01/06/2007 1 Ruhr-Universität Bochum, Germania, 24 maggio 2007 Isabella Chiari TRATTAMENTO DI TESTI ITALIANI: STRUMENTI, RISORSE E PROBLEMI Isabella Chiari 1 CORPORA E APPLICAZIONI Perché la linguistica dei corpora è oggi tanto rilevante? Ruhr-Universität Bochum, Germania, 24 maggio 2007 rilevante? Come si integra la linguistica dei corpora con la linguistica computazionale? Quali sono i principali problemi che chi costruisce corpora deve risolvere? Esistono strumenti che aiutano chi fa ricerca linguistica a costruire corpora per la pubblicazione? 2
Transcript
01/06/2007
1
Ruhr-Universität Bochum, Germania, 24 maggio 2007
Isabella Chiari
TRATTAMENTO DI TESTI ITALIANI: STRUMENTI, RISORSE E PROBLEMI
Isabella Chiari
1
CORPORA E APPLICAZIONI
Perché la linguistica dei corpora è oggi tanto rilevante?
Ruhr-Universität Bochum, Germania, 24 maggio 2007
rilevante?Come si integra la linguistica dei corpora con la linguistica computazionale?Quali sono i principali problemi che chi costruisce corpora deve risolvere?Esistono strumenti che aiutano chi fa ricerca linguistica a costruire corpora per la pubblicazione?
2
01/06/2007
2
I CORPORA IN LINGUISTICA COMPUTAZIONALE
Chiari, I. (2007), Introduzione alla linguistica computazionale, Laterza, Roma-Bari.
•Dizionari informatizzati•Dizionari macchina corpus based
Lessicografia elettronica corpus-based
•Taggers e parsers con training corpora
Training corpora per il NLP
•Corpus-based•Example-based machine translation
Traduzione automatica
Tecnologie del parlato
•Addestramento allo speech recognition•Sintesi corpus-based
Tecnologie del parlato
•Individuazione automatica di patterns estratti dai dati
Machine learning – Information technology
IL CIRCOLO VIRTUOSO
Chiari, I. (2007), Introduzione alla linguistica computazionale, Laterza, Roma-Bari.
Corporalinguistici
Elaborazione e trattamento del
materiale testuale
Corpora etichettati Strumenti di NLP
Applicazioni per il trattamento dei
corpora
p•Strumenti NLP
•Parsing e tagging
Training corporaper strumenti di NLP –
MACHINE LEARNING
Tecnologie del parlatoTA
Dizionari-macchina
01/06/2007
3
CORPORA PUBBLICI E CORPORA INDIVIDUALI
Ruhr-Universität Bochum, Germania, 24 maggio 2007
5
3 PROBLEMI
Normalizzazione
Ruhr-Universität Bochum, Germania, 24 maggio 2007
• Determinazione degli insiemi ALFABETO E SEPARATORI• Ambiguità nella punteggiatura (punto, trattino, apostrofo,
accenti), ecc.• Nomi propri, di luoghi, sigle non riconosciuti, ecc.• Unità di misura, numeri (euro, 29), ecc.
Disambiguazione delle omografie
• Omografi assoluti e testuali
Individuazione delle polirematiche
6
01/06/2007
4
NORMALIZZAZIONE: CHE COS’È?
Pre-trattamento ortografico
Ruhr-Universität Bochum, Germania, 24 maggio 2007
•La riduzione di ambiguità dovute alle convenzioni ortografiche•individuazione un insieme di simboli come alfabeto (a, b, c, 5, 8) e
un insieme di separatori (.,;:/?!)•ogni simbolo (il punto, la virgola, la barra, ecc.) sia univoco, ossia
non venga utilizzato in modi diversi nello stesso corpus
Pre-trattamento linguistico
•Riconoscimento di strutture cristallizzate•come sigle, titoli, toponimi, nomi propri (prima di ridurre
eventualmente le maiuscole)•Riconoscimento di locuzioni grammaticali e polirematiche note (da
lista)
7
UN ESEMPIO: TALTAC 2
Trattamento automatico lessicale e testuale per l’analisi del contenuto di un corpus
Ruhr-Universität Bochum, Germania, 24 maggio 2007
• Università La Sapienza di Roma (Economia)
Sergio Bolasco
Analisi lessicali e testuali
• Integrazione con risorse di riferimento (vocabolari, lessici di frequenza)
• con altri programmi di trattamento statistico (Lexico, Spad)• e linguistico
8
01/06/2007
5
NORMALIZZAZIONE: DEFINIZIONE ALFABETO
Ruhr-Universität Bochum, Germania, 24 maggio 2007
9
Ruhr-Universität Bochum, Germania, 24 maggio 2007
NORMALIZZAZIONE
•Apostrofi in accentiM i l / i l
PUNTEGGIATURA
•Maiuscolo/minuscolo
•Locuzioni gramm.•Polirematiche nominali
POLIREMATICHE E COLLOCAZIONI (base)
•nomi propri
NOMI
10
•toponimi•celebrità•titoli•Sigle
LISTE PERSONALIZZATE
01/06/2007
6
COSÌ OTTENGO AD ESEMPIO…LOCUZIONI COME..
