Corso di Laurea Magistrale in Ingegneria Civile delle Infrastrutture Viarie e Trasporti Relazione di fine tirocinio Implementazione del metodo Markov Chain Monte Carlo (MCMC) con il software di calcolo MATLAB Studente: Tutor universitario: Claudia Bandiera Prof. Ernesto Cipriani Prof. Francesco Viti Guido Cantelmo Anno accademico 2016/2017
Transcript
Corso di Laurea Magistrale in Ingegneria Civile delle Infrastrutture Viarie e Trasporti
Relazione di fine tirocinio
Implementazione del metodo Markov Chain Monte Carlo (MCMC) con il software di calcolo MATLAB
Studente: Tutor universitario: Claudia Bandiera Prof. Ernesto Cipriani Prof. Francesco Viti Guido Cantelmo
Anno accademico 2016/2017
1
Università degli Studi di Roma Tre – Relazione di fine tirocinio
Università degli Studi di Roma Tre – Relazione di fine tirocinio
1 INTRODUZIONE
La seguente relazione ha lo scopo di descrivere le attività effettuate ai fini dello svolgimento della tesi di laurea, con particolare riferimento all’acquisizione di ulteriori conoscenze informatiche e modellistiche. Le suddette attività sono previste dall’art.10, co. 5 let. d/e del D.M. 270/2004 e considerate equivalenti al tirocinio; lo svolgimento delle attività di seguito illustrate è stato approvato dal Consiglio del Collegio Didattico di Ingegneria Civile nella seduta del 28 settembre 2017, per il riconoscimento di 4 CFU per un numero di ore non inferiore a 100, come previsto dal piano di studi dell’Ateneo.
Le attività sono state svolte durante il periodo di permanenza presso l’Université du Luxembourg (01/10/2017-31/01/2018) e si collocano all’interno del progetto di tesi finale. Essa, in particolare, ha lo scopo di definire un modello che possa essere in grado di determinare la struttura della domanda di trasporto, in riferimento agli scopi di viaggio e alla distribuzione temporale. Il tirocinio è stato caratterizzato da una prima fase di studio teorico dei metodi di tipo Monte Carlo (MC), con particolare attenzione per il Markov Chain Monte Carlo (MCMC), e una seconda fase dedicata alla definizione di un codice MATLAB in grado di implementare quest’ultimo nel contesto della stima della domanda dinamica di trasporti, in quanto componente fondamentale per del modello finale di stima della domanda giornaliera.
L’elaborato è costituito da un primo capitolo nel quale vengono definite le proprietà sulle quali si basano i metodi di simulazione Monte Carlo, seguito da una descrizione approfondita del Markov Chain Monte Carlo. Sulla base di quanto illustrato nei primi due paragrafi, il terzo ha come soggetto il modello che è stato implementato in MATLAB e i relativi risultati ottenuti dalla sua applicazione, con lo scopo di descrivere il funzionamento dell’algoritmo attraverso la stima di media e deviazione standard rappresentativi di un campione generato artificialmente. Infine, nell’ultimo capitolo verranno illustrate le conclusioni.
3
Università degli Studi di Roma Tre – Relazione di fine tirocinio
2 METODO MONTE CARLO
Quando si parla di metodo Monte Carlo (MC) si intende l’insieme di tecniche che fanno uso di simulazioni con lo scopo di stimare variabili aleatorie per risolvere problemi con base matematica. Le sue origini risalgono alla Seconda Guerra Mondiale ad opera di John von Neumann e Stanislaw Marcin Ulam, all’interno del progetto Manhattan, e venne utilizzato come parola in codice per gli esperimenti condotti a Los Alamos, nel New Mexico, per la costruzione della prima bomba atomica. Quando venne dato il nome "Monte Carlo" a questo procedimento matematico fondato sull'utilizzazione di numeri casuali, l’intento era quello di riferirsi alla capitale del Principato di Monaco, più precisamente ci si riferiva al casinò, alle sale da gioco, alle roulette.
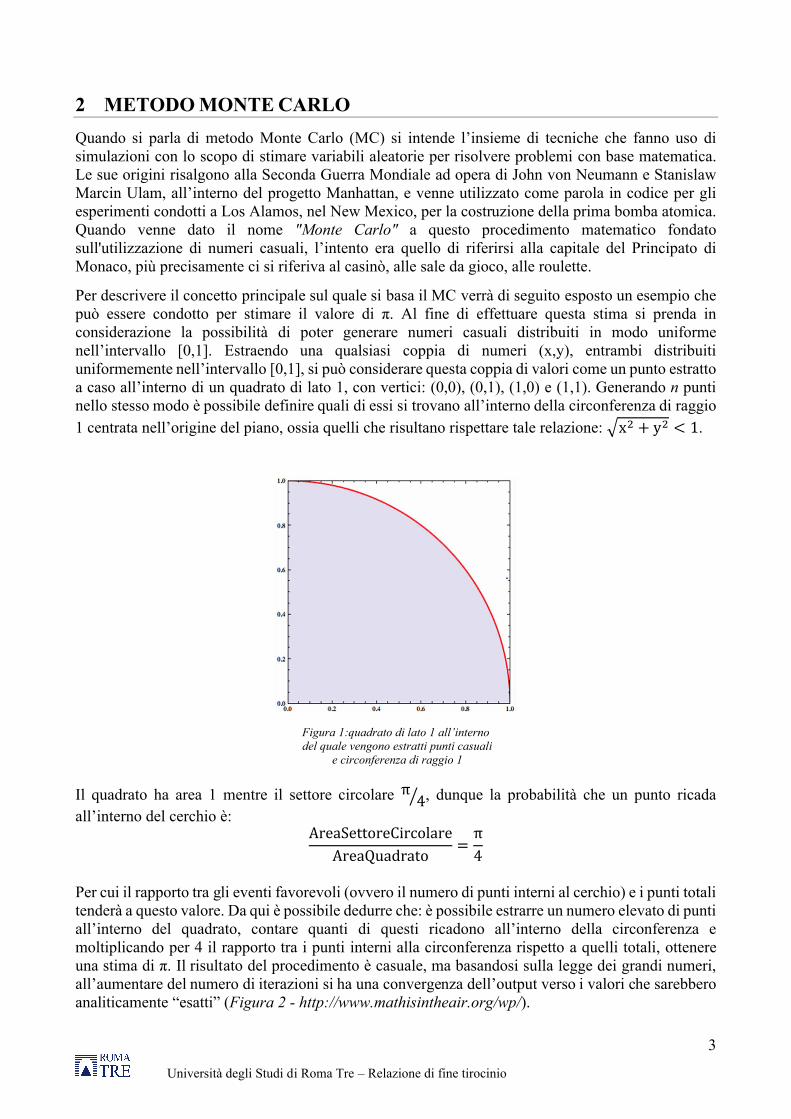
Per descrivere il concetto principale sul quale si basa il MC verrà di seguito esposto un esempio che può essere condotto per stimare il valore di π. Al fine di effettuare questa stima si prenda in considerazione la possibilità di poter generare numeri casuali distribuiti in modo uniforme nell’intervallo [0,1]. Estraendo una qualsiasi coppia di numeri (x,y), entrambi distribuiti uniformemente nell’intervallo [0,1], si può considerare questa coppia di valori come un punto estratto a caso all’interno di un quadrato di lato 1, con vertici: (0,0), (0,1), (1,0) e (1,1). Generando n punti nello stesso modo è possibile definire quali di essi si trovano all’interno della circonferenza di raggio
1 centrata nell’origine del piano, ossia quelli che risultano rispettare tale relazione: �x� + y� < 1.
