo standard SCORM è anche un processo per coordinare diversi gruppi ed interessi. Questo modello di riferimento ha come obiettivo quello di coordinare le tecnologie emergenti con implementazioni commerciali e/o pubbliche. L'architettura di SCORM è composta da quattro elementi essenziali: 1 LO: la cellula minima della quale si compone un corso. Uno stesso LO: se compatibile con lo
standard SCORM, può essere utilizzato all'interno di corsi diversi (architettura modulare); 2 Learning Management System (LMS): il sistema di gestione del corso che ne consente la
fruizione; 3 Course Structure Format (CSF): file d'interscambio in grado di tradurre lo stesso corso in LMS
differenti; 4 Runtime, il sistema che avvia il corso, soddisfacendo le richieste dell'utente finale. Un LO è una risorsa didattica "modulare", una risorsa didattica che si può riusare senza la necessità di modificarne i componenti. Lo standard SCORM è stato elaborato per rendere generalmente riusabili i LO, sulla base dell'esplosione del World Wide Web. Con la certificazione SCORM, i LO possono essere usati in qualunque programma per il supporto alla didattica (Learning Management System) che sia costruita secondo il modello previsto dallo standard SCORM. Il modello SCORM prevede essenzialmente la separazione dei contenuti didattici dall'esecuzione dei sistemi di istruzione. I contenuti didattici sono incapsulati nei LO e resi reperibili universalmente sulla rete attraverso l'uso dei metadati. Note su MPEG-7 MPEG-7 (formalmente chiamato Multimedia Content Description Interface) [16] si pone nell'ottica di fornire strumenti e standard per la descrizione di dati di tipo multimediale (o AV: audio-video),
Progetto VICE
Definizione dell’architettura della piattaforma 34
non considerando la loro particolare tecnologia di memorizzazione e trasmissione, ma ponendosi come valido strumento per la gestione e interpretazione del contenuto informativo presente in essi. Con una espressione inglese si potrebbe dire che riguarda "bits about the bits", ossia dati riguardanti dati, che, con termine tecnico, si potrebbero descrivere come meta-dati. Attualmente sono già in uso meccanismi di questo tipo, tra questi possiamo ricordare i più importanti quali: SMPTE Metadata Dictionary, 52lin Core, EBU P/Meta, TV Anytime. Considerando un generico processo di "generazione" ed "utilizzo" di una descrizione di un documento (rappresentato dalla Figura 21) si nota come la sola area operativa dello standard sia la specifica della "Description" e non i processi che la utilizzano, che invece, secondo il gruppo MPEG, dovranno essere ambito di future ricerche e competizioni fra aziende diverse, in modo da fornire i risultati migliori.
Figura 21 - MPEG-7
MPEG-7 affronta quindi un problema ortogonale a quello riguardante la memorizzazione dei media. In altre parole, guardando da una prospettiva differente, mentre gli standard MPEG precedenti rendevano i contenuti disponibili, MPEG-7 rende facile il reperimento e gestione di essi. In sede di standard decisione fondamentale è stata quella di stabilire che le descrizioni dei documenti (N.B.: la loro forma "canonica") avvenga mediante documenti XML. Tali descrizioni però devono essere "aderenti" allo standard, ossia rispettare vincoli sulle descrizioni utilizzate, sulla loro struttura e cardinalità. Per fare ciò MPEG-7 standardizza (scopo fondamentale di questo standard) i cosiddetti "Descriptors" (D) e "Description Schemes" (DS), che non sono altro che le varie feature (le rappresentazioni di esse) che si possono utilizzare nelle generazione delle descrizioni XML. Stabilito che MPEG-7 utilizza D e DS per descrivere ogni tipo di media, si deve affrontare la modalità con la quale questi elementi vengono codificati. Poiché tale standard tende ad essere il più generico possibile, si è scelto di utilizzare come forma di codifica testuale "canonica" il linguaggio XML schema del W3C. Considerando infatti la popolarità sempre crescente dell'universo XML, il suo uso si pensa faciliterà l'interoperabilità tra le varie implementazioni di tale standard nel futuro. Gli elementi caratteristici di MPEG-7 sono quindi: • "Descriptors" (D): rappresentazione di "features", descrivendole in termini di sintassi e
semantica, descrivendo la relazione featureàvalore; • "Description Schemes" (DS): rappresentazione della struttura e della semantica delle sue
componenti, che possono essere sia D che DS; i vari DS sono, in poche parole, modelli dell'oggetto multimediale a cui si riferiscono e dell' "universo" che rappresentano, specificando il tipo dei D e DS che possono essere usati e le relazioni fra di essi;
• "Description Definition Language" (DDL): linguaggio che permette la creazione di nuovi DS e, possibilmente, D oltre all'estensione di DS già esistenti nello standard;
• Strumenti di sistema per il supporto di meccanismi come la sincronizzazione della descrizione con il media, meccanismi di trasmissione, rappresentazione codificata in forma testuale o binaria.
Progetto VICE
Definizione dell’architettura della piattaforma 35
4 Accesso navigazionale al repository In questo capitolo è descritto il repository come applicazione web. Per fare ciò è utilizzata la metodologia W2000, ciò a permesso di separare la descrizione delle informazioni (LO e i percorsi didattici) dalle modalità di accesso alle stesse.
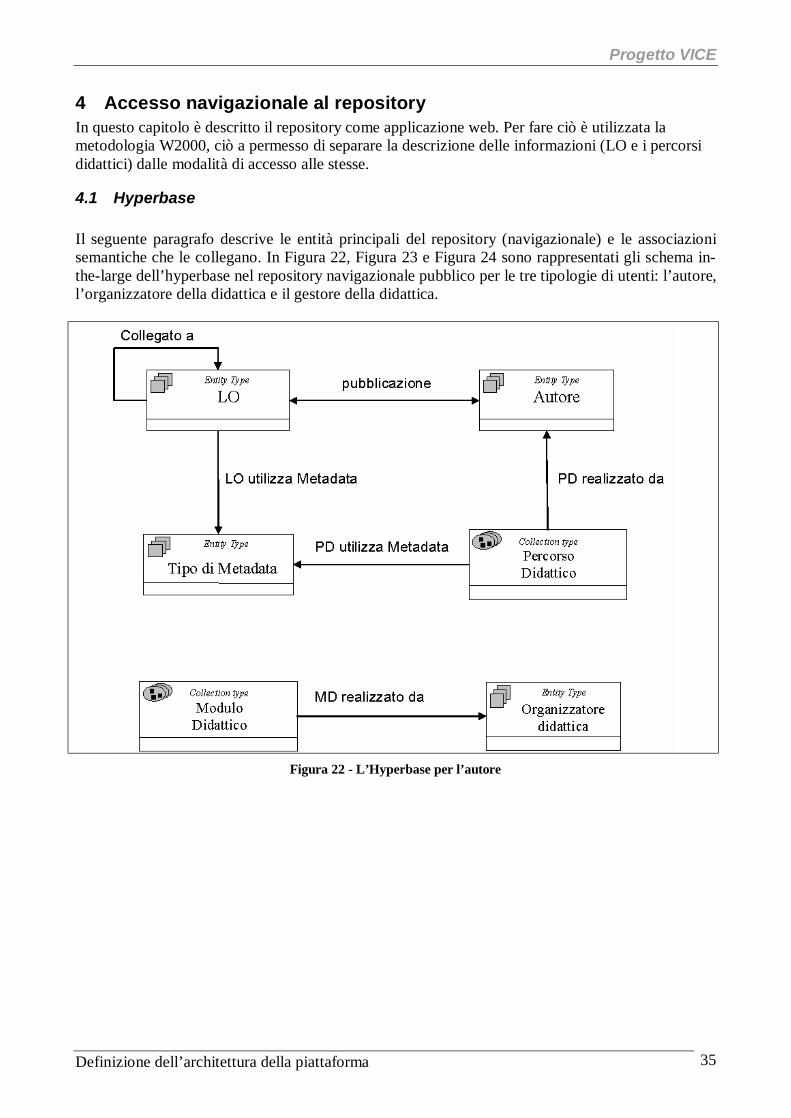
4.1 Hyperbase Il seguente paragrafo descrive le entità principali del repository (navigazionale) e le associazioni semantiche che le collegano. In Figura 22, Figura 23 e Figura 24 sono rappresentati gli schema in-the-large dell’hyperbase nel repository navigazionale pubblico per le tre tipologie di utenti: l’autore, l’organizzatore della didattica e il gestore della didattica.
Figura 22 - L’Hyperbase per l’autore
Progetto VICE
Definizione dell’architettura della piattaforma 36
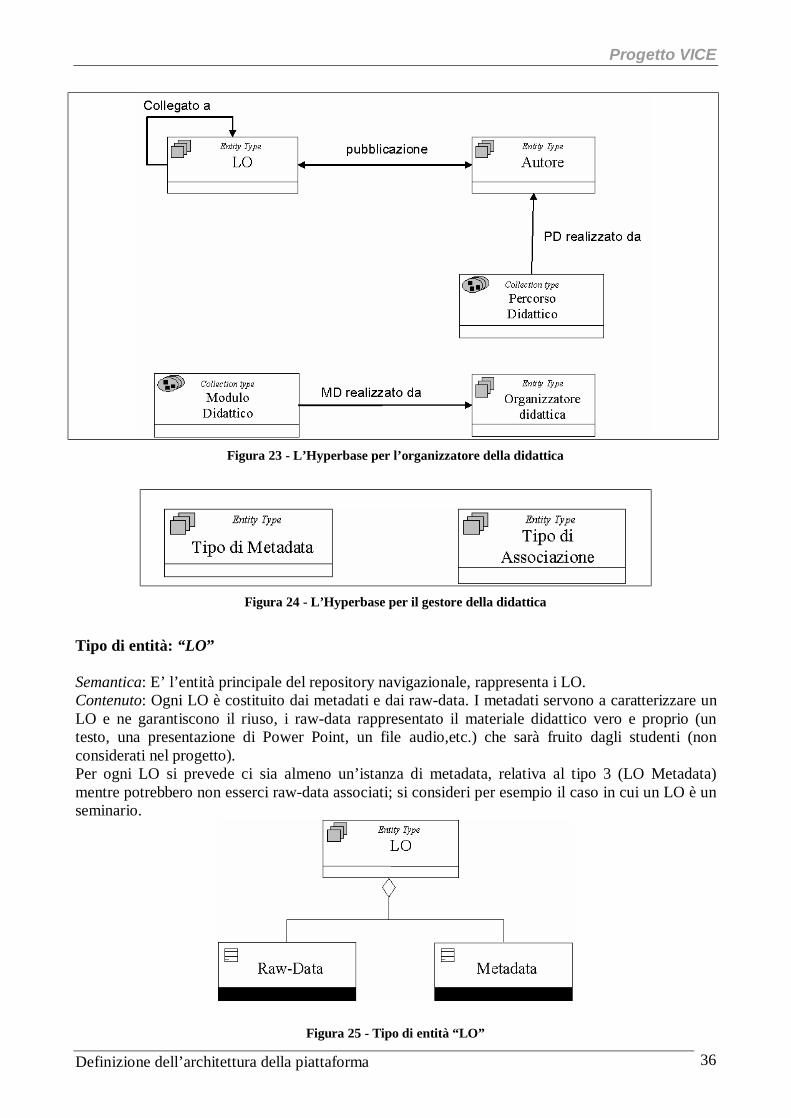
Figura 23 - L’Hyperbase per l’organizzatore della didattica
Figura 24 - L’Hyperbase per il gestore della didattica
Tipo di entità: “LO” Semantica: E’ l’entità principale del repository navigazionale, rappresenta i LO. Contenuto: Ogni LO è costituito dai metadati e dai raw-data. I metadati servono a caratterizzare un LO e ne garantiscono il riuso, i raw-data rappresentato il materiale didattico vero e proprio (un testo, una presentazione di Power Point, un file audio,etc.) che sarà fruito dagli studenti (non considerati nel progetto). Per ogni LO si prevede ci sia almeno un’istanza di metadata, relativa al tipo 3 (LO Metadata) mentre potrebbero non esserci raw-data associati; si consideri per esempio il caso in cui un LO è un seminario.
Figura 25 - Tipo di entità “LO”
Progetto VICE
Definizione dell’architettura della piattaforma 37
Tipo di entità: “Tipo di Metadata” Semantica: rappresentano i descrittori dei metadata che possono essere associati ai LO. Contenuto: contiene sia le informazioni generiche che descrivono il tipo di metadata (tipo, finalità, tipologia di utenti target) sia l’elenco gli attributi che dovranno essere “avvalorati” nel momento in cui il tipo di metadata è associato ad un LO. Quando un tipo di metadata è associato ad un LO dovrà essere specificato il valore di ogni attributo presente nella definizione, per ogni attributo viene quindi generata una coppia del tipo <attributo,valore>. Esempi di informazioni generiche che devono essere inserite nel momento in cui si istanzia un nuovo tipo di metadata sono:
• Tipo: determina il tipo di metadata (es. 3, pedagogico, per accessibilità). • Finalità: descrive le finalità del tipo di metadata (descrizione estesa del Tipo). • Tipologia utenti Target: se presente specifica le tipologie di utenti per i quali il tipo di
metadata è stato definito.
Origine: sono definiti dagli organizzatori della didattica Commento: La possibilità di definire nuovi tipi di metadata da utilizzare per caratterizzare i LO, garantisce il maggior riuso degli stessi e la scalabilità del sistema.
Figura 26 - Il tipo di entità “Tipo di metadata”
Tipo di Entità Astratta: “Operatore Professionista” Semantica: tipo di entità astratta che rappresenta gli utenti del sistema. L’entità si specializza nell’organizzatore della didattica e nell’autore. Contenuto: I component associati al tipo di entità sono:
• Anagrafica: riporta i dati anagrafici. • Didattica: riporta il curriculum, la carriera didattica, le pubblicazioni che
caratterizzano come professionista esperto di un certo settore. • Contatti: telefono, mail, sito web, etc.
Origine: le informazioni che sono state fornite al momento della richiesta di un account. Commento: La specializzazione dell’entità è legata alle diverse funzionalità e ai diversi diritti di accesso per l’Organizzatore della didattica e per l’Autore.
Progetto VICE
Definizione dell’architettura della piattaforma 38
Figura 27 - Il tipo di entità astratta “Operatore professionista”
Figura 28 - I tipi di entità “Autore” e “Organizzatore della didattica”
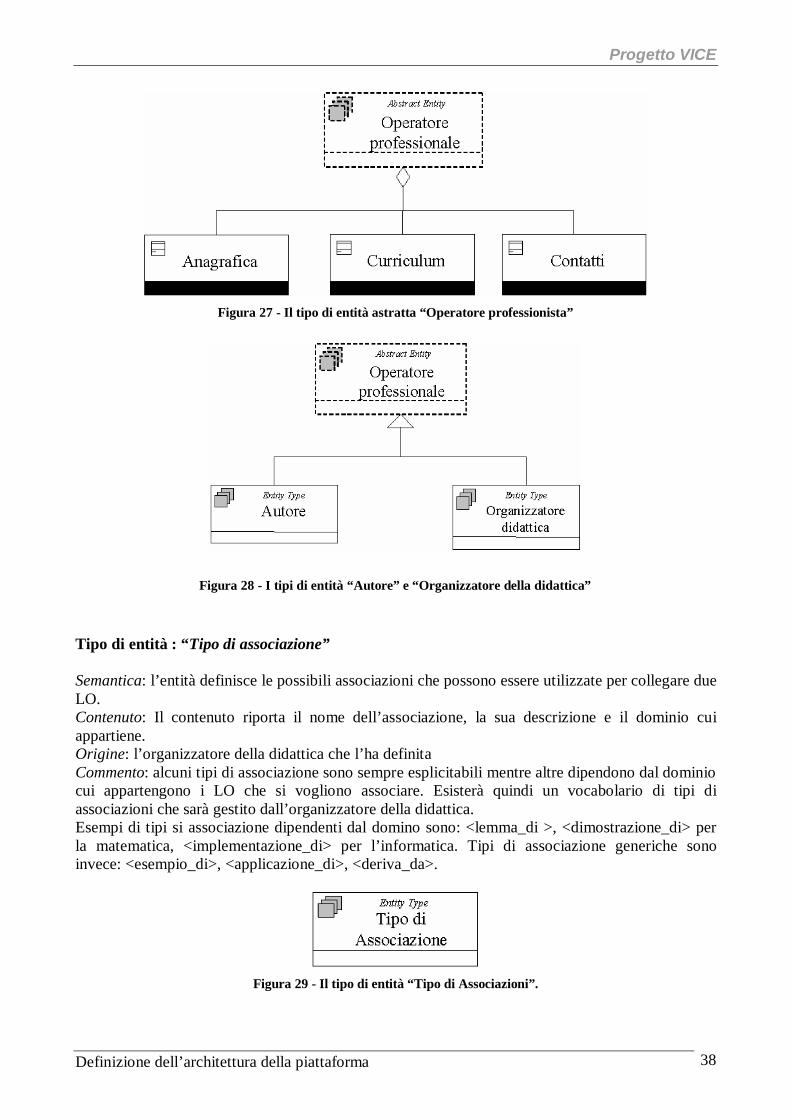
Tipo di entità : “Tipo di associazione” Semantica: l’entità definisce le possibili associazioni che possono essere utilizzate per collegare due LO. Contenuto: Il contenuto riporta il nome dell’associazione, la sua descrizione e il dominio cui appartiene. Origine: l’organizzatore della didattica che l’ha definita Commento: alcuni tipi di associazione sono sempre esplicitabili mentre altre dipendono dal dominio cui appartengono i LO che si vogliono associare. Esisterà quindi un vocabolario di tipi di associazioni che sarà gestito dall’organizzatore della didattica. Esempi di tipi si associazione dipendenti dal domino sono: <lemma_di >, <dimostrazione_di> per la matematica, <implementazione_di> per l’informatica. Tipi di associazione generiche sono invece: <esempio_di>, <applicazione_di>, <deriva_da>.
Figura 29 - Il tipo di entità “Tipo di Associazioni”.
Progetto VICE
Definizione dell’architettura della piattaforma 39
4.2 Le associazioni semantiche Nel seguente paragrafo sono descritte le associazioni semantiche tra le diverse entità dell’Hyperbase per le diverse tipologie di utenti. Associazione Semantica: “Pubblicazione” Tipo di entità Source: LO Tipo di entità Target: Autore Nomi diretti: “LO realizzato da autore”,”Autore di LO” Semantica: relazione che collega un LO con il proprio autore e viceversa. Un autore può creare più LO, mentre un LO è realizzato da un solo autore.
Figura 30 - L’associazione semantica “Pubblicazione”
Associazione Semantica: “Collegato a” Tipo di entità Source: LO Tipo di entità Target: LO Nomi diretti: collegato a Semantica: l’associazione permette di navigare da un LO verso altri LO. Le associazioni tra i LO sono definite dai vari autori. Commento: L’associazione avrà un tipo derivato dal vocabolario dei tipi di associazione che collega i LO di partenza a quello di arrivo. Ad esempio <corollario_di>
Figura 31 - L’associazione semantica “Collegato a”
Progetto VICE
Definizione dell’architettura della piattaforma 40
Associazione Semantica: “PD realizzato da” Tipo di entità Source: Percorso didattico Tipo di entità Target: Autore Nomi diretti: PD realizzato da Semantica: l’associazione permette di navigare da un Percorso Didattico verso l’autore che l’ha creato
Figura 32 - L’associazione semantica “PD realizzato da”
Associazione Semantica: “MD realizzato da” Tipo di entità Source: Modulo Didattico Tipo di entità Target: Organizzatore didattica Nomi diretti: MD realizzato da Semantica: l’associazione permette di navigare da un Percorso Didattico verso l’autore che l’ha creato
Figura 33 - L’associazione semantica “MD realizzato da”
Associazione Semantica: “LO utilizza Metadata” Tipo di entità Source: LO Tipo di entità Target: Tipo di Metadata Nomi diretti:LO utilizza Metadata Semantica: l’associazione permette di navigare da un LO verso le definizione dei tipi di matadata che possono essere utilizzati per caratterizzarlo o che già lo caratterizzano. Commento: Permette ad un autore di vedere la definizione del tipo di metadata da associare ad un LO per permettergli di utilizzarlo correttamente.
Figura 34 - L’associazione semantica “LO utilizza Metadata”
Progetto VICE
Definizione dell’architettura della piattaforma 41
Associazione Semantica: “PD utilizza Metadata” Tipo di entità Source: Percorso Didattico Tipo di entità Target: Tipo di Metadata Nomi diretti: PD utilizza Metadata Semantica: l’associazione permette di navigare da un Percorso Didattico verso le definizione dei tipi di matadata che possono essere utilizzati per caratterizzarlo o che già lo caratterizzano. Commento: Permette ad un autore di vedere la definizione del tipo di metadata da associare ad un percorso didattico per permettergli di utilizzarlo correttamente.