Ruhr-Universität Bochum, Germania, 24 maggio 2007
11
NOMI PROPRI, SIGLE, FORMULE
Ruhr-Universität Bochum, Germania, 24 maggio 2007
12
01/06/2007
7
NORMALIZZAZIONE: TESTO INTERNET 2004
Ruhr-Universität Bochum, Germania, 24 maggio 2007
A 746
PRON 60
AA 746
AVV 4.323 NM 1.150
PREP 2.589
A
AVV
CONG
ESC
FORM
N
NM
13
CONG 552 ESC 3 FORM 163
N 1.301
PREP
PRON
PRIMA E DOPO LA NORMALIZZAZIONE
Ruhr-Universität Bochum, Germania, 24 maggio 2007
Dati corpusPrima della
normalizzazione Normalizzato Differenza
TOKEN (occorrenze) 254.365 240.173 14.192
TYPES20.130 18.730 1.400
14
OMOGRAFI123.097
(48,4%) 108.760 (45,3%) 14.337
01/06/2007
8
GLI OMOGRAFI - TIPOLOGIE
•parole caratterizzate da un significante comune, ma che rimandano a significati radicalmente diversi spesso senza alcuna parentela
Omografi (omonimi, omofoni)
Ruhr-Universität Bochum, Germania, 24 maggio 2007
significati radicalmente diversi, spesso senza alcuna parentela etimologica
•Calcio•“pedata” •“Ca”•“impugnatura di un fucile o pistola”
Omografi assoluti
p g p
•Faccia•“viso”•“voce del verbo fare”
Omografi testuali
15
STRUMENTI
Omografi assoluti
Ruhr-Universität Bochum, Germania, 24 maggio 2007
•Word sense disambiguation•Strumenti probabilistici/statistici
•Opzionale (attualmente ancora indietro)
OS
Omografi testuali (relativi)
•POS tagging e Lemmatizzatori•Basati su regole•Probabilistici
•Operazione di base per ogni corpus
16
01/06/2007
9
SE NON RISOLVO IL PROBLEMA OTTENGO…
Ruhr-Universität Bochum, Germania, 24 maggio 2007
17
E SE GUARDO LE CONCORDANZE TROVO:
Ruhr-Universität Bochum, Germania, 24 maggio 2007
18
01/06/2007
10
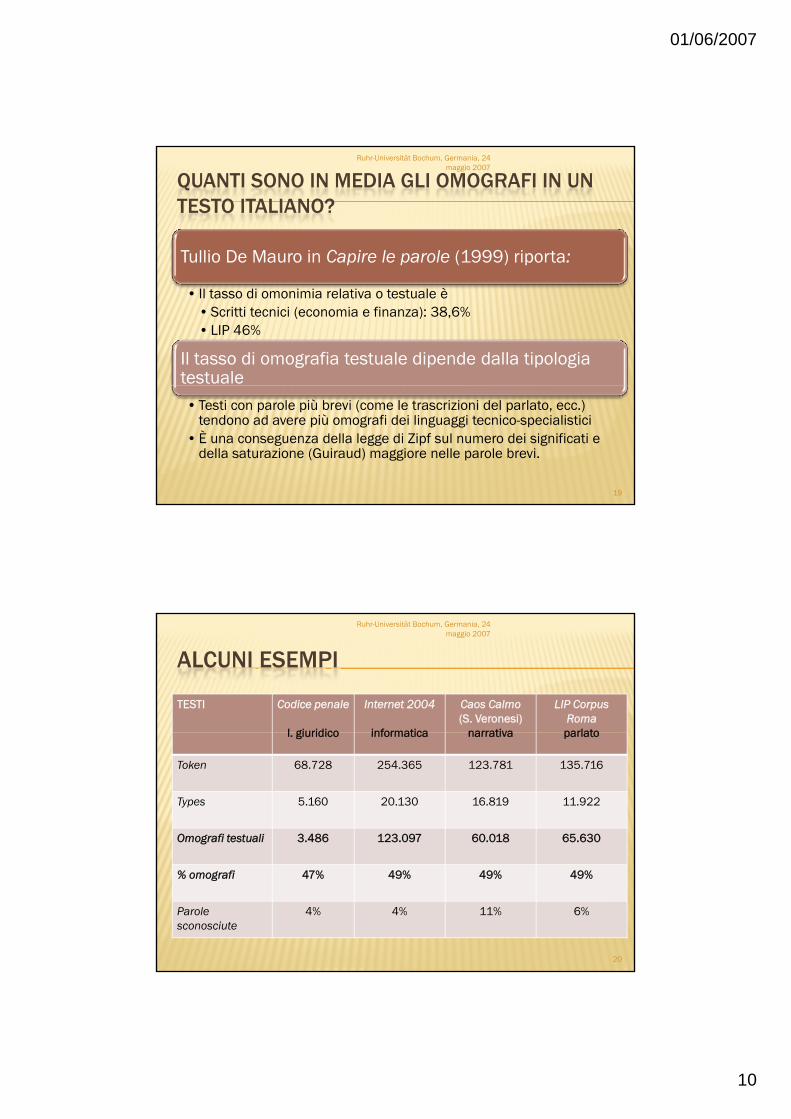
QUANTI SONO IN MEDIA GLI OMOGRAFI IN UN TESTO ITALIANO?
Tullio De Mauro in Capire le parole (1999) riporta:
Ruhr-Universität Bochum, Germania, 24 maggio 2007
• Il tasso di omonimia relativa o testuale è • Scritti tecnici (economia e finanza): 38,6%• LIP 46%
Il tasso di omografia testuale dipende dalla tipologia testuale• Testi con parole più brevi (come le trascrizioni del parlato, ecc.)
tendono ad avere più omografi dei linguaggi tecnico-specialistici• È una conseguenza della legge di Zipf sul numero dei significati e
della saturazione (Guiraud) maggiore nelle parole brevi.
19
ALCUNI ESEMPI
TESTI Codice penale
l giuridico
Internet 2004
informatica
Caos Calmo(S. Veronesi)
narrativa
LIP Corpus Romaparlato
Ruhr-Universität Bochum, Germania, 24 maggio 2007