Figura 1:quadrato di lato 1 all’interno del quale vengono estratti punti casuali
e circonferenza di raggio 1
Il quadrato ha area 1 mentre il settore circolare π 4� , dunque la probabilità che un punto ricada
all’interno del cerchio è: AreaSettoreCircolare
AreaQuadrato=π
4
Per cui il rapporto tra gli eventi favorevoli (ovvero il numero di punti interni al cerchio) e i punti totali tenderà a questo valore. Da qui è possibile dedurre che: è possibile estrarre un numero elevato di punti all’interno del quadrato, contare quanti di questi ricadono all’interno della circonferenza e moltiplicando per 4 il rapporto tra i punti interni alla circonferenza rispetto a quelli totali, ottenere una stima di π. Il risultato del procedimento è casuale, ma basandosi sulla legge dei grandi numeri, all’aumentare del numero di iterazioni si ha una convergenza dell’output verso i valori che sarebbero analiticamente “esatti” (Figura 2 - http://www.mathisintheair.org/wp/).
4
Università degli Studi di Roma Tre – Relazione di fine tirocinio
Figura 2: a) 6000 punti estratti con π~3.11467 b)30000 punti estratti con π~3.1436
Queste tipologie di metodi vengono utilizzati in molti campi: astrofisica, previsioni metereologiche, ingegneria, biologia, finanza, ecc. e, nonostante le molteplici applicazioni, la tecnica Monte Carlo, viene sostanzialmente implementata per la stima di tre problemi: integrazione numerica, ottimizzazione e generazione di distribuzioni di probabilità.
Dunque, il metodo Monte Carlo è una tecnica statistica di simulazione attraverso la quale è possibile ottenere la stima di parametri di interesse attraverso la generazione di numeri causali estratti da una distribuzione che si suppone abbia il fenomeno preso in esame. Per simulazione si intende lo studio del comportamento di un sistema tramite la sua riproduzione in un contesto semplificato e controllabile. Si cerca di descrivere il fenomeno in esame attraverso la definizione di equazioni che esprimono le relazioni presenti tra le varie componenti del sistema oggetto di studio. Effettuando esperimenti sul modello matematico si ottengono dei risultati che si assume siano una adeguata rappresentazione della realtà. Il fine ultimo è quello estendere la conoscenza di tale sistema, verificare (o negare) la validità di ipotesi su di esso e riuscire a raccogliere informazioni per poter formulare possibili previsioni.
Per poter implementare questa tecnica è necessario definire le sue componenti principali, ovvero:
- parametri: definiti dal decisore come input, quindi controllabili; - variabili di input: variabili di ingresso il cui valore può essere descritto in termini
probabilistici, in quanto esse dipendono da eventi che non sono sotto il controllo del decisore; - modello: equazioni matematiche, espresse in funzione dei parametri e delle variabili di input,
che descrivono le relazioni tra le componenti del sistema e definiscono il legame degli output con i parametri e le variabili di input;
- variabili di output: rappresentano i risultati della simulazione.
A questo punto, dopo aver definito un problema, la sua risoluzione si ottiene producendo un numero N di combinazioni dei valori che le variabili di input possono assumere e, attraverso le equazioni del modello, calcolare i relativi output. Ogni combinazione si ottiene estraendo in maniera casuale un valore per ciascuna variabile di input in riferimento alla distribuzione di probabilità che la caratterizza e alla correlazione esistente tra le variabili. Tale operazione viene, dunque, ripetuta N volte (con N sufficientemente “grande” da avere la possibilità di ottenere dei risultati statisticamente affidabili), ricavando così N valori di output indipendenti, rappresentativi dei possibili valori che gli output possono assumere.
Un’ulteriore precisazione necessaria riguarda la definizione di sequenza di numeri casuali, infatti, con essa si intende una successione di numeri che non hanno nessuna relazione tra di loro, pur
5
Università degli Studi di Roma Tre – Relazione di fine tirocinio
seguendo tutti la stessa distribuzione di probabilità. I numeri possono essere generati dal computer attraverso degli algoritmi che sostanzialmente si basano su tre categorie di numeri:
- numeri “veramente” casuali, che derivano da misure di fenomeni fisici aleatori; - numeri pseudocasuali: sono serie generate direttamente dal calcolatore secondo un
determinato algoritmo; - numeri “quasi” casuali: pur essendo generati da un algoritmo, sono più che altro una serie di
numeri disposti in maniera uniforme.
La modalità di generare numeri casuali più diffusa risulta essere quella relativa ai numeri pseudocasuali.
Al fine di ottenere una buona stima delle variabili di interesse, risulta fondamentale effettuare un’ottima formulazione del problema, sia in termini di equazioni matematiche tra le variabili di input e quelle di output, sia riguardo la definizione della distribuzione di probabilità delle variabili di input definite. Quest’ultima può essere ricavata in vari modi a seconda dei dati a disposizione. In altre parole, per alcuni tipi di eventi è possibile avere a disposizione delle serie storiche dei dati e, quindi eseguire un adattamento di queste con gli andamenti delle funzioni di distribuzione predefinite. Un altro metodo si basa sul ricampionamento, ovvero si estraggono in modo casuale dei valori dalla serie di dati a disposizione, con successiva reimmissione di essi, senza definire delle distribuzioni di probabilità a cui i dati si adattano meglio. Quando, invece, i dati non sono a disposizione può essere effettuata una valutazione soggettiva della probabilità. In un caso, il decisore fissa dei possibili valori che le variabili in esame possono assumere, associandoli a delle probabilità cumulate, così da ottenere delle variabili casuali discrete. Per determinare, invece, una distribuzione continua esistono vari metodi. Tra questi è possibile stimare tre valori della variabile presa in esame: una stima pessimistica (il caso peggiore), una stima ottimistica (il caso migliore) e una realistica (il caso ritenuto più probabile); i seguenti valori serviranno poi per costruire una distribuzione triangolare.