Figura 35 - L’associazione semantica “LO utilizza Metadata”
4.3 Il livello di accesso Nel seguente paragrafo sono descritte le principali collezioni che permettono di accedere ai LO e ai “Percorsi didattici” utilizzando il repository navigazionale. Oltre alle collezioni descritte nel paragrafo se ne potranno aggiungere altre definite nel corso del progetto. Un tipo particolare di collezione è il “Percorso didattico”, definito come collezione di LO e di altri percorsi didattici è a tutti gli effetti considerato come un nuovo tipo di LO (è stato infatti già considerato nell’Information Model), sarà infatti possibile associargli dei metadata che ne garantiscano il riuso. Tipo di collezione: “Percorso didattico” Accessibile a: Autore, Organizzatore della didattica Contenuto: I membri della collezione “Percorso Didattico” possono essere sia dei singoli LO sia altri percorsi didattici precedentemente creati. Navigazione: Il pattern navigazionale del percorso didattico è a “grafo incompleto” (Figura 37) dove ogni nodo del grafo è un LO o un altro percorso didattico. Gli archi invece definisco la sequenza di fruizione. A partire da ogni Lo è comunque sempre possibile navigare utilizzando le associazioni semantiche. Commento: Il percorso didattico è strettamente correlato al concetto di “corso”, un autore potrebbe infatti esportare il percorso didattico creando un corso da far fruire agli studenti.
Figura 36 - La collezione “Percorso didattico”
Progetto VICE
Definizione dell’architettura della piattaforma 42
Inizio Corso
Esame/fine corso
Percorso Z
Navigazionesemantica
Percorso X
Percorso Y
Figura 37 - Il pattern navigazionale del Percorso didattico
Tipo di collezione: “Modulo Didattico” Accessibile a: Autore, Organizzatore della didattica Contenuto: I membri della collezione “Modulo Didattico” sono i Percorsi Didattici Navigazione: Index più Guided Tour Commento: Creato da un organizzatore della didattica è accessibile anche ai diversi autori
Figura 38 - Tipo di Collezione “Modulo Didattico”
Progetto VICE
Definizione dell’architettura della piattaforma 43
Tipo di Collezione : “LO per autore” Accessibile a: Autore, Organizzatore della didattica Contenuto: I membri della collezione sono i LO creati dai vari autori Commento: Esisterà una collezione per ogni autore Collezione Container: “Tutti gli autori” Contenuto: I membri della collezione sono le varie istanze del tipo di collezione “LO per autore”
Figura 39 - Tipo di Collezione “LO per Autore”
Tipo di Collezione : “Percorsi Didattici per autore” Accessibile a: Autore, Organizzatore della didattica Contenuto: I membri della collezione sono i Percorsi Didattici creati dai vari autori Commento: Esisterà una collezione per ogni autore Collezione Container: “Tutti gli autori” Contenuto: I membri della collezione sono le varie istanze del tipo di collezione “Percorsi Didattici per autore”
Figura 40 - Tipo di Collezione “LO per Autore”
Progetto VICE
Definizione dell’architettura della piattaforma 44
Tipo di Collezione : “Percorsi per argomento” Accessibile a: Autore, Organizzatore della didattica Contenuto: I membri della collezione sono i vari Percorsi didattici creati dai vari autori Commento: La tipizzazione dei percorsi è legata ai metadata che gli sono stati associati in fase di creazione Collezione Container: “Tutti gli argomenti” Contenuto: I membri della collezione sono le varie istanze del tipo di collezione “Percorsi per argomento”
Figura 41 - Tipo di Collezione “Percorsi per Argomento”
Tipo di Collezione : “Search Collection” Accessibile a: Autore, Organizzatore della didattica Contenuto: I membri della collezione possono essere sia LO che percorsi didattici. Commento: i membri che compongono la collezione sono il risultato di ricerca sulla base di alcuni parametri inserite dall’utente. Un esempio di “Search collection” può essere l’insieme dei LO creati da “Paolo Paolini” il cui argomento è “Web Design” o “Usabilità Web” (Figura 43). La ricerca con parametri utilizza le modalità di ricerca classica e pedagogica, in entrambi i casi il risultato sarà una collezione di LO e/o percorsi.
Figura 42 - Tipo di Collezione “Search Collection”
Progetto VICE
Definizione dell’architettura della piattaforma 45
Figura 43 - Esempio di search collection
Tipo di Collezione : “BAG” Accessibile a: Autore, Organizzatore della didattica Contenuto: I membri della collezione sono LO e/o Percorsi didattici che un utente di cui un utente vuole tenere traccia, per elaborarli in un secondo momento Commento: Ad ogni utente ha a disposizione più BAG che gli consentono di suddividere i LO e i percorsi didattici in base a specifici criteri di scelta. Tutte le BAG dell’utente vengono poi importate nel localizzatore.
Figura 44 - Tipo di collezione “BAG”
Progetto VICE
Definizione dell’architettura della piattaforma 46
Collezione Singola: “I tipi di Metadata” Accessibile a: Gestore della didattica Contenuto: I membri della collezione sono i vari tipi di Metadata definiti dal gestore della didattica
Figura 45 - Tipo di collezione “I tipi di Metadata”
Collezione Singola: “I tipi di Associazione” Accessibile a: Gestore della didattica Contenuto: I membri della collezione sono i vari tipi di Associazione definiti dal gestore della didattica
Figura 46 - Tipo di collezione “I tipi di Associazione”
4.4 Hyperbase nel localizzatore L’Hyperbase del localizzatore relativo ai vari utenti è analogo a quello del repository pubblico. La differenza sostanziale è che nel localizzatore dei vari utenti vi sono solo le entità create dall’autore stesso o importate dal repository pubblico. Rispetto al repository pubblico solo differenti anche le strutture di accesso ai LO, ai Percorsi didattici, ai Moduli didattici. Esisteranno infatti, oltre a tutte le collezioni già descritte, anche le collezioni del tipo “I miei LO” o “I miei percorsi didattici” che non sono previsti nel repository pubblico.
Progetto VICE
Definizione dell’architettura della piattaforma 47
Collezione Singola: “I miei LO” Contenuto: I membri della collezione sono i LO dell’utente del localizzatore.
Figura 47 - La collezione singola “I miei LO”
Collezione Singola: “I miei Percorsi Didattici” Contenuto: I membri della collezione sono i Percorsi Didattici dell’utente del localizzatore.
Figura 48 - La collezione singola “I miei Percorsi Didattici”
Progetto VICE
Definizione dell’architettura della piattaforma 48
5 Il wizard pedagogico
5.1 Informazioni pedagogiche (produttore) L’unità operativa IMATI di Genova propone il seguente contributo riguardo alle informazioni pedagogiche : Descrizione Classificazione per tipologia educativa Goal cognitivi Prerequisiti Modalità di comunicazione Livello di difficoltà Formato Tempi Classificazioni contenutistiche (riferite eventualmente a più di un corpo di conoscenza) (Livello di aggregazione)
5.2 Informazioni pedagogiche di supporto alla scelta e individuazione di materiale Tipo Sottotipo Illustrativo • Presentazioni (es. illustrazione delle diverse topologie di rete)
• Esempi di casi • Esempi di problemi (es. illustrazione della soluzione che si vuole per un problema e analisi
dei passi necessari a raggiungerla) • Simulazioni (p.e. una simulazione atta ad illustrare le conseguenze di una decisione sbagliata
nella scelta della velocità di un mezzo) • …………………
Attivo • Testi di esercizi di tipo drill & practice ( a risposta univoca) • Testi di problemi • Testi di proposte di progetti • Proposte di discussione/riflessione • ……………….
Verificativo • Batterie di test da svolgersi manualmente • Test elettronici di auto-valutazione • Test elettronici per la valutazione da parte del docente • Questionari • …………….
Ricettivo
• Comportamentista • Cognitivista
Esplorativo
• Ambienti di simulazione • Micromondi • Ambienti di lavoro (workbench) • Ambienti per l’analisi di casi di studio • Analisi di casi • Giochi di ruolo • Risoluzione di problemi aperti • ……………….
Supporto (materiale usato in moduli didattici)
• Glossari • Bibliografie ragionate • Guidelines • Casi non commentati • Listati di programma • Tabelle di dati • ……………..
Progetto VICE
Definizione dell’architettura della piattaforma 49
Tipi
• I moduli di cui lo studente dovrebbe aver già fruito • I moduli valutativi che dovrebbero essere stati ‘superati’ • Indicazione sui goal cognitivi già raggiunti, relativi al dominio
Goal cognitivo Verbi Possibili attività/materiali
Conoscere (intesa nel senso di riconoscere, ricordare informazione)
Valutare (giudicare sulla base di opinioni personali, producendo un nuovo prodotto con un obiettivo)
Confrontare, concludere, decidere ….
Casi di studio
Critiche
Progetti
Confronti
……………
Progetto VICE
Definizione dell’architettura della piattaforma 50
5.3 Osservazioni sugli aiuti per costruire un percorso in base ad un approccio educativo
Si potrebbero proporre al docente in fase di consultazione alcuni template “generalizzati” di impostazione di percorsi didattici secondo le principali teorie di apprendimento In questo modo il docente potrebbe scegliere la struttura generale che vuole seguire nell’impostazione del percorso didattico (in realtà poi questa scelta non lo vincola in nessun modo, ma gli fornisce soltanto dei suggerimenti su come procedere) e una volta fissata questa il wizard provvederà, richiedendo opportune informazioni al docente, ad identificare i “contenuti”. Soltanto in seguito alla specificazione di adeguate informazioni pedagogiche da parte del docente il sistema provvederà a presentargli i LO con cui creare il percorso e a suggerire, in relazione della strategia scelta, l’ordine in cui presentarli. L’aspetto finale potrebbe essere, per questa proposta, la costruzione di un percorso didattico che si realizzi attraverso fasi successive “suggerite” e guidate dal wizard (pensiamo a titolo di esempio alla creazione di un grafico con Excel). Passo 1: il wizard propone al docente di scegliere l’impostazione didattica favorita che meglio aderisce alla posizione adottata dal docente durante la sua pratica didattica, ad esempio:
E’ prevista a questo livello la possibilità di approfondire il significato conferito dal wizard ai termini precedenti, al fine di permettere una scelta più consapevole al docente: ad esempio cliccando su un pulsante specificatamente preposto a questa funzione, il sistema presenterà una breve descrizione del termine e la struttura generale che verrà suggerita nei singoli casi per la creazione del percorso didattico. Passo 2: una volta scelta la struttura di base, verrà data la possibilità al docente di scegliere tra gli argomenti a disposizione quello su cui sarà incentrato il percorso didattico; tale scelta potrà essere effettuata tramite una sorta di indice dei contenuti (corpo di conoscenza) precostituito secondo le regole generali adottate per la classificazione dei contenuti all’interno del repository. Passo 3: per rispondere nel modo più efficiente possibile alle richieste del docente il sistema proporrà una serie di opzioni di selezione collegate alle principali informazioni di carattere pedagogico di cui sono stati dotati gli oggetti contenuti nel repository. Questa fase permette di effettuare un raffinamento automatico degli oggetti che verranno presentati e tra i quali il docente potrà scegliere autonomamente secondo ulteriori criteri soggettivi. Passo 4: infine, rispettando la struttura di base selezionata nel Passo 1, verranno proposti al docente gli oggetti presenti nel repository rispondenti alle specifiche impostate dal docente nelle fasi precedenti e significativi in relazione al particolare segmento di percorso che si sta completando (ad esempio, nella fase di presentazione non verranno proposti oggetti rivolti all’aspetto valutativo del percorso didattico). Sottolineiamo che l’adesione ad un determinato approccio non vincola in nessun modo il docente a rispettarne rigidamente la struttura: attraverso opportune azioni successive al completamento della procedura guidata, egli potrà quindi inserire nel percorso singoli LO che riterrà significativi per l’attività che andrà a svolgere, indipendentemente dalle specifiche strutturali del “template” selezionato (per collegarci all’esempio precedente, potrà inserire comunque materiale valutativo nella fase espositiva).
5.4 Osservazioni su altri tipi di aiuto Ipotizziamo invece che il docente non stia necessariamente costruendo un ben determinato percorso didattico, ma che stia, in via più generale, selezionando materiale di interesse per un successivo utilizzo.
Progetto VICE
Definizione dell’architettura della piattaforma 51
Ci sembra dunque significativo in questo contesto prevedere una funzionalità per dare la possibilità al docente di catalogare in modo arbitrario e autonomo il materiale scelto, senza doverlo obbligare ad aderire alla visione degli sviluppatori (che si rispecchia nelle scelte di classificazione presenti all’interno del repository) e quindi senza doversi adeguare a classificazioni esistenti. In sintesi proponiamo la creazione da parte del docente di una classificazione dinamica propria, indipendente dalle altre classificazioni adottate dal sistema. Prevediamo dunque che venga data la possibilità di creare all’interno del sistema delle voci personali, a cui associare di volta in volta gli oggetti selezionati tra quelli proposti dal sistema in fase di ricerca.
Progetto VICE
Definizione dell’architettura della piattaforma 52
6 Il modulo ontologico La sottoattività legata agli aspetti ontologici del repository si pone l’obiettivo di progettare la componente semantica del progetto VICE e coordinare le attività delle unità collegate nella definizione delle ontologie di riferimento. Lo scenario è quello del semantic web ed è incentrato sull’idea di affiancare agli oggetti nel repository una opportuna rappresentazione degli stessi tramite metadati a cui fornire una semantica formale. In questo modo sarà possibile rendere l’informazione circa la natura e le caratteristiche dei LO fruibile non solo da parte degli utenti umani, ma anche da parte di agenti artificiali, che erogano servizi di supporto quali:
• Ricerca semantica del repository • Verifica di correttezza degli interventi formativi • Assistenza alla costruzione interattiva di corsi • Sequenziazione automatica dei LO
6.1 Le ontologie ed il semantic web La sfida del semantic web è la costruzione di sistemi in grado di gestire documenti comprensibili sia all’utente umano che ad agenti artificiali. Il WEB è nato come strumento di condivisione di risorse documentali, nella sua prima accezione di trattava di una grande quantità di documenti accessibili tramite rete, questi documenti erano completamente statici, nel senso che non erano in alcun modo in grado di adattarsi a specifiche richieste dell’utente. Il secondo passo evolutivo della rete è stata l’introduzione di contenuti dinamici, in grado di rispondere diversamente a diverse richieste dell’utente e di comporre contenuti personalizzati a partire da elementi passivi semplici. In questo quadro si inseriscono i vari standard e le varie tecnologie per l’elaborazione “server side”, come JSP, ASP e Servlet, che permettono di generare contenuti dinamici da fruire tramite la rete, costituendo oggetti analoghi ai Learning Object generativi descritti da Wiley [38]. Una ulteriore svolta nell’organizzazione della rete è nata con i WebService ed è tuttora in atto; lo scenario futuribile è di un web semantico, in cui i documenti saranno ugualmente fruibili da utenti umani ed artificiali [41]. Agenti artificiali potranno interpretare documenti scritti o indicizzati attraverso formalismi e linguaggi specifici per la rappresentazione della conoscenza. E’ chiaro quindi che la chiave di volta del web semantico è l’insieme di formalismi in grado di collegare un livello sintattico utilizzabile in rete con una semantica sufficientemente ricca per un ragionamento automatico di effettiva utilità, ma contemporaneamente di complessità sufficientemente controllata da rendere la soluzione scalabile alle dimensioni del web come oggi lo conosciamo.
6.2 Una struttura per il semantic web Il passaggio dalla semplice sintassi dei documenti in rete alla rappresentazione formale dei loro contenuti è incentrato su quattro concetti fondamentali:
• Documento • Metadato • Modello • Ontologia
Al livello più basso troviamo il singolo documento, che costituisce la risorsa ultima a cui accedere, al livello di documento non è a priori possibile introdurre alcuna restrizione di tipo o formato, dato che non è immaginabile vincolare l’intera rete ad adottare un qualsivoglia standard. In generale un documento potrà essere un file XML, una pagina HTML, un archivio ZIP scaricabile dalla rete, un’applicazione o qualsiasi altra risorsa.
Progetto VICE
Definizione dell’architettura della piattaforma 53
Ogni documento contiene informazione in un formato per lo più incomprensibile ad un agente artificiale, descrizioni e spiegazioni in linguaggio naturale, e contenuti multimediali. Si possono immaginare almeno due approcci differenti alla rappresentazione semantica delle entità:
6.2.1 l’approccio dei metadati Il primo approccio consiste nell’introdurre dei “ganci” semantici all’interno di ogni documento, ad esempio tramite opportuni tag XML. Per permettere ad un sistema artificiale di gestire in maniera coerente la risorsa è quindi necessario introdurre un certo numero di informazioni standard, interpretabili in maniera univoca. Queste informazioni sono dei metadati, cioè dei dati che descrivono i dati veri e propri contenuti nel documento. Restringendo il campo di interesse ai Learning Object, lo standard 3 [60], basato su XML, definisce un insieme di metadati caratteristici di ogni LO utilizzabili per la ricerca automatica delle risorse e per una loro rudimentale sequenziazione. Tuttavia, la descrizione a marcatori dell’XML non è sufficiente a convogliare una semantica che esprima relazioni fra concetti [68]; è pertanto auspicabile utilizzare i metadati, espressi tramite opportuni tag XML (come ad esempio 3), come ancore semantiche verso una rappresentazione di più alto livello della realtà in cui contestualizzare la risorsa. Questa rappresentazione costituisce, appunto, l’ontologia di riferimento. L’ontologia è l’ultimo scalino verso il web semantico, indipendentemente dall’architettura scelta e può essere definita come: “una esemplificazione formale di un determinato campo dello scibile umano” [56]
6.2.2 l’approccio della rete semantica Un approccio alternativo consiste nell’estrazione dei ganci semantici dalle risorse e nella costruzione di un “nodo semantico” della risorsa stessa. Ogni nodo semantico è in un certo senso equivalente all’insieme dei metadati relativi alla risorsa, ma una sua rappresentazione distinta permette l’utilizzo di sintassi più articolate e linguaggi specifici per esprimere le relazioni. L’insieme dei nodi semantici costituisce quindi un modello di riferimento, esprimibile da una rete semantica, che mantiene una serie di link alle risorse concrete fruibili dagli utenti umani. Infine, la definizione di un modello si appoggia su una descrizione di livello ancora superiore dei termini e dei concetti fondamentali del dominio, tale descrizione, che riguarda gli elementi costitutivi e definitori del mondo, è una particolare rete semantica che prende il nome di Ontologia e, a causa dell’importanza dei concetti espressi e della ricchezza delle deduzioni che un agente intelligente deve poter eseguire su di essi, richiede tipicamente una trattazione ed una assiomatizzazione distinta dal resto del modello.
Progetto VICE
Definizione dell’architettura della piattaforma 54
Figura 49:architetture a tre livelli del web semantico
Dal confronto delle due architetture di Figura 49 si evidenzia come l’ontologia del modello a metadati sia di fatto molto più che una descrizione definitoria dei concetti e della “natura” del dominio descritto, ma diventi più simile ad una complessa rete semantica che comprende anche aspetti ontologici. Indipendentemente dall’architettura scelta, l’elemento innovativo dell’adozione di reti semantiche ed ontologie nel semantic web è che, contrariamente agli approcci tradizionali, i metadati del singolo documento non esprimono direttamente alcuna relazione semanticamente significativa tra i documenti stessi, al contrario le relazioni tra le risorse sono indotte e deducibili dalle relazioni tra i concetti a cui ciascuna risorsa è “ancorata”.
6.3 I linguaggi del semantic web L’effettivo sviluppo delle metodologie del semantic web, come visto, è strettamente legato all’affermazione di linguaggi di riferimento, in grado di fornire un supporto sintattico adatto a ciascun livello dell’architettura di Figura 49. Lo scenario di tali linguaggi è fortemente articolato e complesso, molte sono le tecnologie che si completano vicendevolmente in una sinergia non banale. Occorre quindi concentrare l’attenzione sugli standard emergenti e valutare l’applicabilità di ogni strumento ponendosi come obiettivo un sistema distribuito, debolmente tipizzato ed il più aperto possibile ad espansioni ed evoluzioni future.
6.3.1 XML Al livello appena superiore ai dati grezzi contenuti in ogni documento è necessario introdurre una sintassi standard, ma contemporaneamente espandibile, che permetta di descrivere con sufficiente elasticità le risorse in maniera facilmente comprensibile sia ad un lettore umano che ad un agente artificiale. Questo obiettivo è pienamente raggiunto dal framework XML, che si limita a definire una serie di regole con cui ciascuna applicazione può confezionarsi su misura un formato attraverso un insieme di tag. XML assume quindi un ruolo centrale di catalizzatore dell’attuale svolta del web, permettendo tra l’altro di trattare con un’unica sintassi problematiche molto diverse tra di loro come la presentazione grafica, la traduzione (XSL) e la ricerca (XQL, XQuery ed XML-QL) all’interno di documenti. Infine lo standard XML fornisce degli strumenti general purpose per verificare la correttezza sintattica dei documenti; il più semplice è il DTD, che di fatto fa parte della definizione originale di XML, mentre il più potente e più usato XML(S) è di fatto una applicazione di XML per scrivere documenti che descrivono a loro volta la sintassi di un particolare formato XML.
documenti
metadati modello
ontologia
Progetto VICE
Definizione dell’architettura della piattaforma 55
E’ importante notare come l’intera costruzione XML sia completamente indipendente da qualsiasi interpretazione semantica, ad esempio la gestione dei namespace (XMLNS) prescinde dal fatto che un namespace corrisponda o meno ad un documento internet.