l. giuridico informatica narrativa parlato
Token 68.728 254.365 123.781 135.716
Types 5.160 20.130 16.819 11.922
Omografi testuali 3.486 123.097 60.018 65.630
% omografi 47% 49% 49% 49%
Parole sconosciute
4% 4% 11% 6%
20
01/06/2007
11
POS TAGGING E LEMMATIZZAZIONE
• etichettatura automatica per categorie grammaticali
Il part-of-speech (POS) tagging
Ruhr-Universität Bochum, Germania, 24 maggio 2007
• etichettatura automatica per categorie grammaticali• Il tagger riceve in input una frase e restituisce in output le forme grafiche delle
parole accompagnate da etichette che segnalano la categoria grammaticale di appartenenza
• potrebbe corrispondere a tre etichettature grammaticali possibili:•determinante (articolo)•nome (nota musicale)
ESEMPIO: la forma grafica <LA>
•nome (nota musicale)•pronome (pronome personale)
• Tagger basati su regole (dizionario-macchina e grammatica)• Tagger probabilistici (training, parametri, applicazione statistica)
Tipologie
21
UN ESEMPIO: TREETAGGER
Autori
Ruhr-Universität Bochum, Germania, 24 maggio 2007
•Helmut Schmid, Institute for Computational Linguistics of the University ofStuttgart
Gratuito e condiviso•Scaricabile (Mac, Windows, Linux)•Online (max 2 mega): http://cental.fltr.ucl.ac.be/~pat/tagger/
Tagger probabilisticoU d i i t•Usa decision trees•Che determina automaticamente l’ampiezza del contesto per calcolare le
probabilità di transizione (più adatto delle catene markoviane per eventi rari)•96,36% di precisione sul Penn-Treebank (inglese)
22
01/06/2007
12
OUTPUT DI TREETAGGER
Ruhr-Universität Bochum, Germania, 24 maggio 2007
23
PROBLEMI CON TREETAGGER
I parametri
Ruhr-Universität Bochum, Germania, 24 maggio 2007
• non vanno bene per tutte le tipologie testuali, • ad esempio il parlato
• Spesso costruire un training corpus ah hoc non è possibile (1.000.000 di tokens, manualmente corretti)
• Il tagger va comunque sottoposto a nuovo training se si vuole ampliare il suo lessico
Errori sistematiciErrori sistematici• Participi e aggettivi• Mancato riconoscimento di nomi• Mancata indicazione di polirematiche
24
01/06/2007
13
TRAINING E CORREZIONE MANUALE
Training corpus
Ruhr-Universität Bochum, Germania, 24 maggio 2007
• Se si dispone già di un ampio corpus annotato• Se la tipologia è molto uniforme, e il vocabolario è ridotto
• es. meteo, oroscopo, ricette, istruzioni per l’uso, ecc.