Il modello di tipo Monte Carlo “classico” fornisce risultati soddisfacenti quando la distribuzione di probabilità risulta essere semplice o si hanno a disposizione un numero sufficientemente elevato di dati. In altre condizioni, è preferibile utilizzare altri modelli più elaborati. In particolare, nel caso in esame, verrà implementato il Markov Chain Monte Carlo (MCMC). Questo perché la funzione di probabilità che si vuole studiare è variabile nel tempo, ovvero il suo andamento varia, per esempio, tra la mattina e il pomeriggio. Non avendo a disposizione informazioni precise sulla distribuzione della domanda è, quindi, necessario definire un modello che sia più idoneo a descrivere il problema.
6
Università degli Studi di Roma Tre – Relazione di fine tirocinio
3 MARKOV CHAIN MONTE CARLO
Il Markov Chain Monte Carlo (MCMC) è un metodo di campionamento guidato dal computer. Il nome combina due proprietà: quelle del metodo Monte Carlo (esposte nel paragrafo precedente) e della catena di Markov.
La catena di Markov è un processo stocastico a memoria corta, vale a dire che la probabilità riferita agli eventi futuri non dipende dai passi che hanno portato alla condizione attuale (questa è la proprietà di Markov). Il contributo della catena di Markov nel MCMC si basa sull’idea che i campioni casuali sono generati da uno speciale processo sequenziale, dove ogni campione casuale è usato come punto di partenza per generare il successivo campione casuale. Per descrivere il funzionamento del Markov Chain si consideri in un processo a tempo discreto e stati discreti una successione di variabili aleatorie (��, ��, … , ��, … ) definite in uno spazio S, indicato come spazio degli stati. Considerando che l’indice n di �� sia il tempo, possiamo definire come stati i possibili valori di ��. Il processo inizia in uno di questi stati e si muove successivamente in un altro stato. In altre parole, se la catena si trova all’istante n in uno stato i, all’istante successivo si sposta allo stato j con una probabilità ���, che dipende
esclusivamente dalla posizione corrente. Le probabilità ��� viene chiamata probabilità di transizione
Come base iniziale del metodo viene definita una distribuzione di probabilità, su S, che specifica lo stato di partenza. Di seguito viene mostrato un esempio grafico, ovvero un diagramma con due stati del processo, A e B. I numeri indicano le probabilità di transizione da uno stato all’altro.
Figura 3:Diagramma di due stati A e B con relative probabilità di transizione (https://brilliant.org/)
Il MCMC è particolarmente utilizzato nell’inferenza Bayesiana, in quanto le distribuzioni a posteriori risultano particolarmente difficili da studiare attraverso la stima analitica. Attraverso l’inferenza statistica è possibile derivare le caratteristiche di una popolazione osservando una parte di essa, ovvero un campione. A differenza del calcolo delle probabilità, in questo caso, lo scopo è quello ricostruire la distribuzione di probabilità in base all’osservazione degli eventi. Si assume che un modello, descritto da certi parametri θ sia vero e si cerca di ottenere la distribuzione di θ noti i dati x. Al fine di definire tale modello, viene inizialmente definita una funzione a priori. Essa è una funzione matematica che esprime la convinzione (belief) di come è distribuito il parametro del quale vogliamo ottenere la stima. Essa può essere basata sull’esperienza, oppure può essere frutto di ipotesi fatte dal decisore. Il secondo passo si basa sulla collezione di dati e la definizione della funzione di verosimiglianza (likelihood). Quest’ultima quantifica la verosimiglianza di un valore di un parametro sulla base dei dati osservati. Infine, viene effettuato il calcolo della probabilità a posteriori. Attraverso questo ultimo step è possibile aggiornare la convinzione sul parametro con i risultati dell’esperimento. Secondo il teorema di Bayes, essa viene calcolata come:
�(�|�) =�(�|�) ∙ �(�)
�(�)
7
Università degli Studi di Roma Tre – Relazione di fine tirocinio
Dove:
- �(�|�) è la probabilità a posteriori (o posterior); - �(�|�) viene detta likelihood (o funzione di verosimiglianza); - �(�) è detta probabilità a priori (o prior); - �(�) viene detta evidenza (o likelihood marginale), essa è semplicemente una costante che
normalizza la probabilità, quindi la probabilità relativa dei parametri non dipende da essa e può essere ignorata.
Possiamo, quindi, riscrivere la formula come:
�(�|�) ∝ �(�|�) ∙ �(�)
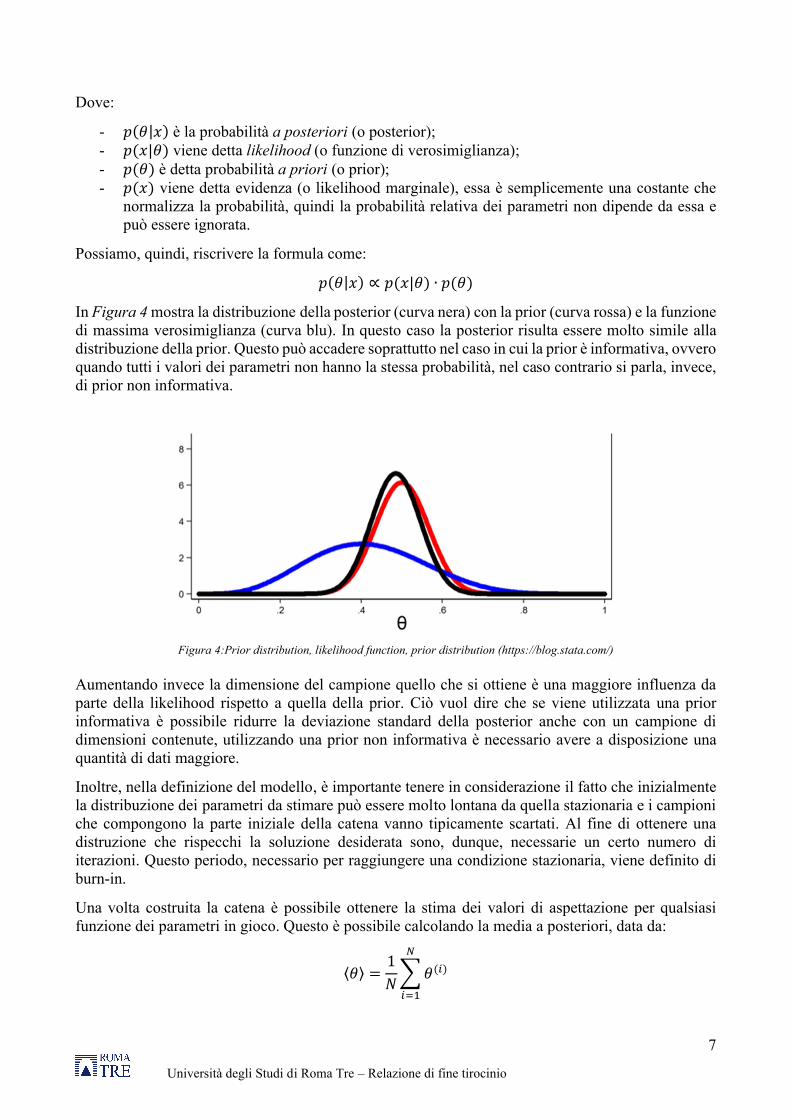
In Figura 4 mostra la distribuzione della posterior (curva nera) con la prior (curva rossa) e la funzione di massima verosimiglianza (curva blu). In questo caso la posterior risulta essere molto simile alla distribuzione della prior. Questo può accadere soprattutto nel caso in cui la prior è informativa, ovvero quando tutti i valori dei parametri non hanno la stessa probabilità, nel caso contrario si parla, invece, di prior non informativa.