6.3.2 RDF L’assoluta genericità di XML ne costituisce la maggiore attrattiva, ma si trasforma ovviamente anche nel suo principale limite quando si intende utilizzarlo in problemi molto specifici. Se si sceglie l’architettura basata sul modello logico, al livello di modello è necessario descrivere un insieme di risorse raggiungibili da web, in questo caso è opportuno utilizzare un linguaggio opportunamente studiato per la rappresentazione di modelli, come RDF. RDF (Resource Description Framework) è un linguaggio particolarmente adatto per rappresentare informazioni circa le risorse di rete [78]. In particolare è destinato a rappresentare metadati circa risorse, come autore e titolo di una pagina web. Tuttavia, generalizzando il concetto di pagina web a quello di “risorsa”, RDF è in grado di descrivere informazioni anche su entità non direttamente raggiungibili sulla rete come un docente, uno studente, un negozio ecc.. RDF si basa sull’idea di identificare oggetti utilizzando URI, e descrivere le risorse in termini di proprietà e valori di proprietà. Rispetto ad XML, lo standard RDF aggiunge una semantica di base ad alcuni tag e ad alcuni campi:
• I riferimenti diventano univoci, questo significa, ad esempio, che tutti i tag del tipo <rdf:Description about=”http://www.example.org/index.html#Marco”> dovranno essere riconosciuti come facenti riferimento ad una stessa risorsa
• Alcuni tag hanno una semantica fissata: ad esempio l’applicazione dovrà riconoscere i tag <description> e <type> come definiti dallo standard
• La struttura del documento viene interpretata come un descrittore: il parser deve riconoscere i tag interni ad una description come proprietà della risorsa descritta
E’ infine da evidenziare il fatto che, sebbene una rete RDF possa essere visualizzata come un file XML secondo lo standard RDF/XML, RDF ha una vita propria ed indipendente da XML, tanto che la sua forma “originale” è composta da una serie di asserzioni nella forma <soggetto predicato oggetto>.
6.3.3 RDF Schema XML definisce una sintassi, ma non definisce la conformazione sintattica effettiva di ogni applicazione (tanto che occorre un DTD o un XMLS per la sua validazione), allo stesso modo RDF definisce una semantica, ma non fornisce alcuno strumento per la validazione o il ragionamento su tale struttura. Ad esempio non esiste alcun concetto di tipo, se non come link sintattico tra una entità ed una seconda entità che ne rappresenta la classe di appartenenza. La descrizione delle proprietà di classi, relazioni e tipi sono tuttavia necessarie se si vuole eseguire automaticamente qualche tipo di inferenza sulla descrizione o più semplicemente si vuole poter controllare la correttezza del modello stesso. Ad esempio, RDF non definisce alcun modo per definire che un oggetto inanimato non possa avere una data di nascita. La descrizione del vocabolario di un modello RDF è demandata ad un differente linguaggio, detto appunto RDF Schema (RDF[S]). RDF[S] è perfettamente integrato con RDF e mette a disposizione costrutti per definire:
• Relazioni “is a” e tassonomie tra classi • Restrizioni di dominio e codominio delle relazioni • Relazioni isa e tassonomie tra relazioni
RDF[S] si pone quindi a cavallo tra il modello descritto dalla rete semantica e l’ontologia dei concetti.
Definizione dell’architettura della piattaforma 56
6.3.4 OWL e DAML+OIL Pur essendo un linguaggio potente per la rappresentazione della conoscenza, RDF non ha di per sé alcun modo di operare inferenze o deduzioni. In realtà RDF[S] estende la rete semantica, ma permette semplicemente di costruire tassonomie elementari di tipi e fornisce pertanto un supporto decisamente scarno all’inferenza [55] [62]. Bisogna rifarsi ad un ulteriore livello che riesca ad associare i concetti a regole logiche d’uso, cioè a nodi concettuali all’interno di ontologie. La descrizione degli aspetti ontologici del mondo reale richiede alcune estensioni ad RDF[S], che sono state proposte nel linguaggio DAML+OIL e recepite dal W3C come punto di partenza di OWL. In particolare OWL definisce solo alcune estensioni sintattiche, così che una ontologia sia sostanzialmente un comune file RDF[S], ma con tag opportuni definiti da OWL [75] per rappresentare:
• Cardinalità degli elementi • Cardinalità delle proprietà • Tipi di dato elementari, con possibili estensioni sulla base di XML[S] • Liste limitate di elementi • Negazione (classe complemento) • Vincoli di disgiunzione tra classi • Intersezione ed unione di classi • Condizioni necessarie e sufficienti per l’appartenenza ad una classe • Proprietà inverse • Caratteristiche (es: transitività) di relazioni
Al suo interno OWL è organizzato in una gerarchia a tre livelli: al livello base troviamo OWL Lite, che sostanzialmente è equivalente ad RDF[S], al livello superiore c’è invece OWL Full, che supporta costrutti avanzati come la costruzione di metaclassi (cioè metaconcetti), ma che sottende una teoria non decidibile, mentre al livello intermedio si colloca OWL DL, così chiamato in virtù della sua equivalenza espressiva con le Description Logic, così da mantenere la decidibilità anche estendendo notevolmente il potere espressivo di RDF[S]. Limitare la potenza espressiva del linguaggio di modellazione alle logiche descrittive, con particolare riferimento a SHIQ, permette di utilizzare dimostratori di complessità nota e rende il problema del reasoning sulla rete semantica trattabile e scalabile. In particolare sono noti metodi efficienti di ragionamento [59] e sono stati implementati prototipi di dimostratori, come 53 [53] e 70 [70].
Figura 50 - una visione gerarchica del semantic web
Progetto VICE
Definizione dell’architettura della piattaforma 57
6.4 Strumenti per il semantic web L’utilizzo di ontologie presuppone l’esistenza di una serie di strumenti di sviluppo, come editor e sistemi per la manipolazione, interrogazione e ragionamento. L’offerta di editor ontologici e, più genericamente, editor per reti semantiche è molto vasta, dato che l’interesse nel campo ha spinto vari produttori e diversi istituti di ricerca a realizzare editor a volte integrati con sistemi di reasoning, oppure ad estendere in tal senso prodotti preesistenti, tipicamente provenienti dal mondo dell’ingegneria del software. Una lista parziale degli strumenti più diffusi è:
Nome Produttore Linguaggi Reasoning Coherence Unicorn Solutions XML, XMLS, RDBS,
OntoBuilder University of Savoy DAML+OIL, XML, LOK, KIF
OntoEdit Ontoprise F-logic, RDFS, DAML+OIL, RDB
OntoBroker
Ontolingua Stanford Knowledge systems Lab
DAML+OIL, KIF, OKBC, Loom, Prolog,
ontolingua, CLIPS, Classic, Ocelot, Protege
JTP
Protégé-2000 Stanford medical informatics
OKBC, RDFS, XML, EDB
PAL, 53, 70
RDFAuthor alpha RDF, XML Correttezza RDF
RDFEdit Jan Winkler RDF, DAML, OIL, Shoe Sintattica WebOnto Knowledge media
institute OCML, RDF, RDFS, GXL, ontolingua, OIL
Solo OCML
Progetto VICE
Definizione dell’architettura della piattaforma 58
Oltre agli editor visuali sono disponibili alcune librerie che consentono agli agenti software di interagire con le reti semantiche e con sistemi di reasoning integrati. Tra tutti ricordo Jena, che permette ad un agente Java di:
• leggere e scrivere reti semantiche in RDF • definire e manipolare concetti in maniera Object Oriented mediante opportune classi • eseguire interrogazioni sulla base di conoscenza mediante il linguaggio RDQL • eseguire ragionamenti automatici sul modello, espandendolo mediante inferenze • utilizzare ontologie in DAML+OIL ed OWL
6.5 Le ontologie per l’e-learning La formalizzazione di una base di conoscenze è il punto di partenza fondamentale ed irrinunciabile per la realizzazione di agenti intelligenti che svolgano il proprio compito di supporto alla didattica in maniera coerente con la semantica del dominio applicativo. Tuttavia, tale processo di formalizzazione è complesso e richiede un gran dispendio di risorse da due punti di vista:
• Qualitativo: la definizione ontologica del dominio dell’applicazione deve essere sufficientemente preciso da escludere ogni possibile ambiguità di interpretazione, ma contemporaneamente non deve caratterizzare in maniera troppo rigida il campo di interesse perché questo comporterebbe una perdita di elasticità del sistema, artificiosa rispetto alle effettive potenzialità. Il corretto equilibrio tra precisione e flessibilità richiede una definizione ontologica attenta e qualificata degli aspetti pedagogici degli interventi formativi.
• Quantitativo: la costruzione di ontologie è notoriamente dispendioso in termini di tempo; all’interno del progetto VICE l’elemento che richiede il maggior sforzo in questo senso è certamente la descrizione dell’ontologia di contenuto, dato che gli argomenti su cui vertono i singoli LO sono estensionalmente significativi rispetto, ad esempio, alle tipologie degli utenti o ai concetti inerenti le procedure e le metodologie didattiche.
Da quanto detto emerge la necessità di individuare tempestivamente gli elementi del sistema che intervengono nei processi automatici di ricerca e composizione di LO ed indirizzare gli sforzi verso una prototipazione rapida di tali componenti. Per guidare la selezione è utile individuare le domande fondamentali a cui occorre rispondere per inquadrare il particolare scenario applicativo del progetto, queste sono sostanzialmente:
• Cosa stiamo insegnando? • A chi lo stiamo insegnando? • Quali sono gli obiettivi del processo di apprendimento? • Di che risorse disponiamo? • Come dobbiamo organizzare i processi didattici per raggiungere gli obiettivi formativi?
Per rispondere a queste cinque domande occorrono altrettante ontologie, che presenteremo nel prosieguo. Queste ontologie, pur rappresentando informazioni di natura profondamente diversa, sono fittamente interconnesse tra di loro e costituiscono collettivamente un supporto ontologico integrato, che disegna lo scenario applicativo in cui si collocano gli agenti intelligenti.
6.5.1 Ontologia di contenuto L’elemento centrale attorno a cui ruota il sistema ontologico è la descrizione dei concetti oggetto dell’attività didattica, cioè degli argomenti su cui vertono i LO del repository. L’ontologia del contenuto è l’applicazione largamente più diffusa delle tecniche di rappresentazione della conoscenza all’interno di sistemi di e-learning ed è costituita da un insieme di nodi, corrispondenti ai concetti, collegati tra i loro da link semantici di tipo strutturale, che descrivono le relazioni semantiche tra concetti. Vassileva e Deters propongono l’uso di due tipi di link semantici: relazioni direzionali , 1:n oppure. n:1 per rappresentare le gerarchie con riferimento all’astrazione,
Progetto VICE
Definizione dell’architettura della piattaforma 59
aggregazione e relazioni causali, relazioni bidirezionali 1:1 per rappresentare relazioni di analogia e temporali. Alle relazioni di tipo strutturale, così chiamate perché descrivono la struttura del corpus di concetti, si affiancano relazioni che caratterizzano i concetti da un punto di vista pedagogico. La principale relazione pedagogica è quella di prerequisito, che collega concetti propedeutici a quei concetti che li richiedono ed induce un ordinamento parziale tra i nodi dell’ontologia. Contrariamente alle relazioni strutturali, che possono essere utilizzati come criteri preferenziali nella selezione dei concetti e nella loro sequenziazione, le relazioni pedagogiche rappresentano per lo più dei vincoli che devono essere rispettati dal sistema di elaborazione intelligente dei contenuti. A causa della loro particolare natura, l’associazione di prerequisiti può essere trattata in tre modalità differenti:
− La relazione di prerequisito può essere usata come unica associazione semantica nell’ontologia. Il risultato è una struttura a curriculum che può guidare la costruzione di percorsi formativi. Tuttavia, proprio per la sua semplicità, questa soluzione comporta un forte impoverimento del modello e limita pertanto la flessibilità e la personalizzabilità dei processi che su tale modello si basano.
− I link di prerequisito possono essere del tutto omessi dall’ontologia di contenuto e dedotti implicitamente dai link strutturali secondo opportune regole di trasformazione. Ad esempio si può definire una regola del tipo : “per insegnare un concetto occorre insegnare tutte le componenti di tale concetto (relazione part-of)”. Questo approccio presenta diversi aspetti positivi. Innanzitutto diventa possibile utilizzare ontologie di dominio prodotte in ambiti differenti dall’e-learning, così il sistema potrebbe riferirsi ad una ontologia della matematica nata inizialmente come riferimento interno di un centro di ricerca aggiungendo le regole per mappare i link strutturali sui link pedagogici. Inoltre l’introduzione della fase di mapping tra le due tipologie di relazioni è il passo ideale del processo di modellizzazione in cui far intervenire differenti criteri pedagogici e si propone come ulteriore mezzo di personalizzazione
− I link di prerequisito possono essere considerati alla pari di tutti gli altri link semantici, così verrebbe a cadere una distinzione formale tra link strutturali e link pedagogici. La differenza viene recuperata quando i vari agenti artificiali ed i tool di supporto all’utente interpretano le relazioni pedagogiche come vincoli da rispettare, mentre usano i link strutturali come criteri aggiuntivi di preferenza.
− Infine le relazioni di propedeuticità possono essere considerate distinte dall’ontologia vera e propria e proiettate direttamente sui descrittori dei singoli LO. In questo modo ogni risorsa è descritta non solo sulla base dei concetti su cui verte, ma anche sui concetti che si richiede l’utente conosca per poterla fruire adeguatamente. Questa soluzione si pone a metà strada tra una rappresentazione delle propedeuticità interamente contenuta nell’ontologia ed una rete che coinvolge direttamente coppie di LO (soluzione quest’ultima per altro inattuabile a causa della crescita del modello in base alla dimensione del repository).
6.5.2 Ontologia dello studente I nuovi sistemi di apprendimento assistito dal calcolatore sono stati ben collocati all’interno della teoria dell’insegnamento da M. Martinez [62], che si è concentrato sulla tematica della personalizzazione dell’intervento formativo. Secondo Martinez la personalizzazione dell’intervento ha un ruolo fondamentale nel raggiungimento degli obiettivi formativi in quanto permette di assecondare le naturali inclinazioni dell’utente prevenendo l’insorgere di noia, disinteresse e frustrazione. L’approccio centrato sull’utente (whole-person) considera tutti gli aspetti educativi, psicologici, emozionali e relazionali dello studente per costruire e somministrare un percorso formativo su misura, che potrebbe addirittura adattarsi alle richieste emergenti ed ai comportamenti dell’utente. In un sistema informatizzato la personalizzazione richiede in primo luogo il riconos47ento dell’utente e possibilmente anche una sua profilazione che colga gli elementi determinati allo scopo.
Progetto VICE
Definizione dell’architettura della piattaforma 60
Sono stati identificati cinque livelli di personalizzazione: • Riconos47ento del nome: al livello più elementare è sufficiente riconoscere lo studente,
usando ad esempio dei banali userID e password. In questo modo è possibile mantenere un dossier personale per ogni studente, che conterrà i corsi seguiti, gli esercizi svolti, ecc… Il riconos47ento dell’utente sortisce un effetto psicologico positivo, aumentandone il coinvolgimento e l’interesse
• Auto descrizione: mediante questa tecnica ogni studente è in grado di descrivere al sistema le proprie caratteristiche. Ad esempio si potrebbe eseguire un test preliminare prima di un corso per valutare le capacità preesistenti, in modo che il sistema possa rispondere meglio alle esigenze dal singolo utente
• Raggruppamento: è possibile utilizzare caratteristiche demografiche come il titolo di studio o il tipo di impiego per raggruppare l’utenza in sottoinsiemi di più modeste dimensioni, all’interno dei quali l’azione formativa possa essere sostanzialmente uniforme ed indifferenziata
• Cognitive-based: utilizza informazioni sul processo cognitivo. Ad esempio è possibile registrare preferenze sul tipo di interazione (testuale, visiva o audio) per far fronte a preferenze personali o, eventualmente, ad handicap dello studente.
• Whole-Person: la personalizzazione centrata sull’utente utilizza informazioni psicologiche e pedagogiche quali l’orientamento dell’utente, le attività preferite, l’atteggiamento nei confronti della materia ecc.. La raccolta delle informazioni pedagogiche può avvenire contestualmente all’erogazione del corso, monitorando le scelte fatte dall’utente ed eseguendo una profilazione dinamica.
La profilazione dell’utente è una attività fondamentale che supporta la costruzione di percorsi formativi personalizzati. Secondo Martinez [62] è possibile definire delle classi di studenti in larga misura indipendenti dalle peculiarità della materia o degli argomenti oggetto di studio. Queste categorie riflettono diversi atteggiamenti dello studente nei confronti dell’attività pedagogica:
• Transforming learners: sono gli studenti più motivati, che vedono nella formazione un mezzo per migliorare se stessi. Tendono a dare grande importanza all’apprendimento, ma richiedono che sia lasciata loro una grande autonomia nell’organizzazione del materiale e nelle modalità di fruizione dello stesso. In questo caso è preferibile non organizzare rigidamente tutti i LO relativi al corso, ma proporre un modulo sintetico di introduzione e di panoramica degli argomenti e fornire un insieme destrutturato di moduli che il lettore possa navigare mediante il modello dell’ipertesto secondo le modalità che preferisce. La principale causa di fallimento dell’intervento formativo è la demotivazione e la noia dovuta ad un contesto poco stimolante.
• Performing learners: sono studenti motivati nelle situazioni di loro interesse, prevalentemente ad orientamento applicativo. Lo studente performing cerca continui riconos47enti per gli obiettivi raggiunti, specialmente se li valuta più difficili del dovuto. I performing learner prediligono una formazione orientata ai dettagli ed alla pratica e richiedono una guida puntuale da parte del docente.
• Conforming learners: hanno un atteggiamento passivo nei confronti del processo educativo, sono spesso meno capaci ed hanno scarso interesse per gli argomenti trattati e per l’autonomia nella costruzione di percorsi formativi. E’ la categoria che meglio si adatta ad una rigida strutturazione dell’intervento formativo, ma deve essere continuamente stimolata nella soluzione di problemi semplici.
• Resistant learners: sono soggetti che non percepiscono il processo formativo come importante o positivo nella loro realtà, a volte a causa di precedenti fallimenti. Tendono ad ostacolare il processo sia deliberatamente che non. Tuttavia, a volte questi studenti possono mostrare un alto potenziale se messi nelle opportune condizioni. Martinez sostiene che “se
Progetto VICE
Definizione dell’architettura della piattaforma 61
uno studente non vuole imparare non lo farà; indipendentemente dalla qualità dell’istruzione offerta. Se uno studente vuole imparare lo farà comunque; indipendentemente dalla qualità dell’istruzione offerta” [62].
La tipologia dell’utente finale è particolarmente significativa durante la fase di progettazione e realizzazione di un intervento formativo, dato che può guidare sia la scelta dei LO che le tecniche di composizione (es: transforming learners). Alcuni standard, tra cui 3, permettono di specificare la tipologia di utenza a cui meglio si addice il singolo oggetto.
6.5.3 Ontologia degli obiettivi La definizione degli obiettivi didattici richiede la specifica delle competenze richieste dall’utente. Fino ad ora ci siamo concentrati sull’idea che la relazione tra l’utente ed i concetti del dominio sia sostanzialmente non modale, cioè non sia caratterizzata dalle particolari abilità che lo studente possiede in riferimento al concetto. In realtà, la tipizzazione degli archi tra il modello dello studente e l’ontologia del contenuto permetterebbe di focalizzare maggiormente il processo formativo verso degli scopi precisi. Ad esempio, un corso con scopi prettamente professionalizzanti può articolarsi lungo una sequenza di concetti analoga ad un corso universitario, ma prediligerà la formazione di competenze pratiche e di problem solving, almeno nella misura in cui questo non pregiudichi i vincoli di propedeuticità. La costruzione di una ontologia degli obiettivi pedagogici può rifarsi alle ontologie di Bloom [42] e di Merrill [64], che propongono una tassonomia più o meno dettagliata delle possibili competenze. L’ontologia può contenere una piccola rete di relazioni di propedeuticità, che esprime, ad esempio, il fatto che la capacità di applicare un concetto richiede per lo meno una conoscenza superficiale degli aspetti definitori ad esso correlati. L’ontologia degli obiettivi è strettamente interconnessa con l’ontologia degli utenti, dato che interviene nella qualificazione dei profili utente. Analogamente, la definizione degli obiettivi interviene nella fase di pianificazione dei curriculum e guida i corrispettivi algoritmi di planning. In letteratura è stato anche proposto di integrare l’ontologia delle capacità all’interno dell’ontologia di contenuto, così la rete conterrà una serie di nodi per ogni concetto, ciascuno relativo ad una particolare competenza, interconnessi tra di loro da opportuni archi di propedeutici. Questa soluzione appare poco scalabile, dato che impedisce di distinguere l’informazione contenutistica dall’informazione sulle capacità.