Correzione manuale• Se il corpus è piccolo• oppurepp• Se è assolutamente necessaria una corretta annotazione
• per esempio se si vuole pubblicare il corpus di uno o più testi di un autore
• Se si può contare su un numero ampio di collaboratori
25
UN AIUTO NELLA CORREZIONE: POSEDIT
Silvio Pazzaglia, Università per stranieri di Perugia
Ruhr-Universität Bochum, Germania, 24 maggio 2007
•gratuito•http://elearning.unistrapg.it/corpora/
g
•Permette di intervenire e correggere rapidamente l’ouput
Cosa fa?
di Treetagger per poterlo usare in altri applicativi•Creare una cartella con i file del corpus e rinominare i txt
con estensione .ctx, correggere e poi eventualmente rinominare in .txt
26
01/06/2007
14
SCHERMATA POSEDIT
Ruhr-Universität Bochum, Germania, 24 maggio 2007
27
Ruhr-Universität Bochum, Germania, 24 maggio 2007
Intervento manuale, mediante scorrimento (verticale) della listaIntervento mediante ricerca globale e sostituzione per
Parole sconosciuteCorrezione manualePost-editing (con Taltac2)
29
TALTAC 2 E TREETAGGER
Integrazione
Ruhr-Universität Bochum, Germania, 24 maggio 2007
• Taltac 2 può pre-trattare il corpus e ricostruirlo normalizzato• Il testo viene analizzato da TreeTagger• Il testo può essere poi importato da Taltac2
P ibilità di f i d ll i di T lt 2 l
Potenziamento
• Possibilità di usufruire delle risorse di Taltac2 per la normalizzazione e per il trattamento del corpus
• Concordanze• Analisi statistiche (misure, co-occorrenze, confronto tra
lessici, analisi delle specificità)
30
01/06/2007
16
LE POLIREMATICHEEspressioni composte da più di una parola grafica, che tuttavia si comportano semanticamente e spesso morfo-sintatticamente come UN SOLO LESSEMA
Chiari, I. (2007), Introduzione alla linguistica computazionale, Laterza, Roma-Bari.
•stare a cuore, forza pubblica, prigioniero politico, vedere rosso, essere al verde
«specifico sovrappiù semantico, vale a dire la non ricostruibilità del loro significato in base alla semplice somma dei significati dei singoli componenti» (De Mauro)
cristallizzazione morfo-sintattica
•voi due siete proprio due occhi di lince•non *voi due siete proprio due occhi di linci
LE COLLOCAZIONI
Combinazioni di parole relativamente più libere delle polirematiche, ma accomunate da una
Chiari, I. (2007), Introduzione alla linguistica computazionale, Laterza, Roma-Bari.
particolare frequenza d’uso, ossia dalla preferenza per l’occorrenza congiunta dei suoi componenti.