Figura 4:Prior distribution, likelihood function, prior distribution (https://blog.stata.com/)
Aumentando invece la dimensione del campione quello che si ottiene è una maggiore influenza da parte della likelihood rispetto a quella della prior. Ciò vuol dire che se viene utilizzata una prior informativa è possibile ridurre la deviazione standard della posterior anche con un campione di dimensioni contenute, utilizzando una prior non informativa è necessario avere a disposizione una quantità di dati maggiore.
Inoltre, nella definizione del modello, è importante tenere in considerazione il fatto che inizialmente la distribuzione dei parametri da stimare può essere molto lontana da quella stazionaria e i campioni che compongono la parte iniziale della catena vanno tipicamente scartati. Al fine di ottenere una distruzione che rispecchi la soluzione desiderata sono, dunque, necessarie un certo numero di iterazioni. Questo periodo, necessario per raggiungere una condizione stazionaria, viene definito di burn-in.
Una volta costruita la catena è possibile ottenere la stima dei valori di aspettazione per qualsiasi funzione dei parametri in gioco. Questo è possibile calcolando la media a posteriori, data da:
⟨�⟩ =1
���(�)�
���
8
Università degli Studi di Roma Tre – Relazione di fine tirocinio
Per generare gli elementi di una catena esistono diversi algoritmi. Un esempio è l’algoritmo di Metropolis-Hastings, nel quale viene effettuato il campionamento da una distribuzione definita a priori, al fine di stimare la distribuzione target e alla base del modello viene definita una tecnica per rifiutare o accettare i valori proposti ad ogni iterazione. Un altro algoritmo è quello del campionamento di Gibbs che è un caso particolare dell’algoritmo di Metropolis-Hastings, con la differenza che viene sempre accettato il valore campionato e le distribuzioni condizionate devono essere sempre note. Questa condizione porta l’algoritmo ad essere meno applicabile.
9
Università degli Studi di Roma Tre – Relazione di fine tirocinio
4 IL MODELLO
Per la costruzione del modello è necessario definire come primo parametro il numero di iterazioni. Tale valore aumenta notevolmente all’aumentare della complessità del problema e del numero di variabili da stimare. Viene scelta, successivamente, una forma per la distribuzione di probabilità necessaria a determinare il numero di parametri da stimare. In seguito, per ogni parametro da stimare viene definita una prior caratterizzata da una propria distribuzione di probabilità con di valori di input per iniziare la stima. L’algoritmo, così, propone una nuova distribuzione per ogni parametro ad ogni iterazione scegliendo un nuovo valore da una distribuzione normale centrata nel valore corrente. La varianza di questa distribuzione è un altro parametro di input della simulazione, aumentando questo valore aumenta il salto, ovvero la differenza tra il valore proposto e quello corrente. L’ultimo input è caratterizzato dai dati osservati, un insieme di valori che seguono la distribuzione analizzata e utilizzati per calcolare la likelihood. L’algoritmo si basa sul confronto tra i valori correnti e quelli proposti considerando la verosimiglianza della distribuzione in riferimento ai dati e ai parametri sulla base della prior. La posterior, per ogni variabile, è caratterizzata dai valori di output di ogni iterazione, che costituiscono la catena di Markov. Calcolando il valore medio di tali output si ottengono i parametri finali della distribuzione.
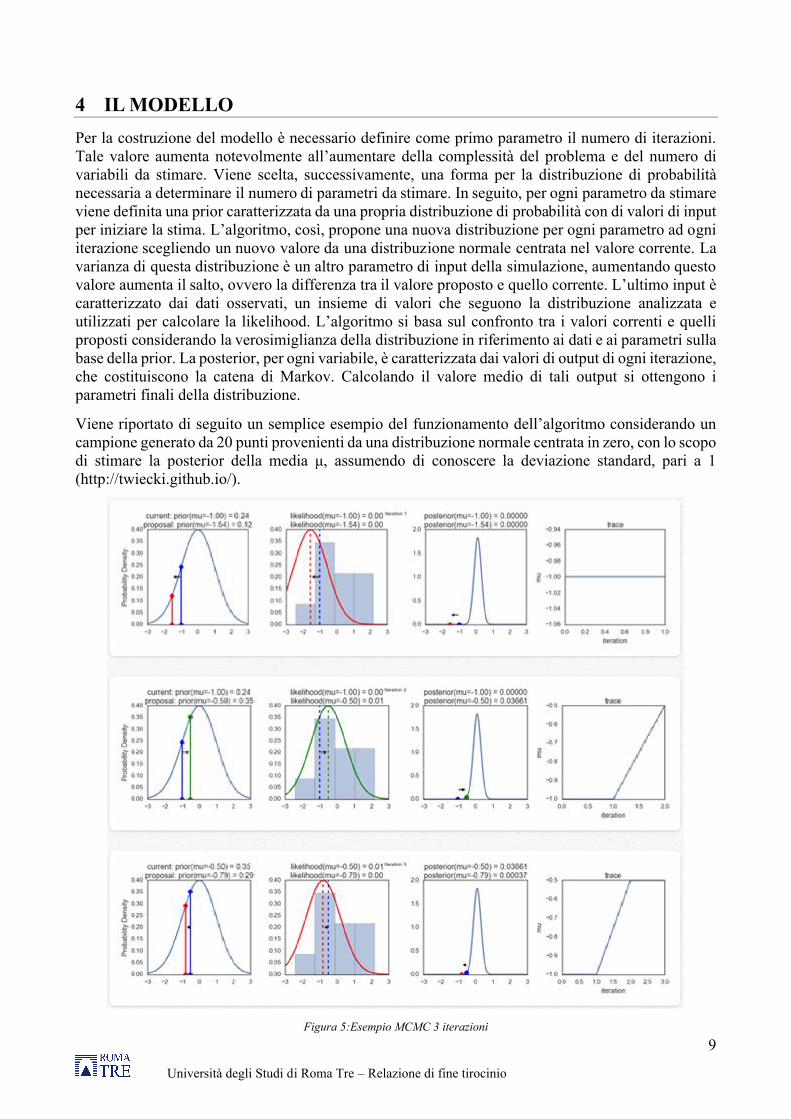
Viene riportato di seguito un semplice esempio del funzionamento dell’algoritmo considerando un campione generato da 20 punti provenienti da una distribuzione normale centrata in zero, con lo scopo di stimare la posterior della media μ, assumendo di conoscere la deviazione standard, pari a 1 (http://twiecki.github.io/).