6.5.4 Ontologia delle risorse La descrizione delle risorse didattiche è quella che storicamente ha suscitato la maggior attenzione nel mondo della pedagogia. Ogni LO è rappresentato da un nodo all’interno di una opportuna rete semantica, che raccoglie le informazioni fondamentali sulla risorsa tramite un opportuno insieme di metadati. Le informazioni fondamentali possono essere raggruppate in tre categorie fondamentali:
• Informazioni tecniche: comprendono il formato del file che contiene la risorsa, un URI sufficiente alla localizzazione del LO e la sua fruizione, la dimensione del file, data di creazione, autore ed eventuali richieste specifiche per la sua fruizione. Questo sottoinsieme di metadati può fare convenientemente riferimento a standard industriali utilizzati anche al di fuori dell’e-learning, come ad esempio 52lin Core.
• Informazioni pedagogiche elementari: contengono i dati circa le caratteristiche pedagogiche della risorsa. Qui il riferimento è 3, estensione di 52lin Core per il mondo dell’apprendimento. Informazioni pertinenti in questo gruppo sono la difficoltà della risorsa, il tempo presunto di fruizione e la tipologia di utenza a cui si rivolge. Una classificazione pedagogica e cognitiva dei LO è stata proposta nei lavori di Wiley e recepita dall’IMS.
• Informazioni pedagogiche complesse: in questa terza sezione troviamo le informazioni pedagogiche che non possono essere riferite semplicemente all’ontologia delle risorse, ma richiedono richiami espliciti ad ontologie differenti. In questo gruppo troviamo la classificazione delle risorse a seconda della natura pedagogica (spiegazione, verifica,
Progetto VICE
Definizione dell’architettura della piattaforma 62
esercizio, esempio, ecc..) ed il collegamento con i nodi dell’ontologia di contenuto che rappresentano i concetti trattati dal LO.
I LO possono essere classificati sulla base della loro struttura e della loro dimensione [38]:
• Fundamental: sono LO elementari, come semplici immagini JPEG • Combined-closed: sono composti da un insieme statico di LO più semplici. Ad esempio
potrebbe trattarsi di una scheda composta da una foto statica, del testo e dell’audio di accompagnamento. La composizione deve essere statica, nel senso che le parti componenti non sono più identificabili singolarmente.
• Combined-open: sono simili ai precedenti, ma gli oggetti costituenti vengono combinati dinamicamente all’atto della fruizione e restano disponibili singolarmente. Esempio tipico è quello di una pagina web che costituisce “l’intelaiatura” in cui vengono incasellati componenti multimediali come testo, immagini, video ecc..
• Generative-presentation: è l’esempio più semplice di LO attivo. In questo caso è il LO stesso che raccoglie e propone componenti differenti sulla base delle specifiche richieste dello studente. Come esempio Wiley indica un applet Java in grado di generare un insieme di note e pentagrammi e di proporre all’utente un esercizio sul riconos47ento degli accordi; ovviamente in questo caso i singoli elementi e l’esercizio stesso non si ripresenteranno mai identici a se stessi, ma il LO genererà autonomamente la presentazione.
• Generative-instructional: è un’estensione dei LO Generative-presentation, in questo caso l’oggetto è in grado di generare dinamicamente sia la parte formativa che quella valutativa. Costituiscono la logica e la struttura per combinare LO e valutare l’interazione con lo studente.
La tassonomia proposta permette di identificare caratteristiche peculiari di ciascuna classe di LO in termini di:
• Numero degli elementi costituenti • Tipi di oggetti contenuti • Componenti riusabili • Funzioni tipiche del LO • Dipendenza da oggetti esterni • Tipo di logica contenuta ed implementata • Potenziale per il riutilizzo in contesti differenti (decontestualizzazione) • Potenziale per il riutilizzo nello stesso contesto
6.5.5 Ontologia pedagogica L’ultimo problema è descrivere formalmente i criteri pedagogici che guidano la scelta e la composizione di risorse didattiche. Questa descrizione si articola a due livelli differenti:
• A livello concettuale: come già accennato, se si sceglie di derivare i link pedagogici di precedenza dai link strutturali tra concetti è possibile esprimere alcuni criteri pedagogici tramite la scelta di tali equivalenze.
• A livello di presentazione: la maggior parte delle scelte pedagogiche intervengono nella fase di selezione del materiale e nella composizione di piccole unità pedagogiche incentrate su un argomento specifico (pianificazione di presentazione, come discusso in seguito).
6.6 I servizi basati sulle ontologie Il sistema ontologico integrato fornisce il supporto semantico per una serie di servizi avanzati; questi si articolano in tre gruppi fondamentali:
Progetto VICE
Definizione dell’architettura della piattaforma 63
1. servizi generali: sono una estensione di alcuni servizi comuni già erogabili da un repository classico, ma che traggono vantaggi dalla rappresentazione esplicita dell’ontologia di riferimento e, soprattutto, dai comuni servizi di reasoning a questo collegati. In questa famiglia troviamo la ricerca e navigazione semantiche del repository ed il controllo di consistenza dello stesso
2. servizi di supporto: sono servizi piuttosto semplici ed atomici, indipendenti dalle funzionalità di base del repository, che possono essere utilizzati da queste o direttamente dall’utente. Gli esempi più significativi sono le varie tecniche per la costruzione automatica di LO per la valutazione dello studente
3. servizi ITS (Intelligent Tutoring System): sono i servizi più strettamente collegati alla rappresentazione della semantica dei metadati e costituiscono la maggiore innovazione dovuta all’introduzione delle ontologie di riferimento. Tipicamente richiedono un supporto al reasoning terminologico e l’utilizzo di tecniche ed algoritmi provenienti dal mondo dell’Intelligenza Artificiale. I servizi ITS si concentrano soprattutto sulla struttura degli interventi come processi nello spazio e nel tempo e, grazie all’informazione circa il dominio di conoscenze da veicolare (ontologia di contenuto) e circa gli approcci pedagogici si propongono vuoi di verificare la qualità degli interventi vuoi di generarne alcuni in maniera automatica
6.6.1 Ricerca semantica La rete semantica composta dai descrittori dei LO e dei profili utenti unita con le informazioni contenute nelle ontologie permette di esprimere le query non in termini sintattici, usando linguaggi come SQL o RDQL, ma descrivendo semanticamente le proprietà degli oggetti desiderati. Questa possibilità, unita con la descrizione formale dei criteri che guidano la composizione dei LO, permette di costruire un servizio che suggerisce volta per volta al docente una selezione di LO adatti man mano che si procede alla costruzione di un corso. L’ontologia di contenuto contiene le principali informazioni per l’estrazione di oggetti dal repository. L’aiuto ontologico alla ricerca si espleta in tre modalità fondamentali:
6.6.1.1 Ricerca per tassonomie Una ontologia è in generale inquadrabile come estensione di una tassonomia, su cui viene plasmata e che ne costituisce la struttura portante. La relazione di concetto/sottoconcetto è solitamente la principale del modello e viene utilizzata per rappresentare le varie forme di specializzazione che intervengono in quasi tutti i processi di modellizzazione. Per questo motivo il sistema ontologico integrato si presta d essere utilizzato innanzitutto come un albero di classificazione dei contenuti. Ammettiamo ad esempio di aver definito una ontologia di contenuto per la matematica, in questo caso avremmo dovuto definire ConcettoMatematico come caso particolare dei ConcettoInsegnabile definito all’interno della top-ontology di riferimento per il nostro sistema. ConcettoMatematico si articola ulteriormente in un sottoalbero, all’interno del quale troveremo, ad esempio, il concetto di Operazione. Nella parte di modello dell’ontologia (quello che DL si chiamerebbe A-Box) introduciamo la derivata come individuo facente parte del concetto di Operazione. L’albero tassonomico può essere utilizzato in vari modi per migliorare la ricerca di materiale didattico.
• Innanzitutto è possibile un utilizzo diretto della tassonomia da parte del docente. Questo può navigare l’albero tassonomico dei contenuti a partire da ConcettoInsegnabile ed espandendo volta per volta il ramo di suo interesse, sfruttando l’organizzazione dei concetti in modo da vedere quali contenuti dell’area di interesse sono presenti nel repository, ma senza per questo doversi muovere nella complessa rete di relazioni che costituisce l’ontologia nella sua interezza
• Il sistema può utilizzare la classificazione per rispondere adeguatamente a richieste dell’utente che non siano direttamente riferibili a specifici valori nei metadati del repository.
Progetto VICE
Definizione dell’architettura della piattaforma 64
Immaginiamo ad esempio che un docente voglia preparare un corso di analisi e sia interessato alle operazioni su funzioni. Utilizzando il supporto ontologico l’utente può richiedere tutti i LO che hanno come argomento una Operazione. Il sistema di reasoning sottostante utilizza la classificazione degli argomenti per recuperare tutto il materiale che tratta di operazioni, indipendentemente dal particolare individuo dell’ontologia di contenuto a cui si fa riferimento nei metadati del LO e dal particolare sottoconcetto in cui questo è classificato nella tassonomia.
Figura 51 -estratto di possibili ontologie di contenuto e delle risorse. Le linee tratteggiate dividono il livello dei
concetti (T-Box) dal livello del modello (A-Box)
La Figura 51 presenta un estratto di una semplice ontologia di contenuto per corsi di matematica e la descrizione di un applet interattivo che presenta un esercizio sulle derivate. Una descrizione di questo tipo permette al docente di raggiungere la stessa risorsa sia secondo il path di navigazione Concetto > Concetto matematico > Operazione > derivata che, ad esempio, LO > Interattivo >
Applet. In maniera analoga, le query che il docente pone al sistema possono riferirsi ai concetti generali
quali Concetto Matematico e LO Interattivo.
6.6.1.2 Interoperabilità tra basi di conoscenza differenti Il motore di interrogazione semantica può sfruttare i servizi di reasoning caratteristici dei sistemi di rappresentazione della conoscenza per integrare repository distribuiti, sfruttando tutte le relazioni implicite di equivalenza e di inclusione (sussunzione) tra i termini definiti in ontologie diverse in modo da promuovere l’interoperatività tra sistemi basati su ontologie differenti. Una critica spesso rivolta al mondo delle ontologie sostiene che l’interoperabilità delle piattaforme richiede un livello irrealistico di accordo su una particolare ontologia. In realtà, a nostro avviso, questo non è vero, o per lo meno è solo uno dei metodi per ottenere l’interoperabilità. Più in generale, l’ingegnere della conoscenza responsabile della manutenzione dell’ontologia di un particolare istituto, volendo integrare il repository di un istituto differente, può limitarsi a collegare tra di loro solo alcuni dei nodi delle due ontologie, lasciando che il sistema di reasoning sottostante derivi le relazioni di inclusione tra concetti in modo da garantire l’interoperabilità.
Definizione dell’architettura della piattaforma 65
Un caso particolare e particolarmente semplice di questa interoperabilità passa attraverso la mappatura di alcuni tra i metadati proposti con gli standard attualmente più diffusi, quali 52lin Core e 3.
6.6.1.3 Navigazione semantica del repository Come visto nei paragrafi precedenti l’uso di ontologie di riferimento migliora sensibilmente il processo di ricerca ed estrazione dell’informazione dal repository, sia introducendo una serie di criteri di ricerca basati sulla semantica del contenuto, sia per quanto riguarda l’integrazione di repository differenti e potenzialmente facenti riferimento ad ontologie differenti. Una volta ottenuti i LO di interesse, la rete di relazioni semantiche che collegano i LO tra di loro (relazioni retoriche) e che collegano i concetti a cui tali LO si riferiscono possono ancora essere utili per una navigazione localizzata del repository che permetta l’individuazione di risorse collegate o similari. Se ad esempio il docente sta selezionando dei LO che presentano il concetto di derivata il sistema ontology-based può, ad esempio, suggerire collegamenti con LO di valutazione dello stesso concetto, oppure con LO che costituiscono un rinforzo formativo perché richiamano i concetti chiave propedeutici a quello trattato (ad esempio, una definizione del concetto di limite)
6.6.1.4 Costruzione di domande a risposta chiusa Come accennato, uno dei servizi di supporto basati sull’ontologia è la costruzione automatica di quiz. Il primo modo per realizzare questo servizio è stato studiato da Fisher all’interno del progetto Multibook [54], che esemplifica l’applicabilità del modello dei LO almeno in un contesto educativo ben delineato e caratterizzato. Multibook è un libro sulle tecnologie multimediali che può essere fruito in maniera personalizzata a seconda delle specifiche richieste dell’utente ed ha una seppur limitata capacità di generare nuovi contenuti oltre che di organizzare i LO presenti nella KB. Per supportare la sequenziazione personalizzata Multibook modellizza lo studente all’interno dell’ontologia (human learner entità) e segue un modello di tutoraggio che coinvolge lo studente (learner), l’insegnante tutore (coach) e la macchina. Gli esperimenti sono stati svolti utilizzando i metadati standard di 3 ed implementando una ontologia generale per l’interazione con l’insegnate ed una ontologia specifica per la sequenziazione dei LO. Fisher ripropone la divisione tra metadati ed ontologia chiamando gli uni “risorse” e l’altra “conoscenza”. Inoltre, all’interno di Multibook esiste una ulteriore distinzione tra due componenti complementari della conoscenza sul dominio:
• Concept space: contiene le informazioni ontologiche sulla materia, nella fattispecie il multimedia. L’ontologia è composta da concetti chiave e relazioni necessarie alla costruzione di percorsi formativi ed utili per legare tra di loro i LO in maniera semantica
• Media Brick Space: è direttamente collegato con i singoli LO, tanto che è forse più simile ad un modello che ad una teoria. Oltre ai riferimenti ai singoli LO ed ai relativi metadati contiene delle informazioni “retoriche” che legano tra di loro gli oggetti secondo relazioni di difficoltà, modalità di fruizione ecc..
Da un punto di vista pratico gran parte del lavoro svolto in Multibook ha riguardato la generazione automatica di esercizi. L’idea è di generare semplici domande chiuse utilizzando l’informazione semantica dell’ontologia del contenuto. Le domande generabili sono raggruppate in varie famiglie:
• Part-of questions: sono domande del tipo “da che elementi è composto x?” • Application questions: del tipo “quale è il campo di applicazione di x?” • Domande sui dettagli: “quante righe e colonne compongono un’immagine QCIF?” • Calcoli: “quanti bit ci sono in un’immagine 400x400 a 24 bit?”
Progetto VICE
Definizione dell’architettura della piattaforma 66
Mentre le domande sui dettagli ed i calcoli sono difficilmente generabili in modo automatico, in quanto coinvolgono semantiche complesse, le domande sulle parti e sulle applicazioni possono essere generate automaticamente grazie all’ontologia del dominio. In particolare, parlando delle domante “part-of”, il concetto di cui si vuole testare la conoscenza è rappresentato da un nodo all’interno dell’ontologia del dominio; partendo da questo nodo sarà sufficiente seguire gli archi del tipo “composto da” per ottenere la lista delle componenti. L’algoritmo di costruzione della domanda si articola quindi in:
1 Identificare il nodo che rappresenta il concetto voluto 2 Costruire la risposa giusta seguendo gli archi dell’ontologia 3 Costruire un certo numero di risposte sbagliate 4 Mischiare casualmente l’ordine delle risposte
Paradossalmente, il problema più grosso consiste nel creare risposte sbagliate “verosimili”; per fare questo occorre estrarre dall’ontologia una delle molteplici tassonomie in essa contenute, cioè ridurla ad un albero con archi del tipo “is-a” o “is part of”, risalire uno o più livelli dell’albero senza allontanarsi troppo dall’argomento trattato e produrre nuove soluzioni a partire dal nodo raggiunto. La sperimentazione ha fornito risultati sostanzialmente positivi in termini di credibilità degli esercizi e di soddisfazione degli studenti.
6.6.1.5 Esercizi di ricostruzione dell’ontologia Un differente approccio all’utilizzo dell’ontologia di contenuto per la generazione automatica di LO valutativi è stato proposto da 47olino ed altri [47] e si basa sulle “Verified concepì map”. L’idea di fondo è utilizzare l’ontologia non solo come un modello del dominio conoscitivo che guida il sistema artificiale nella gestione del repository, ma anche come una fonte oggettiva di conoscenza che può diventare essa stessa contenuto di un LO. In questo caso la costruzione dell’esercizio è solo parzialmente automatica:
1. Il docente identifica i concetti chiave di cui vuole valutare la conoscenza da parte dello studente e seleziona un insieme di relazioni semantiche che li collega tra di loro
2. Viene estratta una sottorete dall’ontologia di contenuto che contenga i concetti identificati dal docente
3. La sottorete viene scomposta nei suoi elementi costituenti All’atto dell’erogazione del LO allo studente verrà richiesto di ricostruire la sottorete semantica collocando nella giusta configurazione i concetti e le relazioni tra di essi. Una volta che il docente ritiene di avere completato la rete il sistema è in grado di confrontare la soluzione proposta con quella effettivamente presente nell’ontologia di contenuto. A questo punto sono dati tre casi:
1. La sottorete è stata correttamente assemblata. In questo caso il test ha avuto esito positivo 2. La sottorete è compatibile con l’ontologia di riferimento, ma non equivalente. Ad esempio, è
possibile definire delle gerarchie tra le relazioni e lo studente potrebbe aver correttamente collegato i concetti derivata e limite con un arco uso, senza aver identificato con precisione il tipo di “uso” che la derivata fa del limite.
3. la sottorete presenta errori: sia per mancanza di archi, che per presenza di archi sbagliati Negli ultimi due casi il sistema è in grado di evidenziare l’errore e di porre in essere azioni correttive, tipicamente richiedendo allo studente di sostituire un arco sbagliato o di specificare meglio una relazione. La soluzione proposta da 47olino richiede che il docente definisca le singole azioni correttive, anche se probabilmente l’ontologia contiene già informazioni sufficienti per generare richieste di correzione sufficientemente utili.
Progetto VICE
Definizione dell’architettura della piattaforma 67
Figura 52 - attività caratteristiche delle verified concept map
6.6.1.6 Sequenziazione e pianificazione didattica I servizi di supporto alla costruzione di interventi formativi sfruttano tutte le ontologie descritte e si basano sulla descrizione della struttura desiderata di un corso personalizzato rispetto al particolare profilo dell’utente ed agli obiettivi formativi. Questa informazione può essere sfruttata per due scopi duali:
• Verifica di correttezza di un intervento: in questo scenario il docente utente viene guidato dal sistema interattivo nella costruzione di una sequenza di LO, utilizzando tra gli altri i servizi di ricerca semantica già citati. Una volta che l’intervento è stato terminato il sistema è in grado di verificare alcune caratteristiche desiderate, quali la struttura pedagogica desiderata, l’omogeneità delle risorse utilizzare e la coerenza e coesione contenutistica della sequenza
• Composizione automatica dell’intervento: andando verso una automatizzazione più radicale del processo formativo, la costruzione automatica degli interventi si pone come un servizio di estrema utilità per migliorare i tempi ed i costi di erogazione della formazione.
La sequenziazione del materiale didattico può essere riletta come la pianificazione dell’intervento formativo ed è quindi riconducibile alla tematica del planning centrale nell’Intelligenza Artificiale. La costruzione di un percorso formativo può essere pensata in due fasi distinte e consecutive:
• Pianificazione dei contenuti: il primo obiettivo è la costruzione di un percorso all’interno dell’ontologia di contenuto che raggiunga gli obiettivi formativi a partire da un sottoinsieme dei concetti conosciuti dallo studente. Questa fase può utilizzare algoritmi classici dell’IA e può produrre sia percorsi lineari, imponendo un ordinamento totale tra i nodi interessati, sia una pianificazione parziale, estraendo in generale una sottorete semantica dall’ontologia di contenuto. Questa seconda soluzione preserva un certo grado di flessibilità negli interventi, semplificando la seconda fase di popolazione del corso con il materiale didattico vero e proprio
• Pianificazione di delivery: nella seconda fase si procede alla costruzione, per ogni nodo del piano dei contenuti, di un sottografo di LO relativi ad un particolare concetto. In questa fase intervengono criteri pedagogici “in piccolo”, che possono essere colti tramite degli schemi all’interno dell’ontologia pedagogica. Qui si sceglie se presentare prima una lezione e poi degli esercizi, oppure anticipare un esempio introduttivo per poi procedere ad una trattazione sistematica dell’argomento e così via.
Scelta degli archi Scelta dei nodi
Costruzione sottorete
Definizione dinamica
Composizione
StudenteCorrezioneDocente Valutazione
Verifica
Progetto VICE
Definizione dell’architettura della piattaforma 68
6.7 Implementazione
6.7.1 Integrazione Il sottosistema ontologico è pensato per supportare sia l’utilizzo e la fruizione dei contenuti didattici da parte dell’utente, che l’elaborazione automatica degli stessi da parte di uno o più agenti software. Il sottosistema di Intelligenza Artificiale (IA) potrà fornire servizi guidati dal reasoning sulle varie rappresentazioni semantiche. L’integrazione del sottosistema di Intelligenza Artificiale può essere pensato a due livelli distinti:
1. integrazione funzionale: il primo passo è fornire servizi di IA come la verifica della correttezza dei corsi o una rudimentale sequenziazione dei learning Object. Questi servizi potranno essere genericamente acceduti dall’utente mediante opportune interfacce grafiche ed opportuni protocolli di interfaccia, tra cui ricordiamo SOAP.