• compilare un modulo• obliterare il biglietto• delitto efferato
Gli elementi che entrano a far parte di una Gli elementi che entrano a far parte di una collocazione sono molto più rigidi e poco analitici, quindi anche i traducenti in una lingua straniera tendono a essere imprevedibili
01/06/2007
17
PROBLEMI PER LA LINGUA ITALIANA
Q i di li i i ò i l f
Morfologia flessiva ricca
Ruhr-Universität Bochum, Germania, 24 maggio 2007
•Quindi una stessa polirematica si può trovare in molte forme•Ma NON TUTTE le forme
•Ci vedo rosso•Ci avete visto rosso•Ci vidi rosso
Vederci rosso
•Ci ho visto proprio rosso
•*Ci abbiamo visto rossi•*Lei ci vide rossa
*
33
QUINDI…
Ruhr-Universität Bochum, Germania, 24 maggio 2007
Non si possono usare le misure e gli
strumenti che vanno bene per l’inglese
È necessario sviluppare strumenti
che sappiano riconoscere le
li ti h it lipolirematiche italiane
34
01/06/2007
18
STRUMENTI
L i di lif i (FDP) i 4 000 lif i
Lessico dei poliformi (FDP)
Ruhr-Universität Bochum, Germania, 24 maggio 2007
•Lessico di poliformi (FDP), con circa 4.000 poliformi•sia locuzioni di tipo grammaticale, sia gruppi nominali di tipo
polirematico, sia espressioni di verbi idiomatici•(Bolasco, 1998).
•Analisi automatica di testi dal web e personaliKil iff t lii
Web Bootcat e Sketch Engine
•Kilgarriff et alii
•Procedura per applicare le misure di associazione statistica ai lemmi
Taltac2 – ricostruzione corpus lemmatizzato
35
WEB BOOTCAT CORPUS IN POCHI SECONDI MA…
Autori
Ruhr-Universität Bochum, Germania, 24 maggio 2007
• Baroni, M., Kilgarriff, A., Pomikálek, J., Rychlý, P
• http://corpora.sketchengine.co.uk
Sito web
Bibliografia
• Baroni, M., Kilgarriff, A., Pomikálek, J., Rychlý, P.: WebBootCaT: instant domain-specific corpora to support human translators. Proceedings of EAMT 2006, Oslo. (2006) 247-252
Bibliografia
36
01/06/2007
19
COSTRUZIONE DEL CORPUS
Ruhr-Universität Bochum, Germania, 24 maggio 2007
37
Ruhr-Universität Bochum, Germania, 24 maggio 2007
38
01/06/2007
20
SKETCH ENGINE
Autori
Ruhr-Universität Bochum, Germania, 24 maggio 2007
• A. Kilgarriff, M. Rundall, e altri
• Costruisce riassunti automatici del comportamento grammaticale di una parola in un corpus
• Estrae collocazioni, misura la similarità tra parole
Cosa fa?
• Macmillan English Dictionary e molti altri dizionari
Strumento per la lessicografia
39
Ruhr-Universität Bochum, Germania, 24 maggio 2007
40
01/06/2007
21
CALCIO
Ruhr-Universität Bochum, Germania, 24 maggio 2007
41
CALCIO 2
Ruhr-Universität Bochum, Germania, 24 maggio 2007
42
01/06/2007
22
CONCORDANZA (LEMMATIZZATA)
Ruhr-Universität Bochum, Germania, 24 maggio 2007
43
CONCLUSIONI
Corpora
Ruhr-Universität Bochum, Germania, 24 maggio 2007
•per costruire un corpus bisogna risolvere alcuni problemi tecnici di trattamento dei testi
•se non trattiamo i testi, allora tanto vale andare a esplorare il web con Google (ma…questo è un altro tema)…
StrumentiN t t è f tt•Nessuno strumento è perfetto
•Alcuni strumenti permettono meglio di risolvere alcuni problemi
Perché facciamo questo? ….
44
01/06/2007
23
DEFINIZIONE DI EAGLES
Ruhr-Universität Bochum, Germania, 24 maggio 2007
An electronic corpus is “scorpus which is encoded in
a standardized and homogeneous way for open-
ended retrieval tasks”
Un corpus elettronico è “un corpus che è codificato in maniera standardizzata e omogenea per consentire