Figura 5:Esempio MCMC 3 iterazioni
10
Università degli Studi di Roma Tre – Relazione di fine tirocinio
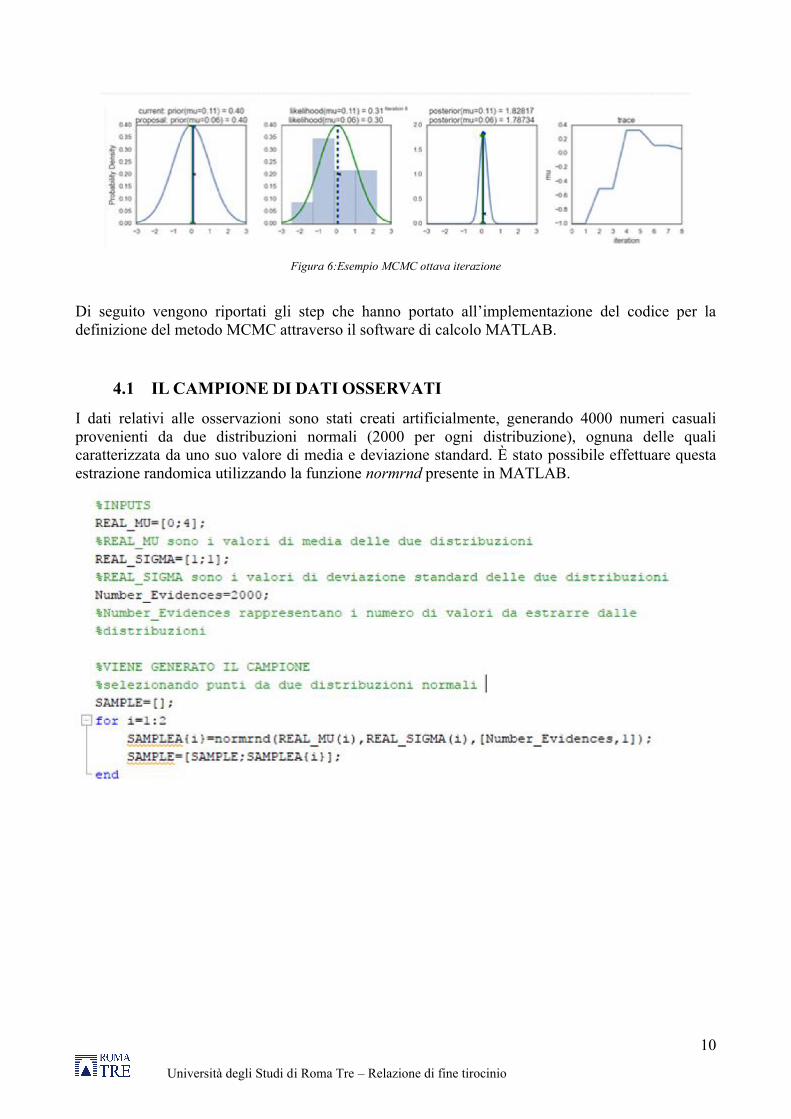
Figura 6:Esempio MCMC ottava iterazione
Di seguito vengono riportati gli step che hanno portato all’implementazione del codice per la definizione del metodo MCMC attraverso il software di calcolo MATLAB.
4.1 IL CAMPIONE DI DATI OSSERVATI
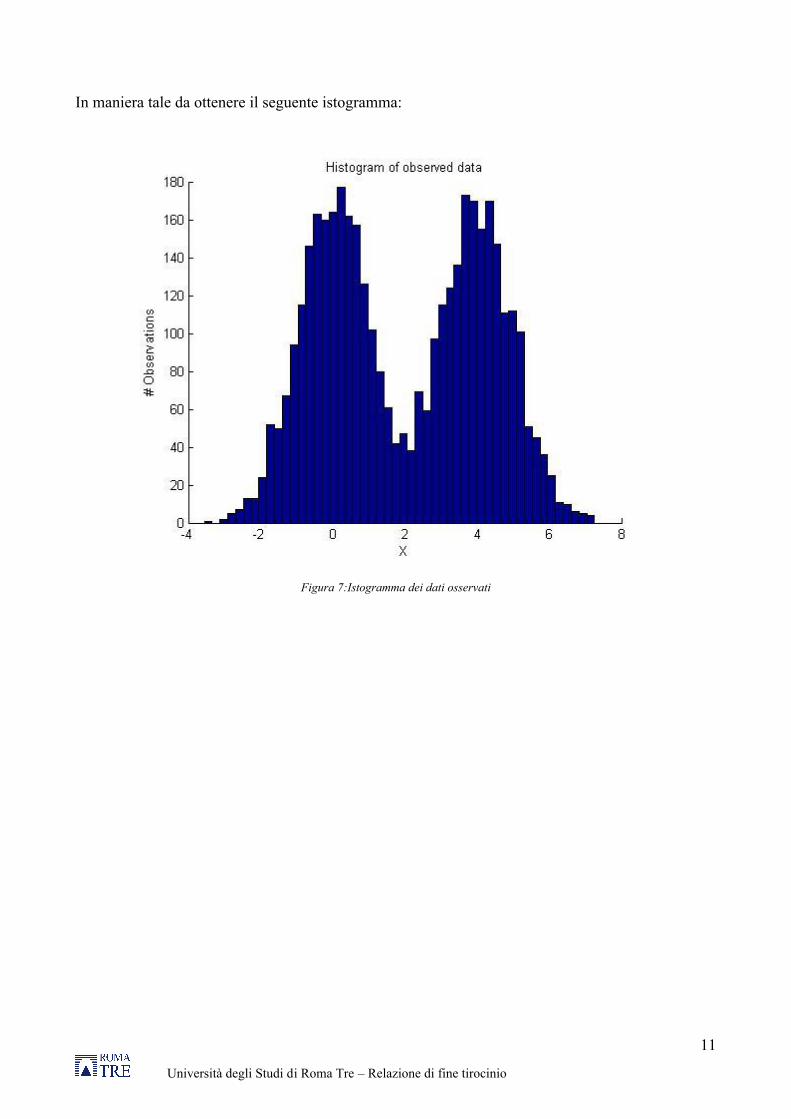
I dati relativi alle osservazioni sono stati creati artificialmente, generando 4000 numeri casuali provenienti da due distribuzioni normali (2000 per ogni distribuzione), ognuna delle quali caratterizzata da uno suo valore di media e deviazione standard. È stato possibile effettuare questa estrazione randomica utilizzando la funzione normrnd presente in MATLAB.