2. integrazione strumentale: ad un livello successivo di elaborazione è possibile progettare protocolli e dinamiche di interazione del sistema di IA con il resto del sistema che si basino sulle dinamiche operative dell’utente. In questo modo è possibile integrare i servizi i IA negli specifici tool per la composizione e la fruizione degli interventi formativi.
DocenteStudente
IA Service
Semantic Representation
Utente IA Interface
Browsing
Editing
Repository
(a)
DocenteStudente
Semantic Representation
Utente
Repository
Editing
Browsing
IA Service
(b) Figura 53 - i due diversi gradi di integrazione: mediante servizi genericamente messi a disposizione dell’utente (a) o mediante una pina integrazione all’interno dei tool di editing (b)
Generazione di reti semantiche Le evidenti disomogeneità tra le richieste di un sistema di tutoring Ontology-based e le necessità di incapsulamento dei metadati all’interno del repository rendono auspicabile la realizzazione di uno o più tool di conversione che mantengano aggiornate le due rappresentazioni. La rappresentazione RDF della base di conoscenza dovrà contenere:
Progetto VICE
Definizione dell’architettura della piattaforma 69
• Le informazioni generiche per l’identificazione della risorsa: questo può essere ottenuto in maniera naturale sfruttando la caratteristica rappresentazione delle risorse di RDF [76]. ogni risorsa viene identificata da un riferimento univoco tramite un URI. Incidentalmente, ed in questo caso ciò è altamente auspicabile, l’URI può coincidere con un URL per risorse effettivamente raggiungibili tramite la rete. Questo rende estremamente naturale il collegamento del modello con la risorsa fisicamente fruibile. In maniera del tutto duale rispetto a quanto avviene secondo l’approccio a metadati incapsulati, è il nodo della rete semantica a fare rifererimento alla risorsa: basta quindi utilizzare l’indirizzo URL del Learning Object come identificatore della risorsa all’interno del repository per ottenere una relazione implicita tra modello e dominio concreto.
• Le informazioni generiche di caratterizzazione della risorsa: queste informazioni, certamente presenti all’interno del database principale, riguardano aspetti di gestione ordinaria dei learning object. Tali informazioni riguardano, ad esempio, il versioning della risorsa, l’autore e la data di creazione della stessa ed il formato del learning object. Questa componente informativa ha per lo più uno scarso interesse per il modulo di IA, se non per le specifiche richieste della riproduzione e fruizione derivanti dal particolare formato della risorsa. Lo standard di riferimento per questa componente è il 52lin Core, che fornisce anche informazioni circa la tipologia di utenti a cui è rivolta la ricorsa [69]
• Informazioni specifiche per la didattica. In particolare lo standard 31 si propone come una raccolta di metadati ad uso pedagogico, in grado di rappresentare, tra le altre, le informazioni sulla difficoltà del materiale, i dettagli legati alla sua fruizione e la tipologia dell’intervento formativo. Queste informazioni sono assunte come facenti parte dei metadati presenti nel repository, dato che lo standard SCORM include il set di metadati 3.
• Informazioni semantiche. Nonostante la presenza di metadati per la classificazione, lo standard 3 non fornisce un supporto esplicito per la definizione degli argomenti tramite rimandi ad ontologie di riferimento [50]. Sarà quindi necessario rappresentare dell’informazione aggiuntiva, che colleghi i contenuti alle varie ontologie. Sono state proposte diverse metodologie per inserire ogni singolo LO in ontologie di vario tipo senza dover estendere 3 [65] [71] [46]. In realtà l’utilizzo di ontologie fornisce una grande libertà nel definire non solo i termini, ma anche le relazioni. Queste informazioni sono caratteristiche del sottomodulo di IA, ma possono essere utilizzate anche da altri sottosistemi (come ad esempio il sistema di ricerca dei LO).
La base di conoscenza a disposizione del sistema di IA sarà quindi parzialmente realizzata appositamente per tale sottosistema e parzialmente generata automaticamente a partire dalla descrizione principale presente nel database. Oltre alla parte riguardante la descrizione delle risorse, che deve essere tradotta con riferimento ad una opportuna ontologia di contenuto, è auspicabile interfacciare il sottosistema di IA con il modulo di profilazione utente. La base di dati relativi ad ogni studente dovrebbe contenere tre tipi di informazioni:
• Identificazione dell’utente: l’assegnamento di una login ad ogni studente, unitamente con l’URL dell’organizzazione a cui si riferisce l’iscrizione consente di ottenere facilmente un URI univoco per lo studente, che ben si presta ad essere utilizzato come identificativo in un modello RDF
• Caratteristiche e curriculum formativo: in questa sezione andranno inseriti i dati quantitativi dello studente, come i LO già fruiti, i risultati dei test che ha sostenuto, ecc.
1 Learning Object Metadata
Progetto VICE
Definizione dell’architettura della piattaforma 70
• Profilazione dell’utente: l’assegnamento di ogni utente ad una particolare tipologia permette di personalizzare il servizio erogato senza per questo dover parametrizzare eccessivamente i vari processi di elaborazione [62].
Il modello concreto dello studente può essere tradotto in un opportuno descrittore RDF aggiungendo informazioni pedagogiche che colleghino direttamente i livelli semantici della profilazione e del contenuto. E’ ad esempio opportuno tradurre i risultati oggettivi e quantitativi dei test in una relazione tra lo studente ed i concetti insegnati, che misurino qualitativamente la conoscenza e le abilità maturate dall’utente nei confronti di un corpus di concetti [57].
Figura 54 - schema funzionale di due tool di estrazione della conoscenza
DB Repository
Dati Utenti
Ontologia di contenuto
Ontologia dell’utente
LO Library
import LO
RDF repository
import profile
RDF user
Progetto VICE
Definizione dell’architettura della piattaforma 71
7 Profilazione utente e adattività Nel contesto del presente documento, il contributo che viene presentato, si pone come l’illustrazione delle specifiche e dei metodi di trattamento dei moduli didattici da parte di un agente automatico il cui scopo è l’erogazione adattiva [43, 44, 58] dei contenuti del repository basandosi sull’acquisizione delle caratteristiche e degli interessi dell’utente come sottoprodotto della navigazione e/o delle ricerche che l’utente effettua. Per erogazione adattiva dei contenuti, si intende un filtro che, prese in ingresso le richieste di materiale didattico al repository, ne isoli il contenuto che permetta una identificazione delle caratteristiche dell’utente (attività di profilazione utente), e, sfruttando il risultato di questa analisi, adatti la risposta del repository alla interrogazione interpretata secondo il profilo desunto. La parte adattiva del contributo trova naturale collocazione nel più ampio ambito del Wizard pedagogico, il cui scopo è orientare l’utente verso la fruizione guidata da meccanismi propri dell’Intelligenza Artificiale del contenuto del repository. Rispetto a tale finalità ed in cotal contesto, il filtro adattivo si pone come nesso tra i meccanismi di interrogazione tradizionale, basata su interrogazioni (query) ad un database, e gli strumenti di navigazione ed ricerca basati sulla conoscenza. Rispetto agli aspetti architetturali del progetto, il contributo fornisce un meccanismo avanzato di profilazione degli utenti, che, nel caso specifico del filtro, ne permette il comportamento adattivo, e che può essere usato per altre attività, tra cui l’analisi dei risultati ottenuti dagli utenti nel corso del reperimento dei dati di loro interesse, fornendo la base su cui costruire la valutazione dell’efficacia dei meccanismi di interrogazione di qualsivoglia guisa. Il comportamento adattivo, nel contesto precipuo del progetto, è finalizzato ad ottenere due scopi: 1. enfatizzare i contenuti didattici ottenibili a fronte di una richiesta da parte di un utente, a
seconda delle sue caratteristiche generali e del suo interesse momentaneo; 2. cogliere i cambi di contesto nell’interesse di un utilizzatore. Il primo aspetto serve per poter inquadrare i contenuti didattici (Learning Object – LO) nell’ambito degli interessi, sia strutturali che momentanei, dell’utente, rendendo quindi più facile ad usarsi la classificazione ontologica in metadati associata ad ogni LO. Questa accresciuta facilità avviene a scapito della generalità e complessità di interrogazione intelligente che l’ontologia mette a disposizione, e pertanto, il filtro costituisce un complemento a tale accesso alla conoscenza, e non un sostituto. La seconda finalità è indispensabile per calmierare l’automatismo del primo aspetto, preservando l’apprendimento incrementale delle caratteristiche dell’utente, ma annullando, nel momento opportuno, le informazioni raccolte sull’interesse momentaneo dell’utilizzatore. In questa visione, il comportamento adattivo si espleta nella sequenza di passi: 1. ricezione di una interrogazione Q verso il repository 2. analisi della query Q, ed estrazione delle informazioni di profilo P 3. aggiornamento del profilo utente in base alle informazioni P 4. inoltro della richiesta Q al repository 5. ricezione della risposta R dal repository 6. trasformazione di R in R’ in base al profilo dell’utente 7. inoltro della risposta R’ all’utente
Progetto VICE
Definizione dell’architettura della piattaforma 72
I passi 1, 4, 5 e 7 sono di natura prettamente tecnologica e dipendono esclusivamente dai canali di comunicazione tra i vari componenti architetturali del progetto, nonché dagli standard di rappresentazione utilizzati. I passi 2 e 3 richiedono una identificazione delle caratteristiche, reperibili in una query, che definiscano una informazione sull’utente, e richiedono manipolazione del profilo di un utente. Questi passi pertanto dipendono dalla rappresentazione delle query, dei profili e dagli strumenti atti a manipolare queste rappresentazioni, ovvero questi passi hanno una valenza tecnologica sussidiaria rispetto ai passi precedenti. Tuttavia, l’identificazione di quale informazione costituisce il profilo di un utente, la rappresentazione di questa informazione, partizionata in strutturale e di interesse momentaneo, la manipolabilità dei profili, in modo che siano aggiornabili conformemente agli obiettivi di adattività sopra esposti, costituiscono degli aspetti che richiedono una indagine cognitiva e matematica per poter essere efficacemente definiti. Il passo 6, che funge da naturale contraltare ai passi 2 e 3, evidenzia un aspetto precipuamente tecnologico nella sua necessità di manipolare la rappresentazione di una risposta del repository; tuttavia la sua definizione richiede una analisi cognitiva e matematica. Infatti, essendo adattiva la parte attiva del comportamento, per espletare la sua efficacia tale parte deve essere strettamente sincronizzata con le manipolazioni effettuabili nello spazio dei profili, da cui la necessità di una analisi del modello matematico indotto. Inoltre, per poter dare risultati coerenti con la descrizione di profilo desunta al passo 3, è necessario definire le trasformazioni effettuabili in termini di combinazione cognitiva tra l’ontologia del repository, che è rispecchiata nei metadati associati ai LO risultato della query, e l’ontologia soggiacente allo spazio dei profili. Sinteticamente, gli aspetti tecnologici sono di duplice natura: 1. le scelte che vengono definite dal modo in cui sono rappresentati i LO nel repository, il modo in
cui il repository stesso è interrogabile, il modo in cui l’ontologia dei metadati è definita, sono tutti fattori che introducono dei vincoli sul come il filtro possa funzionare. La definizione di questi aspetti costringe e permette al filtro di espletare la propria azione nel modo in cui opera.
2. le scelte sulla rappresentazione delle entità proprie del filtro, in particolare come sono definiti i profili e le trasformazioni sulle risposte dal repository, determinano l’azione del filtro. Queste rappresentazioni sono più sensibili nell’influenzare la capacità di espletare il comportamento adattivo desiderato.
La definizione matematica delle caratteristiche che determinano il comportamento adattivo, in particolare, il modellare lo spazio dei profili sicché sia immanente nella sua struttura il concetto di cambio di contesto negli interessi dell’utente, e, secondariamente, il collegare lo spazio dei profili allo spazio delle trasformazioni dei risultati, al fine di garantire una uniformità di comportamento a fronte di interessi similari, sono aspetti essenziali per ottenere un filtro adattivo che espleti la sua azione garantendo gli obiettivi che sono stati prefissi. Una analisi matematica di questi aspetti permette di eliminare l’aspetto informale dalla definizione del comportamento adattivo, stabilendo il medesimo su una base matematica, che, al contempo, renda più semplice la codifica tecnica del filtro, e ne permetta una valutazione precisa del
Progetto VICE
Definizione dell’architettura della piattaforma 73
comportamento in relazione agli obiettivi definiti all’inizio di questa sezione, ovvero al suo dover svolgere una trasformazione adattiva coerente. Gli aspetti cognitivi determinano in misura fondamentale il successo del comportamento adattivo. Essi sono riassumibili come l’individuare le caratteristiche che definiscono un profilo, come legare queste caratteristiche alle query, e come definire il contenuto semantico delle trasformazioni che devono intervenire sulle risposte dal repository. In questo contesto, usiamo il termine cognitivo per indicare il fatto che il definire i succitati aspetti implica una comprensione del dominio del problema, in particolare degli aspetti didattici cui il progetto nel suo complesso è destinato. Infatti, solo con una appropriata visione d’insieme di questi problemi, e desumendo le caratteristiche cui il filtro deve rispondere nonché il modo di fornire risposte coerenti rispetto al dominio di conoscenza del problema, è possibile ottenere un comportamento adattivo corretto e ragionevole.
7.1 Architettura Dall’analisi precedente, l’architettura del filtro adattivo risulta essere la seguente:
Esso è costituito da due algoritmi fondamentali: l’analyzer, che prende una richiesta dall’utente, ne estrae una variazione di profilo che applica al profilo corrente, ed il transformer, che prende la risposta alla interrogazione fornita dal repository e la trasforma a seconda dei dati presenti nel profilo corrente. Inoltre il filtro mette a disposizione un database di profili, che contiene le descrizioni dei profili degli utenti. Il filtro adattivo trova naturale collocazione nell’architettura complessiva del progetto: esso è posto in corrispondenza dei moduli che inoltrano le query al repository, e che da esso attendono risposte. In tal modo, l’azione del filtro adattivo sarebbe trasparente ai moduli di interrogazione, e quindi sarebbe a carico del filtro adattivo il non modificare le risposte del repository a fronte di attività che non siano la consultazione, quali, ad esempio le attività di authoring o di accesso ai metadati. In verità, questo problema, che implica la distinzione delle attività di consultazione e ricerca, e le attività di aggiornamento, manutenzione ed estensione del repository, è di limitato impatto sull’archittettura del filtro, essendo facilmente eliminabile con una opportuna comunicazione della
Filtro
Repository Profili
Analyzer
Transformer
Query
Risposta
Progetto VICE
Definizione dell’architettura della piattaforma 74
tipologia di sessione di lavoro da parte di un utilizzatore, informazione che deve essere presente nella sessione di lavoro del medesimo, la quale può, e deve, essere utilizzata dal filtro per la profilazione.
7.2 Profilazione utenti La costruzione dei profili degli utenti, a causa del comportamento adattivo atteso, è un processo in due passi: ogni utente ha un profilo base, che ne determina le caratteristiche iniziali, e questo profilo base subisce delle mutazioni nel tempo a seconda delle interrogazioni al repository che l’utente svolge nel corso del tempo. La definizione delle caratteristiche che concorrono a formare il profilo di un utente è un processo che integra informazioni utilizzate in molti dei contesti in cui progetto trova attuazione. Infatti, informazioni che entrano a far parte del profilo sono quelle che caratterizzano sia gli aspetti di interesse dell’utente, sia le sue caratteristiche strutturali, quali, ad esempio, le disabilità, per cui è necessario erogare i contenuti in modo particolare. Nel prosieguo, definiremo caratteristiche dell’utente quelle sopracitate come strutturale, in contrasto con le caratteristiche dotate di un corrispettivo nella ontologia del repository, essenziali per caratterizzare gli interessi dell’utente in rapporto all’offerta formativa rappresentata dal patrimonio dei LO. In ogni caso, per poter cogliere l’aspetto adattivo corrispondente ad una variazione di interesse dell’utente, è necessario dividere le caratteristiche che definiscono il profilo in due componenti strutturate: la prima rappresenta l’identità dell’utente, mentre la seconda ne modella gli interessi. Con il termine identità si vuole cogliere quell’insieme di caratteristiche che, in rapporto all’interazione con il repository, restano costanti nel tempo, anche se possono non essere note all’atto della creazione del profilo base, e che quindi definiscono, in un certo senso, la visione dell’utente che il software può avere. Invece le caratteristiche di interesse sono quelle che cercano di cogliere il momentaneo dell’interazione con l’utente, ed, in particolare, quali aspetti nell’ontologia complessiva del repository sono al momento corrente, sotto esame da parte dell’utente. In questo senso, sia aspetti matematici che aspetti cognitivi sono coinvolti nella definizione delle caratteristiche che vanno a definire un profilo. I primi aspetti determinano in modo sostanziale i vincoli che la rappresentazione dello spazio dei profili deve soddisfare per permettere l’esibizione del comportamento adattivo cercato; i secondi aspetti determinano sia la significatività dell’azione adattiva, sia la ricchezza espressiva dei profili, in modo che possano essere efficacemente usati anche dai componenti sviluppati da altre unità di ricerca. Entrambi gli aspetti, per la loro peculiarità ed importanza saranno discussi separatamente. La questione della rappresentazione dei profili dipende dal modo in cui sono definiti per mezzo delle loro caratteristiche. Tuttavia, per i vincoli architetturali e tecnologici ogni profilo sarà rappresentato come un opportuno documento XML, il cui schema è conforme agli standard usati per rappresentare i metadati [45, 51], poiché l’interazione sugli interessi dell’utente può essere gestita solo mediante la condivisione semantica della conoscenza tra l’ontologia del repository e le caratteristiche dei profili che sono deputate a caratterizzare l’aspetto transiente dell’interazione con l’utente. In modo analogo, ed, in un certo senso, simmetrico (vide aspetti matematici nel seguito), lo spazio delle trasformazioni che devono operare sulle risposte del repository per fornire il comportamento
Progetto VICE
Definizione dell’architettura della piattaforma 75
adattivo cercato, sarà rappresentato da un insieme di documenti basati su tecnologia XML. Lo scopo è fare in modo che il documento rappresentante una trasformazione venga applicato al profilo dell’utente, generando un secondo documento che identifichi univocamente la trasformazione da applicare alla risposta fornita dal repository. La tecnologia suggerita dalla descrizione funzionale or ora data è, evidentemente, l’uso di stylesheet XSLT, il cui vantaggio è la totale standardizzazione e compatibilità con tutti gli strumenti adottati nel progetto, essendo lo strumento standard per manipolare documenti XML in un contesto di filtraggio.
7.3 Aspetti matematici Come visto in precedenza, un profilo è costituito da due insiemi di caratteristiche: gli attributi che definiscono l’utente in se, e gli attributi che ne specificano gli interessi momentanei. La modellazione che si propone è quella che definisce lo spazio dei profili Π come il prodotto, in senso topologico [61], dello spazio delle caratteristiche dell'utente Υ e dello spazio degli interessi momentanei Ι. Gli spazi topologici Υ ed Ι sono definiti come spazi metrici, dotati di opportuna norma, e quindi anche lo spazio Π risulta essere uno spazio metrico normato in modo canonico. E’ ragionevole imporre che lo spazio Π sia uno spazio di Banach, ovvero in cui ogni successione monotona converga uniformemente nel senso di Cauchy. Intuitivamente, questa assunzione corrisponde a richiedere che, a fronte di una successione, potenzialmente infinita, di richieste al filtro adattivo tutte “vicine”, ossia in cui il focus di interesse si raffina via via, allora anche il profilo individuato risulta essere man mano sempre più “esatto”, cioè specchio fedele degli interessi dell’utente. Quindi l’algoritmo analyzer del filtro adattivo risulta essere un estrattore di informazione dalla query al repository che fornisce un ∆ da sommare al profilo dell’utente richiedente; se il profilo corrente modificato da ∆ risulta essere nella bolla di diametro fissato δ che corrisponde alla soglia che identifica il mantenimento dell’interesse corrente, allora il profilo deve essere aggiornato da ∆, altrimenti deve essere aggiornata solo la parte del profilo corrispondente alle componenti in Υ. Questa succinta descrizione, in realtà corrisponde ad un modello matematico dello spazio dei profili piuttosto ricco, seppur semplice, che consente la sintesi dell’algoritmo analyzer indipendentemente dagli aspetti cognitivi, il cui significato operativo diviene usabile dal filtro attraverso il processo estrattivo che si compie sulla query. Caratteristica fondamentale di questo modello dello spazio dei profili, è la garanzia dell’aspetto di adattamento dei profili alle variazioni delle richieste dell’utente, in modo coerente e matematicamente provabile, quindi, costituendo una base solida da cui generare il comportamento automatico che il filtro espleta. Lo spazio delle trasformazioni applicabili alle risposte è parametrizzato dai profili: ad ogni trasformazione possibile corrisponde una famiglia di trasformazioni concrete, una per possibile profilo. Quindi lo spazio dei profili è l’unione disgiunta di questi insiemi di trasformazioni concrete.
Progetto VICE
Definizione dell’architettura della piattaforma 76
Ogni componente dello spazio dei profili, ovvero ogni famiglia di trasformazioni concrete, indicizzate da profili distinti, ma con in comune la medesima matrice algoritmica, induce uno spazio di Banach sull’insieme delle risposte. Questo è ottenuto corredando lo spazio delle risposte con una metrica che dipende dall’algoritmo accomunante le trasformazioni concrete, ed imponendo un vincolo che lega la nozione di distanza nello spazio dei profili alla nozione di distanza nello spazio delle risposte indotto. Intuitivamente, questa imposizione corrisponde a dire che la stessa variazione di profilo induce la stessa variazione sulla trasformazione delle risposte, ovvero che la variazione di profilo è della stessa entità della variazione tra le risposte trasformate a partire dal medesimo documento. La succitata proprietà garantisce la proprietà di smoothness degli spazi dei profili e delle trasformazioni, ovvero che a piccole variazioni di un profilo corrispondano piccole variazioni delle risposte. Inoltre, la struttura matematica dello spazio delle genera, in modo relativamente semplice tutti i vincoli utili per garantire una risposta adeguata del filtro nel senso del comportamento adattivo atteso. Il modello matematico accennato è un modo auspicabilmente generale per affrontare il problema di costruire filtri adattivi il cui comportamento sia garantibile matematicamente: ci aspettiamo che l’analisi svolta in questo senso nell’ambito del progetto VICE fornirà gli strumenti ed i metodi per generalizzare l’approccio suggerito a comportamenti adattivi più complessi.
7.4 Aspetti cognitivi Il modello matematico soggiacente all’azione del filtro adattivo garantisce che, se si modellano opportunamente le caratteristiche degli utenti e degli interessi allora lo spazio delle trasformazioni possiede il carattere necessario per garantire il comportamento corretto del filtro stesso, nel senso del rispetto delle caratteristiche di convergenza e di smoothness. E’ evidente che il modello può essere applicato solamente se le caratteristiche individuate per descrivere gli utenti, siano al contempo tali da generare la struttura matematica richiesta e tali da integrarsi con l’ontologia del repository. Il primo aspetto, ovvero la coerenza con il modello matematico, risulta essere non problematica, date caratteristiche strutturali del modello stesso. Per raggiungere lo scopo nel secondo aspetto, è necessario analizzare attentamente le caratteristiche degli utenti e degli interessi legando entrambe all’ontologia che si utilizza per classificare i LO messi a disposizione dal repository. Per effettuare questa analisi occorre porre in atto una conoscenza specifica degli aspetti didattici che devono guidare l’azione del filtro. Tecnicamente la soluzione che stiamo analizzando consiste in una rappresentazione dei profili come un vettore di attributi, uno per caratteristica ontologica, i cui valori siano dei “voti” in quella caratteristica. Questa rappresentazione genera naturalmente uno spazio di Banach, essendo un parallelepipedo nell’usuale spazio euclideo multidimensionale. Ovviamente, non essendo i concetti su cui è basata l’ontologia tra loro indipendenti, la rappresentazione dei profili non costituisce una base dello spazio, bensì ne rappresenta un appiattimento, e quindi rientra pienamente nella matematica usata per modellare l’azione del filtro.
Progetto VICE
Definizione dell’architettura della piattaforma 77
Un altro aspetto che riguarda la conoscenza sul dominio del problema, è la definizione del diametro della bolla che costituisce la soglia di discriminazione per definire un cambio di contesto nell’interesse momentaneo dell’utente. In realtà, la soluzione cui intendiamo porre mano considera questo diametro variabile, a seconda dei parametri del profilo cui viene applicato per proiezione. In tal modo è possibile tenere conto delle connessioni tra gli attributi e della reciproca influenza che questi esercitano tra loro, compensando gli effetti dovuti alla dipendenza tra attributi. La definizione precisa del diametro, anche in questo senso esteso, quindi non può prescindere da una valutazione della distanza tra concetti, e quindi richiede l’apporto di un esperto nella realizzazione di strumenti di e-learning per poter scaturire da una comprovata esperienza sul campo. Riguardo allo spazio delle trasformazioni, per poter garantire la funzionalità del filtro adattivo ai fini complessivi del progetto, e per poterne misurare l'efficacia, restringeremo la nostra attenzione a due classi di trasformazioni che riteniamo interessanti per gli aspetti: una classe di trasformazioni che ordina un insieme di LO a seconda della loro aderenza al profilo (al variare del concetto di aderenza, varia la trasformazione), ed una classe di trasformazioni che, preso un singolo LO ne modifica i metadati per riportarli all’interno delle caratteristiche pregnanti del profilo dell’utente, mediante le relazioni che sussistono tra gli elementi dell’ontologia del repository. Esempi: supponiamo che l’utente abbia nel suo profilo le seguenti caratteristiche: interesse per Java, essere un docente di Informatica, interesse verso la progettazione di software. 1. un esempio di trasformazione della prima classe è il seguente: a fronte della richiesta dei LO che
trattano di Java, ne ordina la sequenza che costituisce la risposta ponendo per primi quelli che trattano di modellazione dei dati con Java, per secondi quelli che trattano di programmazione con Java, e per ultimi, ad es., quelli che sono rivolti agli studenti di Scienze della Comunicazione.
2. un esempio di trasformazione della seconda classe è il seguente: a fronte della richiesta del LO che tratta di modellazione di dati con Java, il suo attributo “modellazione di dati” viene convertito in “progettazione di software”, essendo il secondo concetto inclusivo del primo, e presente nel profilo dell’utente.
Anche con le limitazioni proposte sulle trasformazioni, la cui natura comunque soddisfa il modello matematico accennato in precedenza, per poter garantire un comportamento adattivo equilibrato, la competenza prima necessaria alla sintesi concreta delle trasformazioni risiede nella esperienza di utilizzo di strumenti di e-learning e nella esperienza nello sviluppo dei loro contenuti. Inoltre, è opportuno sottolineare come l’analisi di questi aspetti costituisca un ulteriore fattore aggregante rispetto al progetto complessivo, imponendo la coordinazione delle competenze sulle metodologie didattiche al fine di avere, in ogni parte del progetto VICE, una uniformità di intenti e metodi, che si espletano in modo differente, per poter, coralmente, dare uno strumento innovativo di supporto alla didattica in un contesto reale.
7.5 Aspetti tecnologici Le scelte tecnologiche che occorre operare per poter realizzare il filtro adattivo, dipendono in misura essenziale dalle scelte tecnologiche che sono state effettuate per gli altri componenti del progetto VICE.
Progetto VICE
Definizione dell’architettura della piattaforma 78
Analizzando le principali scelte tecnologiche che sono state proposte dalle altre unità di ricerca, possiamo definire, in modo più o meno completo, quali requisiti e vincoli sono imposti sul filtro adattivo affinché questo possa operare nell’ambiente del sistema VICE. La prima scelta rilevante è il metodo di rappresentazione dei metadati [45, 51, 52, 54]: dal punto di vista del filtro adattivo è importante la scelta di XML [1] come linguaggio di rappresentazione dei metadati [52, 66, 67], eventualmente in una sua specializzazione quale SCORM [39] o 3 [60]. L’utilizzo di tecnologia basata su XML qualifica il progetto VICE come un esempio di entità del Semantic Web, ed il filtro adattivo ne è un esempio, usando come tecnologie portanti XML [1, 72], XSLT [49, 48], RDF [45, 73] ed OWL [75, 76, 77]. Questo requisito del filtro adattivo è importante per garantire la trattabilità dei dati manipolati dal filtro adattivo in un contesto il più vasto possibile; inoltre, questo requisito consente la riusabilità del filtro stesso in altri contesti e su dati di natura anche molto differente, pur di cambiare la sua base di conoscenza, ovvero rivedendo i suoi aspetti cognitivi. La seconda scelta rilevante è il metodo di rappresentazione dei collegamenti tra LO; infatti il concetto di link tradizionale appare inadeguato per molti motivi tra cui il fatto che non permette di scatenare una azione adattiva efficace, essendo semanticamente povero. La soluzione proposta al momento, ovvero rappresentare i link come query, appare essere la migliore per garantire l’azione adattiva trasparentemente agli altri componenti del sistema, e quindi garantire l’uniformità di azione del filtro su tutti i LO consultati. La terza scelta rilevante è la tecnologia di sviluppo delle soluzioni software: pur operando con XML [40, 63, 1] e la famiglia completa di rappresentazioni correlate (RDF [45, 73], OWL [75, 76, 77], SMIL, …), che garantiscono l’indipendenza dei dati dalla particolare soluzione di programmazione adottata, infatti, alla fine sarà necessario avere un sistema di deployment che dovrà rendere evidente il lavoro svolto dai vari gruppi di ricerca e quindi funzionare erogando effettivamente il servizio per cui il progetto VICE è stato concepito. Nella analisi presente in questo documento abbiamo assunto implicitamente che il linguaggio di query sia in effetti un sottoinsieme di Xquery e di Xpath, in modo da poter essere analizzato attraverso gli strumenti di parsing di XML. In realtà la necessità del filtro è il poter associare una opportuna informazione semantica, anche quantitativa, in termini di concetti attivati da una query, pertanto è necessario che la query stessa venga rappresentata in un modo che la renda confrontabile con l’ontologia dei concetti affinché il suo significato possa essere analizzato in termini di conoscenza sul dominio dei LO. Questo non è un vincolo imposto dal filtro all’intero progetto VICE, in quanto lo stesso problema si ripropone nel caso dell’analizzatore di query del repository, che dovrà inferire dall’ontologia la soddisfacibilità di una query rispetto ai metadati, e quindi dovrà selezionare, all’interno del database dei LO quali oggetti soddisfino i criteri espressi dalla richiesta. Per quanto riguarda la rappresentazione dei profili, verrà adottato un opportuno XSchema che consentirà di costruire un documento XML per ogni profilo, in modo da rispecchiare le caratteristiche che definiscono l’utente e le caratteristiche che definiscono l’ontologia dei concetti adottata dal repository, che supporremo descritta in OWL.
Progetto VICE
Definizione dell’architettura della piattaforma 79
Il database dei profili, infine, verrà rappresentato su un opportuno database XML, sia esso quello centrale del repository, sia invece locale al filtro, a seconda delle necessità che risulteranno da una successiva fase di integrazione dei componenti software. La rappresentazione delle trasformazioni avverrà per mezzo di XSLT [49, 48, 74], in modo che gli aspetti cognitivi siano isolati dal codice del filtro, e possano essere tutti rappresentati per mezzo di componenti riconducibili ad XML.
7.6 Stato del contributo L’azione di ricerca sul filtro adattivo è effettuata su tre fronti: 1. Definizione degli aspetti matematici che inducono il comportamento adattivo atteso; 2. Costruzione del filtro, e conseguente integrazione con le altri componenti del progetto; 3. Analisi cognitiva del comportamento adattivo, e conseguente sviluppo di una base di
conoscenza che il filtro utilizzi per svolgere il proprio compito. Allo stato attuale del progetto, la prima componente è stabilmente definita, e in corso di integrazione con la seconda, da cui attendiamo i risultati sperimentali per attivare la fase di disseminazione dei risultati, relativamente a questo contributo. L’attuale sforzo è concentrato sulla seconda e terza attività, che ci attendiamo, dovranno a breve iniziare a mostrare le prime evidenze sperimentali.
Progetto VICE
Definizione dell’architettura della piattaforma 80
8 Valutazione e validazione dell’usabilità La rapida introduzione delle più recenti tecnologie nelle case e sui luoghi di lavoro, unitamente all’incremento di connettività attraverso internet e telefonia mobile, consente di mettere a disposizione ovunque ed in ogni momento informazioni e conoscenze, non solo finalizzate a soddisfare il bisogno di informazioni ma sempre più spesso rivolte anche all’apprendimento. Seminari, conferenze e addirittura interi corsi specialistici sono sempre più spesso disponibili in rete o su supporto CD-Rom. Contemporaneamente a questo aumento dell’offerta da parte del settore informatico è anche aumentata la domanda da parte del mondo del lavoro: per molte aziende è attualmente necessario disporre di una forza lavoro altamente competente e geograficamente distribuita, il che rende sempre più necessarie innovazioni rivolte alla creazione di una conoscenza realmente distribuita, accessibile e utilizzabile (in termini di efficacia, efficienza e soddisfazione). Soloway ha identificato come nuova sfida nella comunità di Human-Computer Interacion (HCI) l’uso dei computer a “supporto di individui o di gruppi di individui durante la fase di sviluppo di una più ricca e più approfondita conoscenza delle attività delle loro professioni” [34]. Se i ricercatori di HCI hanno dedicato molta attenzione a migliorare l’usabilità dei sistemi informatici, la sfida attuale è di andare oltre le problematiche dell’usabilità, tipica dei software generici, e di iniziare ad esplorare la progettazione di sistemi che supportano le persone che stanno sviluppando esperienza in un nuovo e sconosciuto work practice, inteso come le responsabilità, i task, gli artefatti, la terminologia, la conoscenza, e le relazioni coinvolte in una data attività di lavoro. La sfida di usare i computer per “rendere la gente più brava” assicura una prospettiva di progetto diversa, che coinvolge l’evoluzione della progettazione learner-centered (LC) per considerare in modo significativo i bisogni dei discenti. La nozione di progettare tool centrati sui bisogni dei discenti è diventata più popolare negli ultimi anni, e molti ricercatori stanno esplorando questo nuovo campo. Le soluzioni proposte finora sono però abbastanza ad hoc per situazioni specifiche. La comunità HCI ha bisogno di sviluppare tecniche e metodologie di progetto che supportino il progettista nella costruzione di software LC. Il lavoro dell’unità di Bari è essenzialmente rivolto ad identificare, in una metodologia di Learner-Centred Design (LCD), le tecniche più appropriate la valutazione di sistemi di e-learning, non solo per quanto riguarda l’usabilità delle interfacce utente ma possibilmente anche per quanto riguarda l’efficacia dell’apprendimento. Il lavoro del primo anno è stato:
- Analisi dello stato dell’arte su LCD - analisi di utenti e attività di lavoro che il software deve supportare - studio degli utenti mentre analizzano sistemi di e-learning già disponibili. Ciò allo scopo di
capire la difficoltà che incontrano, i problemi delle piattaforme attuali e trarre indicazioni per un progetto più efficace.
In questo documento si descrive il lavoro effettuato nel primo anno di attività. In particolare, riguardo al punto 1, nella sezione 6.1 si riporta un confronto tra caratteristiche di LCD e User-Centred Design (UCD) e in sezione 6.2 si descrivono le principali caratteristiche di LCD che risultano dall’analisi dello stato dell’arte. Con l’obiettivo di identificare metodi di valutazione specifici per l’e-learning, nella sezione 6.3 e sue sottosezioni, dopo aver riportato le classiche definizioni di usabilità, si discute l’usabilità per l’e-learning e si propone di specializzare la tecnica di ispezione SUE [23] alla valutazione di sistemi di e-learning. Nella sezione 6.4 si descrive uno studio effettuato con utenti che utilizzano sistemi già disponibili allo scopo di raffinare tali euristiche e di identificare linee guida per la valutazione di sistemi di e-learning, come descritto in sezione 6.5.
Progetto VICE
Definizione dell’architettura della piattaforma 81
8.1 Learner-Centred Design vs User-Centred Design I tool LC si rivolgono ai bisogni dei discenti: persone che sono usualmente novizie in un dato work practice, siano essi studenti o adulti che lavorano ed hanno bisogno di migliorare la loro formazione. Ci sono varie differenze tra la progettazione di software user-centered e quella di software di formazione LC. Nel caso di generico software user-centered, lo sforzo di apprendimento da parte dell’utente è solo nella comprensione delle funzionalità del tool. Nel caso di software LC i discenti, oltre ad imparare il tool con il quale lavorano, devono anche apprendere un nuovo work practice. Nel tradizionale progetto user-centered, gli utenti sono considerati esperti nel work practice, essi hanno bisogno dei computer solo per eseguire i loro compiti in maniera semplice ed efficiente [24]. Contrariamente, i discenti sono novizi in un work practice e hanno bisogno di strumenti che tengano conto della loro mancanza di conoscenza e di supporti che li aiutino ad apprendere un nuovo work practice. I discenti si possono caratterizzare nel seguente modo [35]: Non posseggono una quantità significativa di conoscenza nel work practice, cioè non condividono la conoscenza delle attività, della terminologia e di tutto ciò che riguarda il work practice. Sono eterogenei: i discenti non necessariamente condividono la stessa cultura, la stessa formazione di base, la stessa esperienza, gli stessi stili di apprendimento. Per questo motivo i tool LC hanno bisogno di considerare un’ampia diversità nella popolazione di utenti. Nel tradizionale approccio user-centered, il problema centrale è il gap concettuale tra l’utente e il tool, ciò che Norman modella con i concetti di “golfo di esecuzione” e “golfo di valutazione” [27]. Questi golfi non possono essere ignorati nell’approccio LC, dal momento che i discenti certamente devono essere capaci di usare i tool progettati per i loro bisogni. Tuttavia, nell’approccio LC, il problema centrale non è il gap concettuale fra utente e tool, ma piuttosto è il gap concettuale tra il discente e il modello di conoscenza realizzato da un esperto del work practice (“golfo di esperienza”). Un discente ha bisogno di capire che tipo di attività deve fare, gli argomenti che riguardano la pratica, la conoscenza necessaria a completare le attività di lavoro e così via. In altre parole, il discente ha bisogno di sviluppare un modello concettuale corretto e appropriato del lavoro che deve svolgere. La “dimensione” del golfo di esperienza descrive quanto un discente è lontano dalla conoscenza del work practice. La dimensione del golfo di esperienza è proporzionale alla quantità di cambiamento concettuale del modello del work practice del discente. I tool LC possono supportare il discente nella fase di apprendimento attraverso l’uso di scaffolding. Gli scaffold sono caratteristiche del software che supportano l’esecuzione di un dato compito o attività da parte di qualcuno che è novizio in quel compito o attività. È dunque necessario sviluppare una teoria per il progetto di scaffold efficaci. Soloway sottolinea che, come nel progetto di sistemi user-centered si può essere guidati dalla “teoria delle azioni” di Norman [27], nel progetto LC è necessario sviluppare una teoria che aiuti a capire la nozione di “acquisire esperienza” e poter quindi sviluppare principi che siano alla base di un progetto LC. Le teorie di apprendimento costruttiviste e socio-costruttiviste possono aiutarci a descrivere la natura dell’esperienza che si sta considerando e a definire un modello che aiuti i discenti a superare il golfo dell’esperienza [34, 36]. L’approccio costruttivista riconosce che l’apprendimento non è un semplice processo passivo di trasferimento d’informazione dall’esperto al novizio, al contrario è un processo attivo, che considera un approccio “learning by doing”, dove i discenti devono manipolare cognitivamente il materiale che stanno apprendendo per creare collegamenti cognitivi dal nuovo materiale alla loro propria conoscenza [29, 28]. L’approccio socio-costruttivista riconosce che l’apprendimento avviene quando i discenti lavorano in un contesto che permette loro di vedere e capire la cultura professionale del loro lavoro [18]. In base a queste due teorie, un tool LC utilizzato nel suo contesto reale dovrebbe concettualizzare (o visualizzare) i work practice in modo tale che il discente possa impegnarsi e capire le attività, il linguaggio, i termini e tutto ciò che concerne il work practice.
Progetto VICE
Definizione dell’architettura della piattaforma 82
I discenti hanno bisogno di aver accesso e partecipare ad attività simili a quelle che gli esperti svolgono in un determinato work practice [17]. Mancando ai discenti la conoscenza del work practice, si ha la necessità di un supporto aggiuntivo (scaffolding) che li guidi e/o li aiuti ad eseguire le loro nuove attività. Naturalmente, i discenti non possono usare gli stessi tool che usano gli esperti data la differenza del loro livello di conoscenza. Così un progettista LC deve progettare tool modellati sui tool degli esperti, ma semplificati per poter essere idonei ai discenti. Questi tool dovrebbero permettere ai discenti di partecipare alle attività in maniera il più simile possibile a quella degli esperti e permettere la costruzione di artefatti che verranno usati nel work practice. A mano a mano che il discente acquisisce esperienza nel work practice, lo scaffolding dovrebbe “attenuarsi” o scomparire. Un semplice esempio di scaffolding potrebbe essere costituito dall’uso di una guida in linea che, con messaggi sia testuali che vocali, possa guidare il learner, o il gruppo se è in atto una situazione di apprendimento cooperativo, nell’esecuzione di un compito intervenendo sempre meno, con una invasività che va via via diminuendo se il discente o il gruppo acquisisce competenza, ovvero il sistema gliela riconosce. Nella Tabella 1 vengono sintetizzate le dimensioni che caratterizzano il progetto LC.