11
Università degli Studi di Roma Tre – Relazione di fine tirocinio
In maniera tale da ottenere il seguente istogramma:
Figura 7:Istogramma dei dati osservati
12
Università degli Studi di Roma Tre – Relazione di fine tirocinio
4.2 DEFINIZIONE DEL MODELLO
Per definire il modello è stato necessario fare delle assunzioni. In esso assumiamo per semplicità che i dati siano distribuiti secondo una normale, vale a dire che la likelihood del modello è normale. Come si è visto una distribuzione normale è caratterizzata da due parametri: la media (μ) e la deviazione standard (σ). Quindi, lo scopo è quello di dedurre la posterior per questi due parametri. Per ogni parametro che si vuole stimare, bisogna scegliere la prior. Nel caso in esame è stata scelta una distribuzione normale come prior per la media e uniforme per la deviazione standard, con i seguenti valori iniziali:
Come è stato specificato precedentemente bisogna definire dei valori iniziali dei parametri, fissandoli arbitrariamente:
Si propone, inoltre, al modello di effettuare dei movimenti (salti) da questa posizione verso un’altra (questa è la parte riferita al processo di Markov).
Quindi, la distribuzione scelta per i nuovi valori di μ e σ è una distribuzione normale centrata nel valore corrente di μ e σ con un passo pari a 0.1 (nel caso in esame).
Il processo inizia definendo un nuovo valore di media e deviazione standard:
e per ogni valore (corrente e proposto) vengono create nuove distribuzioni di probabilità
13
Università degli Studi di Roma Tre – Relazione di fine tirocinio
al fine di calcolare la likelihood per le due opzioni. Il procedimento avviene sommando i logaritmi delle funzioni di densità di probabilità:
Con gli stessi valori viene calcolata la distribuzione di densità di probabilità della prior che segue le assunzioni fatte:
Il punteggio viene a questo punto calcolato come somma della likelihood e le distribuzioni di probabilità di media e deviazione standard definite dalla prior, sia nel caso corrente che quello proposto:
Fino a qui è stato realizzato un algoritmo in grado di proporre movimenti in direzioni random. Dato che è necessario definire la posterior di μ e σ, costituita da tutti i valori proposti accettati, è necessario definire anche una probabilità di accettazione:
Se il valore viene accettato diventa il nuovo parametro corrente, altrimenti viene scartato e viene selezionato un altro valore. Ogni valore accettato, inoltre, viene salvato:
14
Università degli Studi di Roma Tre – Relazione di fine tirocinio
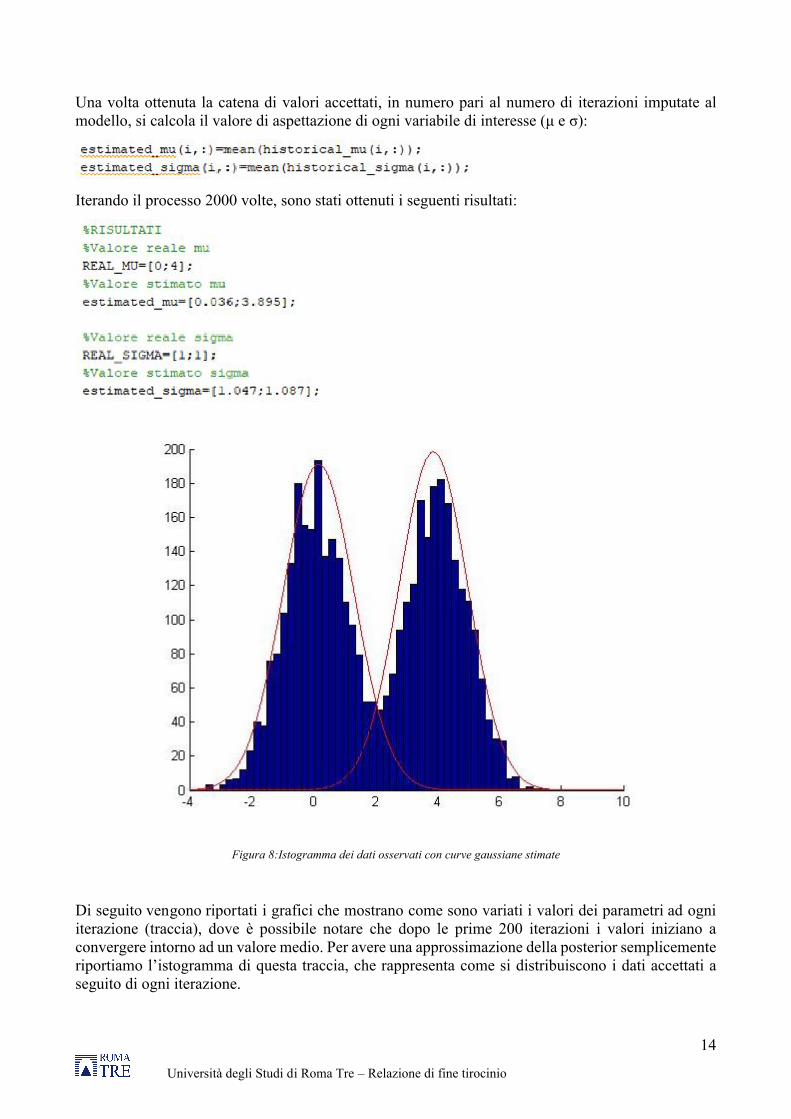
Una volta ottenuta la catena di valori accettati, in numero pari al numero di iterazioni imputate al modello, si calcola il valore di aspettazione di ogni variabile di interesse (μ e σ):
Iterando il processo 2000 volte, sono stati ottenuti i seguenti risultati:
Figura 8:Istogramma dei dati osservati con curve gaussiane stimate
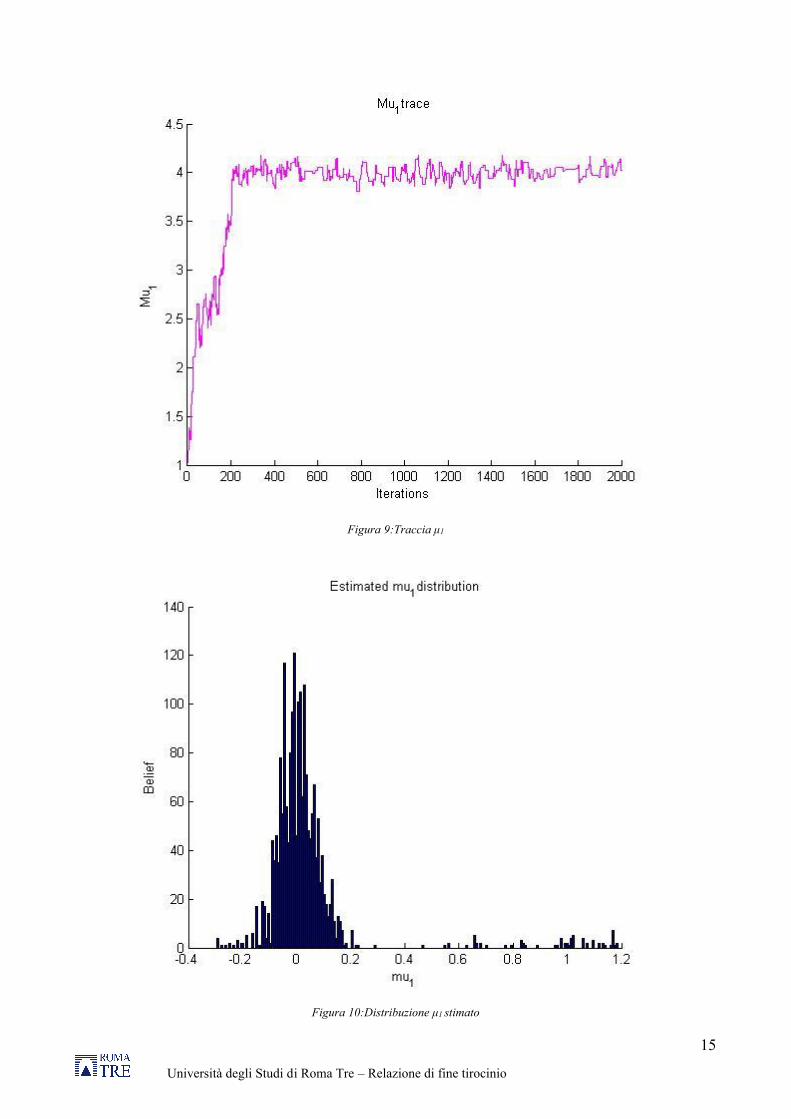
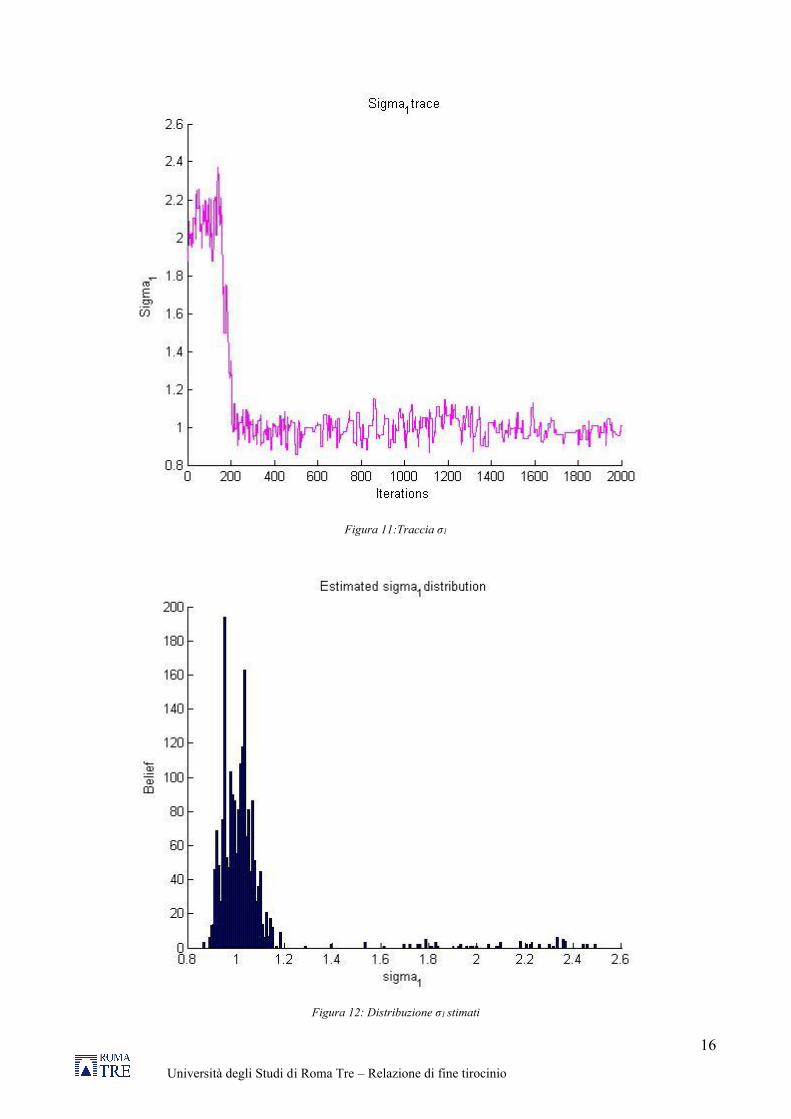
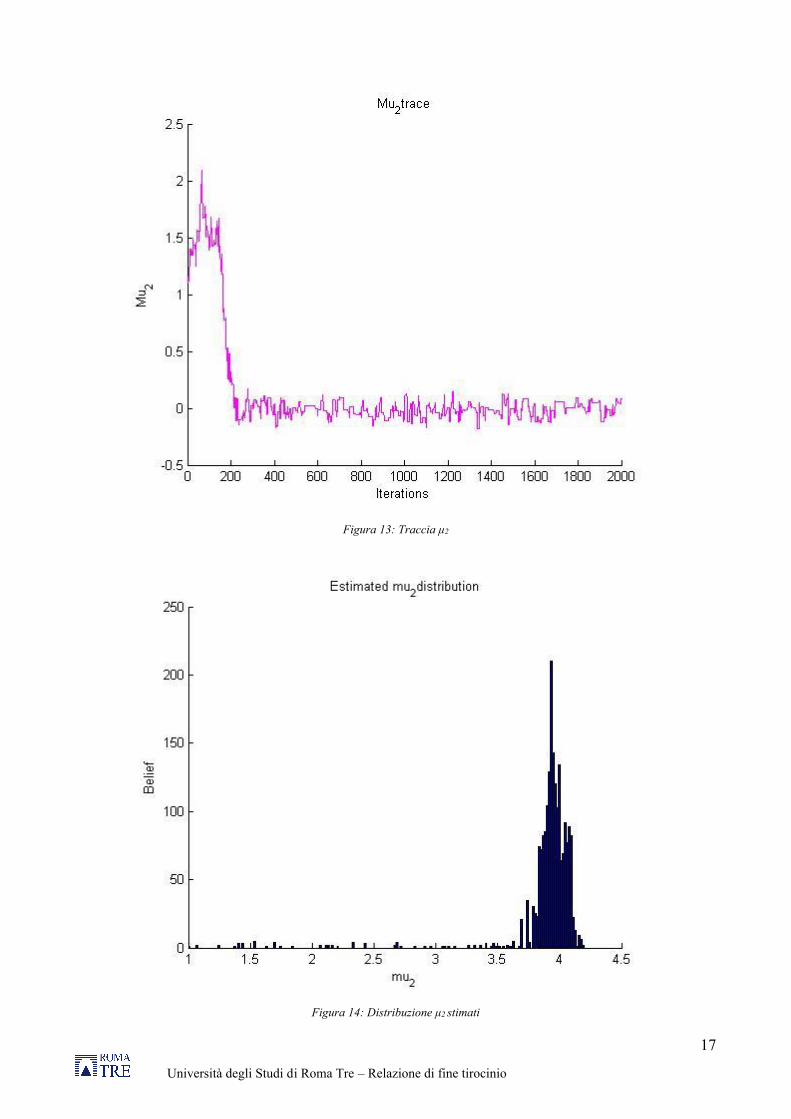
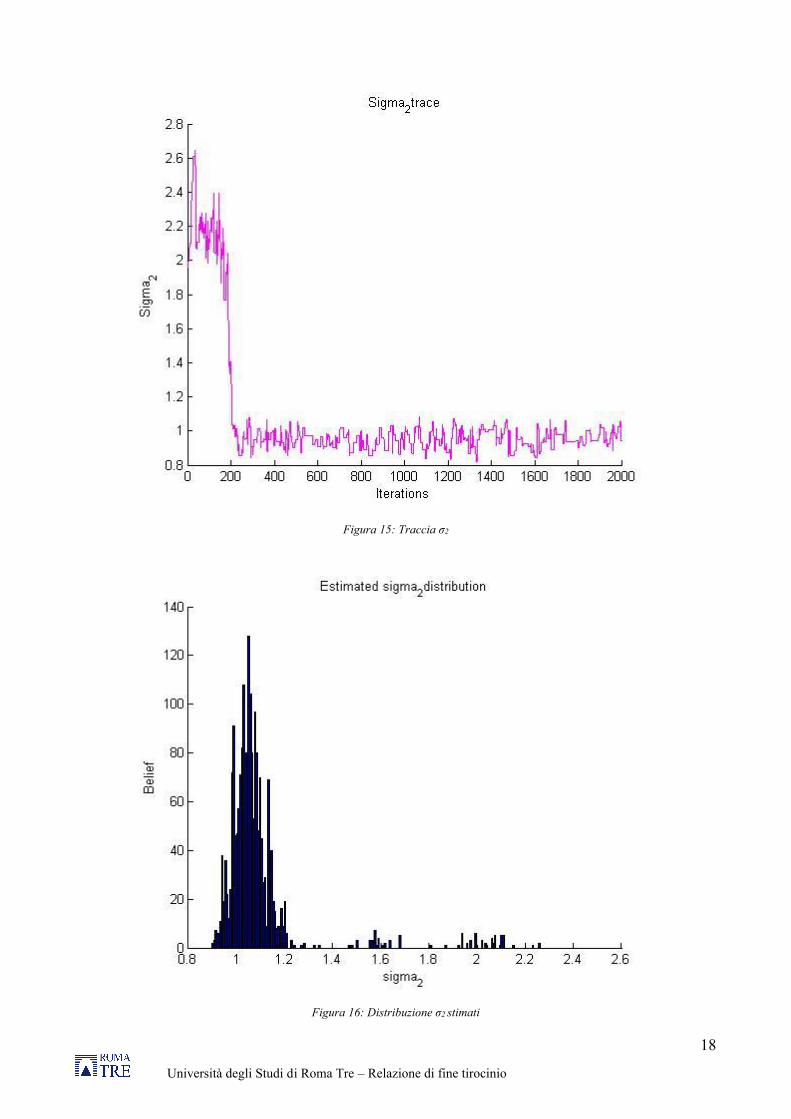
Di seguito vengono riportati i grafici che mostrano come sono variati i valori dei parametri ad ogni iterazione (traccia), dove è possibile notare che dopo le prime 200 iterazioni i valori iniziano a convergere intorno ad un valore medio. Per avere una approssimazione della posterior semplicemente riportiamo l’istogramma di questa traccia, che rappresenta come si distribuiscono i dati accettati a seguito di ogni iterazione.
15
Università degli Studi di Roma Tre – Relazione di fine tirocinio
Figura 9:Traccia μ1
Figura 10:Distribuzione μ1 stimato
16
Università degli Studi di Roma Tre – Relazione di fine tirocinio
Figura 11:Traccia σ1
Figura 12: Distribuzione σ1 stimati
17
Università degli Studi di Roma Tre – Relazione di fine tirocinio