Dimensioni Learner-Centred Design Utenti Discenti: novizi in un dato work practice Obiettivo principale Progettare tool che supportano i discenti nello
sviluppare una migliore conoscenza di un nuovo work practice
Gap concettuale da considerare
Golfo di esperienza fra discente e work practice(senza ignorare il golfo di esecuzione e di valutazione)
Approccio teorico per colmare il gap concettuale
Applicare teorie di apprendimento (costruttiviste e socio-costruttiviste)
Requisiti di un tool LC 1. Supportare i discenti nella partecipare ai nuovi work practice, incorporando nel tool scaffolding relativi al work practice
2. Supportare i diversi tipi di discenti: livelli di esperienza, stili di apprendimento, formazione di base, età, ecc.
3. Attenuare e progressivamente eliminare lo scaffolding a mano a mano che il discente acquisisce esperienza nel work practice
Implicazioni per il progetto Progettare tool che supportano i discenti nell’eseguire task autentici del work practice e che espongono gradualmente i discenti alla cultura (tool, task, linguaggio) del work practice
Tabella 1:Dimensioni del progetto LC
Un team di progetto LC ha bisogno di avere una conoscenza dettagliata del work practice, cioè i
progettisti hanno bisogno di avere un buon work model, una connessione tra il work practice e l’esperienza necessaria per impegnarsi nelle attività di tale work practice. Un buon work model da solo, comunque, non è sufficiente per un buon tool LC. Poiché il discente è novizio, il work model non può essere presentato così com’è, perché il discente non conosce il lavoro. Per risolvere questo problema, il team di progetto ha bisogno di concettualizzare il work model in maniera tale che il discente possa apprendere. Per questo motivo, il team di progetto ha anche bisogno di un educational model che descriva come il work model dovrebbe essere concettualizzato per meglio
Progetto VICE
Definizione dell’architettura della piattaforma 83
facilitare la costruzione di conoscenza del discente. Di conseguenza, il team di progetto LC ha bisogno di work experts (professionisti di un work practice) per studiare e analizzare il work practice e per creare un buon work model, e di educational experts (insegnanti, ricercatori) per distinguere i tipi di comunicazione con i discenti e guidarli nell’effettuare il cambiamento concettuale da discente a esperto.
Lo sviluppo dei work model e degli educational model è vitale. La collaborazione dei work expert e degli educational expert è necessaria nel processo di sviluppo di un tool LC per assistere il progettista, che ha la responsabilità sia di progettare un sistema usabile sia di realizzare le indicazioni dei work expert e degli educational expert (Figura 55).
Figura 55:Modelli concettuali e ruoli nel team Learner-Centered Design
8.2 Progettazione Learner- Centred Certamente molte delle tecniche tradizionali del progetto di software possono essere utilizzate in un progetto LC. Tuttavia, abbiamo anche bisogno di metodi specifici per l’approccio LC, che ci aiutino ad identificare e valutare le strategie di scaffolding che possono essere utilizzate. Nel tradizionale approccio user-centered, i requisiti del software definiscono quali funzioni il software deve avere per aiutare gli utenti a completare il loro lavoro in modo efficiente. Nel nuovo approccio LC, abbiamo bisogno di considerare altri tipi di requisiti. Precisamente, un “requisito LC” è un’area identificata in cui il discente ha bisogno di supporto per una certa attività di lavoro [31]. Per determinare i requisiti di un sistema LC, il team di progetto ha bisogno ancora di guide e metodi che lo aiutino loro a determinare:
- fino a che punto il discente può impegnarsi nell’attività - perché un discente ha bisogno di supporto per impegnarsi nell’attività - che tipo di conoscenza manca al discente - che tipo di supporto potrebbe essere utile al discente per impegnarsi nell’attività
La collaborazione con gli educational experts può aiutare a identificare metodi per definire requisiti per LCD in modo più formale e metodologico. Molte delle tecniche tradizionali del progetto user-centered possono essere utilizzate in LCD. Tuttavia, abbiamo bisogno di metodi specifici per LCD, che ci aiutino a scoprire le difficoltà che i discenti incontreranno, quando lavoreranno nel nuovo work practice. Preece et al. [30] descrivono due importanti fasi per il progetto del software:
- la fase di tipo concettuale: i progettisti determinano le strategie per individuare i requisiti del software;
Progetto VICE
Definizione dell’architettura della piattaforma 84
- la fase di tipo fisico: i progettisti determinano le istanze fisiche delle strategie concettuali del software.
Nell’approccio LC, nella fase di tipo concettuale si definiscono anche le strategie concettuali dello scaffolding che saranno utilizzate per individuare i requisiti del tool LC; nella fase di tipo fisico si implementano le strategie concettuali dello scaffolding nel tool LC in modo tale che i discenti possono capire ed eseguire l’attività supportata. Si presenta, quindi come una necessità di fatto, la definizione e l'applicazione di linee guida e di standard che permettano la realizzazione di uno strumento non solo usabile dal punto di vista dell’organizzazione, reperibilità e accessibilità dei contenuti, ma anche efficace dal punto di vista didattico. Bisogna sviluppare strategie efficaci di scaffolding che siano da guida, per esempio, alle seguenti problematiche:
1. Che tipo di scaffolding utilizzare per i diversi discenti 2. Che tipo di scaffolding può essere utile per attrarre e motivare i discenti nel loro percorso di
apprendimento; a questo scopo, i ricercatori informatici sono supportati da psicologi, insegnanti, che cercano di fornire strategie utili che supportino la motivazione del discente.
3. Quale è il modo migliore di rimuovere lo scaffolding: ci sono ancora molti problemi aperti riguardo la rimozione dello scaffolding, riguardo chi dovrebbe eliminare lo scaffolding, se il discente, l’insegnante, il sistema o una combinazione dei tre; quale è il meccanismo migliore per rimuovere gli scaffold, se le preferenze del discente o il controllo automatico del sistema, e così via.
8.3 Usabilità del software LC I tool LC hanno bisogno di essere usabili, un team LC certamente ha bisogno di osservare i principi di usabilità quando progetta software didattico, poiché certamente ad un tool non usabile mancheranno alcuni benefici che potrebbero essere indispensabili per i discenti. L’approccio learner-centered ha però anche bisogno di metodi di valutazione e di criteri che valutano i differenti effetti cognitivi risultanti dall’uso della tecnologia [33]. L’approccio user-centered si focalizza sull’efficienza, affinché gli utenti possano completare i loro compiti facilmente. Se un tool LC è troppo user-centered potrebbe essere troppo facile per il discente completare il suo compito. In questo caso, il discente potrebbe non essere forzato ad applicare lo sforzo cognitivo necessario per imparare il nuovo work practice, secondo quelli che sono i principi della teoria costruttivita. Per esempio, se consideriamo i software “wizard”, essi non si possono definire una buona tecnica LC, perché questi software fanno il lavoro che in realtà dovrebbe essere fatto dai discenti. I progettisti hanno bisogno di conoscere meglio come progettare tool usabili che permettono ai discenti di impegnarsi attivamente in un work practice. In particolare, la valutazione di un tool LC deve avvenire in modo diverso dalla valutazione di un software user-centered. Nei tradizionali sistemi user-centered, i progettisti si focalizzano sulla valutazione dell’uso del tool e considerano criteri di valutazione, quali il numero di errori che si commettono utilizzando il tool, il tempo impiegato per eseguire un task, ecc. Nella valutazione dei sistemi LC, c’è bisogno di valutare i singoli scaffold e le strategie di scaffolding, ma anche l’efficacia pedagogica totale del software, in modo tale da verificare quanto bene un discente apprende il work practice dopo aver usato il software.
8.3.1 Usabilità del software Attualmente è ampiamente riconosciuto che l’usabilità è un fattore cruciale della qualità delle applicazioni interattive. Differenti concetti sono usualmente associati alla nozione di usabilità. La definizione fornita da J. Nielsen si basa su una descrizione dettagliata degli attributi dell’usabilità [25]. Nielsen propone un modello nel quale l’usabilità è presentata come uno degli aspetti caratterizzanti l’accettabilità del sistema da parte degli utenti finali. L’usabilità non è una proprietà mono-dimensionale del sistema, ma è caratterizzata da cinque attributi: facilità d’apprendimento, cioè la facilità di apprendere le funzionalità e il comportamento del sistema; facilità d’uso, cioè il
Progetto VICE
Definizione dell’architettura della piattaforma 85
livello di produttività raggiungibile, dopo l’apprendimento del sistema; facilità di memorizzazione, cioè la facilità di ricordare le funzionalità del sistema, in modo che l’utente casuale può ritornare al sistema dopo un periodo di inattività, senza aver bisogno di capire nuovamente come utilizzarlo; basso livello di errori, cioè la capacità del sistema di aiutare gli utenti a non commettere errori durante l’uso, e nel caso si verificassero , dare la possibilità all’utente di risolvere facilmente; soddisfazione dell’utente che valuta quanto l’utente gradisce il sistema. Quest’ultimo attributo non deve essere sottovalutato in quanto un sistema gradevole da usare aumenta la produttività dell’utente. Un’altra definizione è fornita dallo standard ISO 9126 (“Software Quality Product Evaluation: Quality Characteristics and Guidelines for their use”) e riflette le prospettive dell’ingegneria del software sulla qualità dei prodotti software [20]. Nell’ISO 9126, la qualità generale di un prodotto software è decomposta in due categorie di criteri: I criteri che definiscono il concetto di qualità in uso, in termini di qualità del prodotto che sono esterne al prodotto software e che sono direttamente collegate al contesto d’uso, al profilo utente e alle motivazioni per cui il prodotto è usato. Questo concetto è fortemente collegato alla “qualità del prodotto dal punto di vista dell’utente”. In questi criteri si definiscono fattori come: l’efficacia (la completezza e l’accuratezza con cui un utente raggiunge i suoi obiettivi); la produttività (il rapporto tra risorse e efficacia); la sicurezza (la quantità di rischio per la salute dell’utente); la soddisfazione (il livello di contentezza che un utente ha durante e dopo l’uso del sistema). i criteri che definiscono le proprietà intrinseche di un prodotto, che possono essere analizzate prima che il prodotto sia rilasciato e indipendentemente dalla situazione d’uso. I fattori che vengono inclusi in questi criteri sono: la funzionalità (la quantità di funzioni contenute in un prodotto rilasciato); l’affidabilità (la capacità di un prodotto di mantenere i suoi livelli di performance sotto condizioni stabilite per un determinato periodo di tempo); l’usabilità (la misura di quanto un prodotto è adatto, facile e pratico da usare); l’efficienza (la quantità di operazioni -e più generalmente, risorse- da utilizzare per raggiungere un obiettivo); la manutenibilità (la misura in cui un prodotto è facile da testare, da modificare e estendere); la portabilità (abilità di spostare un prodotto da una piattaforma ad un’altra, il livello di conformità agli standard). Più specificatamente, nello standard ISO 9126 l’usabilità è ulteriormente suddivisa in cinque sotto-caratteristiche: comprensibilità (understandability), la capacità intrinseca del prodotto software di rendere di mostrare agli utenti la sua adattabilità ai vari compiti che devono essere svolti nel contesto d’uso; l’apprendibilità (learnability), la capacità intrinseca del prodotto software di aiutare l’utente ad apprendere facilmente le sue funzionalità; l’operabilità (operability), la capacità intrinseca del prodotto software di rendere possibile agli utenti l’esecuzione e il controllo delle sue funzionalità; attrattività (attractiviness), la capacità intrinseca del prodotto software di essere gradevole agli utenti; conformità (compliance), la capacità del prodotto software di aderire a standard, convenzioni e linee guida dell’usabilità. Questi fattori relativi all’usabilità sono collegati a quelli definiti in un altro standard, ISO 9241 (Ergonomic Requirements for Office Work with Visual Display Terminals) [21], che contiene delle linee guida per il progetto dell’interfaccia utente e fornisce requisisti e consigli che possono essere utilizzati durante il progetto e la valutazione di interfacce utente. L’ISO 9241 rivede e completa la definizione di usabilità data nell’ISO 9126. In questo standard, l’usabilità è intesa come strettamente dipendente da particolari circostanze in cui un prodotto è usato, cioè la natura degli utenti, i compiti che devono svolgere, e l’ambiente sociale e fisico in cui lavorano. Nella parte 11 di questo standard l’usabilità è definita come: “the extent to which a product can be used by specified users achieve specified goals with effectiveness, efficiency and satis53ion in a specified context of use ”. Per effectiveness (efficacia) s’intende accuratezza e completezza con cui utenti specifici raggiungono determinati obiettivi in specifici ambienti. Efficiency (efficienza) si riferisce alle risorse spese in relazione all’accuratezza e alla completezza degli obiettivi raggiunti. Satis53ion (soddisfazione) è definita come comfort e accettabilità del sistema da parte degli utenti. L’usabilità è quindi intesa come un obiettivo di alto livello del progetto di un sistema. Possiamo concludere che
Progetto VICE
Definizione dell’architettura della piattaforma 86
entrambi i concetti di qualità d’uso e di usabilità, come definito nell’ISO 9241, includono gli aspetti più significativi generalmente associati all’usabilità dalle comunità HCI.
8.3.2 Usabilità dei sistemi di E-Learning L’usabilità è relativa all'interfaccia di un sistema interattivo, per mezzo della quale l'utente si relaziona con il software. Va dunque sottolineato che l'usabilità ha senso solo in presenza di un utente e di una relazione d'uso e non esiste nel prodotto in sé. Compito degli studi di usabilità è fare in modo che il modello mentale di chi progetta il software (design model), corrisponda il più possibile al modello mentale del funzionamento del software così come se lo costruisce l'utente finale (user model). L'utente è messo al centro del processo di analisi e sviluppo. Nel caso specifico dell’e-learning, progettare un'interfaccia "usabile" significa comporre in un unico disegno metafore di interazione, immagini e concetti usati per veicolare funzioni e contenuti sullo schermo, creando un sistema di navigazione che non disorienti l'utente. Un software per formazione dovrebbe rappresentare un'esperienza gratificante per il discente dovrebbe possedere le seguenti caratteristiche:
- essere interattivo e fornire notevoli informazioni di ritorno (feedback); - avere obiettivi specifici; - essere motivante; - comunicare una continua sensazione di sfida (non così difficile da creare un senso di
frustrazione, né così facile da annoiare); - dare la sensazione di un coinvolgimento diretto; - fornire strumenti appropriati al compito e all'utente; - evitare distrazioni e fattori di disturbo che interrompano il flusso del lavoro.
Da qui la necessità di costruire interfacce chiare e coerenti, che permettano una navigazione semplice ed efficace, che mantengano quello che promettono e non mettano mai in situazioni da cui non si sappia come uscire. In altre parole, nella costruzione di un percorso didattico che sia efficace e motivante bisogna puntare alla semplicità e concentrarsi sulle esigenze e sugli obiettivi degli utenti, invece che su "effetti speciali" fini a se stessi. Sarebbe opportuno fornire linee guida operative per la progettazione e, secondo quanto definito nel “Human-Centred Design Process for Interactive Systems” (ISO 13407) [22], ogni alternativa di progetto deve essere valutata il prima possibile con i potenziali utenti del prodotto stesso. L'obiettivo del produttore di sistemi di e-learning è quello di assicurare che i prodotti software siano caratterizzati da: brevi tempi di apprendimento, rapida esecuzione dei compiti, percentuale di errore tendente a zero, facilità nel ricordare le istruzioni di base, alta soddisfazione dell'utente. Data la natura remota dell’e-learning, l’usabilità gioca un ruolo vitale per il suo successo. Un sistema di e-learning poco usabile ostacola l’apprendimento del discente, il quale sarebbe costretto a spendere più tempo nel cercare di capire come funziona il software piuttosto che nel cercare di capirne il contenuto. La valutazione di usabilità dei sistemi di e-learning potrebbe essere usata per isolare i problemi di apprendimento in particolari software di e-learning e proporre metodi per correggere questi errori [37]. L’usabilità di un sistema di e-learning è un concetto difficile da definire, date le diverse dimensioni e fattori che essa include. Studi recenti hanno dimostrato che i maggiori produttori di sistemi di e-learning non fanno test di usabilità sui loro prodotti, probabilmente perché i clienti non hanno modo di valutare il grado di usabilità del prodotto [FelO2]. D’altra parte, malgrado l’enorme quantità di denaro spesa sui prodotti per l’e-learning, nessun produttore di software verifica se il corso che ha sviluppato sia usabile o comunque utile. Tradizionalmente, i test di usabilità offrono un modo per garantire che un prodotto o un pezzo di software funzioni, cioè verificano se questo prodotto ha senso ed è facile da usare per gli utenti che ci devono interagire. In realtà, il primo ostacolo che si incontra nel verificare l’usabilità di un sistema di e-learning è quello di stabilire un insieme di principi, basati su risultati di ricerca
Progetto VICE
Definizione dell’architettura della piattaforma 87
accademica o industriale, in base ai quali stabilire se il sistema davvero funziona oppure no. Ma ciò ancora non esiste. Gli standard e i test di usabilità, che hanno trovato la loro rispettabilità per l’e-commerce ed altre applicazioni, hanno bisogno di essere rivisti prima di poter essere applicati all’e-learning: per esempio, gli strumenti per rendere navigabile e attraente un sito per prenotare un volo non possono essere applicati direttamente ad un corso di biologia on-line. Norman afferma che per l’e-learning, “L’apprendibilità del contenuto è più importante dell’usabilità”. E continua: “Molte tecniche utilizzate dalla comunità HCI, quali il learner-centered, il progetto iterativo, e la valutazione possono essere usate per favorire l’apprendimento.”[32]. Valutare l’apprendimento può portare i professionisti dell’usabilità fuori dalla loro originaria area di lavoro. Per rendere il loro lavoro efficace, essi dovrebbero collaborare con esperti di pedagogia, in modo da poter stilare una serie di linee guida pedagogiche che siano di aiuto alla valutazione dell’efficacia pedagogica del software.
8.3.3 Valutazione di usabilità per sistemi di e-learning Tra i vari approcci di valutazioni di usabilità, i metodi di ispezione sono molto popolari. Il loro vantaggio principale è comunque il risparmio di costi: essi non coinvolgono utenti né richiedono attrezzatura speciale o disponibilità di laboratori [25, 26]. Inoltre, gli esperti possono scoprire un’ampia gamma di problemi e possibili errori in un sistema complesso in un intervallo di tempo limitato. Per questo motivo, i metodi di ispezione sono stati ampiamente utilizzati negli ultimi anni, specialmente negli ambienti industriali [26a], dato che l’industria è ampiamente interessata a metodi efficaci che possono fornire buoni risultati pur essendo poco costosi. I metodi d’ispezione di usabilità coinvolgono solo i valutatori esperti, che ispezionano l’interfaccia utente con lo scopo di trovare possibili problemi di usabilità, fornendo giudizi basati sulla loro conoscenza, e facendo raccomandazioni per risolvere i problemi e migliorare l’usabilità dell’applicazione. I metodi di ispezione di usabilità sono più soggettivi, avendo una forte dipendenza dagli ispettori ‘skills’. Tra i metodi di ispezione, possiamo includere la valutazione euristica, cognitive walkthrough, l’ispezione formale di usabilità, le ispezioni sulla base di linee guida aziendali o di standard [26]. La valutazione euristica è il metodo più informale; coinvolge l’esperto di usabilità che analizza gli elementi di dialogo dell’interfaccia utente per valutare se sono conformi ai principi di usabilità, usualmente detti euristiche, da qui il nome del metodo. Essa prescrive di richiedere l’analisi del sistema da parte di un piccolo numero di esperti i quali valutano l’interfaccia, utilizzando una lista di principi di usabilità riconosciuti, le euristiche. Alcune ricerche hanno mostrato che la valutazione euristica è una tecnica di valutazione dell’usabilità molto efficiente, con un alto rapporto costo benefici, e per questo è riferita come uno dei cosiddetti metodi di usabilità economici. D’altra parte, la valutazione euristica, ed in generale i metodi di ispezione, hanno come svantaggio la soggettività e la forte correlazione tra qualità dei risultati ed esperienza del valutatore. Inoltre, un’altra limitazione è che tali tecniche si concentrano sulla valutazione delle interfacce grafiche, vale a dire su aspetti comuni alla maggior parte delle applicazioni interattive. Molti valutatori sono eccellenti nell’analizzare solo certe caratteristiche di un’applicazione interattiva; spesso, però, essi trascurano altre caratteristiche strettamente dipendenti dalla categoria specifica di un’applicazione e/o dal dominio applicativo. Allo scopo di identificare tecniche di valutazione di usabilità efficaci, sistematiche e contenute nei costi, negli ultimi anni è stata definita una metodologia di valutazione che è stata utilizzata soprattutto per applicazioni ipermediali. SUE (Systematic Usability Evaluation) è una metodologia di valutazione dell’usabilità, che combina metodi di ispezione con metodi empirici in modo sistematico, sfruttando le caratteristiche migliori di entrambi e riducendo gli svantaggi [23]. Il processo di valutazione considera attributi di usabilità più specializzati, in grado di catturare le caratteristiche di un’applicazione. SUE prescrive
Progetto VICE
Definizione dell’architettura della piattaforma 88
che ogni processo di valutazione inizi dall’ispezione dell’applicazione. Viene proposta una nuova tecnica di ispezione che si basa sull’uso di Abstract Task (AT), cioè pattern di valutazione che indicano gli aspetti dell’applicazione su cui focalizzare l’analisi. Dopo l’ispezione, se necessario, può anche essere effettuato un test con utenti reali per analizzare in modo più dettagliato eventuali aspetti problematici dell’applicazione. Il progetto del test utente è guidato quindi dai risultati dell’ispezione, essendo così più focalizzato ed efficace. Nella fase preliminare devono essere prese un certo numero di decisioni e devono essere eseguite due importanti attività:
- la definizione di un insieme di criteri da verificare durante la valutazione. - la definizione di un insieme appropriato di AT da applicare durante la fase di ispezione.
I criteri o principi di usabilità sono gli attributi in cui l’usabilità può essere scomposta, così da essere meglio analizzata. Gli Abstract Task sono modelli (pattern) di valutazione che forniscono una descrizione dettagliata delle attività che devono essere eseguite dai valutatori durante l’ispezione. Una lista di Abstract Task rappresenta una guida sistematica su come esplorare le caratteristiche rilevanti dell’applicazione, permettendo la standardizzazione dell’attività di ispezione. Molti valutatori sono eccellenti nell’analizzare solo certe caratteristiche di un’applicazione interattiva; spesso, però, essi trascurano altre caratteristiche strettamente dipendenti dalla categoria specifica di un’applicazione e/o dal dominio applicativo. Sfruttare un insieme di Abstract Task pronti per l’uso permette soprattutto a valutatori con poca esperienza di ottenere buoni risultati. Seguendo l’approccio proposto da SUE, stiamo sviluppando sia dei criteri di usabilità (o euristiche) che degli AT specifici per i sistemi di e-learning.
8.4 Interazione con i sistemi di e-Learning: uno studio pilota Allo scopo di scoprire i problemi che sorgono usando i sistemi di e-learning, è stato condotto uno studio coinvolgendo un gruppo di e-students, osservati mentre interagivano in una situazione reale con uno di questi sistemi.
8.4.1 Partecipanti e metodo Mediante la tecnica “thinking aloud”, dieci studenti di un Master tenuto presso l’Università di Bari sono stati osservati mentre interagivano con un sistema di DL (Distance Learning). I valutatori hanno preso nota di quello che ogni studente faceva e diceva. Poi, è stata eseguita un’intervista per reperire ulteriori informazioni riguardo all’usabilità del sistema. Le domande riguardavano le difficoltà incontrate durante l’utilizzo del sistema di e-learning, il modo migliore di organizzare il sistema (materiale educativo, servizi, test, etc.) e un’opinione riguardo ai tool di comunicazione usati (forum, chat, mail). Durante le ore del Master, gli studenti, accedendo tramite Internet al sistema DL e seguendo un percorso di apprendimento stabilito, dovevano apprendere alcuni nuovi argomenti studiando il materiale educativo riportato in una lista. I partecipanti potevano usare i tool di comunicazione della piattaforma per scambiarsi informazioni, per chiedere aiuto e per suggerire soluzioni. Alla fine, era previsto un test di auto-valutazione.
8.4.2 Risultati I partecipanti hanno affermato di non aver avuto problemi la prima volta che hanno usato la piattaforma di e-learning, poiché avevano fatto un breve corso di addestramento della durata di circa due ore. Ciò nonostante, l’osservazione effettuata ha dimostrato che i partecipanti hanno incontrato diverse difficoltà, nonostante avessero già familiarità con il sistema. Le difficoltà osservate sono correlate soprattutto al disorientamento, in particolare nell’utilizzo di un servizio per la prima volta. Dovendo seguire un nuovo percorso di apprendimento, a causa di problemi di scarsa auto-evidenza delle funzionalità del sistema, il discente si disorienta rapidamente e procede con difficoltà.
Progetto VICE
Definizione dell’architettura della piattaforma 89
Alcuni problemi sono dovuti all’assenza, nella piattaforma, di un meccanismo capace di attirare l’attenzione dell’utente sul materiale o sugli esercizi schedulati per una particolare sessione o unità del corso: probabilmente, è da attribuirsi a ciò se molti studenti hanno selezionato un’unità didattica sbagliata. È evidente che la presentazione del materiale didattico è un aspetto rilevante per l’usabilità di un sistema di e-learning. A tal fine, può essere utile evidenziare graficamente la struttura del corso e gli oggetti di maggior interesse in ogni lezione, fornendo così visivamente una mappa concettuale. Sarebbe anche opportuno consentire la personalizzazione dell’accesso al contenuto. I partecipanti hanno avuto problemi anche nella ricerca del materiale didattico da studiare: infatti, questo era elencato in una lista lunga due o più pagine, ma essi non hanno capito come spostarsi da una pagina all’altra. Così, non hanno potuto fare il download del materiale elencato nelle pagine successive alla prima. Quindi, la ricerca del materiale dovrebbe essere facilitata tramite un meccanismo di ricerca per parola chiave e il titolo assegnato al materiale dovrebbe essere esplicativo del contenuto. Inoltre, dovrebbe essere possibile usare la piattaforma offline senza perdere né la possibilità di utilizzo dei tool né il contesto del materiale educativo. Per esempio, quando gli studenti stanno seguendo un percorso ipermediale o stanno rispondendo alle domande di un test, l’interruzione della connessione non deve obbligarli a ricominciare dall’inizio. L’auto-valutazione prevista alla fine dell’osservazione ha permesso ai partecipanti di controllare i progressi ottenuti e questo è risultato molto motivante. Nel sistema, quindi, dovrebbe essere previsto un tool di authoring che faciliti la creazione dei test di auto-valutazione. I partecipanti hanno lamentato il fatto che la vista si affatica quando l’interazione con il sistema di e-learning si protrae a lungo. Perciò, il materiale educativo dovrebbe essere stampabile o, se interattivo, dovrebbe essere ridotto o fruibile in un intervallo di tempo più lungo. Infine, i partecipanti hanno espresso un giudizio positivo sui tool di comunicazione. Inoltre, questi tool permettono di gestire il processo di insegnamento per uno o più studenti, attraverso interazioni sincrone ed asincrone. Per di più, la comunicazione consente un apprendimento collaborativo. Dai risultati dello studio, appare chiaro che l’usabilità dell’e-learning è un argomento molto complesso. Sono stati considerati aspetti di presentazione, in particolare i suggerimenti di aiuto nel percorso di apprendimento. Inoltre, la presenza di tool ipermediali richiede la possibilità di personalizzare il percorso di lettura e la comunicazione per mezzo di differenti canali, pur evitando il disorientamento. Infine, dovrebbe essere incoraggiata l’iniziativa dell’utente: per esempio, i partecipanti hanno apprezzato il test di auto-valutazione per valutare i loro progressi. Tutti questi aspetti sono correlati non solo all’ambiente di e-learning, ma anche alla struttura del materiale didattico.
8.5 Studio di linee guida per la valutazione di usabilità di piattaforme di e-Learning Nella definizione di linee guida per la valutazione di sistemi di e-learning è necessario distinguere tra contenitore e contenuto. Infatti, alcuni attributi possono essere riferiti ad una piattaforma di e-learning, cioè ad un ambiente più o meno complesso con una serie di strumenti integrati per l’insegnamento e l’apprendimento e per la gestione di materiale didattico; invece, altri attributi sono specifici di un modulo educativo. Quindi, si tratta di due strade da percorrere parallelamente ed indipendentemente, in quanto vanno prese in considerazione caratteristiche diverse. Comunque, in entrambi i casi, è necessaria un’attenta analisi dei seguenti aspetti:
A. La presentazione che racchiude gli aspetti più esteriori dell’interfaccia, tramite i quali vengono fatti risaltare le possibilità e gli strumenti offerti dalla piattaforma o dal modulo educativo.
B. L’ipermedialità, in cui vengono considerati gli aspetti legati alla comunicazione attraverso diversi canali e secondo una struttura che può essere non sequenziale, ponendo l’accento sull’analisi e sulla personalizzazione dei percorsi di lettura.
Progetto VICE
Definizione dell’architettura della piattaforma 90
C. La proattività dell'applicazione che considera i meccanismi e le modalità con cui il sistema supporta la formazione del discente, e le attività che gli vengono sottoposte.
D. L’attività dell’utente che punta l’attenzione sulle necessità che sorgono nel discente durante l’interazione, quindi sulle attività che potrebbe voler compiere, e su come il sistema riesce a far loro fronte.
In questo rapporto, riportiamo i risultati relativi all’identificazione di attributi di usabilità e di linee guida relative alla piattaforma di e-learning, da cui i vari LO sono fruibili. Analogamente, nel documento CU03.00005 vengono riportate le linee guida per la valutazione di usabilità di LO. Presentazione L’aspetto di presentazione della piattaforma riguarda tutte le caratteristiche di visualizzazione dei tool e degli elementi che la compongono. In realtà, noi non dovremmo confondere la visualizzazione di tali elementi con la loro strutturazione e modellizzazione. Per l’aspetto di presentazione, sono state identificate le seguenti linee guida:
1. Evidenziare gli errori commessi ed il modo per non ricadervi 2. Le possibilità ed i comandi a disposizione dell’utente devono essere chiari 3. La struttura dei corsi deve essere visualizzata in maniera chiara.
Ipermedialità Nel contesto della piattaforma, la presenza di tool ipermediali è una caratteristica positiva: infatti, permettono di comunicare attraverso diversi canali (audio, video, testo), ma anche di organizzare le lezioni in modo non sequenziale permettendo così allo studente di scegliere un percorso logico di apprendimento differente da quello suggerito dal docente. Per l’aspetto di ipermedialità dei sistemi di e-learning, le linee guida identificate sono:
4. Permettere un agevole movimento tra i diversi argomenti evidenziando i riferimenti ad altri argomenti
5. Deve essere permessa la comunicazione attraverso diversi canali mediali 6. Deve essere possibile accedere in modo personalizzato ai contenuti 7. Si deve poter utilizzare la piattaforma off-line mantenendo il contesto di strumenti e
materiale educativo. Proattività dell’applicazione Un altro aspetto importante è quello della proattività dell’applicazione, che riguarda i tool offerti dalla piattaforma. La facilità d’uso di questi tool permette all’utente di concentrare i propri sforzi sul processo di apprendimento. Inoltre, bisogna evitare che l’utente commetta errori nell’utilizzo dei tool. Per l’aspetto che riguarda la proattività dell’applicazione, le linee guida sono:
8. Deve essere possibile inserire test di verifica ed esercizi 9. Deve essere previsti meccanismi legati alla prevenzione degli errori sulla piattaforma 10. I tool della piattaforma devono essere di facile utilizzo.
Attività dell’utente Infine, per l’aspetto dell’attività dell’utente le linee guida identificate sono:
11. Deve essere possibile effettuare verifiche e controllare i propri progressi in qualsiasi momento
12. Deve essere possibile integrare facilmente il materiale 13. Devono essere presenti meccanismi di indicizzazione e di ricerca per parola chiave o in
linguaggio naturale 14. Deve esistere un meccanismo di authoring che faciliti la stesura di verifiche.
Progetto VICE
Definizione dell’architettura della piattaforma 91
Bibliografia [1] “EXTENSIBLE MARKUP LANGUAGE 1.0”, W3C Reccomendation,
http://www.w3.org/TR/REC-xml , Febbraio 1998. [2] SCORM Documentation is avaible at “The Advanced Distributed Learning (ADL) Initiative”
, http://www.adlnet.org/ [3] IEEE 3 Working Group, http://ltsc.ieee.org/wg12/ [4] The UWA Project , www.uwaproject.org [5] Atlantis SpA, Robotiker, HOC-Politecnico di Milano, University of Linz, Technical
University of Crete, Universita' della Svizzera Italiana, University College of London: “Deliverable D2: General Definition of the UWA Framework”, www.uwaproject.org
[6] O.M.F. De Troyer, C.J. Leune, “WSDM: a user centered design method for Web site”, in Proc. Of Int. Conf. WWW7.
[7] W. Goedefroy, R. Meersman, O.M.F. De Troyer: “UR-WSDM: Adding User Requirement Granularity to Model Web Based Information System”. 1st International Workshop on Hypermedia Development, tenuto in contemporanea con Hypertext’98.
[8] Andrea Savigni, “Deliverable D6: Requirements Elicitation: Model, Notation, and Tool Architecture”, http://www.uwaproject.org
[9] A. van Lamsweerde. “Requirements Engineering in the Year 00: A Research Perspective.”, In Proceedings of ICSE’2000 – 22nd International Conference on Software Engineering, Limerick, 2000.
[10] HOC- Politecnico di Milano “Deliverable D7: Hypermedia and operation design : model, notation and tool architecture”, http://www.uwaproject.org
[11] Petrucco Corrado ,“Learning Object: un nuovo supporto all’eLearning”, IS-Informatica & Scuola, Anno X, N. 3, Novembre 2002
[12] Amato, F. Debole, F. Rabitti, and P. Zezula. YAPI: Yet another path index for XML searching. In ECDL 2003, 7th European Conference on Research and Advanced Technology for Digital Libraries, Trondheim, Norway, August 17-22, 2003, 2003.
[13] J. Clark, S. DeRose, XML Path Language (XPath) Version 1.0, W3C Recommendation, http://www.w3.org/TR/xpath, November, 1999.
[14] World Wide Web Consortium, “XQuery 1.0: An XML Query Language,” W3C Working Draft, August, 2002. http://www.w3.org/TR/2002/WD-xquery-20020816/
[15] Shareable Content Object Reference Model Initiative (SCORM), The XML Cover Pages, October 2001, http://xml.coverpages.org/scorm.html.
Nardi (Ed.), context and Consciouness: Activity Theory and Human-Computer Interaction. Cambridge, MA: MIT Press, 1996.
[18] Brown, J.S., Collins, A., and Duguid, P. Situated cognition and the culture of learning. Educational Researcher, Vol. 18, pp. 32-42, 1989.
[19] Feldstein, M. What is "usable" e-learning?. E-learn Magazine, Vol. 2002, Isuue 9, September 2002.
[20] ISO (International Organization for Standardization), ISO 9126: Software Quality Product Evaluation: Quality Characteristics and Guidelines for their use, 1992.
[21] ISO (International Organization for Standardization), ISO 9241: Ergonomics Requirements for Office Work with Visual Display Terminal (VDT) - Parts 1-17, 1997.
[22] ISO (International Organization for Standardization), ISO 13407: Human-Centered Design Process for Interactive Systems, 1998.
Definizione dell’architettura della piattaforma 92
[23] Matera, M., Costabile, M.F., Garzotto, F., and Paolini, P.. SUE Inspection: an Effective Method for Systematic Usability Evaluation of Hypermedia”. IEEE Transactions on Systems, Man and Cybvernetics- Part A, Vol. 32, N. 1, pp. 93-103, 2002.
[24] D.J. Mayhew, “The Usability Engineering Lifecycle”, San Francisco, CA: Morgan Kaufman Press, 1999.
[25] Nielsen, J. Usability Engineering. Academic Press, Cambridge, MA, 1993. [26] Nielsen, J., and Mack, R.L.. Usability Inspection Methods, John Wiley & Sons, New York,
1994. [27] Norman, D.A. Cognitive engineering”, in D.A. Norman and S.W. Draper (Eds.), User
Centered System Design. Hillsdale, NJ: Lawrence Erlbaum Associates, 1986. [28] Papert, S. The children’s machine: Rethinking school in the age of the computer. New York:
Basic Books, 1993. [29] piaget, j. The constrict of reality in the child. New York: Basic Books, 1954. [30] Preece, J., Rogers, Y., Sharp, H., and Benyon, D. Human-Computer Interaction. Reading,
MA:Addison-Wesley, 1994. [31] Quintana, C., Carra, A., Krajcik, J., and Elliot, S. Learner-Centred Design: Reflections and
new Directions. Human-Computer Interaction in tHe New Millenium. In Carroll (Ed.) ACM Press, New York: Addison-Wesley, 2001.
[32] Quigley, A. Usability-tested e-learning? not until the market requires it. Special to eLearn Magazine. Volume 2002 , Issue 2, February 2002.
[33] Sa3on, G., Perkins, D.N., and Globerson, T. Partners in cognition: Extending Human Intelligence with Intelligent Techonlogies. Educational Researcher, pp. 2-9, April 1991.
[34] Soloway, E., Guzdial, M., and Hay, K.H. Learner-Centered Design: the Challenge for HCI in the 21st Century, Interactions, Vol. 1, N. 2, 1994.
[35] Soloway, E., and Pryor, A.. The Next Generation in Human-Computer Intercation. Communication con ACM, Volume 39, n. 4, 1996.
[36] Soloway, E., Jackson, S.L., Kleim, J., Quintana, C., Reed, J., Spitulnik, J., Stratford, S.J., Studer, S., Eng, J., and Scala, N. Learning Theiry in pratice: Case studies in learner-centered design. Human 53ors in computing systems: CHI’96 Conference Proceedings. Reading, mA:Addison-Wesley, 1996.
[37] Wong, B., Nguyen, T., Chang, E., Jayaratna, N. Usability Metrics for e-Learning. Accepted to Workshop on Human Computer Interface for Semantic Web and Web Applications. Part of the International Federated Conferences (OTM '03).
[38] D.A. Wiley : “Connecting learning objects to instructional design theory: A definition, a metaphor, ad a taxonomy”, Utah State University, 2001
[39] ADL, “The Advanced Distributed Learning (ADL) Initiative”, http://www.adlnet.org/
[40] Armstrong E., Working with XML: “the Java API for XML Parsing (JAXP) Tutorial”, 2001, http://java.sun.com/xml/jaxp-docs-1.0.1/docs/tutorial
[41] T. Barners-Lee, J. Hendler, O. Lassila : “The Semantic Web”, Scientific American, 2001
[42] B.S. Bloom (ed.) : “Taxonomy of Educational Objectives. The Classification of Educational Goals” Handbook I, Cognitive Domain. New York: Longman, 1956.
[43] Brusilovsky P., Kobsa A., Vassileva J., Adaptive hypertext and hypermedia, Kluwer Academic Publishers, 1998.
[44] Brusilovsky P., Maybury M.T., The adaptive web: From adaptive hypermedia to the adaptive web, Communications of the ACM 45 (5), 2002.
[45] Bray t., RDF and metadata, 1998, http://www.xml.com/xml/pub/98/06/rdf.html.
[46] N. Capuano, M. De Santo, M. Marsella, M. Molinara, S. Salerno : “A multi-agent architecture for intelligent tutoring”, Proceedings of the International Conference on
Definizione dell’architettura della piattaforma 93
Advances in Infrastructure for Electronic Business, Science and Education in internet, 2002.
[47] L. 47olino, J. Key, A. Miller : “Incremental student modelling and reflection by verified concept-mapping”, School of Information Technologies, university of Sydney
[48] Clark J. (ed.), XSL transformations (XSLT) version 1.0, W3C Recommendation, 1999, http://www.w3.org/TR/xslt.
[49] Clark J., XSL transformations (XSLT) version 1.1, W3C Working Draft, 2001, http://www.w3.org/TR/xslt11/.
[50] A. De Nicola, M. Missikoff, F. Schiappelli : “Verso un supporto ontologico per la creazione di corsi e-Learning”, Web Learning per la qualità del capitale umano 2003, pp. 52-64, Trento, Editoria Universitaria Elettronica.
[51] Duval E., Hodgins W., Sutton S.A., Weibel S., Metadata principles and practicalities, DB magazine 8 (1), 2001.
[52] The 52lin Core Meta-data Iniziative, http://52lincore.org [53] http://www.cs.man.ac.uk/~horrocks/53/ [54] Fisher S., Course and exercise sequencing using metadata in adaptive hypermedia
learning systems, ACM Journal of Educational Resources in Computing, 2001. [55] Y. 55, V. Ratnakar : “A Comparison of (Semantic) Markup Languages”, USC
Information Sciences Institute and Computer Science Departmente. [56] N. Guarino : “Formal Ontology, Conceptual Analysis and Knowledge
Representation”, International Journal of Human and Computer Studies, 1995 [57] N. Henze, W. Nejdl : “Knowledge Modeling for Open Adaptive Hypermedia”, in
proceedings of the 2nd International Conference on Adaptive Hypermedia and Adaptive Web-Based Systems (AH 2002), Malaga, 2002
[58] Hannafin M.J., Hill J.R., McCarty J.E., Designing resource-based learning and performance support systems, 2001.
[59] I. Horrocks, U. Sattler : “Optimized reasoning for SHIQ”, LTSC-Report, LuFg Theoretische informatik, 2001
[60] IEEE, Draft standard for learning object metadata, 2002, http://ltsc.ieee.org/doc/wg12/3_1484_12_1_v1_Final_Draft.pdf.
[61] Janich K., Topologie, Springer Verlag, 1996. [62] M. Martinez : “Designing Learning Objects to Personalize Learning”, 2000 [63] McLaughlin B., Web Publishing Frameworks, in Mc Laughlin B., Java and XML,
O’Reilly and associates, 2000 [64] M.D. Merrill : “Instructional Design Theories and Models”, Component Display
Theory. In C. Reigeluth (ed.), Hillsdale, NJ: Erlbaum Associates., 1983 http://www.oreilly.com/catalog/javaxml/chapter/ch09.html. [65] P. Mohan, J. Greer, G. McCalla : “Instructional planning with Learning Objects”, in
proceedings of Workshop on Knowledge Representation and Automated Reasoning for E-Learning Systems (KRR-5), Eighteen International Joint Conference on Artificial Intelligence (IJCAI-03), Acapulco, 2003
Definizione dell’architettura della piattaforma 94
[71] M. A. Sicilia, E. Garcia, P. Diaz, I. Aedo: “Learning Links: reusable assets with support for vagueness and ontology-based typing”, Workshop on Concepts and Ontologies in Web-Based Educational Systems (ICCE 2002), Auckland, 2002
[72] W3C, XML linking specification, W3C Working Draft, 1999, http://www.w3.org/TR/WD-xlink.