Figura 13: Traccia μ2
Figura 14: Distribuzione μ2 stimati
18
Università degli Studi di Roma Tre – Relazione di fine tirocinio
Figura 15: Traccia σ2
Figura 16: Distribuzione σ2 stimati
19
Università degli Studi di Roma Tre – Relazione di fine tirocinio
5 CONCLUSIONI
L’esempio riportato mostra buoni risultati in ambiente controllato, considerando l’approssimazione di solo due curve “semplici”, come quelle delle distribuzioni normali, chiedendo al modello di stimare solo i parametri di media e deviazione standard.
Il passo successivo sarà quello di ampliare questo modello, questo è possibile grazie ai vantaggi contenuti nel MCMC. In quanto, grazie a questo algoritmo è possibile analizzare funzioni molto più complesse di quelle gaussiane, ovvero funzioni che contengono al loro interno un numero più elevato di variabili e per ognuna di esse è possibile ottenere una rappresentazione statistica come variabili di output, quindi senza analizzare solo pochi indicatori come la media e la varianza. È possibile calcolare queste differenti variabili di output contemporaneamente, ciò comporta il fatto di avere a disposizione nello stesso tempo più criteri per la valutazione. Inoltre, è possibile testare differenti ipotesi sul modello o sui dati di input, ripetendo le simulazioni dopo aver introdotto le opportune modifiche e analizzando gli effetti sull’output. È quindi anche possibile condurre specifiche analisi di sensitività su singole variabili o dati di input.
Le difficoltà che si incontrano con questo modello sono legate innanzi tutto alla sua formulazione, infatti la sua costruzione risulta essere probabilmente l’aspetto più critico, dato che da esso dipendono i risultati che poi si ottengono. Come, per esempio, la stima delle probabilità da attribuire agli eventi, considerando, inoltre, che per definirle bisogna anche considerare i costi di analisi in termini di tempo.